



Resumen ejecutivo
Las alucinaciones de IA —casos en los que los modelos generan información falsa o inventada con total confianza— representan uno de los riesgos más críticos y, sin embargo, infravalorados en el panorama empresarial actual impulsado por la IA. Los datos siguientes dejan clara la magnitud. También dejan claro que ningún modelo es inmune, por lo que la mitigación de alucinaciones mediante verificación multimodelo se está convirtiendo en un requisito estructural, no en una salvaguarda opcional.
Este informe recopila datos estadísticos en bruto de múltiples benchmarks autorizados, estudios del sector y seguimiento de incidentes del mundo real para servir como base de contenido.
Las cifras principales son abrumadoras:
- Las pérdidas empresariales globales por alucinaciones de IA alcanzaron 67,4 mil millones de dólares en 2024 solo[1][2]
- El 47% de los directivos empresariales ha tomado decisiones importantes basándose en contenido generado por IA sin verificar[3][1]
- Incluso los mejores modelos de IA siguen alucinando al menos el 0,7% de las veces en tareas básicas de resumen, y las tasas se disparan hasta el 18,7% en preguntas legales y el 15,6% en consultas médicas[4]
- En preguntas difíciles de conocimiento, todos salvo tres de los 40 modelos probados tienen más probabilidades de alucinar que de dar una respuesta correcta[5][6]
¿Qué es una alucinación de IA? (Definición técnica + en lenguaje sencillo)
En lenguaje sencillo
Una alucinación de IA ocurre cuando un modelo de IA se inventa algo con seguridad. No dice «no lo sé», sino que presenta hechos inventados, estadísticas inventadas, casos legales falsos o estudios médicos inexistentes como si fueran reales. La respuesta suena autorizada y se lee perfectamente. Eso es lo que la hace peligrosa.[7]
Definición técnica
En términos técnicos, la alucinación se refiere a una salida generada que no está fundamentada en los datos de entrada proporcionados ni en la realidad factual. Hay dos tipos principales:
- Alucinación intrínseca (también llamada «alucinación de fidelidad»): el modelo contradice información proporcionada explícitamente en su material de origen. Por ejemplo, durante un resumen, añade hechos que no están presentes en el documento original.[8]
- Alucinación extrínseca (también llamada «alucinación de factualidad»): el modelo genera información que no puede verificarse con ninguna fuente conocida; inventa hechos, citas, estadísticas o eventos desde cero.[9]
Un hallazgo técnico crítico de una investigación del MIT (enero de 2025): cuando los modelos de IA alucinan, tienden a usar un lenguaje más seguro que cuando proporcionan información factual. Los modelos tenían un 34% más de probabilidades de usar expresiones como «definitivamente», «ciertamente» y «sin duda» al generar información incorrecta.[4]
Esta es la paradoja central: cuanto más se equivoca la IA, más segura suena.
Por qué sucede
Los LLM son, en esencia, motores de predicción, no bases de conocimiento. Generan texto prediciendo la siguiente palabra estadísticamente más probable en función de patrones aprendidos a partir de los datos de entrenamiento. No «entienden» la verdad: predicen plausibilidad. Cuando el modelo se encuentra con una laguna en sus datos de entrenamiento o se enfrenta a una consulta ambigua, rellena el hueco con una invención verosímil en lugar de admitir incertidumbre.[1]
