



Zusammenfassung
KI-Halluzinationen – Fälle, in denen Modelle falsche oder erfundene Informationen mit voller Überzeugung generieren – stellen eines der kritischsten und dennoch am meisten unterschätzten Risiken in der heutigen KI-gestützten Geschäftswelt dar. Die nachfolgenden Daten verdeutlichen das Ausmaß. Sie zeigen auch, dass kein Modell immun ist, weshalb Halluzinationsminderung durch Multi-Modell-Verifizierung zu einer strukturellen Anforderung wird, nicht zu einer optionalen Schutzmaßnahme.
Dieser Bericht kompiliert statistische Rohdaten aus mehreren maßgeblichen Benchmarks, Branchenstudien und Echtzeitvorfallverfolgung als inhaltliche Grundlage.
Die Kernzahlen sind erschütternd:
- Globale Geschäftsverluste durch KI-Halluzinationen erreichten allein 2024 67,4 Milliarden US-Dollar[1][2]
- 47 % der Führungskräfte haben wichtige Entscheidungen auf Basis unverifizierter KI-generierter Inhalte getroffen[3][1]
- Selbst die besten KI-Modelle halluzinieren bei einfachen Zusammenfassungsaufgaben noch mindestens 0,7 % der Zeit – und die Raten steigen auf 18,7 % bei juristischen Fragen und 15,6 % bei medizinischen Anfragen[4]
- Bei schwierigen Wissensfragen halluzinieren alle bis auf drei von 40 getesteten Modellen häufiger, als sie eine korrekte Antwort geben[5][6]
Was ist eine KI-Halluzination? (Technische Definition + Verständliche Erklärung)
Verständliche Erklärung
Eine KI-Halluzination entsteht, wenn ein KI-Modell sich etwas ausdenkt und dabei sehr überzeugend wirkt. Es sagt nicht „Ich weiß es nicht“ – stattdessen präsentiert es erfundene Fakten, ausgedachte Statistiken, falsche Gerichtsfälle oder nicht existierende medizinische Studien, als wären sie real. Die Antwort klingt autoritativ und liest sich perfekt. Genau das macht sie gefährlich.[7]
Technische Definition
In technischer Hinsicht bezeichnet Halluzination generierte Ausgaben, die nicht in den bereitgestellten Eingabedaten oder der faktischen Realität verankert sind. Es gibt zwei Haupttypen:
- Intrinsische Halluzination (auch „Faithfulness-Halluzination“ genannt): Das Modell widerspricht Informationen, die in seinem Ausgangsmaterial ausdrücklich enthalten sind. Zum Beispiel fügt es beim Zusammenfassen Fakten hinzu, die im Originaldokument nicht vorkommen.[8]
- Extrinsische Halluzination (auch „Factuality-Halluzination“ genannt): Das Modell erzeugt Informationen, die sich anhand keiner bekannten Quelle verifizieren lassen – es erfindet Fakten, Zitate, Statistiken oder Ereignisse aus dem Nichts.[9]
Eine zentrale technische Erkenntnis aus MIT-Forschung (Januar 2025): Wenn KI-Modelle halluzinieren, verwenden sie tendenziell selbstbewusstere Sprache als bei faktischen Informationen. Modelle nutzten mit 34 % höherer Wahrscheinlichkeit Formulierungen wie „definitiv“, „sicherlich“ und „ohne Zweifel“, wenn sie falsche Informationen erzeugten.[4]
Das ist das zentrale Paradoxon: Je falscher die KI liegt, desto sicherer klingt sie.
Warum es passiert
LLMs sind im Kern Vorhersage-Engines, keine Wissensdatenbanken. Sie erzeugen Text, indem sie auf Basis von Mustern aus Trainingsdaten das statistisch wahrscheinlichste nächste Wort vorhersagen. Sie „verstehen“ Wahrheit nicht – sie sagen Plausibilität voraus. Trifft das Modell auf eine Lücke in seinen Trainingsdaten oder eine mehrdeutige Anfrage, füllt es diese Lücke eher mit plausibel klingender Erfindung, statt Unsicherheit einzugestehen.[1]
Benchmark 1: Vectara Hallucination Leaderboard (HHEM)
Was es misst
Das Vectara Hughes Hallucination Evaluation Model (HHEM) Leaderboard ist der am häufigsten zitierte Halluzinations-Benchmark der Branche. Es misst Grounded Hallucination – wie oft ein LLM beim Zusammenfassen eines Dokuments, das ihm ausdrücklich gegeben wurde, falsche Informationen einführt. Man kann es so verstehen: „Hält sich das Modell an das, was direkt vor ihm steht?“[10][8]
KI-Halluzinations-Benchmarks (Live-Tabelle) mit Vectara Hughes Hallucination Evaluation Model (HHEM) Leaderboard.
