



Synthèse exécutive
Les hallucinations IA — des situations où les modèles génèrent des informations fausses ou inventées avec une confiance totale — représentent l’un des risques les plus critiques, mais aussi les plus sous-estimés, dans le paysage économique actuel propulsé par l’IA. Les données ci-dessous en montrent clairement l’ampleur. Elles montrent aussi qu’aucun modèle n’est immunisé, raison pour laquelle l’atténuation des hallucinations via une vérification multi-modèles devient une exigence structurelle, et non une protection optionnelle.
Ce rapport compile des données statistiques brutes issues de plusieurs benchmarks faisant autorité, d’études sectorielles et du suivi d’incidents réels, afin de servir de base de contenu.
Les chiffres clés sont stupéfiants :
- Les pertes mondiales des entreprises dues aux hallucinations IA ont atteint 67,4 milliards de dollars en 2024 à elles seules[1][2]
- 47 % des dirigeants d’entreprise ont pris des décisions majeures sur la base de contenus générés par l’IA non vérifiés[3][1]
- Même les meilleurs modèles d’IA hallucinent encore au moins 0,7 % du temps sur des tâches de synthèse de base — et les taux s’envolent à 18,7 % sur des questions juridiques et 15,6 % sur des requêtes médicales[4]
- Sur des questions de connaissance difficiles, tous les modèles testés sauf trois sur 40 ont plus de chances d’halluciner que de donner une réponse correcte[5][6]
Qu’est-ce qu’une hallucination IA ? (Définition technique + en termes simples)
En termes simples
Une hallucination IA se produit lorsqu’un modèle d’IA invente quelque chose avec assurance. Il ne dit pas « je ne sais pas » — il présente des faits fabriqués, des statistiques inventées, de faux précédents juridiques ou des études médicales inexistantes comme s’ils étaient réels. La réponse sonne de manière autoritaire et se lit parfaitement. C’est ce qui la rend dangereuse.[7]
Définition technique
En termes techniques, l’hallucination désigne une sortie générée qui n’est pas ancrée dans les données d’entrée fournies ni dans la réalité factuelle. Il existe deux types principaux :
- Hallucination intrinsèque (aussi appelée « hallucination de fidélité ») : le modèle contredit des informations explicitement fournies dans son matériau source. Par exemple, lors d’une synthèse, il ajoute des faits absents du document d’origine.[8]
- Hallucination extrinsèque (aussi appelée « hallucination de factualité ») : le modèle génère des informations qui ne peuvent être vérifiées auprès d’aucune source connue — il invente de toutes pièces des faits, des citations, des statistiques ou des événements.[9]
Un enseignement technique crucial issu de recherches du MIT (janvier 2025) : lorsque les modèles d’IA hallucinent, ils ont tendance à utiliser un langage plus assuré que lorsqu’ils fournissent des informations factuelles. Les modèles étaient 34 % plus susceptibles d’employer des expressions comme « définitivement », « certainement » et « sans aucun doute » lorsqu’ils généraient des informations incorrectes.[4]
C’est le paradoxe central : plus l’IA a tort, plus elle semble sûre d’elle.
Pourquoi cela se produit