Benchmark 1: clasificación de alucinaciones de Vectara (HHEM)
Qué mide
La clasificación Vectara Hughes Hallucination Evaluation Model (HHEM) es el benchmark de alucinaciones más citado del sector. Mide la alucinación fundamentada: con qué frecuencia un LLM introduce información falsa al resumir un documento que se le proporcionó explícitamente. Piénselo así: «¿Puede el modelo ceñirse a lo que tiene escrito delante?»[10][8]
Benchmarks de alucinaciones de IA (tabla en vivo) con la clasificación Vectara Hughes Hallucination Evaluation Model (HHEM) incluida.
La metodología: se entregan más de 1.000 documentos a cada modelo con instrucciones de resumir usando solo los hechos del documento. A continuación, el modelo HHEM de Vectara comprueba cada resumen frente a la fuente para identificar afirmaciones inventadas.[10]
Por qué es importante para usuarios empresariales
Esto es directamente análogo a cómo se usa la IA en sistemas RAG (Retrieval Augmented Generation), la columna vertebral de la búsqueda de IA empresarial, los bots de atención al cliente y las herramientas de análisis de documentos. Si un modelo alucina durante el resumen, alucinará al responder preguntas a partir de la base de conocimiento de su empresa.[10]
Tasas de alucinaciones — conjunto de datos original (abril de 2025)
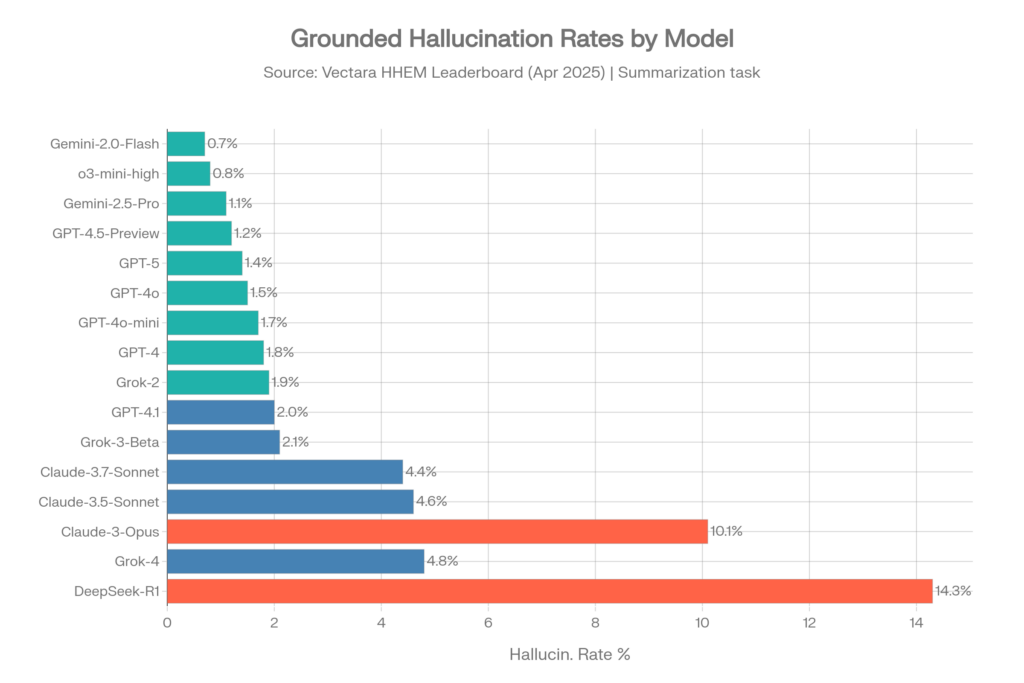
Este conjunto de datos de ~1.000 documentos fue el benchmark estándar hasta mediados de 2025.[10]
| Modelo | Proveedor | Tasa de alucin. | Consistencia fáctica |
| Gemini-2.0-Flash-001 | 0.7% | 99.3% | |
| Gemini-2.0-Pro-Exp | 0.8% | 99.2% | |
| o3-mini-high | OpenAI | 0.8% | 99.2% |
| Gemini-2.5-Pro-Exp | 1.1% | 98.9% | |
| GPT-4.5-Preview | OpenAI | 1.2% | 98.8% |
| Gemini-2.5-Flash-Preview | 1.3% | 98.7% | |
| o1-mini | OpenAI | 1.4% | 98.6% |
| GPT-5 / ChatGPT-5 | OpenAI | 1.4% | 98.6% |
| GPT-4o | OpenAI | 1.5% | 98.5% |
| GPT-4o-mini | OpenAI | 1.7% | 98.3% |
| GPT-4-Turbo | OpenAI | 1.7% | 98.3% |
| GPT-4 | OpenAI | 1.8% | 98.2% |
| Grok-2 | xAI | 1.9% | 98.1% |
| GPT-4.1 | OpenAI | 2.0% | 98.0% |
| Grok-3-Beta | xAI | 2.1% | 97.8% |
| Claude-3.7-Sonnet | Anthropic | 4.4% | 95.6% |
| Claude-3.5-Sonnet | Anthropic | 4.6% | 95.4% |
| Claude-3.5-Haiku | Anthropic | 4.9% | 95.1% |
| Grok-4 | xAI | 4.8% | ~95,2 % |
| Llama-4-Maverick | Meta | 4.6% | 95.4% |
| Claude-3-Opus | Anthropic | 10.1% | 89.9% |
| DeepSeek-R1 | DeepSeek | 14.3% | 85.7% |
Fuente: clasificación Vectara HHEM, repositorio de GitHub, abril de 2025[10]
Conclusiones clave de Vectara (conjunto de datos antiguo)
- Los modelos Google Gemini dominan los primeros puestos, con Gemini-2.0-Flash liderando con un 0,7%[4]
- OpenAI es consistentemente sólido en toda la familia GPT-4, con un rango del 0,8% al 2,0%[10]
- Grok-4 con un 4,8% es notablemente más alto que sus competidores GPT y Gemini: casi 7 veces la tasa de alucinaciones del mejor modelo Gemini[11]
- Los modelos Claude muestran una dispersión sorprendente: Claude-3.7-Sonnet con un 4,4% es respetable, pero Claude-3-Opus con un 10,1% es preocupantemente alto[10]