Die Methodik: Über 1.000 Dokumente werden jedem Modell mit der Anweisung gegeben, ausschließlich die Fakten im Dokument zu verwenden. Vectaras HHEM-Modell prüft dann jede Zusammenfassung gegen die Quelle, um erfundene Behauptungen zu identifizieren.[10]
Warum das für Geschäftsanwender wichtig ist
Dies ist direkt analog dazu, wie KI in RAG-Systemen (Retrieval Augmented Generation) eingesetzt wird – dem Rückgrat von Unternehmens-KI-Suche, Kundensupport-Bots und Dokumentenanalysetools. Wenn ein Modell bei der Zusammenfassung halluziniert, wird es auch bei der Beantwortung von Fragen aus der Wissensdatenbank Ihres Unternehmens halluzinieren.[10]
Halluzinationsraten – Originaldatensatz (April 2025)
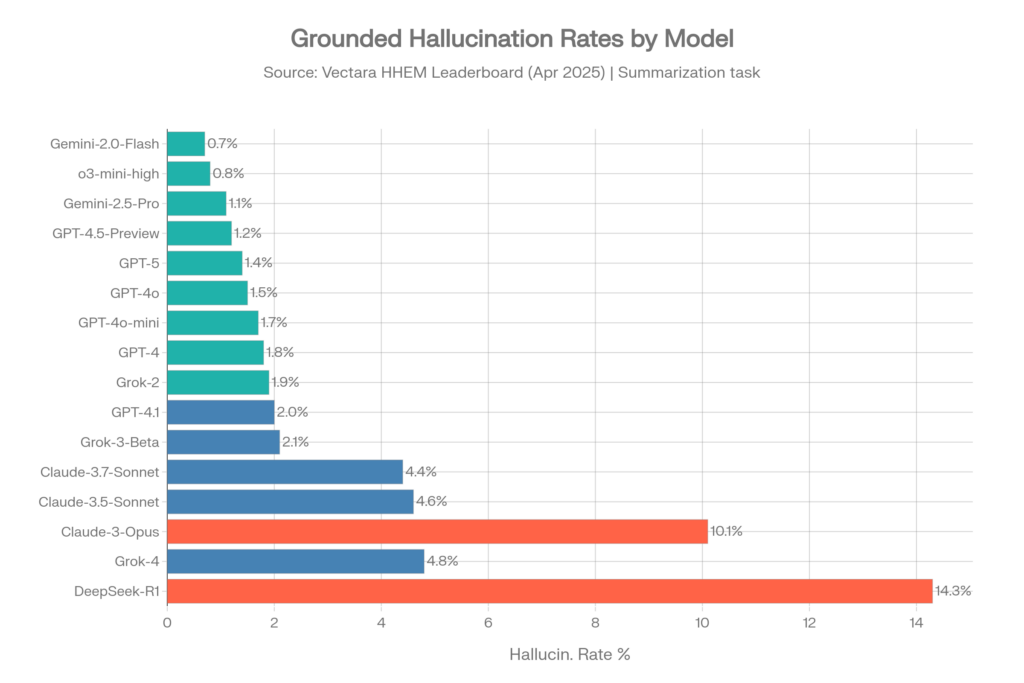
Dieser Datensatz von ~1.000 Dokumenten war bis Mitte 2025 der Standard-Benchmark.[10]
| Modell | Anbieter | Halluz.-Rate | Faktische Konsistenz |
| Gemini-2.0-Flash-001 | 0.7% | 99.3% | |
| Gemini-2.0-Pro-Exp | 0.8% | 99.2% | |
| o3-mini-high | OpenAI | 0.8% | 99.2% |
| Gemini-2.5-Pro-Exp | 1.1% | 98.9% | |
| GPT-4.5-Preview | OpenAI | 1.2% | 98.8% |
| Gemini-2.5-Flash-Preview | 1.3% | 98.7% | |
| o1-mini | OpenAI | 1.4% | 98.6% |
| GPT-5 / ChatGPT-5 | OpenAI | 1.4% | 98.6% |
| GPT-4o | OpenAI | 1.5% | 98.5% |
| GPT-4o-mini | OpenAI | 1.7% | 98.3% |
| GPT-4-Turbo | OpenAI | 1.7% | 98.3% |
| GPT-4 | OpenAI | 1.8% | 98.2% |
| Grok-2 | xAI | 1.9% | 98.1% |
| GPT-4.1 | OpenAI | 2.0% | 98.0% |
| Grok-3-Beta | xAI | 2.1% | 97.8% |
| Claude-3.7-Sonnet | Anthropic | 4.4% | 95.6% |
| Claude-3.5-Sonnet | Anthropic | 4.6% | 95.4% |
| Claude-3.5-Haiku | Anthropic | 4.9% | 95.1% |
| Grok-4 | xAI | 4.8% | ~95,2 % |
| Llama-4-Maverick | Meta | 4.6% | 95.4% |
| Claude-3-Opus | Anthropic | 10.1% | 89.9% |
| DeepSeek-R1 | DeepSeek | 14.3% | 85.7% |
Quelle: Vectara HHEM Leaderboard, GitHub-Repository, April 2025[10]
Wichtigste Erkenntnisse aus Vectara (alter Datensatz)
- Google Gemini-Modelle dominieren die Spitzenplätze, mit Gemini-2.0-Flash an der Spitze bei 0,7 %[4]
- OpenAI ist durchweg stark in der gesamten GPT-4-Familie, mit Werten zwischen 0,8 % und 2,0 %[10]
- Grok-4 mit 4,8 % liegt deutlich höher als seine GPT- und Gemini-Konkurrenten – fast das 7-fache der Halluzinationsrate des besten Gemini-Modells[11]
- Claude-Modelle zeigen eine überraschende Streuung: Claude-3.7-Sonnet mit 4,4 % ist respektabel, aber Claude-3-Opus mit 10,1 % ist besorgniserregend hoch[10]
- Das o3-mini-high-Reasoning-Modell von OpenAI erreichte 0,8 %, was zeigt, dass Reasoning-Fähigkeiten tatsächlich die faktische Verankerung verbessern können[10]
Halluzinationsraten – Neuer Datensatz (November 2025 – Februar 2026)
Vectara startete Ende 2025 einen vollständig überarbeiteten Benchmark mit 7.700 Artikeln (gegenüber 1.000), längeren Dokumenten (bis zu 32.000 Token) und komplexeren Inhalten aus Recht, Medizin, Finanzen, Technologie und Bildung.[12]
Die Ergebnisse sind dramatisch höher – absichtlich. Dieser Benchmark spiegelt reale Unternehmensarbeitslasten besser wider.[12]
| Modell | Anbieter | Halluz.-Rate |
| Gemini-2.5-Flash-Lite | 3.3% | |
