



エグゼクティブ・オーバービュー
AIハルシネーション(AIモデルが絶対的な自信を持って虚偽または捏造された情報を生成する現象)は、今日のAI主導のビジネス環境において、最も重大でありながら過小評価されているリスクの一つです。以下のデータはその規模を明確に示しています。また、いかなるモデルも例外ではないことも明らかにしており、そのためマルチモデル検証によるハルシネーションの軽減は、オプションの安全策ではなく、構造的な必須要件となりつつあります。
本レポートは、複数の権威あるベンチマーク、業界研究、および実世界のインシデント追跡からの生の統計データをまとめたもので、コンテンツの基盤として機能します。
主要な数値は驚くべきものです:
- AIハルシネーションによる世界のビジネス損失は、2024年だけで674億ドルに達しました[1][2]
- ビジネスエグゼクティブの47%が、未検証のAI生成コンテンツに基づいて重大な意思決定を行っています[3][1]
- 最高レベルのAIモデルであっても、基本的な要約タスクにおいて少なくとも0.7%の頻度でハルシネーションを起こします。その割合は、法的質問では18.7%、医療的照会では15.6%まで急上昇します[4]
- 難解な知識問題において、テストされた40モデルのうち3つを除くすべてが、正解を出すよりもハルシネーションを起こす可能性の方が高いという結果が出ています[5][6]
AIハルシネーションとは何か?(技術的定義と平易な解説)
平易な解説
AIハルシネーションとは、AIモデルが自信満々に嘘をつくことです。「わかりません」と言う代わりに、捏造された事実、架空の統計、偽の判例、あるいは存在しない医学研究を、あたかも実在するかのように提示します。その回答は権威があるように聞こえ、文章としても完璧です。それがこの現象を危険なものにしています。[7]
技術的定義
技術的な用語では、ハルシネーションとは、提供された入力データや事実としての現実に根ざしていない生成出力を指します。主に2つのタイプがあります:
- 本質的ハルシネーション(「忠実性のハルシネーション」とも呼ばれる):モデルがソース資料で明示的に提供された情報と矛盾する内容を生成すること。例えば、要約の際、元の文書にない事実を付け加える場合などです。[8]
- 外延的ハルシネーション(「事実性のハルシネーション」とも呼ばれる):モデルが既知のソースで検証できない情報を生成すること。事実、引用、統計、出来事をゼロから捏造します。[9]
MITの研究(2025年1月)による重要な技術的知見:AIモデルはハルシネーションを起こす際、事実に基づいた情報を提供するときよりも自信に満ちた言葉を使う傾向があります。誤った情報を生成する際、モデルが「間違いなく」「確実に」「疑いようもなく」といったフレーズを使用する確率は34%高かったのです。[4]
これが核心的なパラドックスです。AIは間違っていればいるほど、確信に満ちたように聞こえるのです。
なぜ起こるのか
LLMは根本的に知識ベースではなく予測エンジンです。LLMは、トレーニングデータから学習したパターンに基づき、統計的に最も可能性の高い次の単語を予測することでテキストを生成します。真実を「理解」しているのではなく、妥当性を予測しているのです。モデルがトレーニングデータの欠落に遭遇したり、曖昧な照会に直面したりすると、不確実性を認めるのではなく、もっともらしく聞こえる捏造でそのギャップを埋めてしまいます。[1]
ベンチマーク1:Vectaraハルシネーション・リーダーボード(HHEM)
測定内容
Vectara Hughes Hallucination Evaluation Model (HHEM) リーダーボードは、業界で最も広く参照されているハルシネーションのベンチマークです。これは根拠のあるハルシネーション、つまりLLMが明示的に与えられた文書を要約する際に、どの程度の頻度で誤った情報を導入するかを測定します。「モデルは目の前に書かれている内容を忠実に守れるか?」という指標と考えてください。[10][8]