- El modelo de razonamiento o3-mini-high de OpenAI logró un 0,8%, lo que muestra que las capacidades de razonamiento pueden mejorar realmente la fundamentación factual[10]
Tasas de alucinaciones — nuevo conjunto de datos (noviembre de 2025 – febrero de 2026)
Vectara lanzó un benchmark completamente renovado a finales de 2025 con 7.700 artículos (frente a 1.000), documentos más largos (hasta 32K tokens) y contenido de mayor complejidad que abarca derecho, medicina, finanzas, tecnología y educación.[12]
Los resultados son drásticamente más altos, por diseño. Este benchmark refleja mejor las cargas de trabajo empresariales reales.[12]
| Modelo | Proveedor | Tasa de alucin. |
| Gemini-2.5-Flash-Lite | 3.3% | |
| Mistral-Large | Mistral | 4.5% |
| DeepSeek-V3.2-Exp | DeepSeek | 5.3% |
| GPT-4.1 | OpenAI | 5.6% |
| Grok-3 | xAI | 5.8% |
| DeepSeek-R1-0528 | DeepSeek | 7.7% |
| Claude Sonnet 4.5 | Anthropic | >10% |
| GPT-5 | OpenAI | >10% |
| Grok-4 | xAI | >10% |
| Gemini-3-Pro | 13.6% |
Fuente: clasificación de alucinaciones de Vectara, nuevo conjunto de datos, noviembre de 2025[13][12]
El descubrimiento del «impuesto del razonamiento»
La clasificación actualizada de Vectara reveló un hallazgo crítico: los modelos de razonamiento/pensamiento en realidad rinden peor en el resumen fundamentado. Modelos como GPT-5, Claude Sonnet 4.5, Grok-4 y Gemini-3-Pro —que se comercializan como fuertes «razonadores»— superaron todos el 10% de tasa de alucinaciones en el benchmark más difícil.[12][14][15]
La hipótesis: los modelos de razonamiento invierten esfuerzo computacional en «pensar» las respuestas, lo que a veces les lleva a sobrepensar y desviarse del material fuente en lugar de ceñirse simplemente al texto proporcionado. Esto es una advertencia importante para aplicaciones RAG empresariales.[15]
Benchmark 2: AA-Omniscience (Artificial Analysis)
Qué mide
Publicado en noviembre de 2025, AA-Omniscience es un benchmark de conocimiento y alucinaciones que cubre 6.000 preguntas en 42 temas dentro de 6 dominios: Negocios, Humanidades y Ciencias Sociales, Salud, Derecho, Ingeniería de Software y Ciencia/Matemáticas.[5][6]
A diferencia de los benchmarks tradicionales que simplemente cuentan respuestas correctas, el Índice de Omnisciencia penaliza las respuestas incorrectas, lo que significa que un modelo que adivina y falla es castigado con más dureza que uno que admite «no lo sé». La escala va de -100 a +100.[6]
Por qué este benchmark es diferente (y da miedo)
La mayoría de los benchmarks de IA recompensan a los modelos por intentar responder a todas las preguntas, lo que incentiva adivinar. AA-Omniscience invierte esto: pregunta «¿sabe el modelo cuándo no sabe?». La respuesta, para la mayoría de los modelos, es no.[6]
Resultados
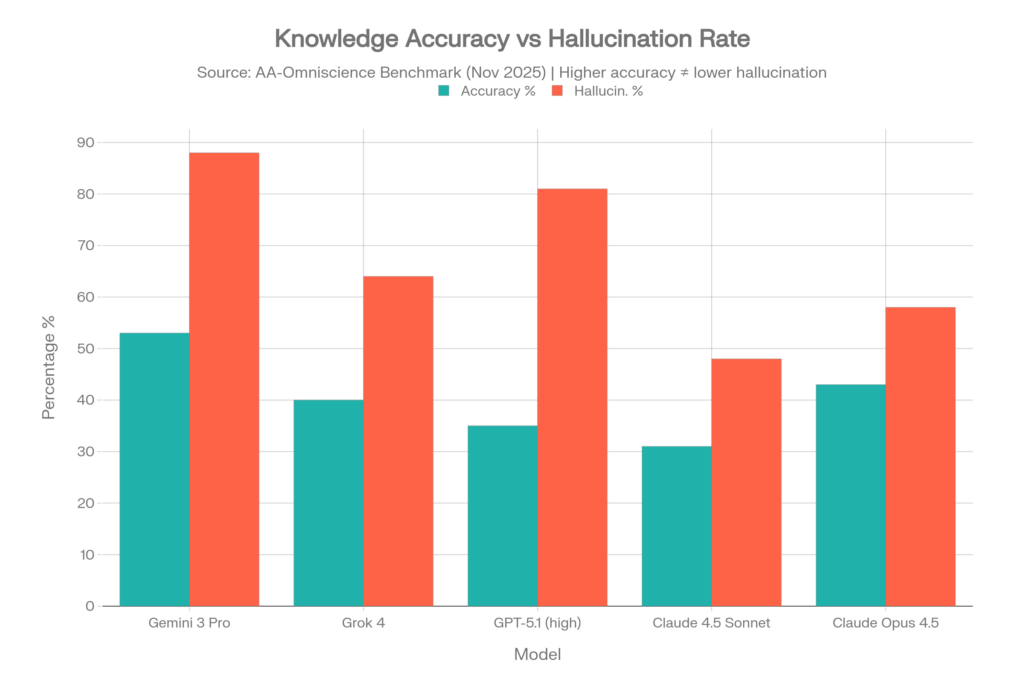
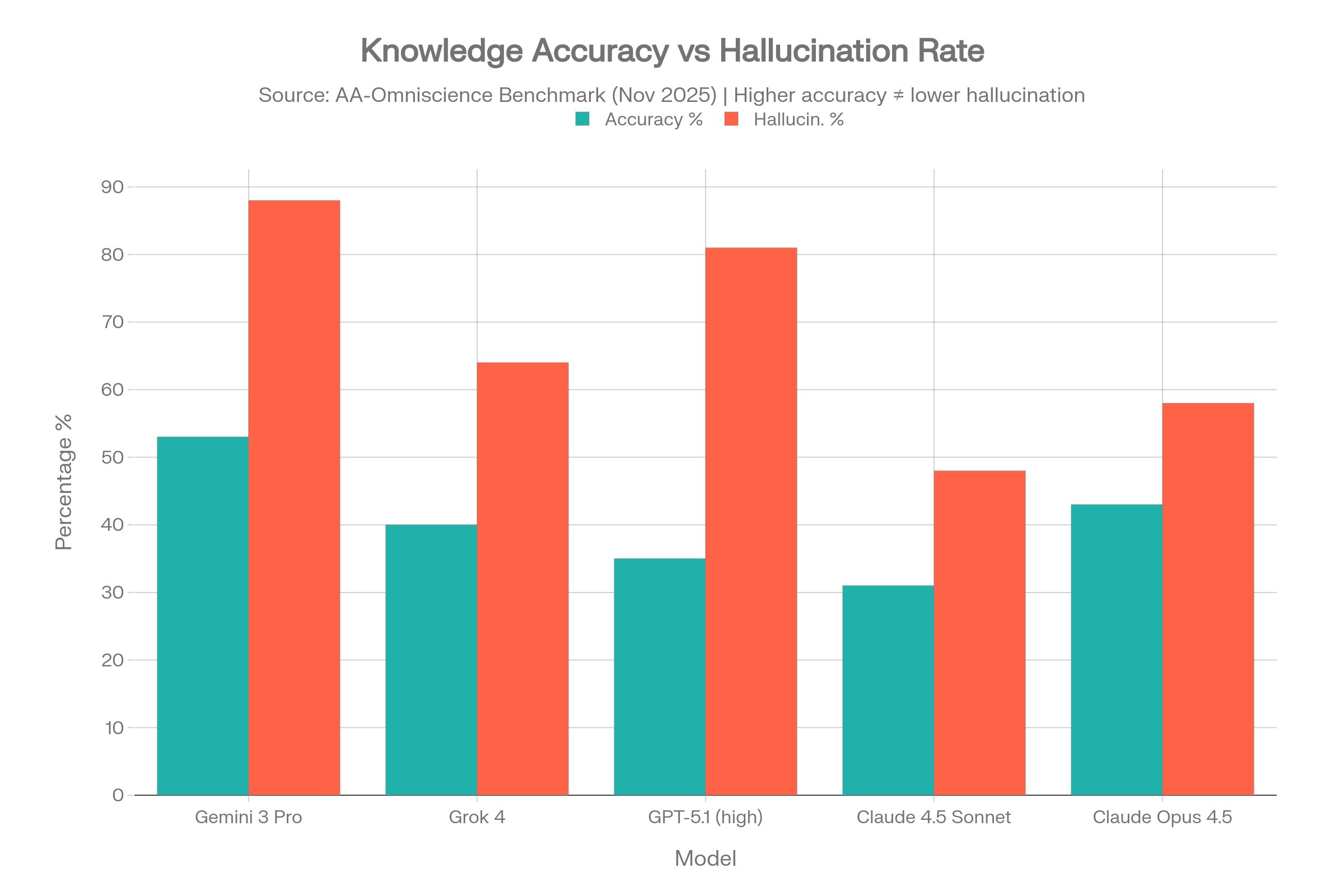
De los 40 modelos probados, solo CUATRO lograron un Índice de Omnisciencia positivo, lo que significa que 36 de 40 modelos tienen más probabilidades de dar una respuesta errónea con seguridad que una correcta en preguntas difíciles de conocimiento.[5][6]
| Modelo | Precisión | Tasa de alucin.* | Omniscience Index |
| Gemini 3 Pro | 53% | 88% | 13 |
| Claude 4.1 Opus | 36% | Baja (mejor) | 4.8 |
| GPT-5.1 (alto) | 35-39% | 51-81% | Positivo |