| Mistral-Large | Mistral | 4.5% |
| DeepSeek-V3.2-Exp | DeepSeek | 5.3% |
| GPT-4.1 | OpenAI | 5.6% |
| Grok-3 | xAI | 5.8% |
| DeepSeek-R1-0528 | DeepSeek | 7.7% |
| Claude Sonnet 4.5 | Anthropic | >10% |
| GPT-5 | OpenAI | >10% |
| Grok-4 | xAI | >10% |
| Gemini-3-Pro | 13.6% |
Quelle: Vectara Hallucination Leaderboard, neuer Datensatz, November 2025[13][12]
Die Entdeckung der „Reasoning Tax“
Vectaras aktualisiertes Leaderboard zeigte eine entscheidende Erkenntnis: Reasoning-/Thinking-Modelle schneiden bei grounded Summaries tatsächlich schlechter ab. Modelle wie GPT-5, Claude Sonnet 4.5, Grok-4 und Gemini-3-Pro – die als starke „Reasoner“ vermarktet werden – lagen beim schwierigeren Benchmark alle über 10 % Halluzinationsrate.[12][14][15]
Die Hypothese: Reasoning-Modelle investieren Rechenaufwand in das „Durchdenken“ von Antworten, was sie manchmal dazu bringt, zu überdenken und vom Ausgangsmaterial abzuweichen, statt sich schlicht an den bereitgestellten Text zu halten. Das ist ein wichtiger Vorbehalt für Enterprise-RAG-Anwendungen.[15]
Benchmark 2: AA-Omniscience (Artificial Analysis)
Was es misst
Im November 2025 veröffentlicht, ist AA-Omniscience ein Wissens- und Halluzinations-Benchmark mit 6.000 Fragen über 42 Themen in 6 Bereichen: Wirtschaft, Geistes- und Sozialwissenschaften, Gesundheit, Recht, Softwareentwicklung und Naturwissenschaften/Mathematik.[5][6]
Im Gegensatz zu traditionellen Benchmarks, die einfach nur richtige Antworten zählen, bestraft der Omniscience Index falsche Antworten – das heißt, ein Modell, das falsch rät, wird härter bestraft als eines, das „Ich weiß es nicht“ zugibt. Die Skala reicht von -100 bis +100.[6]
Warum dieser Benchmark anders ist (und beängstigend)
Die meisten KI-Benchmarks belohnen Modelle dafür, jede Frage zu beantworten, was Raten begünstigt. AA-Omniscience dreht das um: Es fragt „weiß das Modell, wann es etwas nicht weiß?“ Die Antwort lautet bei den meisten Modellen nein.[6]
Ergebnisse
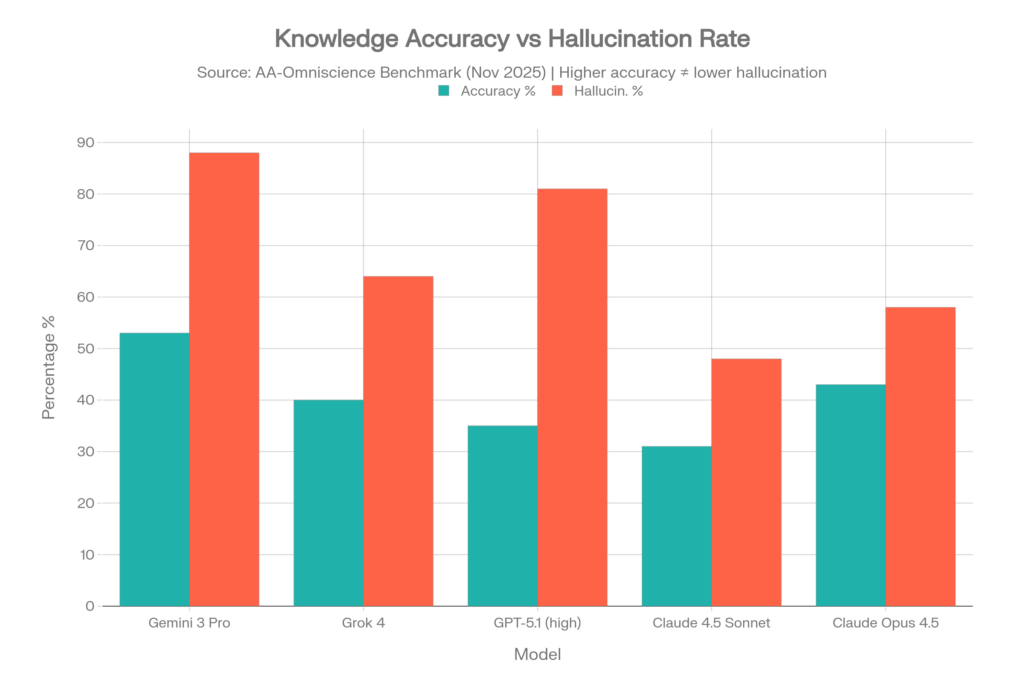
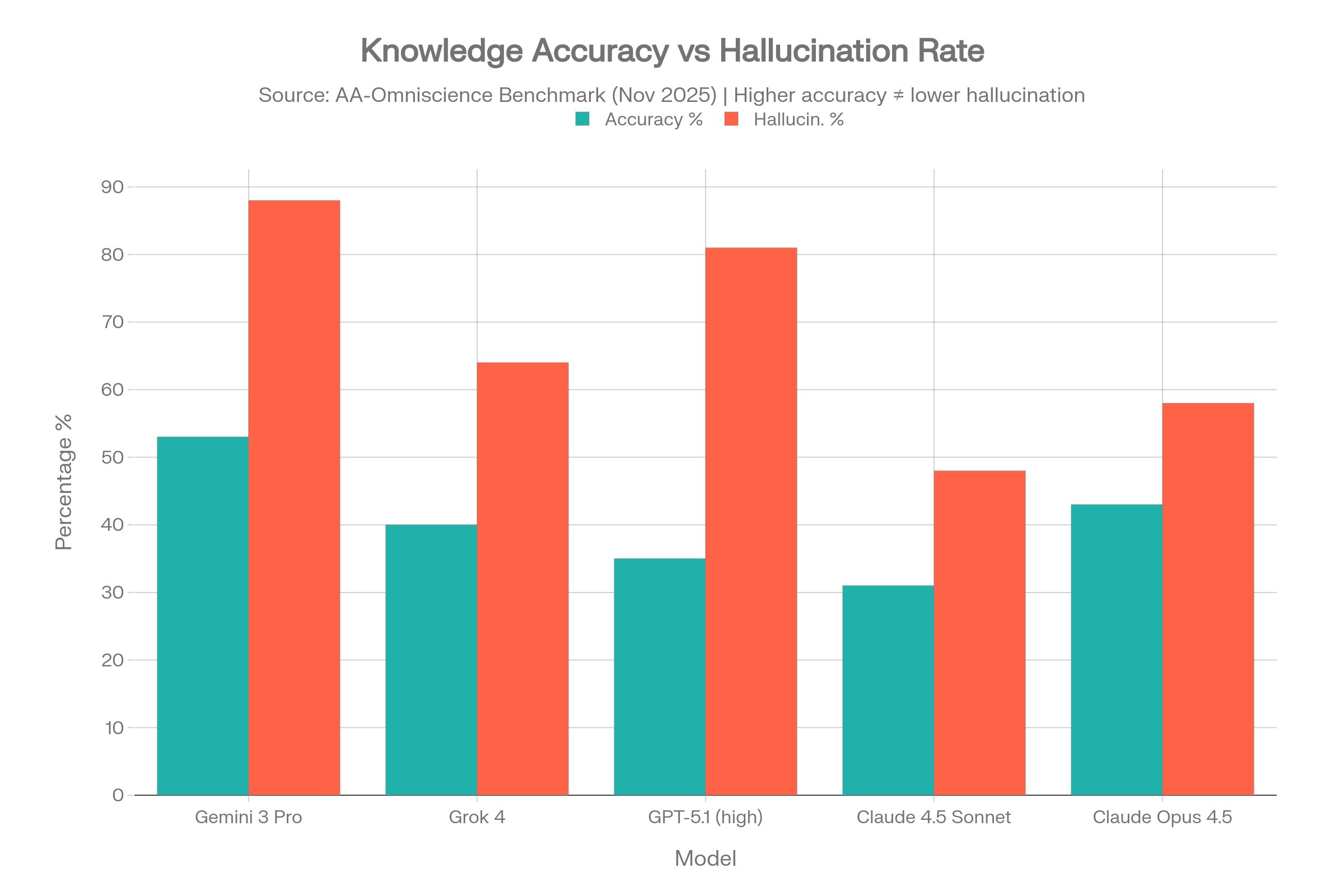
Von 40 getesteten Modellen erreichten nur VIER einen positiven Omniscience Index – das bedeutet, 36 von 40 Modellen geben bei schwierigen Wissensfragen eher eine überzeugte falsche Antwort als eine korrekte.[5][6]
| Modell | Genauigkeit | Halluz.-Rate* | Omniscience Index |
| Gemini 3 Pro | 53% | 88% | 13 |
| Claude 4.1 Opus | 36% | Niedrig (beste) | 4.8 |
| GPT-5.1 (hoch) | 35-39% | 51-81% | Positiv |
| Grok 4 | 40% | 64% | Positiv |
| Claude 4.5 Sonnet | 31% | 48% | Negativ |
| Claude 4.5 Haiku | — | 26 % (niedrigste) | Negativ |
| Claude Opus 4.5 | 43% | 58% | Negativ |
| Grok 4.1 Fast | — | 72% | Negativ |
| Kimi K2 0905 | — | 69% | Negativ |
| Kimi K2 Thinking | — | 74% | Negativ |
| DeepSeek V3.2 Ex | — | 81% | Negativ |
| DeepSeek R1 0528 | — | 83% | Negativ |
| Llama 4 Maverick | — | 87.58% | Negativ |
Halluzinationsrate hier = Anteil falscher Antworten an allen falschen Versuchen (Übersicherheitsmetrik)
Quelle: Artificial Analysis AA-Omniscience Benchmark, November 2025[16][5]