Vectara Hughes Hallucination Evaluation Model (HHEM) リーダーボードを含むAIハルシネーション・ベンチマーク(ライブテーブル)。
評価方法:各モデルに1,000以上の文書を与え、文書内の事実のみを使用して要約するよう指示します。その後、VectaraのHHEMモデルが各要約をソースと照合し、捏造された主張を特定します。[10]
ビジネスユーザーにとっての重要性
これは、エンタープライズAI検索、カスタマーサポートボット、文書分析ツールのバックボーンであるRAG(検索拡張生成)システムでのAIの使われ方と直接的に類似しています。要約中にハルシネーションを起こすモデルは、自社のナレッジベースからの質問に答える際にもハルシネーションを起こします。[10]
ハルシネーション率 — オリジナルデータセット(2025年4月)
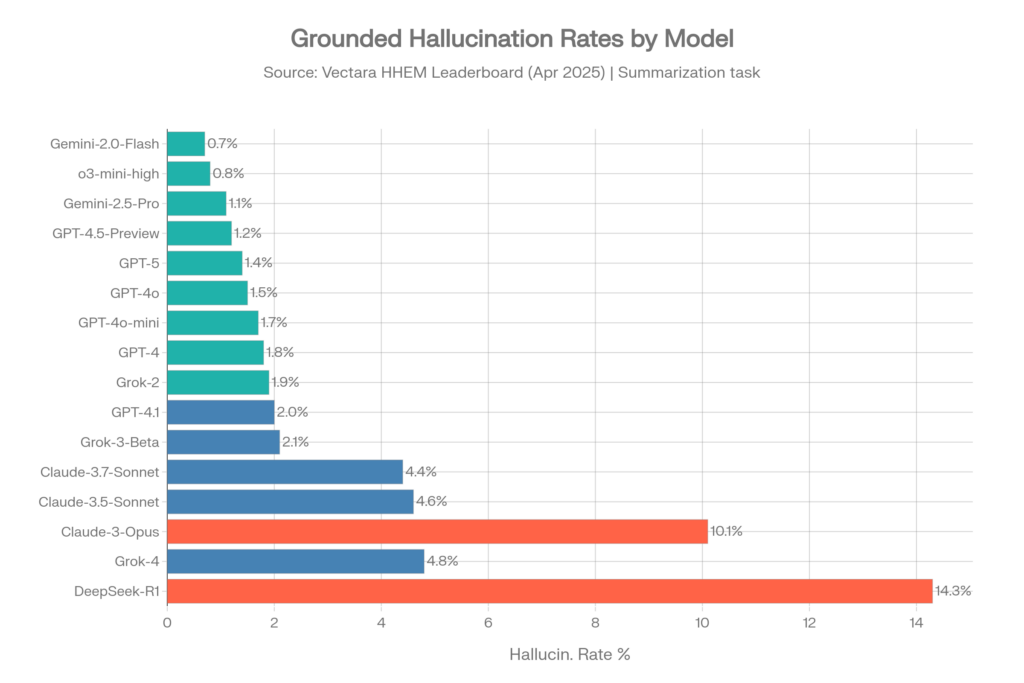
約1,000件の文書からなるこのデータセットは、2025年中盤までの標準的なベンチマークでした。[10]
| モデル | ベンダー | ハルシネーション率 | 事実の一貫性 |
| Gemini-2.0-Flash-001 | 0.7% | 99.3% | |
| Gemini-2.0-Pro-Exp | 0.8% | 99.2% | |
| o3-mini-high | OpenAI | 0.8% | 99.2% |
| Gemini-2.5-Pro-Exp | 1.1% | 98.9% | |
| GPT-4.5-Preview | OpenAI | 1.2% | 98.8% |
| Gemini-2.5-Flash-Preview | 1.3% | 98.7% | |
| o1-mini | OpenAI | 1.4% | 98.6% |
| GPT-5 / ChatGPT-5 | OpenAI | 1.4% | 98.6% |
| GPT-4o | OpenAI | 1.5% | 98.5% |
| GPT-4o-mini | OpenAI | 1.7% | 98.3% |
| GPT-4-Turbo | OpenAI | 1.7% | 98.3% |
| GPT-4 | OpenAI | 1.8% | 98.2% |
| Grok-2 | xAI | 1.9% | 98.1% |
| GPT-4.1 | OpenAI | 2.0% | 98.0% |
| Grok-3-Beta | xAI | 2.1% | 97.8% |
| Claude-3.7-Sonnet | Anthropic | 4.4% | 95.6% |
| Claude-3.5-Sonnet | Anthropic | 4.6% | 95.4% |
| Claude-3.5-Haiku | Anthropic | 4.9% | 95.1% |
| Grok-4 | xAI | 4.8% | 約95.2% |
| Llama-4-Maverick | Meta | 4.6% | 95.4% |
| Claude-3-Opus | Anthropic | 10.1% | 89.9% |
| DeepSeek-R1 | DeepSeek | 14.3% | 85.7% |
出典: Vectara HHEM Leaderboard, GitHub repository, 2025年4月[10]
Vectara(旧データセット)からの主な要点
- Google Geminiモデルが上位を独占しており、Gemini-2.0-Flashが0.7%で首位となっています[4]
- OpenAIはGPT-4ファミリー全体で一貫して強力であり、0.8%から2.0%の範囲に収まっています[10]