| Grok 4 | 40% | 64% | Positivo |
| Claude 4.5 Sonnet | 31% | 48% | Negativo |
| Claude 4.5 Haiku | — | 26% (la más baja) | Negativo |
| Claude Opus 4.5 | 43% | 58% | Negativo |
| Grok 4.1 Fast | — | 72% | Negativo |
| Kimi K2 0905 | — | 69% | Negativo |
| Kimi K2 Thinking | — | 74% | Negativo |
| DeepSeek V3.2 Ex | — | 81% | Negativo |
| DeepSeek R1 0528 | — | 83% | Negativo |
| Llama 4 Maverick | — | 87.58% | Negativo |
La tasa de alucinación aquí = proporción de respuestas falsas entre todos los intentos incorrectos (métrica de exceso de confianza)
Fuente: benchmark AA-Omniscience de Artificial Analysis, noviembre de 2025[16][5]
Líderes por dominio específico
Ningún modelo domina todos los dominios de conocimiento:[5]
| Dominio | Mejor modelo |
| Derecho | Claude 4.1 Opus |
| Ingeniería de software | Claude 4.1 Opus |
| Humanidades | Claude 4.1 Opus |
| Negocios | GPT-5.1.1 |
| Salud | Grok 4 |
| Ciencia | Grok 4 |
La paradoja de Gemini 3 Pro
Gemini 3 Pro logró la mayor precisión (53%) con un amplio margen, pero también mostró una tasa de alucinaciones del 88%. Esto significa que, cuando no sabe una respuesta, se la inventa el 88% de las veces en lugar de admitir incertidumbre. Alta precisión + alta alucinación = un modelo que sabe mucho, pero miente constantemente sobre lo que no sabe.[5]
La historia de Grok
Grok 4 se sitúa en una tasa de alucinaciones del 64% en AA-Omniscience, y su hermano más reciente Grok 4.1 Fast es aún peor, con un 72%. En el benchmark de resumen fundamentado de Vectara, Grok-4 obtuvo un 4,8%, casi 7 veces más que el mejor modelo Gemini. Y en un estudio de Columbia Journalism Review centrado en la precisión de citas de noticias, Grok-3 alucinó un asombroso 94% de las veces.[16][11][17]
xAI afirma que Grok 4.1 es «tres veces menos propenso a alucinar que los modelos Grok anteriores», y un análisis independiente de Clarifai sugiere que las tasas de alucinación bajaron de ~12% a ~4% con mejoras de entrenamiento. Pero los datos de AA-Omniscience cuentan una historia distinta cuando las preguntas se vuelven difíciles.[18][19]
Benchmark 3: estudio de citas de Columbia Journalism Review
Un estudio de marzo de 2025 de Columbia Journalism Review probó modelos de IA en su capacidad para citar con precisión fuentes de noticias. Los resultados fueron alarmantes:[20][17]
| Modelo | Tasa de alucinación |
| Perplexity | 37% |
| Copilot | 40% |
| Perplexity Pro | 45% |
| ChatGPT | 67% |
| DeepSeek | 68% |
| Gemini | 76% |
| Grok-2 | 77% |
| Grok-3 | 94% |
Fuente: Columbia Journalism Review, marzo de 2025, vía 5GWorldPro/Groundstone AI[17][20]
Este estudio es especialmente relevante para usuarios de Perplexity/Sonar: aunque Perplexity obtuvo el «mejor» resultado en esta prueba, una tasa de alucinaciones del 37% en tareas de citación significa que más de una de cada tres fuentes citadas puede contener afirmaciones inventadas. Un análisis independiente señaló que la mayor preocupación de Perplexity es que «cita fuentes reales con afirmaciones inventadas»: las URL parecen reales, pero la información atribuida a esas fuentes está inventada.[21]
Benchmark 4: tasas de alucinaciones financieras
Un estudio de 2025 publicado en International Journal of Data Science and Analytics probó chatbots de IA específicamente en referencias de literatura financiera:[17]