Les LLM sont fondamentalement des moteurs de prédiction, pas des bases de connaissances. Ils génèrent du texte en prédisant le mot suivant le plus probable statistiquement, à partir de schémas appris dans les données d’entraînement. Ils ne « comprennent » pas la vérité — ils prédisent la plausibilité. Lorsque le modèle rencontre une lacune dans ses données d’entraînement ou fait face à une requête ambiguë, il comble le vide par une invention plausible plutôt que d’admettre son incertitude.[1]
Benchmark 1 : classement Vectara des hallucinations (HHEM)
Ce qu’il mesure
Le classement Vectara Hughes Hallucination Evaluation Model (HHEM) est le benchmark d’hallucination le plus cité du secteur. Il mesure l’hallucination ancrée — la fréquence à laquelle un LLM introduit de fausses informations lorsqu’il résume un document qui lui a été explicitement fourni. Voyez-le comme : « Le modèle peut-il s’en tenir à ce qui est écrit devant lui ? »[10][8]
Benchmarks d’hallucinations IA (tableau en direct) incluant le classement Vectara Hughes Hallucination Evaluation Model (HHEM).
Méthodologie : plus de 1 000 documents sont fournis à chaque modèle avec des instructions de synthèse utilisant uniquement les faits du document. Le modèle HHEM de Vectara vérifie ensuite chaque synthèse par rapport à la source afin d’identifier les affirmations fabriquées.[10]
Pourquoi cela compte pour les utilisateurs métier
C’est directement analogue à la manière dont l’IA est utilisée dans les systèmes RAG (Retrieval Augmented Generation) — l’épine dorsale de la recherche IA en entreprise, des bots de support client et des outils d’analyse de documents. Si un modèle hallucine lors d’une synthèse, il hallucine lorsqu’il répond à des questions à partir de la base de connaissances de votre entreprise.[10]
Taux d’hallucinations — jeu de données d’origine (avril 2025)
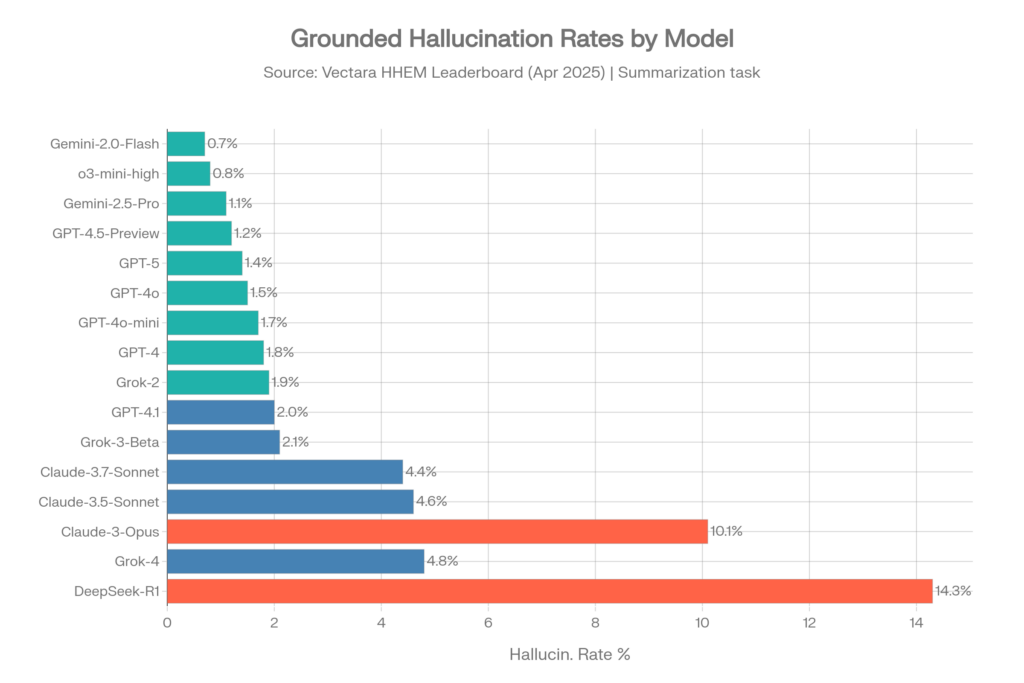
Ce jeu de données d’environ 1 000 documents a été le benchmark standard jusqu’à mi-2025.[10]
| Modèle | Fournisseur | Taux d’hallucinations | Cohérence factuelle |
| Gemini-2.0-Flash-001 | 0.7% | 99.3% | |
| Gemini-2.0-Pro-Exp | 0.8% | 99.2% | |
| o3-mini-high | OpenAI | 0.8% | 99.2% |
| Gemini-2.5-Pro-Exp | 1.1% | 98.9% | |
| GPT-4.5-Preview | OpenAI | 1.2% | 98.8% |
| Gemini-2.5-Flash-Preview | 1.3% | 98.7% | |
| o1-mini | OpenAI | 1.4% | 98.6% |
| GPT-5 / ChatGPT-5 | OpenAI | 1.4% | 98.6% |
| GPT-4o | OpenAI | 1.5% | 98.5% |
| GPT-4o-mini | OpenAI | 1.7% | 98.3% |
| GPT-4-Turbo | OpenAI | 1.7% | 98.3% |
| GPT-4 | OpenAI | 1.8% | 98.2% |
| Grok-2 | xAI | 1.9% | 98.1% |
| GPT-4.1 | OpenAI | 2.0% | 98.0% |
| Grok-3-Beta | xAI | 2.1% | 97.8% |
| Claude-3.7-Sonnet | Anthropic | 4.4% | 95.6% |
| Claude-3.5-Sonnet | Anthropic | 4.6% | 95.4% |
| Claude-3.5-Haiku | Anthropic | 4.9% | 95.1% |
| Grok-4 | xAI | 4.8% | ~95,2 % |
| Llama-4-Maverick | Meta | 4.6% | 95.4% |
| Claude-3-Opus | Anthropic | 10.1% | 89.9% |
| DeepSeek-R1 | DeepSeek | 14.3% | 85.7% |
Source : classement Vectara HHEM, dépôt GitHub, avril 2025[10]
Principaux enseignements de Vectara (ancien jeu de données)
- Les modèles Google Gemini dominent les premières places, avec Gemini-2.0-Flash en tête à 0,7 %[4]
- OpenAI est régulièrement performant sur l’ensemble de la famille GPT-4, de 0,8 % à 2,0 %[10]
- Grok-4 à 4,8 % est nettement plus élevé que ses concurrents GPT et Gemini — près de 7x le taux d’hallucinations du meilleur modèle Gemini[11]
- Les modèles Claude affichent une dispersion surprenante : Claude-3.7-Sonnet à 4,4 % est honorable, mais Claude-3-Opus à 10,1 % est préoccupant[10]