- Grok-4は4.8%と、競合するGPTやGeminiよりも著しく高く、最良のGeminiモデルの約7倍のハルシネーション率を示しています[11]
- Claudeモデルは驚くべきばらつきを見せています。Claude-3.7-Sonnetの4.4%はまずまずですが、Claude-3-Opusの10.1%は懸念されるほど高い数値です[10]
- OpenAIのo3-mini-high推論モデルは0.8%を達成し、推論能力が事実の根拠付けを実際に向上させ得ることを示しました[10]
ハルシネーション率 — 新データセット(2025年11月 – 2026年2月)
Vectaraは2025年末にベンチマークを完全に刷新しました。7,700件の記事(1,000件から増加)、より長い文書(最大32Kトークン)、そして法律、医療、金融、技術、教育にわたる複雑度の高いコンテンツを採用しています。[12]
その結果、意図的に劇的に高い数値が出ています。このベンチマークは、実際の企業のワークロードをより正確に反映しています。[12]
| モデル | ベンダー | ハルシネーション率 |
| Gemini-2.5-Flash-Lite | 3.3% | |
| Mistral-Large | Mistral | 4.5% |
| DeepSeek-V3.2-Exp | DeepSeek | 5.3% |
| GPT-4.1 | OpenAI | 5.6% |
| Grok-3 | xAI | 5.8% |
| DeepSeek-R1-0528 | DeepSeek | 7.7% |
| Claude Sonnet 4.5 | Anthropic | >10% |
| GPT-5 | OpenAI | >10% |
| Grok-4 | xAI | >10% |
| Gemini-3-Pro | 13.6% |
出典: Vectara Hallucination Leaderboard, new dataset, 2025年11月[13][12]
「推論コスト」の発見
Vectaraの更新されたリーダーボードは、重要な発見を明らかにしました。それは、推論・思考モデルの方が、根拠のある要約において実際にパフォーマンスが低下するということです。強力な「推論者」として販売されているGPT-5、Claude Sonnet 4.5、Grok-4、Gemini-3-Proなどのモデルはすべて、より難易度の高いベンチマークで10%を超えるハルシネーション率を記録しました。[12][14][15]
仮説:推論モデルは回答を「考え抜く」ために計算リソースを投入しますが、それが時として「考えすぎ」を招き、単に提供されたテキストに従うのではなく、ソース資料から逸脱する原因となります。これは企業のRAGアプリケーションにとって大きな注意点です。[15]
ベンチマーク2:AA-Omniscience (Artificial Analysis)
測定内容
2025年11月にリリースされたAA-Omniscienceは、ビジネス、人文・社会科学、健康、法律、ソフトウェアエンジニアリング、科学・数学の6つのドメインにおける42のトピック、6,000の質問をカバーする知識およびハルシネーションのベンチマークです。[5][6]
単に正解数を数える従来のベンチマークとは異なり、Omniscience Indexは不正解を減点します。つまり、間違った推測をしたモデルは、「わかりません」と認めたモデルよりも厳しく罰せられます。スケールは-100から+100までです。[6]
なぜこのベンチマークは異なるのか(そして恐ろしいのか)
ほとんどのAIベンチマークは、すべての質問に回答しようとすることを推奨しており、それが推測を促す要因となっています。AA-Omniscienceはこれを逆転させ、「モデルは自分が知らないときを自覚しているか?」を問います。ほとんどのモデルにとって、その答えは「いいえ」です。[6]
結果
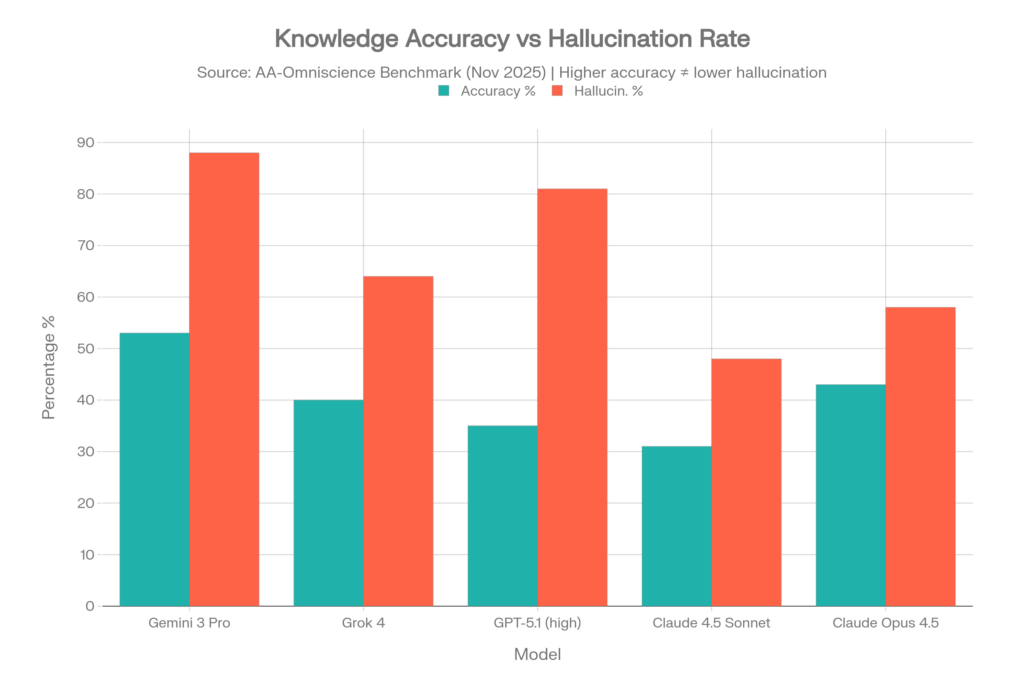