| Modelo | Tasa de alucinación (finanzas) |
| ChatGPT-4o | 20.0% |
| GPT o1-preview | 21.3% |
| Gemini Advanced | 76.7% |
Hallazgos más amplios sobre IA en finanzas:[22]
- El 78% de las empresas de servicios financieros ya despliega IA para análisis de datos
- Las tareas financieras con IA muestran tasas de alucinación del 15-25% sin salvaguardas
- Las empresas informan de 2,3 errores significativos impulsados por IA por trimestre
- El coste por incidente oscila entre 50.000 $ y 2,1 millones de $
- El 67% de las firmas de capital riesgo usa IA para el filtrado de operaciones; el tiempo medio de detección de errores es de 3,7 semanas, a menudo demasiado tarde
- La alucinación de un robo-advisor afectó a 2.847 carteras de clientes, con un coste de 3,2 millones de $ en remediación
Tasas de alucinación específicas por dominio
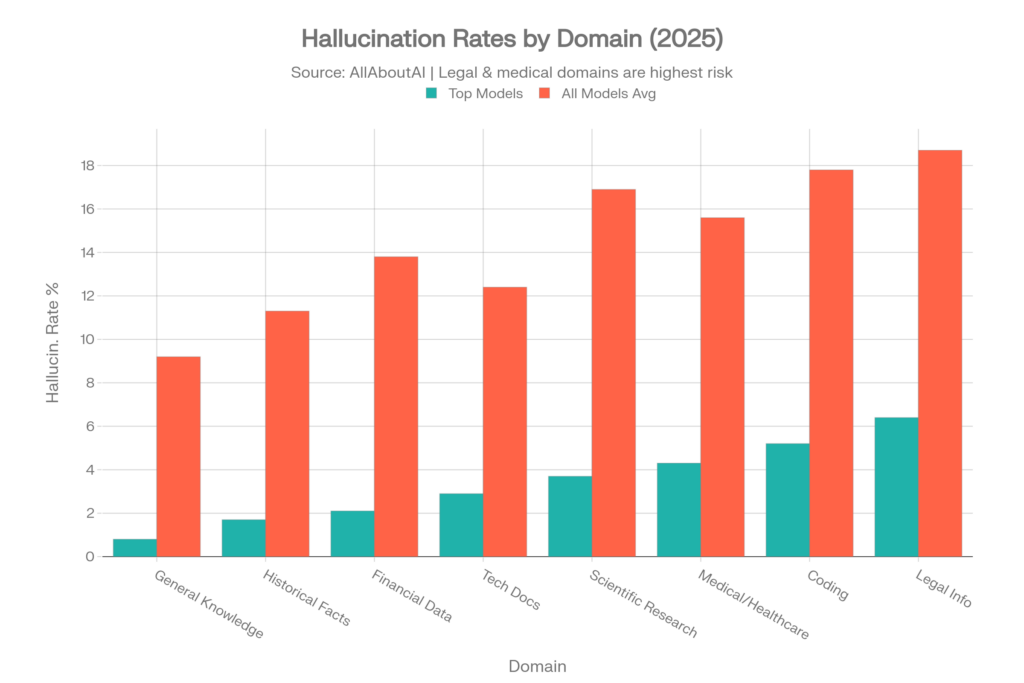
Incluso los modelos con mejor rendimiento muestran tasas de alucinación muy diferentes según la materia. Estos datos de AllAboutAI son críticos para entender el riesgo por caso de uso:[4]
| Dominio de conocimiento | Tasa de los mejores modelos | Media de todos los modelos |
| Conocimiento general | 0.8% | 9.2% |
| Hechos históricos | 1.7% | 11.3% |
| Datos financieros | 2.1% | 13.8% |
| Documentación técnica | 2.9% | 12.4% |
| Investigación científica | 3.7% | 16.9% |
| Medicina/salud | 4.3% | 15.6% |
| Código y programación | 5.2% | 17.8% |
| Información legal | 6.4% | 18.7% |
Análisis en profundidad de alucinaciones médicas
Un estudio de 2025 en MedRxiv analizó 300 viñetas clínicas validadas por médicos:[23]
- Sin prompts de mitigación: 64,1% de tasa de alucinación en casos largos, 67,6% en casos cortos
- Con prompts de mitigación: bajó al 43,1% y 45,3% respectivamente (reducción del 33%)
- GPT-4o fue el mejor: bajó del 53% al 23% con mitigación
- Modelos de código abierto: superaron el 80% de tasa de alucinación en escenarios médicos
Incluso con la mejor tasa de alucinación médica del 23%, casi 1 de cada 4 respuestas de IA médica contiene información inventada. ECRI, una organización global sin ánimo de lucro de seguridad sanitaria, situó los riesgos de la IA como el peligro n.º 1 de tecnología sanitaria para 2025.[24]
Análisis en profundidad de alucinaciones legales
El estudio de Stanford RegLab/HAI sobre alucinaciones legales sigue siendo la investigación definitiva:[25][9]
- Los LLM alucinan entre el 69% y el 88% de las veces en consultas legales específicas
- En preguntas sobre el fallo central de un tribunal, los modelos alucinan al menos el 75% de las veces
- Los modelos a menudo carecen de autoconciencia sobre sus errores y refuerzan supuestos legales incorrectos
- Cuanto más compleja es la consulta legal, mayor es la tasa de alucinación
- El 83% de los profesionales del derecho se ha encontrado jurisprudencia inventada al usar IA[26]
Impacto empresarial en el mundo real: las cifras
El problema de los 67,4 mil millones de dólares
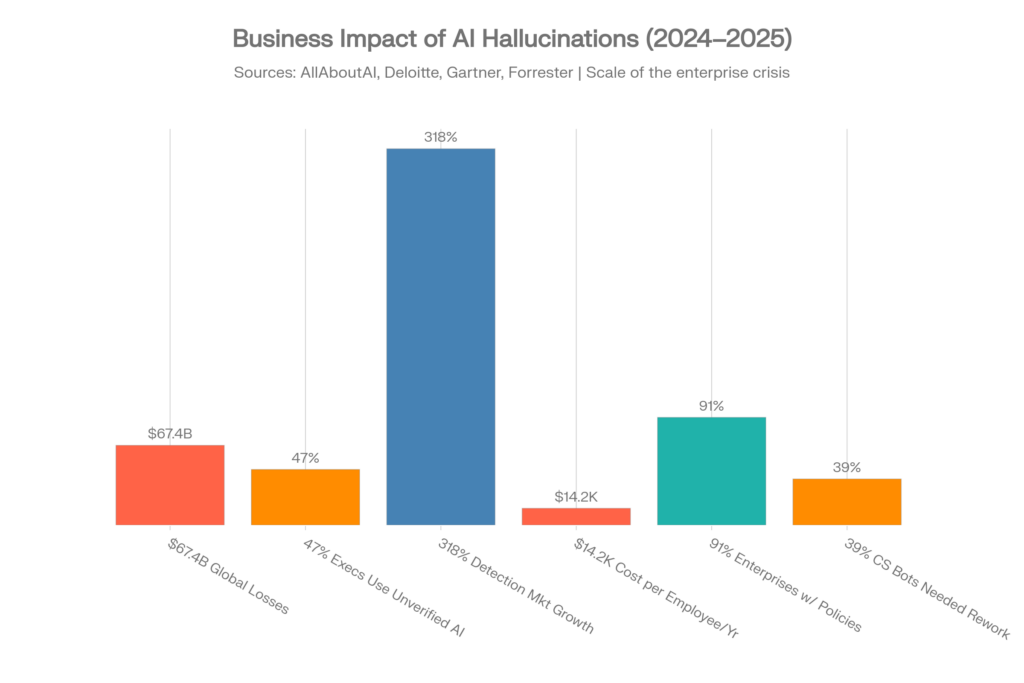
Las pérdidas empresariales globales atribuidas a alucinaciones de IA alcanzaron 67,4 mil millones de dólares en 2024. Esta cifra procede del estudio exhaustivo de AllAboutAI y representa costes directos e indirectos documentados de empresas que dependen de contenido generado por IA inexacto.[1][2]