Domänenspezifische Leader
Kein einzelnes Modell dominiert alle Wissensbereiche:[5]
| Domäne | Bestes Modell |
| Recht | Claude 4.1 Opus |
| Softwareentwicklung | Claude 4.1 Opus |
| Geisteswissenschaften | Claude 4.1 Opus |
| Wirtschaft | GPT-5.1.1 |
| Gesundheit | Grok 4 |
| Naturwissenschaften | Grok 4 |
Das Gemini 3 Pro Paradoxon
Gemini 3 Pro erreichte mit 53 % die höchste Genauigkeit mit großem Abstand – zeigte aber auch eine 88 % Halluzinationsrate. Das bedeutet, dass es, wenn es eine Antwort nicht kennt, in 88 % der Fälle eine erfindet, anstatt Unsicherheit zuzugeben. Hohe Genauigkeit + hohe Halluzination = ein Modell, das viel weiß, aber ständig über das lügt, was es nicht weiß.[5]
Die Grok-Geschichte
Grok 4 liegt bei einer 64 % Halluzinationsrate bei AA-Omniscience, und sein neueres Geschwistermodell Grok 4.1 Fast ist mit 72 % sogar schlechter. Beim Vectara-Benchmark für verankerte Zusammenfassungen kam Grok-4 auf 4,8 % – fast das 7-fache des besten Gemini-Modells. Und in einer Studie des Columbia Journalism Review zur Genauigkeit von Nachrichtenzitaten halluzinierte Grok-3 erschreckende 94 % der Zeit.[16][11][17]
xAI behauptet, Grok 4.1 halluziniere „dreimal seltener als frühere Grok-Modelle“, und eine separate Analyse von Clarifai deutet darauf hin, dass die Halluzinationsraten durch Trainingsverbesserungen von ~12 % auf ~4 % gesunken seien. Die AA-Omniscience-Daten erzählen jedoch eine andere Geschichte, wenn die Fragen schwierig werden.[18][19]
Benchmark 3: Columbia Journalism Review Zitierstudie
Eine Studie des Columbia Journalism Review vom März 2025 testete KI-Modelle auf ihre Fähigkeit, Nachrichtenquellen korrekt zu zitieren. Die Ergebnisse waren alarmierend:[20][17]
| Modell | Halluzinationsrate |
| Perplexity | 37% |
| Copilot | 40% |
| Perplexity Pro | 45% |
| ChatGPT | 67% |
| DeepSeek | 68% |
| Gemini | 76% |
| Grok-2 | 77% |
| Grok-3 | 94% |
Quelle: Columbia Journalism Review, März 2025, via 5GWorldPro/Groundstone AI[17][20]
Diese Studie ist besonders relevant für Perplexity-/Sonar-Nutzer: Obwohl Perplexity in diesem Test am „besten“ abschnitt, bedeutet eine Halluzinationsrate von 37 % bei Zitieraufgaben, dass mehr als jede dritte zitierte Quelle erfundene Behauptungen enthalten kann. Eine separate Analyse stellte fest, dass Perplexitys größtes Problem darin besteht, dass es „reale Quellen mit erfundenen Behauptungen zitiert“ – die URLs wirken echt, aber die diesen Quellen zugeschriebenen Informationen sind ausgedacht.[21]
Benchmark 4: Finanz-Halluzinationsraten
Eine 2025 im International Journal of Data Science and Analytics veröffentlichte Studie testete KI-Chatbots speziell auf Finanzliteratur-Referenzen:[17]
| Modell | Halluzinationsrate (Finanzen) |
| ChatGPT-4o | 20.0% |
| GPT o1-preview | 21.3% |
| Gemini Advanced | 76.7% |
Weitere Erkenntnisse zu KI im Finanzwesen:[22]
- 78 % der Finanzdienstleistungsunternehmen setzen jetzt KI für Datenanalyse ein
- Finanz-KI-Aufgaben zeigen 15–25 % Halluzinationsraten ohne Schutzmaßnahmen
- Unternehmen melden 2,3 signifikante KI-bedingte Fehler pro Quartal