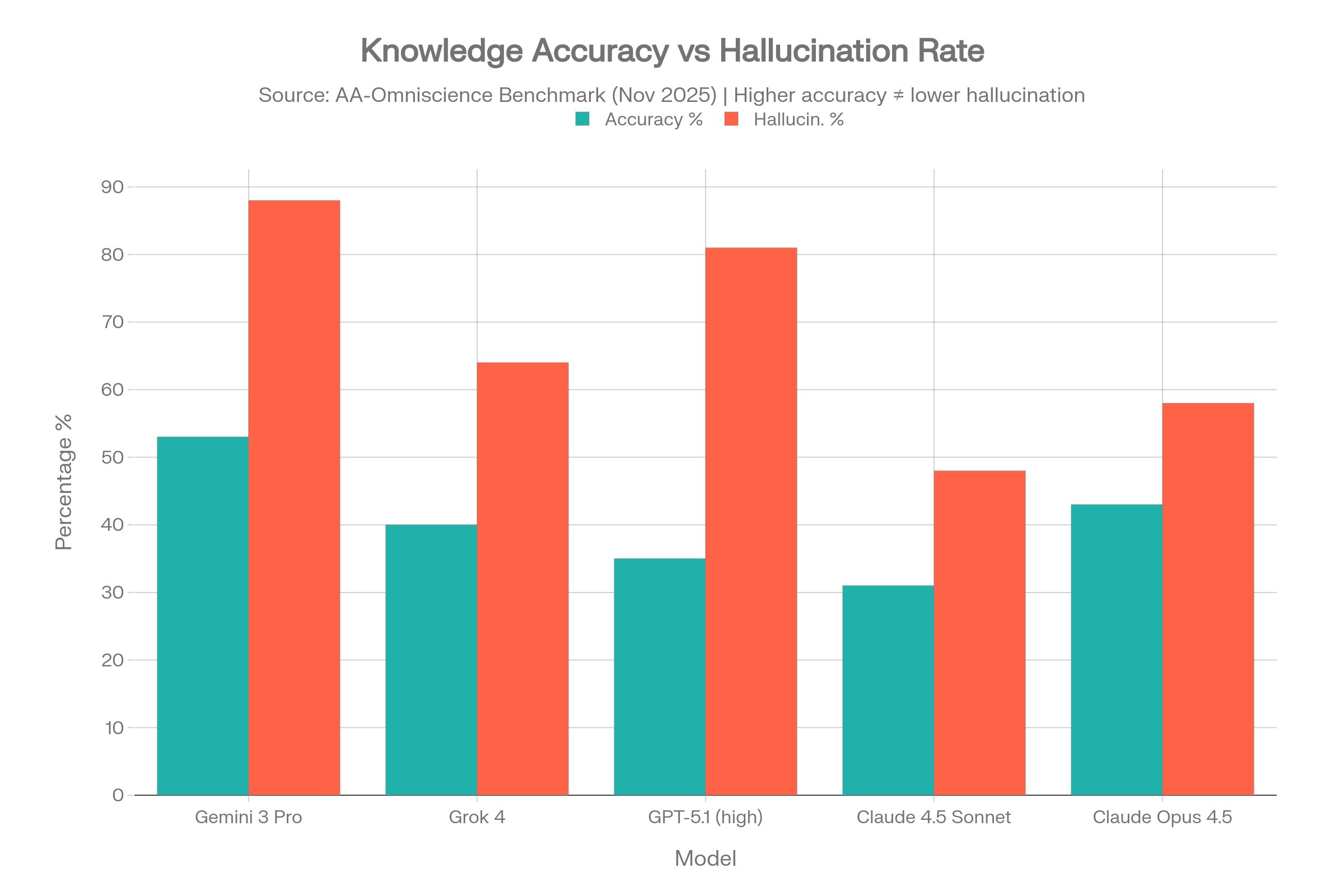
テストされた40モデルのうち、Omniscience Indexがプラスになったのはわずか4モデルでした。つまり、40モデル中36モデルは、難解な知識問題において、正解を出すよりも自信満々に間違った答えを出す可能性の方が高いということです。[5][6]
| モデル | 正確性 | ハルシネーション率* | Omniscience Index |
| Gemini 3 Pro | 53% | 88% | 13 |
| Claude 4.1 Opus | 36% | 低い(最良) | 4.8 |
| GPT-5.1 (high) | 35-39% | 51-81% | プラス |
| Grok 4 | 40% | 64% | プラス |
| Claude 4.5 Sonnet | 31% | 48% | マイナス |
| Claude 4.5 Haiku | — | 26%(最低) | マイナス |
| Claude Opus 4.5 | 43% | 58% | マイナス |
| Grok 4.1 Fast | — | 72% | マイナス |
| Kimi K2 0905 | — | 69% | マイナス |
| Kimi K2 Thinking | — | 74% | マイナス |
| DeepSeek V3.2 Ex | — | 81% | マイナス |
| DeepSeek R1 0528 | — | 83% | マイナス |
| Llama 4 Maverick | — | 87.58% | マイナス |
ここでのハルシネーション率 = すべての不正解の試行のうち、虚偽の回答が占める割合(過信の指標)
出典: Artificial Analysis AA-Omniscience Benchmark, 2025年11月[16][5]
ドメイン別リーダー
すべての知識ドメインを支配する単一のモデルは存在しません:[5]
| ドメイン | 最良モデル |
| 法律 | Claude 4.1 Opus |
| ソフトウェアエンジニアリング | Claude 4.1 Opus |
| 人文科学 | Claude 4.1 Opus |
| ビジネス | GPT-5.1.1 |
| 健康 | Grok 4 |
| 科学 | Grok 4 |
Gemini 3 Proのパラドックス
Gemini 3 Proは、大差をつけて最高の正確性(53%)を達成しましたが、同時に88%というハルシネーション率も示しました。これは、答えを知らないとき、不確実性を認めるのではなく、88%の確率で答えを捏造することを意味します。高い正確性 + 高いハルシネーション = 多くのことを知っているが、知らないことについては常に嘘をつくモデル、ということです。[5]
Grokの現状
Grok 4はAA-Omniscienceで64%のハルシネーション率を記録しており、新しい兄弟モデルであるGrok 4.1 Fastは72%とさらに悪化しています。Vectaraの根拠のある要約ベンチマークでは、Grok-4は4.8%で、最良のGeminiモデルの約7倍でした。また、ニュースの引用の正確性に焦点を当てたColumbia Journalism Reviewの研究では、Grok-3は94%という驚異的な頻度でハルシネーションを起こしました。[16][11][17]
xAIは、Grok 4.1が「以前のGrokモデルよりもハルシネーションを起こす可能性が3倍低い」と主張しており、Clarifaiによる別の分析では、トレーニングの改善によりハルシネーション率が約12%から約4%に低下したことが示唆されています。しかし、AA-Omniscienceのデータは、質問が難しくなると異なる結果を示しています。[18][19]
ベンチマーク3:Columbia Journalism Review 引用調査