Estadísticas clave de impacto empresarial
| Métrica | Valor | Fuente |
| Pérdidas globales por alucinaciones de IA (2024) | 67,4 mil millones de $ | AllAboutAI, 2025 [1] |
| Directivos que usan insights de IA sin verificar | 47% | Deloitte, 2025 [1] |
| Errores de IA por alucinaciones/fallos de precisión | 82% | Testlio, 2025 [27] |
| Bots de atención al cliente que requieren retrabajo | 39% | Testlio, 2024 [3] |
| Multas de la SEC por tergiversaciones sobre IA | 12,7 millones de $ | Informes del sector [3] |
| Empresas con caídas de confianza de inversores | 54% | Informes del sector [3] |
| Coste por empleado de mitigación de alucinaciones | 14.200 $/año | Forrester, 2025 [26][28] |
| Tiempo de empleados verificando contenido de IA | 4,3 horas/semana | Forbes/AllAboutAI [28] |
| Crecimiento del mercado de herramientas de detección de alucinaciones | 318% (2023-2025) | Gartner, 2025 [26] |
| Políticas de IA empresariales con protocolos de alucinaciones | 91% | AllAboutAI, 2025 [26] |
| Organizaciones sanitarias que retrasan la adopción de IA | 64% | AllAboutAI, 2025 [26] |
| Inversión en soluciones específicas para alucinaciones | 12,8 mil millones de $ | AllAboutAI, 2023-2025 [4] |
| Eficacia de RAG para reducir alucinaciones | 71% | AllAboutAI, 2025 [4] |
La paradoja de la Productividad
La ironía más cruel: se suponía que la IA iba a hacernos más productivos. En cambio, los empleados ahora dedican una media de 4,3 horas por semana —más de medio día laboral— solo a verificar si lo que les dijo la IA es realmente cierto. Eso equivale aproximadamente a 14.200 $ por empleado al año en puro coste de verificación. Para una empresa con 500 empleados que usan herramientas de IA, eso son 7,1 millones de $ al año gastados solo en revisar los deberes de la IA.[26][28]
Incidentes legales: la crisis en los tribunales
Las cifras empeoran, no mejoran
A pesar de la creciente concienciación, las alucinaciones de IA en escritos judiciales se están acelerando:[29][30]
- 2023: 10 resoluciones judiciales documentadas que implican alucinaciones de IA
- 2024: 37 resoluciones documentadas
- Primeros 5 meses de 2025: 73 resoluciones documentadas
- Solo julio de 2025: más de 50 casos con citas falsas
El investigador jurídico Damien Charlotin mantiene una base de datos pública de más de 120 casos en los que los tribunales encontraron citas alucinadas por IA, casos inventados o citas legales falsas.[30]
¿Quién comete estos errores?
El cambio de amateur a profesional es alarmante:[30]
- 2023: 7 de cada 10 casos de alucinación procedían de litigantes sin abogado, 3 de abogados
- Mayo de 2025: 13 de 23 casos detectados fueron culpa de abogados y profesionales del derecho
Casos destacados
- Johnson v. Dunn: los abogados presentaron dos escritos con autoridades legales falsas generadas por ChatGPT. Resultado: auto sancionador de 51 páginas, reprimenda pública, exclusión del caso, remisión a autoridades de licencias[29]
- Morgan & Morgan (feb. 2025): una de las mayores firmas de lesiones personales de EE. UU. envió una advertencia urgente a más de 1.000 abogados después de que un juez federal en Wyoming amenazara con sanciones por citas falsas generadas por IA en una demanda contra Walmart[31]