- Le modèle de raisonnement o3-mini-high d’OpenAI a atteint 0,8 %, montrant que les capacités de raisonnement peuvent réellement améliorer l’ancrage factuel[10]
Taux d’hallucinations — nouveau jeu de données (novembre 2025 – février 2026)
Vectara a lancé fin 2025 un benchmark entièrement renouvelé avec 7 700 articles (contre 1 000), des documents plus longs (jusqu’à 32K jetons) et un contenu plus complexe couvrant le droit, la médecine, la finance, la technologie et l’éducation.[12]
Les résultats sont nettement plus élevés — volontairement. Ce benchmark reflète mieux les charges de travail réelles en entreprise.[12]
| Modèle | Fournisseur | Taux d’hallucinations |
| Gemini-2.5-Flash-Lite | 3.3% | |
| Mistral-Large | Mistral | 4.5% |
| DeepSeek-V3.2-Exp | DeepSeek | 5.3% |
| GPT-4.1 | OpenAI | 5.6% |
| Grok-3 | xAI | 5.8% |
| DeepSeek-R1-0528 | DeepSeek | 7.7% |
| Claude Sonnet 4.5 | Anthropic | >10% |
| GPT-5 | OpenAI | >10% |
| Grok-4 | xAI | >10% |
| Gemini-3-Pro | 13.6% |
Source : classement Vectara des hallucinations, nouveau jeu de données, novembre 2025[13][12]
La découverte de la « taxe du raisonnement »
Le classement mis à jour de Vectara a révélé un constat clé : les modèles de raisonnement/réflexion performent en réalité moins bien sur la synthèse ancrée. Des modèles comme GPT-5, Claude Sonnet 4.5, Grok-4 et Gemini-3-Pro — commercialisés comme de bons « raisonneurs » — ont tous dépassé 10 % de taux d’hallucinations sur le benchmark plus difficile.[12][14][15]
Hypothèse : les modèles de raisonnement investissent des ressources de calcul dans le fait de « réfléchir » aux réponses, ce qui les amène parfois à surinterpréter et à s’écarter du matériau source, plutôt que de s’en tenir au texte fourni. C’est une réserve majeure pour les applications RAG en entreprise.[15]
Benchmark 2 : AA-Omniscience (Artificial Analysis)
Ce qu’il mesure
Publié en novembre 2025, AA-Omniscience est un benchmark de connaissances et d’hallucinations couvrant 6 000 questions sur 42 sujets au sein de 6 domaines : Business, Humanités & sciences sociales, Santé, Droit, Génie logiciel et Sciences/Maths.[5][6]
Contrairement aux benchmarks traditionnels qui se contentent de compter les réponses correctes, l’indice Omniscience pénalise les réponses incorrectes — ce qui signifie qu’un modèle qui devine à tort est sanctionné plus sévèrement qu’un modèle qui admet « je ne sais pas ». L’échelle va de -100 à +100.[6]
Pourquoi ce benchmark est différent (et inquiétant)
La plupart des benchmarks d’IA récompensent les modèles qui tentent de répondre à toutes les questions, ce qui incite à deviner. AA-Omniscience inverse la logique : il demande « le modèle sait-il quand il ne sait pas ? ». La réponse, pour la plupart des modèles, est non.[6]
Résultats
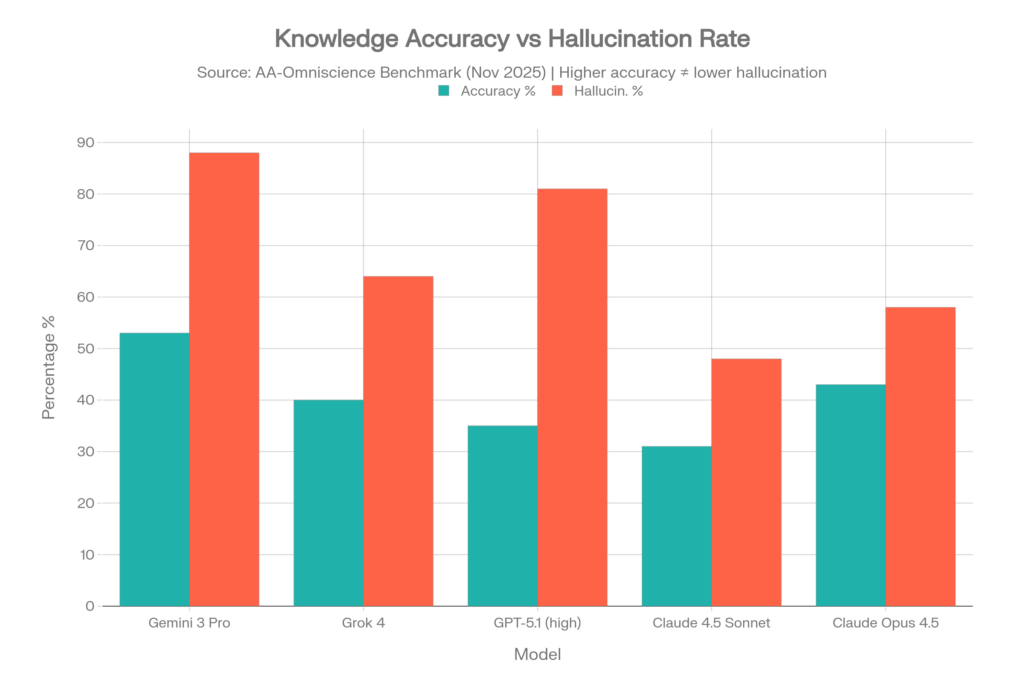
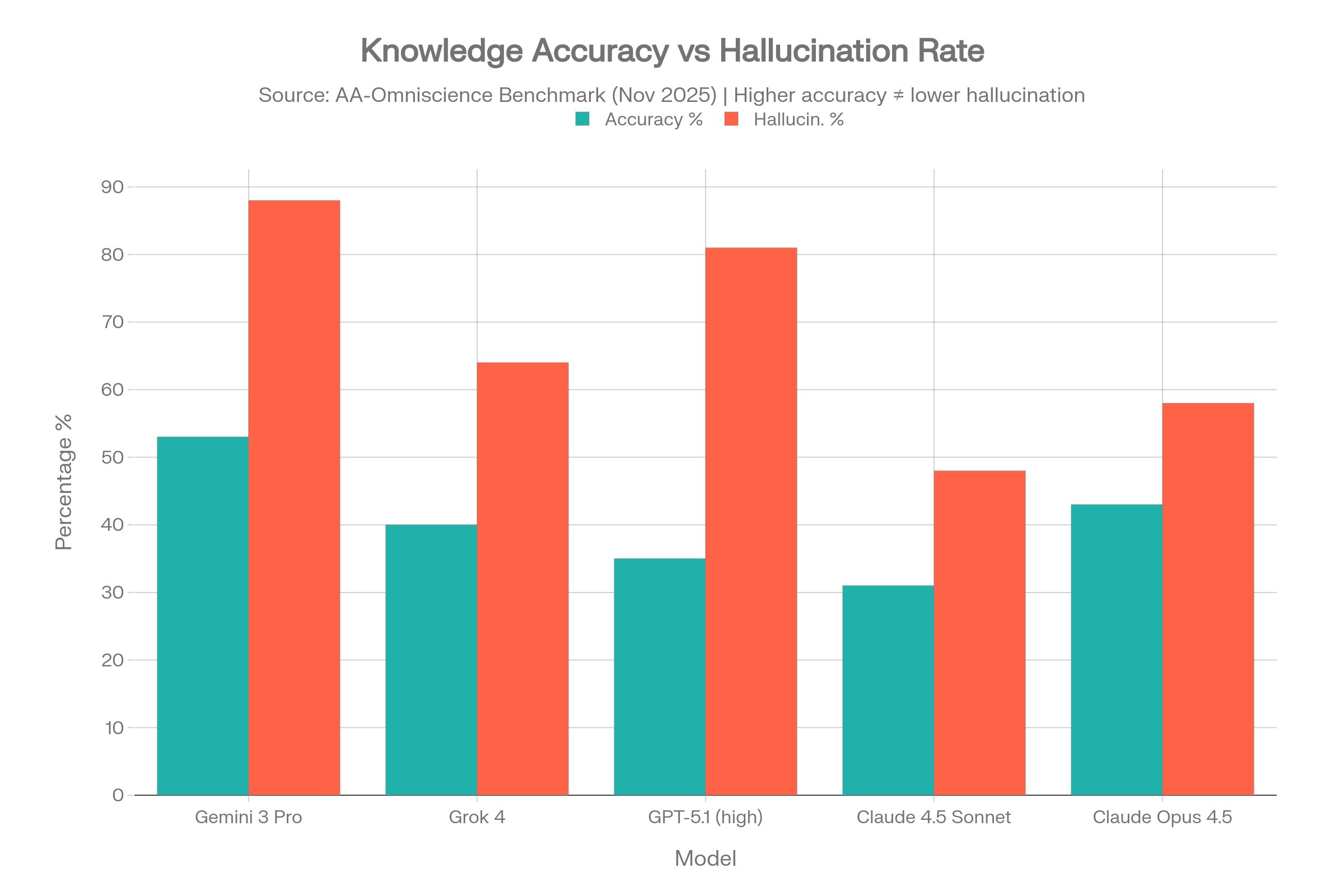
Sur 40 modèles testés, seuls QUATRE ont obtenu un indice Omniscience positif — ce qui signifie que 36 modèles sur 40 ont plus de chances de donner une réponse fausse avec assurance qu’une réponse correcte sur des questions de connaissance difficiles.[5][6]
| Modèle | Précision | Taux d’hallucinations* | Indice d’omniscience |
| Gemini 3 Pro | 53% | 88% | 13 |
| Claude 4.1 Opus | 36% | Faible (meilleur) | 4.8 |
| GPT-5.1 (élevé) | 35-39% | 51-81% | Positif |
| Grok 4 | 40% | 64% | Positif |
| Claude 4.5 Sonnet | 31% | 48% | Négatif |