Columbia Journalism Reviewによる2025年3月の調査では、ニュースソースを正確に引用するAIモデルの能力をテストしました。その結果は憂慮すべきものでした:[20][17]
| モデル | ハルシネーション率 |
| Perplexity | 37% |
| Copilot | 40% |
| Perplexity Pro | 45% |
| ChatGPT | 67% |
| DeepSeek | 68% |
| Gemini | 76% |
| Grok-2 | 77% |
| Grok-3 | 94% |
出典: Columbia Journalism Review, 2025年3月, via 5GWorldPro/Groundstone AI[17][20]
この研究は、Perplexity/Sonarユーザーにとって特に重要です。Perplexityはこのテストで「最高」のスコアを獲得しましたが、引用タスクにおける37%のハルシネーション率は、引用されたソースの3つに1つ以上が捏造された主張を含んでいる可能性があることを意味します。別の分析では、Perplexityの最大の懸念は「実在するソースを捏造された主張と共に引用する」ことであると指摘されています。URLは本物に見えますが、そのソースに帰属する情報は作り話なのです。[21]
ベンチマーク4:金融分野のハルシネーション率
International Journal of Data Science and Analyticsに掲載された2025年の研究では、特に金融文献の参照についてAIチャットボットをテストしました:[17]
| モデル | ハルシネーション率(金融) |
| ChatGPT-4o | 20.0% |
| GPT o1-preview | 21.3% |
| Gemini Advanced | 76.7% |
金融分野におけるAIに関する広範な調査結果:[22]
- 金融サービス企業の78%が、現在データ分析にAIを導入しています
- 金融AIタスクは、安全策がない場合、15〜25%のハルシネーション率を示します
- 企業は、四半期ごとに2.3件の重大なAI主導のエラーを報告しています
- 1件あたりのコストは5万ドルから210万ドルに及びます
- VC企業の67%が案件のスクリーニングにAIを使用しています。エラー発見までの平均時間は3.7週間であり、手遅れになることが多いです
- あるロボアドバイザーのハルシネーションは2,847のクライアントポートフォリオに影響を与え、修復に320万ドルのコストがかかりました
ドメイン別ハルシネーション率
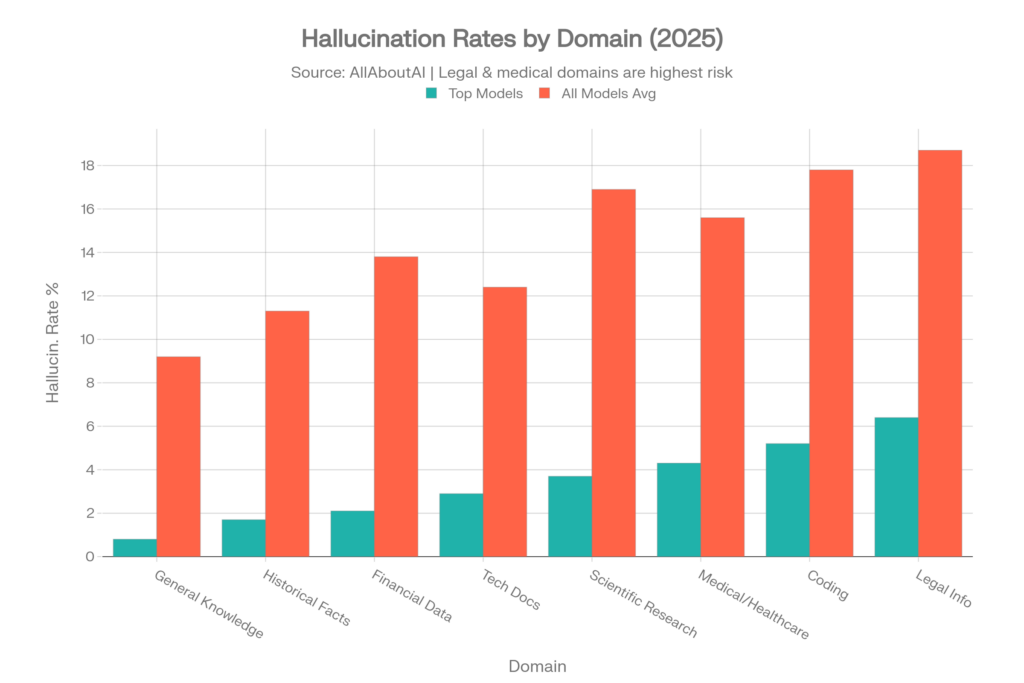
最高のパフォーマンスを示すモデルであっても、主題によってハルシネーション率は劇的に異なります。AllAboutAIによるこのデータは、ユースケース別のリスクを理解するために不可欠です:[4]
| 知識ドメイン | トップモデルの率 | 全モデル平均 |
| 一般知識 | 0.8% | 9.2% |
| 歴史的事実 | 1.7% | 11.3% |
| 金融データ | 2.1% | 13.8% |
| 技術文書 | 2.9% | 12.4% |
| 科学研究 | 3.7% | 16.9% |
| 医療・ヘルスケア | 4.3% | 15.6% |
| コーディング・プログラミング | 5.2% | 17.8% |
| 法的情報 | 6.4% | 18.7% |
医療ハルシネーションの詳細分析
2025年のMedRxivの研究では、医師が検証した300件の臨床症例を分析しました:[23]
- 軽減プロンプトなし: 長い症例で64.1%、短い症例で67.6%のハルシネーション率
- 軽減プロンプトあり: それぞれ43.1%と45.3%に低下(33%の削減)
- GPT-4oが最高のパフォーマンス: 軽減策により53%から23%に低下