- Los tribunales han impuesto sanciones económicas de 10.000 $ o más en al menos cinco casos, cuatro de ellos en 2025[30]
- Se han documentado casos en EE. UU., Reino Unido, Sudáfrica, Israel, Australia y España[30]
Sanidad: donde las alucinaciones pueden matar
FDA y preocupaciones sobre dispositivos médicos
- La FDA ha autorizado 1.357 dispositivos médicos mejorados con IA a finales de 2025, el doble que a finales de 2022[32]
- Investigaciones de Johns Hopkins, Georgetown y Yale hallaron que 60 dispositivos médicos de IA autorizados por la FDA estuvieron implicados en 182 retiradas[32]
- El 43% de estas retiradas se produjo en el plazo de un año desde la aprobación[32]
- El sistema Johnson & Johnson TruDi Navigation System (dispositivo de cirugía sinusal mejorado con IA) se vinculó a al menos 10 lesiones y 100 fallos, incluidas fugas de líquido cefalorraquídeo, perforaciones de cráneo e ictus[33][32]
Desinformación médica con IA
Se descubrió que los principales modelos de IA podían manipularse para producir consejos médicos peligrosamente falsos, como afirmar que el protector solar causa cáncer de piel o vincular el 5G con la infertilidad, con citas inventadas de revistas como The Lancet.[4]
Tendencia histórica: el progreso es real, pero desigual
Las buenas noticias
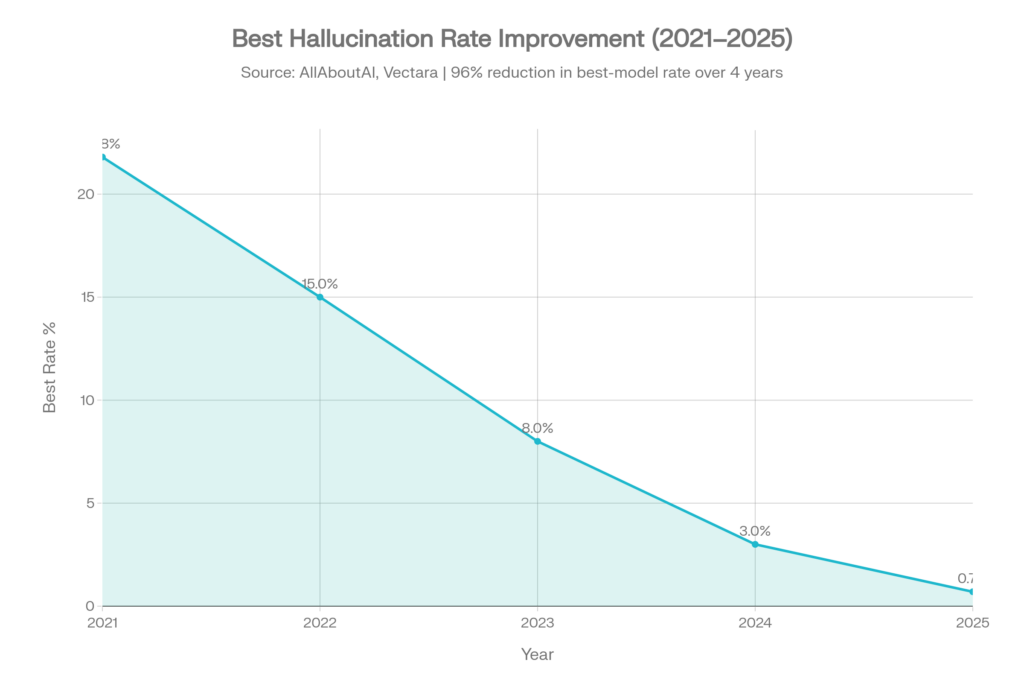
Las tasas de alucinación de los mejores modelos han bajado drásticamente:[4]
| Año | Mejor tasa de alucinación | Contexto |
| 2021 | ~21,8% | Era temprana de GPT-3 |
| 2022 | ~15,0% | Mejora con RLHF |
| 2023 | ~8,0% | GPT-4 y la competencia |
| 2024 | ~3,0% | Mejora rápida |
| 2025 | 0.7% | Gemini-2.0-Flash lidera |
Esto representa una reducción del 96% en las tasas de alucinación del mejor modelo en cuatro años.[4]
Las malas noticias
- La mejora es desigual entre proveedores. Algunos modelos Claude incluso empeoraron: Claude 3 Sonnet pasó del 6,0% al 16,3%, y Claude 2 casi se duplicó del 8,5% al 17,4% en el benchmark de Vectara con el tiempo.[23]
- Los nuevos benchmarks «más difíciles» revelan la brecha entre tareas simples y la complejidad del mundo real. En el nuevo conjunto de datos de Vectara, incluso Gemini-3-Pro llega al 13,6%.[12]
- Los resultados de AA-Omniscience son aleccionadores: en preguntas realmente difíciles, 36 de 40 modelos siguen alucinando más de lo que responden correctamente.[6]
- Las tasas por dominio siguen siendo peligrosamente altas: legal (18,7% de media), médica (15,6%) y programación (17,8%).[4]
La trayectoria de Grok
- Era Grok-1/2: posicionado como un modelo más «orientado a la personalidad», con menos énfasis en la fundamentación factual
- Grok-3: obtuvo un 2,1% en el benchmark antiguo de resumen de Vectara (decente), pero un 94% en precisión de citas en la prueba de Columbia Journalism Review[10][17]
- Grok-4: 4,8% en Vectara, 64% en preguntas difíciles de AA-Omniscience[16][11]
- Grok 4.1: xAI afirmó «3 veces menos alucinaciones», Clarifai estimó una reducción de ~12% a ~4%, pero AA-Omniscience mostró un 72% en Grok 4.1 Fast (peor que el 64% de Grok 4)[18][19][16]
La inconsistencia entre benchmarks sugiere que las mejoras de Grok pueden ser específicas de la tarea y no generalizables.