| Claude 4.5 Haiku | — | 26 % (le plus faible) | Négatif |
| Claude Opus 4.5 | 43% | 58% | Négatif |
| Grok 4.1 Fast | — | 72% | Négatif |
| Kimi K2 0905 | — | 69% | Négatif |
| Kimi K2 Thinking | — | 74% | Négatif |
| DeepSeek V3.2 Ex | — | 81% | Négatif |
| DeepSeek R1 0528 | — | 83% | Négatif |
| Llama 4 Maverick | — | 87.58% | Négatif |
Taux d’hallucinations ici = part de réponses fausses parmi toutes les tentatives incorrectes (métrique de surconfiance)
Source : benchmark AA-Omniscience d’Artificial Analysis, novembre 2025[16][5]
Leaders par domaine
Aucun modèle ne domine l’ensemble des domaines de connaissance :[5]
| Domaine | Meilleur modèle |
| Droit | Claude 4.1 Opus |
| Ingénierie logicielle | Claude 4.1 Opus |
| Humanités | Claude 4.1 Opus |
| Affaires | GPT-5.1.1 |
| Santé | Grok 4 |
| Sciences | Grok 4 |
Le paradoxe de Gemini 3 Pro
Gemini 3 Pro a atteint la meilleure précision (53 %) avec une large avance — mais a aussi affiché un taux d’hallucinations de 88 %. Cela signifie que lorsqu’il ne connaît pas une réponse, il en fabrique une 88 % du temps au lieu d’admettre son incertitude. Haute précision + hallucinations élevées = un modèle qui sait beaucoup, mais ment constamment sur ce qu’il ne sait pas.[5]
L’histoire de Grok
Grok 4 affiche un taux d’hallucinations de 64 % sur AA-Omniscience, et son nouveau « frère » Grok 4.1 Fast est en réalité pire à 72 %. Sur le benchmark Vectara de synthèse ancrée, Grok-4 est à 4,8 % — près de 7x plus élevé que le meilleur modèle Gemini. Et dans une étude de la Columbia Journalism Review axée sur la précision des citations d’actualité, Grok-3 a halluciné à un niveau stupéfiant de 94 %.[16][11][17]
xAI affirme que Grok 4.1 est « trois fois moins susceptible d’halluciner que les anciens modèles Grok », et une analyse distincte de Clarifai suggère que les taux d’hallucinations sont passés de ~12 % à ~4 % grâce à des améliorations d’entraînement. Mais les données AA-Omniscience racontent une autre histoire lorsque les questions deviennent difficiles.[18][19]
Benchmark 3 : étude de citations de la Columbia Journalism Review
Une étude de mars 2025 de la Columbia Journalism Review a testé des modèles d’IA sur leur capacité à citer correctement des sources d’actualité. Les résultats étaient alarmants :[20][17]
| Modèle | Taux d’hallucination |
| Perplexity | 37% |
| Copilot | 40% |
| Perplexity Pro | 45% |
| ChatGPT | 67% |
| DeepSeek | 68% |
| Gemini | 76% |
| Grok-2 | 77% |
| Grok-3 | 94% |
Source : Columbia Journalism Review, mars 2025, via 5GWorldPro/Groundstone AI[17][20]
Cette étude est particulièrement pertinente pour les utilisateurs de Perplexity/Sonar : même si Perplexity a obtenu le « meilleur » score dans ce test, un taux d’hallucinations de 37 % sur les tâches de citation signifie que plus d’une source citée sur trois peut contenir des affirmations fabriquées. Une analyse distincte a noté que la principale inquiétude concernant Perplexity est qu’il « cite de vraies sources avec des affirmations fabriquées » — les URL semblent réelles, mais les informations attribuées à ces sources sont inventées.[21]
Benchmark 4 : taux d’hallucinations en finance
Une étude de 2025 publiée dans l’International Journal of Data Science and Analytics a testé des chatbots d’IA spécifiquement sur des références de littérature financière :[17]
| Modèle | Taux d’hallucinations (finance) |