- Kosten pro Vorfall reichen von 50.000 bis 2,1 Millionen US-Dollar
- 67 % der VC-Firmen nutzen KI für Deal-Screening; durchschnittliche Fehlerentdeckungszeit beträgt 3,7 Wochen – oft zu spät
- Die Halluzination eines Robo-Advisors betraf 2.847 Kundenportfolios und kostete 3,2 Millionen US-Dollar an Sanierungskosten
Fachspezifische Halluzinationsraten
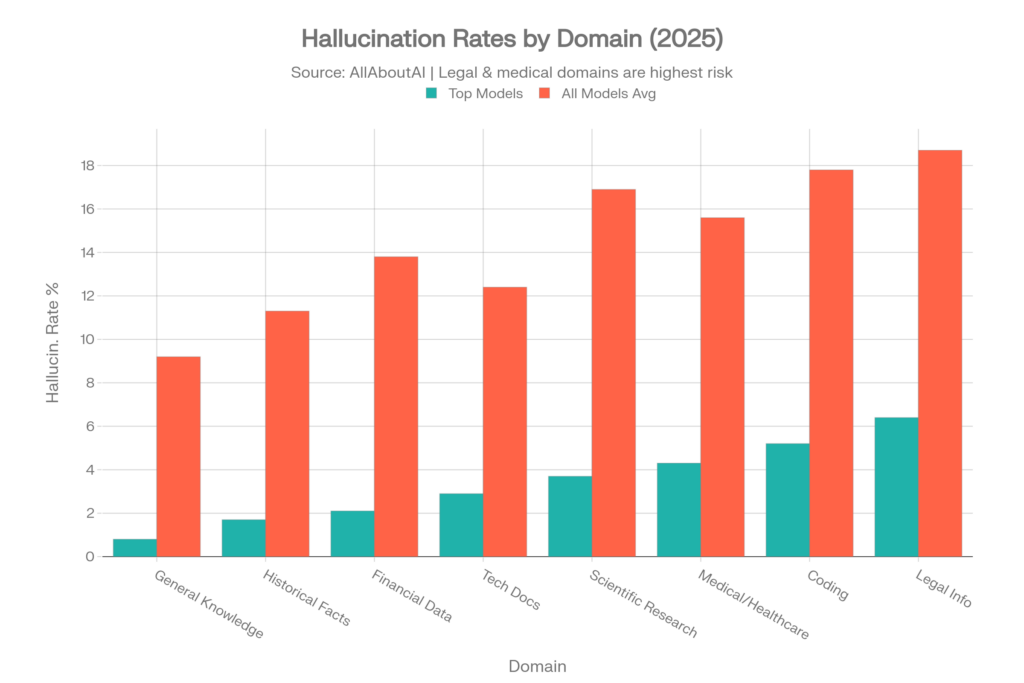
Selbst die leistungsstärksten Modelle zeigen je nach Themengebiet dramatisch unterschiedliche Halluzinationsraten. Diese Daten von AllAboutAI sind entscheidend für das Verständnis des Risikos nach Anwendungsfall:[4]
| Wissensbereich | Top-Modelle Rate | Durchschnitt aller Modelle |
| Allgemeinwissen | 0.8% | 9.2% |
| Historische Fakten | 1.7% | 11.3% |
| Finanzdaten | 2.1% | 13.8% |
| Technische Dokumentation | 2.9% | 12.4% |
| Wissenschaftliche Forschung | 3.7% | 16.9% |
| Medizin/Gesundheitswesen | 4.3% | 15.6% |
| Coding & Programmierung | 5.2% | 17.8% |
| Rechtliche Informationen | 6.4% | 18.7% |
Medizinische Halluzination – Detailanalyse
Eine 2025 in MedRxiv veröffentlichte Studie analysierte 300 von Ärzten validierte klinische Vignetten:[23]
- Ohne Minderungs-Prompts: 64,1 % Halluzinationsrate bei langen Fällen, 67,6 % bei kurzen Fällen
- Mit Minderungs-Prompts: sank auf 43,1 % bzw. 45,3 % (33 % Reduktion)
- GPT-4o war der beste Performer: sank von 53 % auf 23 % mit Minderung
- Open-Source-Modelle: überschritten 80 % Halluzinationsrate in medizinischen Szenarien
Selbst bei der besten medizinischen Halluzinationsrate von 23 % enthält fast jede vierte medizinische KI-Antwort erfundene Informationen. ECRI, eine globale gemeinnützige Organisation für Gesundheitssicherheit, führte KI-Risiken als Gesundheitstechnologie-Gefahr Nr. 1 für 2025 auf.[24]
Juristische Halluzination – Detailanalyse
Die Stanford RegLab/HAI-Studie zu juristischen Halluzinationen bleibt die maßgebliche Forschung:[25][9]
- LLMs halluzinieren bei spezifischen juristischen Anfragen zwischen 69 % und 88 % der Zeit
- Bei Fragen zur Kernentscheidung eines Gerichts halluzinieren Modelle mindestens 75 % der Zeit
- Modelle fehlt oft Selbstwahrnehmung über ihre Fehler und sie verstärken falsche juristische Annahmen
- Je komplexer die juristische Anfrage, desto höher die Halluzinationsrate
- 83 % der Juristen sind auf erfundene Rechtsprechung gestoßen, als sie KI nutzten[26]
Reale Geschäftsauswirkungen: Die Zahlen
Das 67,4-Milliarden-Dollar-Problem
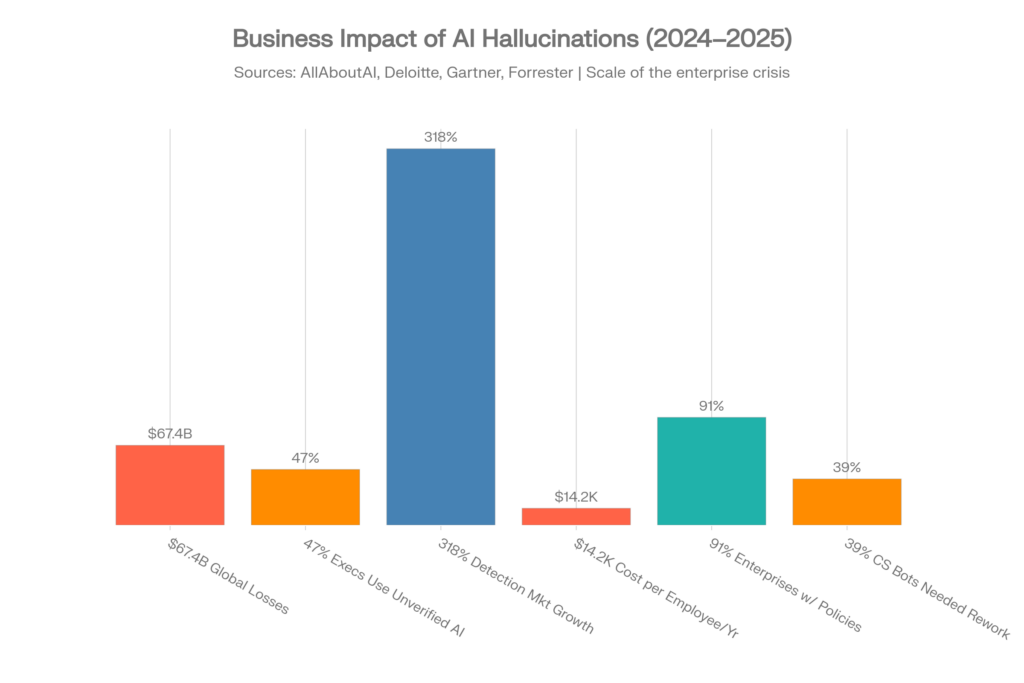
Globale Geschäftsverluste, die KI-Halluzinationen zugeschrieben werden, erreichten 2024 67,4 Milliarden US-Dollar. Diese Zahl stammt aus der umfassenden AllAboutAI-Studie und repräsentiert dokumentierte direkte und indirekte Kosten von Unternehmen, die sich auf ungenaue KI-generierte Inhalte verlassen.[1][2]
Wichtigste Statistiken zu Geschäftsauswirkungen
| Metrik | Wert | Quelle |
| Globale Verluste durch KI-Halluzinationen (2024) | 67,4 Milliarden US-Dollar | AllAboutAI, 2025 [1] |
| Führungskräfte, die unverifizierte KI-Erkenntnisse nutzen | 47% | Deloitte, 2025 [1] |