Resumen modelo por modelo para los modelos de Suprmind.ai
Modelos de OpenAI
| Modelo | Vectara (Antiguo) | Vectara (Nuevo) | AA-Omniscience | Notas |
| GPT-5 / ChatGPT-5 | 1.4% | >10 % | — | Mejora sólida en tareas fáciles; dificultades en las difíciles [11] |
| GPT-5.1 (alto) | — | — | 51-81% alucin., 35% precisión | Mejor para el dominio de Negocios; Índice de Omnisciencia positivo [5] |
| GPT-4o | 1.5% | — | — | Modelo todoterreno, rendimiento consistente [10] |
| o3-mini-high | 0.8% | — | — | Mejor modelo de OpenAI en el Vectara antiguo [10] |
Modelos Claude de Anthropic
| Modelo | Vectara (Antiguo) | Vectara (Nuevo) | AA-Omniscience | Notas |
| Claude 4.5 Sonnet | — | >10 % | 48% alucin., 31% precisión | Gama media en tareas de conocimiento [16] |
| Claude 4.5 Haiku | — | — | 26% alucin. (¡la más baja!) | Mejor gestión de la incertidumbre [16] |
| Claude Opus 4.5 | — | — | 58% alucin., 43% precisión | Buena precisión, pero alto exceso de confianza [16] |
| Claude 4.1 Opus | — | — | Índice de Omnisciencia: 4,8 | Mejor en Derecho, Ing. de software, Humanidades [5] |
| Claude-3.7-Sonnet | 4.4% | — | — | Decente en resúmenes [10] |
Modelos Grok de xAI
| Modelo | Vectara (Antiguo) | Vectara (Nuevo) | AA-Omniscience | Otros |
| Grok 4 | 4.8% | >10 % | 64% alucin., 40% precisión | Mejor en Salud y Ciencia; Índice de Omnisciencia positivo [11][16] |
| Grok 4.1 | — | — | 72% alucin. (variante Fast) | xAI afirma una mejora 3x; los datos son mixtos [16][19] |
| Grok 3 | 2.1% | 5.8% | — | 94% en la prueba de citación de noticias [17] |
Modelos Google Gemini
| Modelo | Vectara (Antiguo) | Vectara (Nuevo) | AA-Omniscience | Notas |
| Gemini 3 Pro | — | 13.6% | 88% alucin., 53% precisión, Índice: 13 | Mayor precisión, pero exceso de confianza extremo [5][12] |
| Gemini 2.5-Pro | 1.1% | — | — | Sólido en el benchmark antiguo [10] |
| Gemini 2.5-Flash | 1.3% | — | — | [10] |
| Gemini 2.5-Flash-Lite | — | 3.3% | — | Mejor en el nuevo benchmark de Vectara [13] |
Perplexity / Sonar
- Sin listado directo en Vectara ni AA-Omniscience para los modelos propietarios de Perplexity
- Perplexity usa modelos subyacentes (históricamente, incluido DeepSeek-R1, que tiene ~14,3% de tasa de alucinación en Vectara)[34]
- Prueba de Columbia Journalism Review: Perplexity 37% de alucinación en precisión de citas (mejor en esa prueba, pero aun así 1 de cada 3)[20]
- Perplexity Pro: 45% de alucinación en la misma prueba[20]
- Perfil de riesgo único: «cita fuentes reales con afirmaciones inventadas»; las URL son reales, pero la información atribuida está inventada[21]
La alucinación más peligrosa: la que no detecta
Los datos revelan un hallazgo crítico que la mayoría de usuarios de IA pasa por alto: la alucinación no es un fallo ocasional, sino una característica fundamental de cómo funcionan estos modelos. Las estadísticas clave que lo ilustran:
- El 47% de los directivos ha actuado basándose en contenido de IA alucinado, lo que significa que aproximadamente la mitad de las decisiones empresariales informadas por IA pueden construirse sobre cimientos inventados[1]
- El 82% de los errores de IA proviene de alucinaciones y fallos de precisión, no de caídas o errores visibles: el sistema parece funcionar perfectamente mientras entrega respuestas erróneas[27]
- 4,3 horas por semana por empleado dedicadas a verificar la salida de la IA, y eso en organizaciones que saben que hay que comprobar[28]
- El coste medio por incidente grave de alucinación oscila entre 18.000 $ en atención al cliente y 2,4 millones de $ en mala praxis sanitaria[1]
Activos de datos descargables
Se han preparado tres archivos CSV como bases de datos en bruto para el desarrollo de contenido:
- ai_hallucination_data.csv — Tasas de alucinación exhaustivas, modelo por modelo, en todos los benchmarks
- domain_hallucination_rates.csv — Tasas por dominio para los mejores modelos frente a todos los modelos
- business_impact_data.csv — 22 métricas clave de impacto empresarial con fuentes y años
Glosario de definiciones clave
| Término | Definición |
| Alucinación | Contenido generado por IA que es factualmente incorrecto o inventado, presentado con seguridad |
| Alucinación fundamentada | Información falsa introducida durante el resumen de un documento proporcionado |
| Alucinación factual | Hechos, estadísticas o citas inventadas sin base en la realidad |
| RAG (Retrieval Augmented Generation) | Técnica que conecta la IA con bases de conocimiento externas para reducir alucinaciones; reduce las tasas en ~71% [4] |
| HHEM (Hughes Hallucination Evaluation Model) | Modelo de Vectara para detectar alucinaciones en resúmenes (puntuación 0-1; por debajo de 0,5 = alucinación) [8] |
| Omniscience Index | Métrica AA-Omniscience (-100 a +100) que recompensa respuestas correctas y penaliza las erróneas con exceso de confianza [6] |
| Tasa de consistencia factual | 100% menos la tasa de alucinación: el porcentaje de salidas fieles al material fuente |
| Impuesto del razonamiento | Fenómeno observado por el que los modelos «pensantes» alucinan más en tareas fundamentadas [15] |
| Sycophancy | Tendencia del modelo a dar la razón al usuario incluso cuando el usuario se equivoca |
| Colapso del modelo | Degradación progresiva de la calidad cuando los modelos se entrenan con contenido generado por IA |
Resumen de fuentes
Benchmarks y estudios principales referenciados:
- Clasificación Vectara HHEM (conjuntos de datos original y actualizado, 2023-2026)[10][12][13]
- Benchmark AA-Omniscience de Artificial Analysis (noviembre de 2025)[5][6]
- Informe de alucinaciones de IA de AllAboutAI 2026 (análisis exhaustivo del sector)[4]
- Columbia Journalism Review estudio de precisión de citas (marzo de 2025)[20][17]
- Stanford RegLab/HAI estudio de alucinaciones legales[25][9]
- Encuesta global de Deloitte sobre toma de decisiones empresariales con IA[26]
- Forrester Research sobre el impacto económico de la mitigación de alucinaciones[26]
- Gartner AI Market Analysis sobre el crecimiento del mercado de herramientas de detección[26]
- MedRxiv 2025 estudio sobre alucinaciones en casos médicos[23]
- International Journal of Data Science and Analytics sobre alucinaciones de IA en finanzas[17]
- ECRI informe 2025 de riesgos de tecnología sanitaria[24]
- Reuters cobertura sobre incidentes legales con IA[31]
- Business Insider base de datos de casos judiciales de alucinaciones de IA[30]
- VinciWorks análisis de la crisis de citas legales de julio de 2025[29]