- オープンソースモデル: 医療シナリオにおいて80%を超えるハルシネーション率
最高の医療ハルシネーション率である23%であっても、医療AIの回答の4つに1つ近くが捏造された情報を含んでいます。世界的なヘルスケア安全非営利団体であるECRIは、2025年の医療技術ハザードの第1位にAIリスクを挙げました。[24]
法的ハルシネーションの詳細分析
法的ハルシネーションに関するStanford RegLab/HAIの研究は、依然として決定的な調査です:[25][9]
- LLMは、特定の法的照会に対して69%から88%の頻度でハルシネーションを起こします
- 裁判所の核心的な判決に関する質問では、モデルは少なくとも75%の頻度でハルシネーションを起こします
- モデルはしばしば自らのエラーに対する自己認識を欠いており、誤った法的仮定を補強してしまいます
- 法的照会が複雑になればなるほど、ハルシネーション率は高くなります
- 法律専門家の83%が、AIの使用中に捏造された判例に遭遇しています[26]
実世界のビジネスへの影響:数値で見る
674億ドルの問題
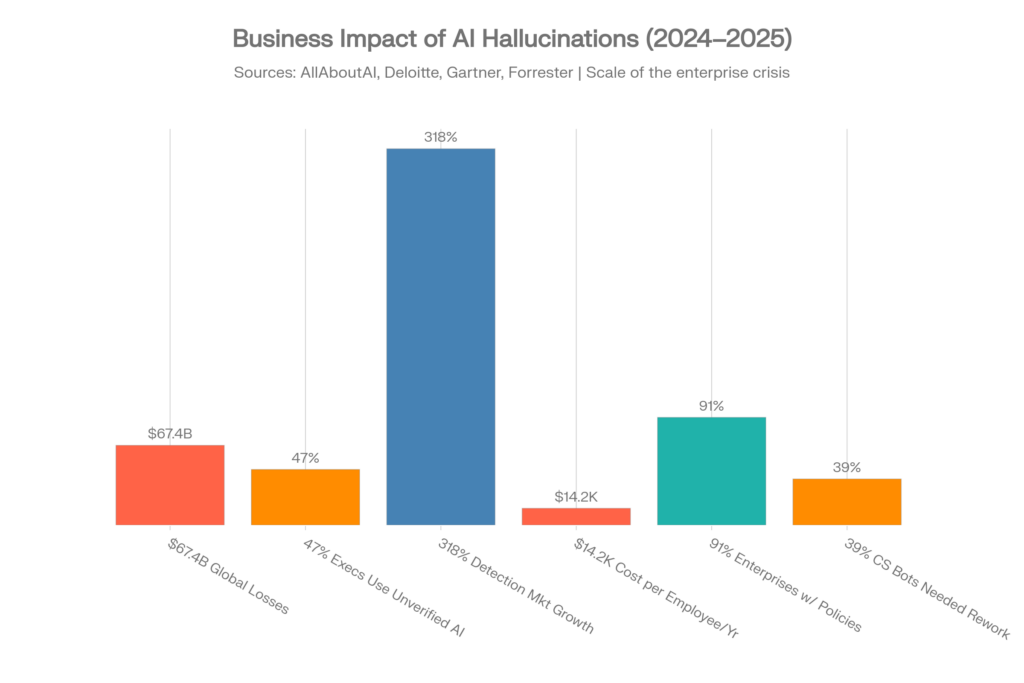
AIハルシネーションに起因する世界のビジネス損失は、2024年に674億ドルに達しました。この数字はAllAboutAIの包括的な研究によるもので、不正確なAI生成コンテンツに依存している企業からの、文書化された直接的および間接的なコストを表しています。[1][2]
主要なビジネス影響統計
| 指標 | 数値 | 出典 |
| AIハルシネーションによる世界的な損失(2024年) | 674億ドル | AllAboutAI, 2025 [1] |
| 未検証のAIの洞察を使用しているエグゼクティブ | 47% | Deloitte, 2025 [1] |
| ハルシネーション/正確性の欠如によるAIのバグ | 82% | Testlio, 2025 [27] |
| 手直しが必要なカスタマーサービスボット | 39% | Testlio, 2024 [3] |
| AIの不実表示に対するSECの罰金 | 1,270万ドル | 業界レポート [3] |
| 投資家の信頼が低下した企業 | 54% | 業界レポート [3] |
| ハルシネーション軽減のための従業員1人あたりのコスト | 14,200ドル/年 | Forrester, 2025 [26][28] |
| AIコンテンツの検証に費やす従業員の時間 | 4.3時間/週 | Forbes/AllAboutAI [28] |
| ハルシネーション検出ツール市場の成長 | 318% (2023-2025) | Gartner, 2025 [26] |
| ハルシネーション・プロトコルを備えた企業AIポリシー | 91% | AllAboutAI, 2025 [26] |
| AI導入を遅らせているヘルスケア組織 | 64% | AllAboutAI, 2025 [26] |
| ハルシネーション特化型ソリューションへの投資 | 128億ドル | AllAboutAI, 2023-2025 [4] |
| ハルシネーション削減におけるRAGの有効性 | 71% | AllAboutAI, 2025 [4] |
生産性のパラドックス
残酷な皮肉:AIは私たちをより生産的にするはずでした。しかし現在、従業員はAIが言ったことが本当に正しいかどうかを確認するためだけに、平均して週に4.3時間(労働日の半分以上)を費やしています。これは、純粋な検証オーバーヘッドとして、従業員1人あたり年間約14,200ドルに相当します。AIツールを使用している従業員が500人の会社の場合、AIの宿題をチェックするためだけに年間710万ドルが費やされていることになります。[26][28]
法的インシデント:法廷の危機
数値は改善するどころか悪化している