| KI-Fehler durch Halluzinationen/Genauigkeitsfehler | 82% | Testlio, 2025 [27] |
| Kundenservice-Bots, die Überarbeitung benötigen | 39% | Testlio, 2024 [3] |
| SEC-Bußgelder für KI-Falschdarstellungen | 12,7 Millionen US-Dollar | Branchenberichte [3] |
| Unternehmen mit Vertrauensverlusten bei Investoren | 54% | Branchenberichte [3] |
| Kosten pro Mitarbeiter für Halluzinationsminderung | 14.200 US-Dollar/Jahr | Forrester, 2025 [26][28] |
| Mitarbeiterzeit zur Verifizierung von KI-Inhalten | 4,3 Stunden/Woche | Forbes/AllAboutAI [28] |
| Marktwachstum für Halluzinationserkennungstools | 318% (2023-2025) | Gartner, 2025 [26] |
| Unternehmens-KI-Richtlinien mit Halluzinationsprotokollen | 91% | AllAboutAI, 2025 [26] |
| Gesundheitsorganisationen, die KI-Einführung verzögern | 64% | AllAboutAI, 2025 [26] |
| Investitionen in halluzinationsspezifische Lösungen | 12,8 Milliarden US-Dollar | AllAboutAI, 2023–2025 [4] |
| RAG-Wirksamkeit bei Halluzinationsreduktion | 71% | AllAboutAI, 2025 [4] |
Das Produktivitätsparadoxon
Die grausamste Ironie: KI sollte uns produktiver machen. Stattdessen verbringen Mitarbeiter jetzt durchschnittlich 4,3 Stunden pro Woche – mehr als einen halben Arbeitstag – nur damit zu verifizieren, ob das, was die KI ihnen gesagt hat, tatsächlich wahr ist. Das sind ungefähr 14.200 US-Dollar pro Mitarbeiter pro Jahr an reinem Verifizierungs-Overhead. Für ein Unternehmen mit 500 Mitarbeitern, die KI-Tools nutzen, sind das 7,1 Millionen US-Dollar jährlich, die nur für die Überprüfung der KI-Hausaufgaben ausgegeben werden.[26][28]
Rechtsvorfälle: Die Gerichtssaalkrise
Die Zahlen werden schlechter, nicht besser
Trotz wachsenden Bewusstseins beschleunigen sich KI-Halluzinationen in Rechtsschriften:[29][30]
- 2023: 10 dokumentierte Gerichtsurteile mit KI-Halluzinationen
- 2024: 37 dokumentierte Urteile
- Erste 5 Monate 2025: 73 dokumentierte Urteile
- Allein Juli 2025: 50+ Fälle mit gefälschten Zitaten
Der Rechtsforscher Damien Charlotin führt eine öffentliche Datenbank von 120+ Fällen, in denen Gerichte KI-halluzinierte Zitate, erfundene Fälle oder gefälschte Rechtszitate fanden.[30]
Wer macht diese Fehler?
Die Verschiebung von Amateur zu Profi ist alarmierend:[30]
- 2023: 7 von 10 Halluzinationsfällen stammten von Selbstvertretern, 3 von Anwälten
- Mai 2025: 13 von 23 entdeckten Fällen waren die Schuld von Anwälten und Juristen
Bemerkenswerte Fälle
- Johnson v. Dunn: Anwälte reichten zwei Anträge mit gefälschten Rechtsquellen ein, die von ChatGPT generiert wurden. Ergebnis: 51-seitige Sanktionsanordnung, öffentlicher Verweis, Disqualifikation vom Fall, Überweisung an Zulassungsbehörden[29]
- Morgan & Morgan (Feb. 2025): Eine der größten Personenschadenskanzleien Amerikas sandte eine dringende Warnung an 1.000+ Anwälte, nachdem ein Bundesrichter in Wyoming Sanktionen wegen gefälschter KI-generierter Zitate in einer Walmart-Klage androhte[31]
- Gerichte haben in mindestens fünf Fällen Geldsanktionen von 10.000 $ oder mehr verhängt, vier davon im Jahr 2025[30]
- Fälle wurden in den USA, im Vereinigten Königreich, in Südafrika, Israel, Australien und Spanien dokumentiert[30]