| ChatGPT-4o | 20.0% |
| GPT o1-preview | 21.3% |
| Gemini Advanced | 76.7% |
Constats plus larges sur l’IA en finance :[22]
- 78 % des entreprises de services financiers déploient désormais l’IA pour l’analyse de données
- Les tâches financières avec IA affichent 15 à 25 % de taux d’hallucinations sans garde-fous
- Les entreprises déclarent 2,3 erreurs significatives pilotées par l’IA par trimestre
- Le coût par incident varie de 50 000 $ à 2,1 millions de dollars
- 67 % des fonds de capital-risque utilisent l’IA pour le tri des opportunités ; le délai moyen de découverte des erreurs est de 3,7 semaines — souvent trop tard
- L’hallucination d’un robo-advisor a affecté 2 847 portefeuilles clients, coûtant 3,2 millions de dollars en remédiation
Taux d’hallucination spécifiques au domaine
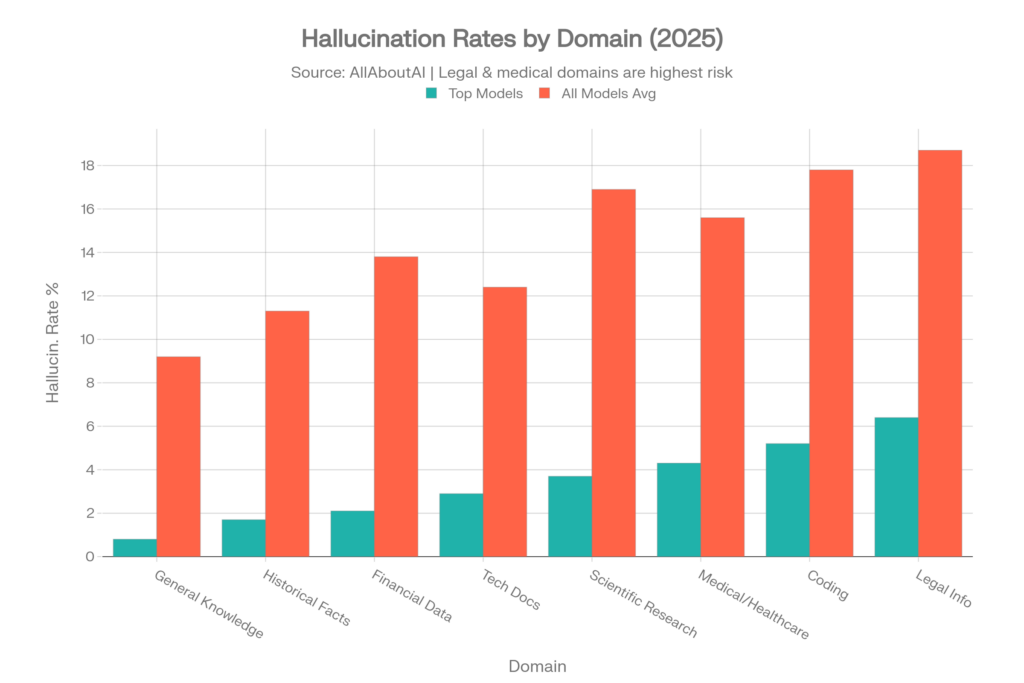
Même les modèles les plus performants affichent des taux d’hallucinations très différents selon le sujet. Ces données d’AllAboutAI sont essentielles pour comprendre le risque selon le cas d’usage :[4]
| Domaine de connaissance | Taux des meilleurs modèles | Moyenne de tous les modèles |
| Connaissances générales | 0.8% | 9.2% |
| Faits historiques | 1.7% | 11.3% |
| Données financières | 2.1% | 13.8% |
| Documentation technique | 2.9% | 12.4% |
| Recherche scientifique | 3.7% | 16.9% |
| Médical/Santé | 4.3% | 15.6% |
| Codage et programmation | 5.2% | 17.8% |
| Informations juridiques | 6.4% | 18.7% |
Analyse approfondie des hallucinations en médecine
Une étude MedRxiv de 2025 a analysé 300 vignettes cliniques validées par des médecins :[23]
- Sans prompts d’atténuation : 64,1 % de taux d’hallucinations sur les cas longs, 67,6 % sur les cas courts
- Avec prompts d’atténuation : baisse à 43,1 % et 45,3 % respectivement (réduction de 33 %)
- GPT-4o a été le plus performant : baisse de 53 % à 23 % avec atténuation
- Modèles open source : ont dépassé 80 % de taux d’hallucinations dans des scénarios médicaux
Même avec le meilleur taux d’hallucinations médicales à 23 %, près d’1 réponse médicale IA sur 4 contient des informations fabriquées. ECRI, une ONG mondiale de sécurité des soins, a classé les risques liés à l’IA comme le danger n°1 des technologies de santé pour 2025.[24]
Analyse approfondie des hallucinations juridiques
L’étude Stanford RegLab/HAI sur les hallucinations juridiques reste la recherche de référence :[25][9]
- Les LLM hallucinent entre 69 % et 88 % du temps sur des requêtes juridiques spécifiques
- Sur des questions portant sur la décision centrale d’un tribunal, les modèles hallucinent au moins 75 % du temps
- Les modèles manquent souvent de conscience de leurs erreurs et renforcent des hypothèses juridiques incorrectes
- Plus la requête juridique est complexe, plus le taux d’hallucinations est élevé
- 83 % des professionnels du droit ont rencontré une jurisprudence fabriquée en utilisant l’IA[26]
Impact réel sur les entreprises : les chiffres
Le problème des 67,4 milliards de dollars
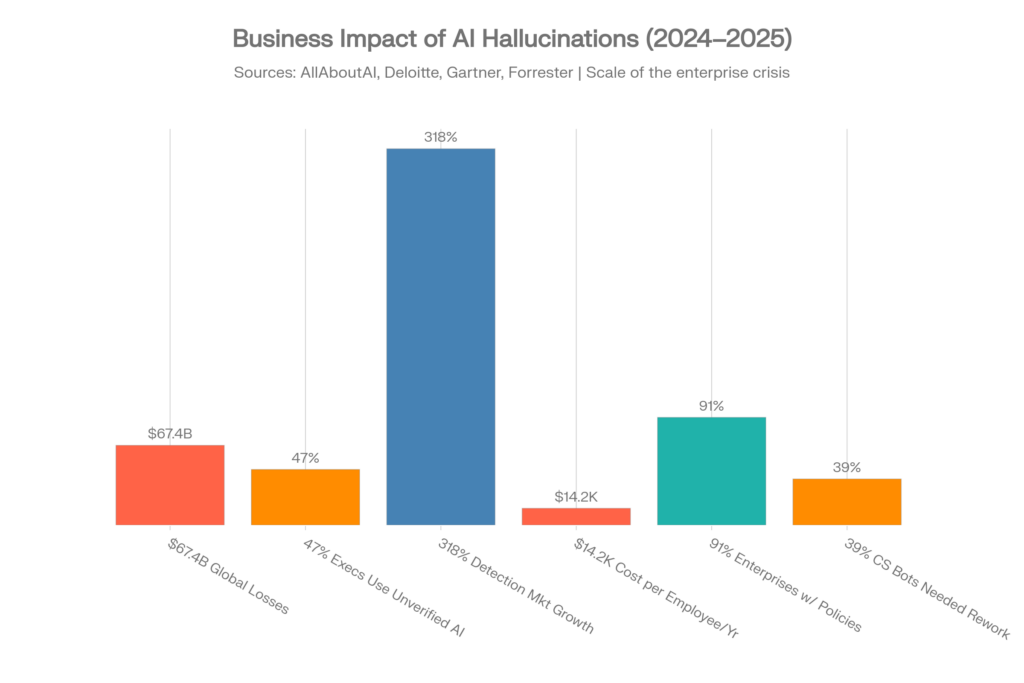
Les pertes mondiales des entreprises attribuées aux hallucinations IA ont atteint 67,4 milliards de dollars en 2024. Ce chiffre provient de l’étude exhaustive d’AllAboutAI et représente des coûts directs et indirects documentés liés à des entreprises s’appuyant sur des contenus générés par l’IA inexacts.[1][2]
Statistiques clés sur l’impact métier