認識が高まっているにもかかわらず、法的文書におけるAIハルシネーションは加速しています:[29][30]
- 2023年: AIハルシネーションが関与した文書化された裁判判決は10件
- 2024年: 文書化された判決は37件
- 2025年の最初の5ヶ月間: 文書化された判決は73件
- 2025年7月だけで: 偽の引用が関与したケースは50件以上
法律研究者のDamien Charlotin氏は、裁判所がAIによるハルシネーションを起こした引用、捏造された判例、または偽の法的引用を発見した120件以上のケースの公開データベースを維持しています。[30]
誰がこれらの間違いを犯しているのか?
アマチュアからプロフェッショナルへのシフトは憂慮すべきものです:[30]
- 2023年: ハルシネーション事例10件中7件は本人訴訟の当事者によるもので、3件は弁護士によるものでした
- 2025年5月: 発覚した23件中13件は、弁護士および法律専門家の過失でした
注目すべき事例
- Johnson v. Dunn: 弁護士がChatGPTによって生成された偽の法的根拠を含む2つの申し立てを提出。結果:51ページにわたる制裁命令、公の譴責、事件からの解任、ライセンス当局への通報[29]
- Morgan & Morgan (2025年2月): アメリカ最大級の個人傷害法律事務所が、ウォルマートの訴訟において偽のAI生成引用を行ったとしてワイオミング州の連邦判事から制裁の脅しを受けた後、1,000人以上の弁護士に緊急警告を送りました[31]
- 裁判所は、少なくとも5つのケースで1万ドル以上の金銭的制裁を課しており、そのうち4つは2025年のものです[30]
- 事例は、米国、英国、南アフリカ、イスラエル、オーストラリア、スペインで文書化されています[30]
ヘルスケア:ハルシネーションが命を奪いかねない場所
FDAと医療機器に関する懸念
- FDAは2025年末時点で1,357件のAI強化医療機器を承認しており、これは2022年末の2倍に相当します[32]
- ジョンズ・ホプキンス大学、ジョージタウン大学、イェール大学の研究によると、FDAが承認した60のAI医療機器が182件のリコールに関与していたことが判明しました[32]
- これらのリコールの43%は、承認から1年以内に発生しています[32]
- ジョンソン・エンド・ジョンソンのTruDiナビゲーションシステム(AI強化副鼻腔手術装置)は、脳脊髄液漏出、頭蓋骨穿刺、脳卒中を含む、少なくとも10件の負傷と100件の不具合に関連していました[33][32]
医療AIの誤情報
主要なAIモデルが、日焼け止めが皮膚がんを引き起こすと主張したり、5Gを不妊症に結びつけたりといった、危険なほど誤った医療アドバイスを生成するように操作可能であることが判明しました。これには、The Lancetのようなジャーナルからの捏造された引用も含まれていました。[4]
歴史的傾向:進歩は本物だが一様ではない
良いニュース
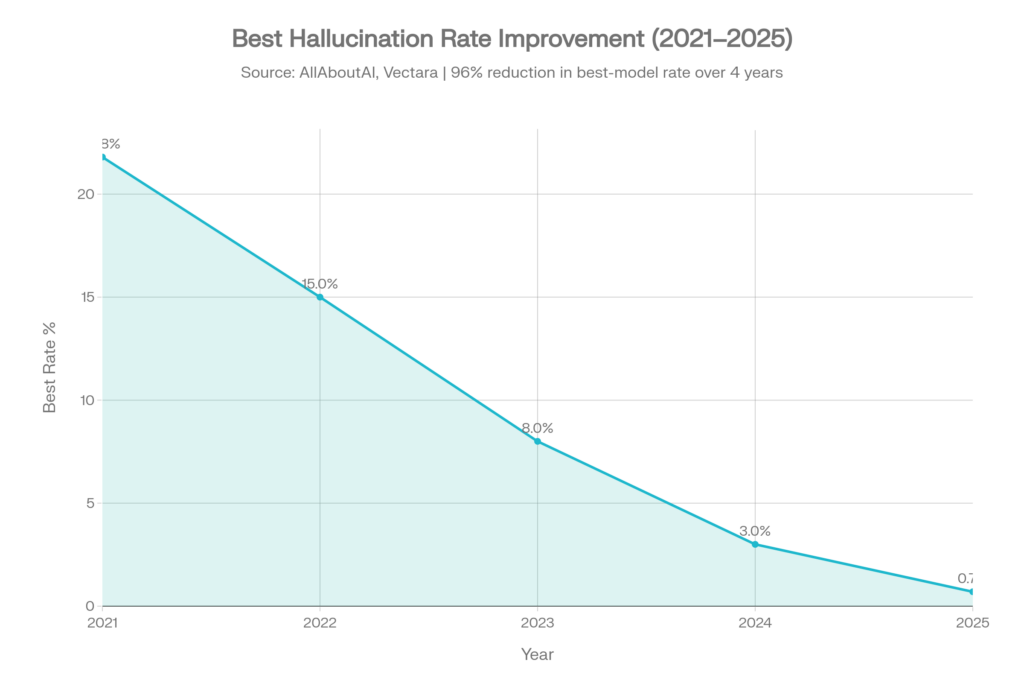
最良モデルのハルシネーション率は劇的に低下しています:[4]
| 年 | 最良ハルシネーション率 | コンテキスト |
| 2021 | 約21.8% | 初期のGPT-3時代 |
| 2022 | 約15.0% | RLHFによる改善 |
| 2023 | 約8.0% | GPT-4と競合の出現 |
| 2024 | 約3.0% | 急速な改善 |
| 2025 | 0.7% | Gemini-2.0-Flashがリード |
これは、4年間で最良モデルのハルシネーション率が96%削減されたことを表しています。[4]
悪いニュース
- 改善はベンダー間で一様ではありません。 一部のClaudeモデルは実際に悪化しました。Vectaraベンチマークにおいて、Claude 3 Sonnetは6.0%から16.3%に、Claude 2は8.5%から17.4%へと、時間の経過とともにほぼ倍増しました。[23]