Gesundheitswesen: Wo Halluzinationen töten können
Bedenken der FDA und zu Medizinprodukten
- Die FDA hat bis Ende 2025 1.357 KI-gestützte Medizinprodukte zugelassen – doppelt so viele wie Ende 2022[32]
- Forschung von Johns Hopkins, Georgetown und Yale ergab, dass 60 von der FDA zugelassene KI-Medizinprodukte in 182 Rückrufen involviert waren[32]
- 43 % dieser Rückrufe erfolgten innerhalb eines Jahres nach der Zulassung[32]
- Das Johnson & Johnson TruDi Navigation System (KI-gestütztes Gerät für Nasennebenhöhlen-Operationen) wurde mit mindestens 10 Verletzungen und 100 Fehlfunktionen in Verbindung gebracht, darunter Liquorlecks, Schädelperforationen und Schlaganfälle[33][32]
Medizinische KI-Fehlinformationen
Es wurde festgestellt, dass führende KI-Modelle manipulierbar sind und gefährlich falsche medizinische Ratschläge produzieren – etwa die Behauptung, Sonnencreme verursache Hautkrebs, oder die Verknüpfung von 5G mit Unfruchtbarkeit – inklusive erfundener Zitate aus Fachzeitschriften wie The Lancet.[4]
Historischer Trend: Fortschritt ist real, aber ungleichmäßig
Die gute Nachricht
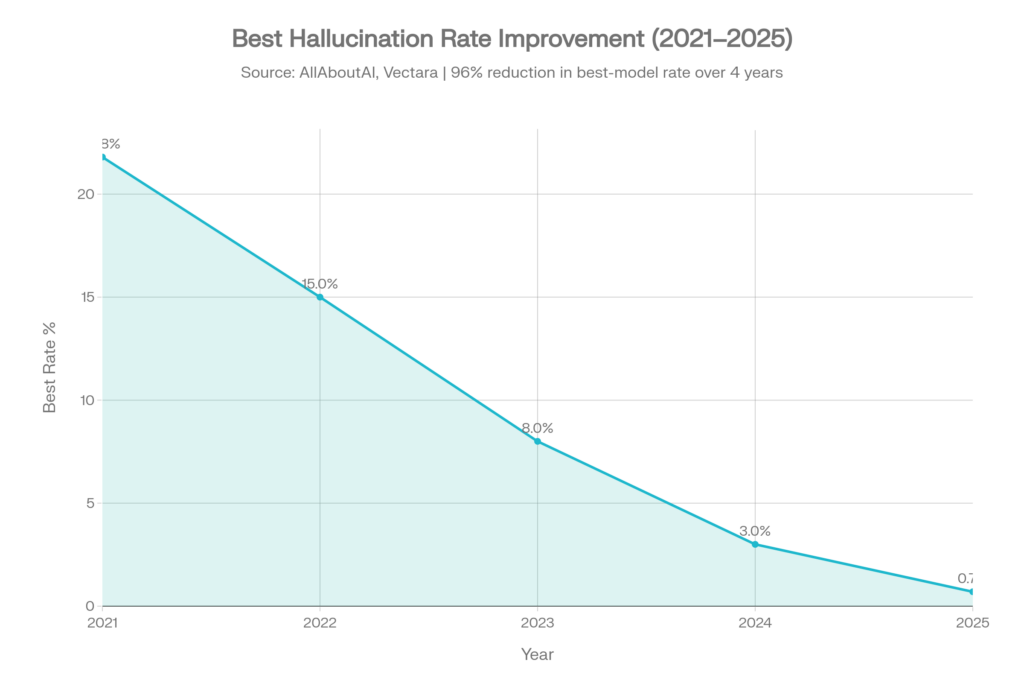
Die Halluzinationsraten der besten Modelle sind drastisch gesunken:[4]
| Jahr | Beste Halluzinationsrate | Kontext |
| 2021 | ~21,8 % | Frühe GPT-3-Ära |
| 2022 | ~15,0 % | Verbesserung durch RLHF |
| 2023 | ~8,0 % | GPT-4 und Wettbewerb |
| 2024 | ~3,0 % | Rasante Verbesserung |
| 2025 | 0.7% | Gemini-2.0-Flash führt |
Das entspricht einer Reduktion um 96 % bei den Halluzinationsraten der besten Modelle über vier Jahre.[4]
Die schlechte Nachricht
- Die Verbesserung ist je nach Anbieter ungleichmäßig. Einige Claude-Modelle wurden sogar schlechter: Claude 3 Sonnet stieg von 6,0 % auf 16,3 %, und Claude 2 verdoppelte sich nahezu von 8,5 % auf 17,4 % im Vectara-Benchmark über die Zeit.[23]
- Neue „schwierigere“ Benchmarks zeigen die Lücke zwischen einfachen Aufgaben und realer Komplexität. Auf Vectaras neuem Datensatz liegt selbst Gemini-3-Pro bei 13,6 %.[12]
- Die AA-Omniscience-Ergebnisse sind ernüchternd: Bei wirklich schwierigen Fragen halluzinieren 36 von 40 Modellen immer noch häufiger, als sie korrekt antworten.[6]
- Domänenspezifische Raten bleiben gefährlich hoch: Recht (18,7 % im Durchschnitt), Medizin (15,6 %) und Coding (17,8 %).[4]
Grok: Entwicklung
- Grok-1/2-Ära: Positioniert als stärker „personality-driven“ Modell mit weniger Fokus auf faktischer Verankerung
- Grok-3: Erreichte 2,1 % auf Vectaras altem Summarization-Benchmark (ordentlich), aber 94 % bei Zitiergenauigkeit im Test der Columbia Journalism Review[10][17]
- Grok-4: 4,8 % bei Vectara, 64 % bei AA-Omniscience (schwierige Fragen)[16][11]
- Grok 4.1: xAI behauptete „3x weniger Halluzinationen“, Clarifai schätzte eine Reduktion von ~12 % auf ~4 %, aber AA-Omniscience zeigte 72 % bei Grok 4.1 Fast (schlechter als Grok 4 mit 64 %)[18][19][16]
Die Inkonsistenz zwischen Benchmarks deutet darauf hin, dass Groks Verbesserungen eher aufgabenspezifisch als allgemein übertragbar sind.