| Indicateur | Valeur | Source |
| Pertes mondiales dues aux hallucinations IA (2024) | 67,4 milliards de dollars | AllAboutAI, 2025 [1] |
| Dirigeants utilisant des insights IA non vérifiés | 47% | Deloitte, 2025 [1] |
| Bugs IA dus aux hallucinations/échecs de précision | 82% | Testlio, 2025 [27] |
| Bots de service client nécessitant des retouches | 39% | Testlio, 2024 [3] |
| Amendes de la SEC pour fausses déclarations liées à l’IA | 12,7 millions de dollars | Rapports sectoriels [3] |
| Entreprises avec baisse de la confiance des investisseurs | 54% | Rapports sectoriels [3] |
| Coût par employé pour l’atténuation des hallucinations | 14 200 $/an | Forrester, 2025 [26][28] |
| Temps des employés à vérifier le contenu IA | 4,3 heures/semaine | Forbes/AllAboutAI [28] |
| Croissance du marché des outils de détection d’hallucinations | 318% (2023-2025) | Gartner, 2025 [26] |
| Politiques IA en entreprise avec protocoles d’hallucinations | 91% | AllAboutAI, 2025 [26] |
| Organisations de santé retardant l’adoption de l’IA | 64% | AllAboutAI, 2025 [26] |
| Investissement dans des solutions spécifiques aux hallucinations | 12,8 milliards de dollars | AllAboutAI, 2023-2025 [4] |
| Efficacité du RAG pour réduire les hallucinations | 71% | AllAboutAI, 2025 [4] |
Le paradoxe de la productivité
L’ironie la plus cruelle : l’IA était censée nous rendre plus productifs. Au lieu de cela, les employés passent désormais en moyenne 4,3 heures par semaine — plus d’une demi-journée de travail — simplement à vérifier si ce que l’IA leur a dit est réellement vrai. Cela représente environ 14 200 $ par employé et par an de surcoût de vérification pur. Pour une entreprise de 500 employés utilisant des outils d’IA, cela représente 7,1 millions de dollars par an dépensés uniquement à vérifier les devoirs de l’IA.[26][28]
Incidents juridiques : la crise des tribunaux
Les chiffres empirent, ils ne s’améliorent pas
Malgré une prise de conscience croissante, les hallucinations IA dans les dépôts juridiques s’accélèrent :[29][30]
- 2023 : 10 décisions de justice documentées impliquant des hallucinations IA
- 2024 : 37 décisions documentées
- 5 premiers mois de 2025 : 73 décisions documentées
- Juillet 2025 à lui seul : plus de 50 affaires impliquant de fausses citations
Le chercheur juridique Damien Charlotin maintient une base de données publique de plus de 120 affaires où des tribunaux ont constaté des citations hallucinéés par l’IA, des affaires fabriquées ou de fausses références juridiques.[30]
Qui commet ces erreurs ?
Le passage de l’amateur au professionnel est alarmant :[30]
- 2023 : 7 cas d’hallucinations sur 10 provenaient de justiciables se représentant eux-mêmes, 3 d’avocats
- Mai 2025 : 13 cas sur 23 détectés étaient dus à des avocats et des professionnels du droit
Affaires notables
- Johnson v. Dunn : des avocats ont déposé deux requêtes avec de fausses autorités juridiques générées par ChatGPT. Résultat : ordonnance de sanctions de 51 pages, réprimande publique, exclusion de l’affaire, signalement aux autorités de délivrance des licences[29]
- Morgan & Morgan (févr. 2025) : l’un des plus grands cabinets américains en dommages corporels a envoyé un avertissement urgent à plus de 1 000 avocats après qu’un juge fédéral du Wyoming a menacé de sanctions pour des citations fallacieuses générées par l’IA dans une action contre Walmart[31]