Modell-für-Modell-Zusammenfassung für Suprmind.ai-Modelle
OpenAI-Modelle
| Modell | Vectara (Alt) | Vectara (Neu) | AA-Omniscience | Hinweise |
| GPT-5 / ChatGPT-5 | 1.4% | >10 % | — | Solide Verbesserung bei einfachen Aufgaben; Schwierigkeiten bei schweren [11] |
| GPT-5.1 (hoch) | — | — | 51–81 % Halluzinationen, 35 % Genauigkeit | Am besten für die Business-Domäne; positiver Omniscience Index [5] |
| GPT-4o | 1.5% | — | — | Arbeitstier-Modell, konstant gute Leistung [10] |
| o3-mini-high | 0.8% | — | — | Bestes OpenAI-Modell auf dem alten Vectara [10] |
Anthropic-Claude-Modelle
| Modell | Vectara (Alt) | Vectara (Neu) | AA-Omniscience | Hinweise |
| Claude 4.5 Sonnet | — | >10 % | 48 % Halluzinationen, 31 % Genauigkeit | Mittelfeld bei Wissensaufgaben [16] |
| Claude 4.5 Haiku | — | — | 26 % Halluzinationen (am niedrigsten!) | Bestes Unsicherheitsmanagement [16] |
| Claude Opus 4.5 | — | — | 58 % Halluzinationen, 43 % Genauigkeit | Gute Genauigkeit, aber hohe Überkonfidenz [16] |
| Claude 4.1 Opus | — | — | 4,8 Omniscience Index | Am besten in Recht, SW Engineering, Geisteswissenschaften [5] |
| Claude-3.7-Sonnet | 4.4% | — | — | Ordentlich bei Summarization [10] |
xAI-Grok-Modelle
| Modell | Vectara (Alt) | Vectara (Neu) | AA-Omniscience | Sonstiges |
| Grok 4 | 4.8% | >10 % | 64 % Halluzinationen, 40 % Genauigkeit | Am besten in Gesundheit & Wissenschaft; positiver Omniscience Index [11][16] |
| Grok 4.1 | — | — | 72 % Halluzinationen (Fast-Variante) | xAI behauptet 3x Verbesserung, Datenlage ist gemischt [16][19] |
| Grok 3 | 2.1% | 5.8% | — | 94 % im News-Citation-Test [17] |
Google-Gemini-Modelle
| Modell | Vectara (Alt) | Vectara (Neu) | AA-Omniscience | Hinweise |
| Gemini 3 Pro | — | 13.6% | 88 % Halluzinationen, 53 % Genauigkeit, Index: 13 | Höchste Genauigkeit, aber extreme Überkonfidenz [5][12] |
| Gemini 2.5-Pro | 1.1% | — | — | Stark auf dem alten Benchmark [10] |
| Gemini 2.5-Flash | 1.3% | — | — | [10] |
| Gemini 2.5-Flash-Lite | — | 3.3% | — | Am besten auf dem neuen Vectara-Benchmark [13] |
Perplexity / Sonar
- Kein direkter Vectara- oder AA-Omniscience-Eintrag für Perplexitys proprietäre Modelle
- Perplexity nutzt zugrunde liegende Modelle (historisch u. a. DeepSeek-R1, das bei Vectara ~14,3 % Halluzinationsrate hat)[34]
- Test der Columbia Journalism Review: Perplexity 37 % Halluzinationen bei Zitiergenauigkeit (bestes Ergebnis in diesem Test, aber immer noch 1 von 3)[20]
- Perplexity Pro: 45 % Halluzinationen im selben Test[20]
- Einzigartiges Risikoprofil: „zitiert reale Quellen mit erfundenen Behauptungen“ – die URLs sind echt, aber die zugeschriebenen Informationen sind erfunden[21]
Die gefährlichste Halluzination: Die, die Sie nicht bemerken
Die Daten zeigen eine entscheidende Erkenntnis, die die meisten KI-Nutzer übersehen: Halluzination ist kein gelegentlicher Bug – sie ist ein grundlegendes Merkmal der Funktionsweise dieser Modelle. Die wichtigsten Kennzahlen, die das verdeutlichen:
- 47 % der Führungskräfte haben auf halluzinierte KI-Inhalte reagiert – das heißt, ungefähr die Hälfte KI-gestützter Geschäftsentscheidungen könnte auf erfundenen Grundlagen beruhen[1]
- 82 % der KI-Bugs gehen auf Halluzinationen und Genauigkeitsfehler zurück, nicht auf Abstürze oder sichtbare Fehler – das System wirkt, als funktioniere es perfekt, liefert aber falsche Antworten[27]
- 4,3 Stunden pro Woche und Mitarbeitendem werden für die Verifizierung von KI-Output aufgewendet – und das in Organisationen, die wissen, dass sie prüfen müssen[28]
- Die durchschnittlichen Kosten pro größerem Halluzinationsvorfall reichen von 18.000 $ im Kundenservice bis zu 2,4 Mio. $ bei Behandlungsfehlern im Gesundheitswesen[1]
Herunterladbare Daten-Assets
Drei CSV-Dateien wurden als Rohdatenbasis für die Content-Erstellung vorbereitet:
- ai_hallucination_data.csv — Umfassende, modellweise Halluzinationsraten über alle Benchmarks hinweg
- domain_hallucination_rates.csv — Domänenspezifische Raten für Top-Modelle vs. alle Modelle
- business_impact_data.csv — 22 zentrale Business-Impact-Kennzahlen mit Quellen und Jahren
Glossar: Schlüsseldefinitionen
| Begriff | Definition |
| Halluzination | KI-generierter Inhalt, der faktisch falsch oder erfunden ist und mit hoher Sicherheit präsentiert wird |
| Grounded Hallucination | Falsche Informationen, die beim Zusammenfassen eines bereitgestellten Dokuments eingeführt werden |
| Factual Hallucination | Erfundene Fakten, Statistiken oder Zitate ohne Grundlage in der Realität |
| RAG (Retrieval Augmented Generation) | Technik, die KI mit externen Wissensdatenbanken verbindet, um Halluzinationen zu reduzieren; senkt die Raten um ~71 % [4] |
| HHEM (Hughes Hallucination Evaluation Model) | Vectaras Modell zur Erkennung von Halluzinationen in Zusammenfassungen (Score 0–1, unter 0,5 = Halluzination) [8] |
| Omniscience Index | AA-Omniscience-Metrik (-100 bis +100), die richtige Antworten belohnt und selbstbewusst falsche bestraft [6] |
| Factual Consistency Rate | 100 % minus Halluzinationsrate – der Anteil der Outputs, die dem Ausgangsmaterial treu bleiben |
| Reasoning Tax | Beobachtetes Phänomen, bei dem „Thinking“-Modelle bei grounded Aufgaben stärker halluzinieren [15] |
| Sycophancy | Tendenz eines Modells, dem Nutzer zuzustimmen, selbst wenn der Nutzer falsch liegt |
| Model Collapse | Fortschreitender Qualitätsverlust, wenn Modelle auf KI-generierten Inhalten trainiert werden |
Quellenübersicht
Wichtigste referenzierte Benchmarks und Studien:
- Vectara HHEM Leaderboard (ursprüngliche und aktualisierte Datensätze, 2023–2026)[10][12][13]
- AA-Omniscience Benchmark von Artificial Analysis (November 2025)[5][6]
- AllAboutAI Hallucination Report 2026 (umfassende Branchenanalyse)[4]
- Columbia Journalism Review-Studie zur Zitiergenauigkeit (März 2025)[20][17]
- Stanford RegLab/HAI-Studie zu juristischen Halluzinationen[25][9]
- Deloitte Global Survey zu KI-gestützter Entscheidungsfindung in Unternehmen[26]
- Forrester Research zu den wirtschaftlichen Auswirkungen von Halluzinationsminderung[26]
- Gartner AI Market Analysis zum Marktwachstum von Erkennungstools[26]
- MedRxiv 2025-Studie zu Halluzinationen medizinischer Fälle[23]
- International Journal of Data Science and Analytics zu finanziellen KI-Halluzinationen[17]
- ECRI 2025-Report zu Gefahren in der Gesundheitstechnologie[24]
- Reuters-Berichterstattung zu juristischen KI-Vorfällen[31]
- Business Insider-Datenbank zu Gerichtsverfahren mit KI-Halluzinationen[30]
- VinciWorks-Analyse der Krise um juristische Zitate im Juli 2025[29]