- Les tribunaux ont imposé des sanctions financières de 10 000 $ ou plus dans au moins cinq affaires, dont quatre en 2025[30]
- Des affaires ont été documentées aux États-Unis, au Royaume-Uni, en Afrique du Sud, en Israël, en Australie et en Espagne[30]
Santé : là où les hallucinations peuvent tuer
Préoccupations de la FDA et des dispositifs médicaux
- La FDA a autorisé 1 357 dispositifs médicaux améliorés par l’IA fin 2025 — le double du nombre de fin 2022[32]
- Des recherches de Johns Hopkins, Georgetown et Yale ont constaté que 60 dispositifs médicaux IA autorisés par la FDA ont été impliqués dans 182 rappels[32]
- 43 % de ces rappels sont survenus dans l’année suivant l’autorisation[32]
- Le système Johnson & Johnson TruDi Navigation System (dispositif de chirurgie des sinus amélioré par l’IA) a été associé à au moins 10 blessures et 100 dysfonctionnements, notamment des fuites de liquide céphalo-rachidien, des perforations du crâne et des AVC[33][32]
Désinformation médicale par l’IA
Il a été constaté que les principaux modèles d’IA pouvaient être manipulés pour produire des conseils médicaux dangereusement faux — par exemple en affirmant que la crème solaire provoque le cancer de la peau ou en liant la 5G à l’infertilité — avec des citations fabriquées de revues comme The Lancet.[4]
Tendance historique : les progrès sont réels mais inégaux
La bonne nouvelle
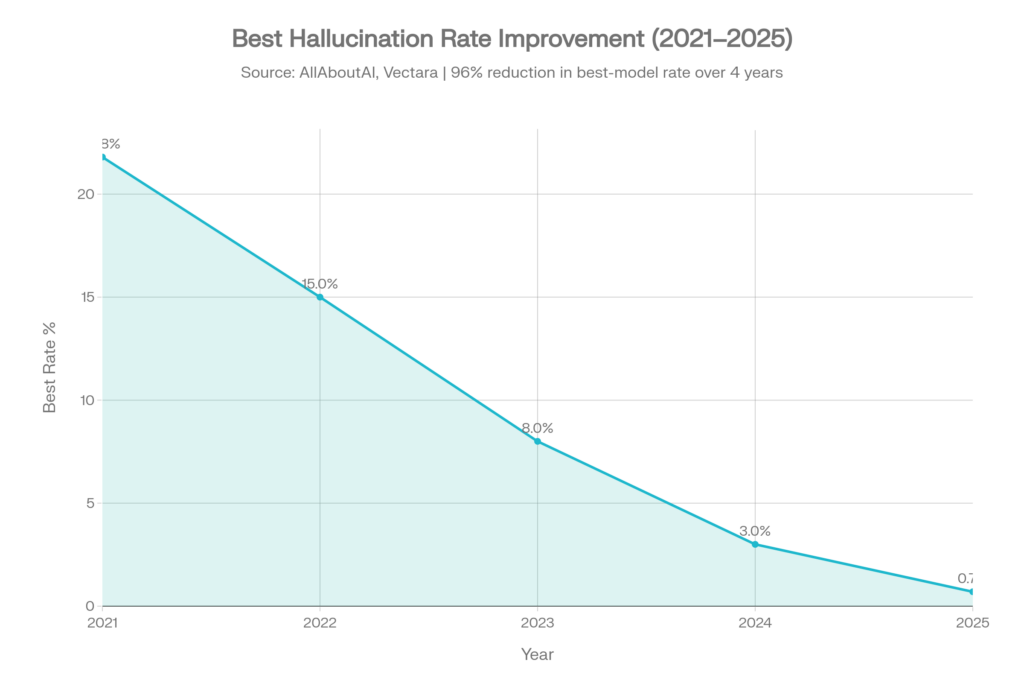
Les taux d’hallucinations des meilleurs modèles ont fortement baissé :[4]
| Année | Meilleur taux d’hallucination | Contexte |
| 2021 | ~21,8 % | Début de l’ère GPT-3 |
| 2022 | ~15,0 % | Amélioration avec le RLHF |
| 2023 | ~8,0 % | GPT-4 et la concurrence |
| 2024 | ~3,0 % | Amélioration rapide |
| 2025 | 0.7% | Gemini-2.0-Flash en tête |
Cela représente une réduction de 96 % des taux d’hallucinations des meilleurs modèles en quatre ans.[4]
La mauvaise nouvelle
- L’amélioration est inégale selon les fournisseurs. Certains modèles Claude se sont même dégradés : Claude 3 Sonnet est passé de 6,0 % à 16,3 %, et Claude 2 a presque doublé de 8,5 % à 17,4 % sur le benchmark Vectara au fil du temps.[23]
- Les nouveaux benchmarks « plus difficiles » révèlent l’écart entre les tâches simples et la complexité du monde réel. Sur le nouveau jeu de données de Vectara, même Gemini-3-Pro atteint 13,6 %.[12]
- Les résultats AA-Omniscience sont sans appel : sur des questions réellement difficiles, 36 modèles sur 40 hallucinent encore plus qu’ils ne répondent correctement.[6]
- Les taux par domaine restent dangereusement élevés : juridique (18,7 % en moyenne), médical (15,6 %) et code (17,8 %).[4]
La trajectoire de Grok
- Ère Grok-1/2 : positionné comme un modèle davantage « axé personnalité », avec moins d’accent sur l’ancrage factuel
- Grok-3 : 2,1 % sur l’ancien benchmark Vectara de synthèse (correct) mais 94 % sur la précision des citations dans le test de la Columbia Journalism Review[10][17]
- Grok-4 : 4,8 % sur Vectara, 64 % sur les questions difficiles AA-Omniscience[16][11]
- Grok 4.1 : xAI a affirmé « 3x moins d’hallucinations », Clarifai a estimé une baisse de ~12 % à ~4 %, mais AA-Omniscience a montré 72 % sur Grok 4.1 Fast (pire que les 64 % de Grok 4)[18][19][16]
L’incohérence entre benchmarks suggère que les améliorations de Grok peuvent être spécifiques à certaines tâches plutôt que généralisables.
Synthèse modèle par modèle pour les modèles Suprmind.ai
Modèles OpenAI
| Modèle | Vectara (Ancien) | Vectara (Nouveau) | AA-Omniscience | Notes |
| GPT-5 / ChatGPT-5 | 1.4% | >10 % | — | Amélioration solide sur les tâches faciles ; difficultés sur les tâches difficiles [11] |
| GPT-5.1 (élevé) | — | — | 51-81 % halluc, 35 % précision | Meilleur pour le domaine Business ; indice Omniscience positif [5] |
| GPT-4o | 1.5% | — | — | Modèle polyvalent, performant de manière constante [10] |
| o3-mini-high | 0.8% | — | — | Meilleur modèle OpenAI sur l’ancien Vectara [10] |
Modèles Claude d’Anthropic
| Modèle | Vectara (Ancien) | Vectara (Nouveau) | AA-Omniscience | Notes |
| Claude 4.5 Sonnet | — | >10 % | 48 % halluc, 31 % précision | Intermédiaire sur les tâches de connaissance [16] |
| Claude 4.5 Haiku | — | — | 26 % halluc (le plus faible !) | Meilleure gestion de l’incertitude [16] |
| Claude Opus 4.5 | — | — | 58 % halluc, 43 % précision | Bonne précision mais forte surconfiance [16] |
| Claude 4.1 Opus | — | — | Indice Omniscience : 4,8 | Meilleur en droit, génie logiciel, humanités [5] |
| Claude-3.7-Sonnet | 4.4% | — | — | Correct en synthèse [10] |
Modèles Grok de xAI
| Modèle | Vectara (Ancien) | Vectara (Nouveau) | AA-Omniscience | Autre |
| Grok 4 | 4.8% | >10 % | 64 % halluc, 40 % précision | Meilleur en santé & sciences ; indice Omniscience positif [11][16] |
| Grok 4.1 | — | — | 72 % halluc (variante Fast) | xAI revendique une amélioration x3, données mitigées [16][19] |
| Grok 3 | 2.1% | 5.8% | — | 94 % au test de citations d’actualité [17] |
Modèles Google Gemini
| Modèle | Vectara (Ancien) | Vectara (Nouveau) | AA-Omniscience | Notes |
| Gemini 3 Pro | — | 13.6% | 88 % halluc, 53 % précision, Indice : 13 | Précision la plus élevée mais surconfiance extrême [5][12] |
| Gemini 2.5-Pro | 1.1% | — | — | Performant sur l’ancien benchmark [10] |
| Gemini 2.5-Flash | 1.3% | — | — | [10] |
| Gemini 2.5-Flash-Lite | — | 3.3% | — | Meilleur sur le nouveau benchmark Vectara [13] |
Perplexity / Sonar
- Aucune présence directe sur Vectara ou AA-Omniscience pour les modèles propriétaires de Perplexity
- Perplexity utilise des modèles sous-jacents (historiquement, notamment DeepSeek-R1, qui a ~14,3 % de taux d’hallucinations sur Vectara)[34]
- Test Columbia Journalism Review : Perplexity à 37 % d’hallucinations sur la précision des citations (meilleur de ce test, mais toujours 1 sur 3)[20]
- Perplexity Pro : 45 % d’hallucinations dans le même test[20]
- Profil de risque unique : « cite de vraies sources avec des affirmations fabriquées » — les URL sont réelles, mais les informations attribuées sont inventées[21]
L’hallucination la plus dangereuse : celle que vous ne détectez pas
Les données révèlent un enseignement clé que la plupart des utilisateurs d’IA manquent : l’hallucination n’est pas un bug occasionnel — c’est une caractéristique fondamentale du fonctionnement de ces modèles. Les statistiques clés qui l’illustrent :
- 47 % des dirigeants ont agi sur la base de contenus IA hallucinés — ce qui signifie qu’environ la moitié des décisions métier informées par l’IA peuvent reposer sur des fondations fabriquées[1]
- 82 % des bugs IA proviennent d’hallucinations et d’échecs de précision, pas de plantages ou d’erreurs visibles — le système semble fonctionner parfaitement tout en délivrant des réponses erronées[27]
- 4,3 heures par semaine et par employé consacrées à vérifier les sorties de l’IA — et cela, parmi les organisations qui savent qu’il faut vérifier[28]
- Le coût moyen par incident majeur d’hallucination varie de 18 000 $ en service client à 2,4 millions de dollars en faute médicale[1]
Ressources de données téléchargeables
Trois fichiers CSV ont été préparés comme bases de données brutes pour le développement de contenu :
- ai_hallucination_data.csv — Taux d’hallucinations complets, modèle par modèle, sur l’ensemble des benchmarks
- domain_hallucination_rates.csv — Taux par domaine pour les meilleurs modèles vs l’ensemble des modèles
- business_impact_data.csv — 22 indicateurs clés d’impact métier avec sources et années
Glossaire des définitions clés
| Terme | Définition |
| Hallucination | Contenu généré par l’IA factuellement incorrect ou fabriqué, présenté avec assurance |
| Hallucination ancrée | Fausse information introduite lors de la synthèse d’un document fourni |
| Hallucination factuelle | Faits, statistiques ou citations fabriqués sans fondement dans la réalité |
| RAG (Retrieval Augmented Generation) | Technique qui connecte l’IA à des bases de connaissances externes pour réduire les hallucinations ; réduit les taux d’environ 71 % [4] |
| HHEM (Hughes Hallucination Evaluation Model) | Modèle de Vectara pour détecter les hallucinations dans les synthèses (score 0-1, en dessous de 0,5 = hallucination) [8] |
| Indice d’omniscience | Métrique AA-Omniscience (-100 à +100) qui récompense les réponses correctes et pénalise les réponses fausses données avec assurance [6] |
| Taux de cohérence factuelle | 100 % moins le taux d’hallucinations — le pourcentage de sorties fidèles au matériau source |
| Taxe du raisonnement | Phénomène observé où les modèles « réfléchissants » hallucinent davantage sur des tâches ancrées [15] |
| Flagornerie | Tendance du modèle à être d’accord avec l’utilisateur même lorsque l’utilisateur a tort |
| Effondrement du modèle | Dégradation progressive de la qualité lorsque les modèles sont entraînés sur du contenu généré par l’IA |
Synthèse des sources
Principaux benchmarks et études référencés :
- Classement Vectara HHEM (jeux de données original et mis à jour, 2023-2026)[10][12][13]
- Benchmark AA-Omniscience d’Artificial Analysis (novembre 2025)[5][6]
- Rapport AllAboutAI sur les hallucinations 2026 (analyse sectorielle complète)[4]
- Columbia Journalism Review — étude sur la précision des citations (mars 2025)[20][17]
- Stanford RegLab/HAI — étude sur les hallucinations juridiques[25][9]
- Deloitte Global Survey sur la prise de décision IA en entreprise[26]
- Forrester Research sur l’impact économique de l’atténuation des hallucinations[26]
- Gartner AI Market Analysis sur la croissance du marché des outils de détection[26]
- MedRxiv 2025 — étude sur les hallucinations dans des cas médicaux[23]
- International Journal of Data Science and Analytics — hallucinations IA en finance[17]
- ECRI — rapport 2025 sur les dangers des technologies de santé[24]
- Reuters — couverture des incidents juridiques liés à l’IA[31]
- Business Insider — base de données des affaires judiciaires d’hallucinations IA[30]
- VinciWorks — analyse de la crise des citations juridiques de juillet 2025[29]