- 新しい「より困難な」ベンチマークがギャップを明らかにしています。 単純なタスクと実世界の複雑さの間には隔たりがあります。Vectaraの新しいデータセットでは、Gemini-3-Proでさえ13.6%に達します。[12]
- AA-Omniscienceの結果は厳しいものです: 真に困難な質問に対して、40モデル中36モデルが依然として正解よりもハルシネーションを多く起こしています。[6]
- ドメイン別の率は依然として危険なほど高いままです: 法律(平均18.7%)、医療(15.6%)、コーディング(17.8%)。[4]
Grokの軌跡
- Grok-1/2時代: 事実の根拠付けよりも「パーソナリティ主導」のモデルとして位置づけられていました
- Grok-3: Vectaraの旧要約ベンチマークでは2.1%(良好)でしたが、Columbia Journalism Reviewのテストでは引用の正確性が94%でした[10][17]
- Grok-4: Vectaraで4.8%、AA-Omniscienceの難問で64%[16][11]
- Grok 4.1: xAIは「ハルシネーションが3倍減少」と主張し、Clarifaiは約12%から約4%への減少を推定しましたが、AA-OmniscienceではGrok 4.1 Fastで72%を示しました(Grok 4の64%より悪化)[18][19][16]
ベンチマーク間の一貫性のなさは、Grokの改善が一般的ではなくタスク固有のものである可能性を示唆しています。
Suprmind.ai モデルのモデル別サマリー
OpenAIモデル
| モデル | Vectara (旧) | Vectara (新) | AA-Omniscience | 備考 |
| GPT-5 / ChatGPT-5 | 1.4% | >10% | — | 簡単なタスクでは着実な改善が見られますが、難しいタスクでは苦戦しています [11] |
| GPT-5.1 (high) | — | — | ハルシネーション率 51-81%、正確性 35% | ビジネスドメインに最適。Omniscience Indexはプラス [5] |
| GPT-4o | 1.5% | — | — | 主力モデルであり、一貫したパフォーマー [10] |
| o3-mini-high | 0.8% | — | — | 旧Vectaraで最高のOpenAIモデル [10] |
Anthropic Claudeモデル
| モデル | Vectara (旧) | Vectara (新) | AA-Omniscience | 備考 |
| Claude 4.5 Sonnet | — | >10% | ハルシネーション率 48%、正確性 31% | 知識タスクでは中位圏 [16] |
| Claude 4.5 Haiku | — | — | ハルシネーション率 26%(最低!) | 不確実性の管理において最良 [16] |
| Claude Opus 4.5 | — | — | ハルシネーション率 58%、正確性 43% | 正確性は高いが、過信も激しい [16] |
| Claude 4.1 Opus | — | — | Omniscience Index 4.8 | 法律、ソフトウェアエンジニアリング、人文科学で最良 [5] |
| Claude-3.7-Sonnet | 4.4% | — | — | 要約においてまずまずの性能 [10] |
xAI Grokモデル
| モデル | Vectara (旧) | Vectara (新) | AA-Omniscience | その他 |
| Grok 4 | 4.8% | >10% | ハルシネーション率 64%、正確性 40% | 健康・科学分野で最良。Omniscience Indexはプラス [11][16] |
| Grok 4.1 | — | — | ハルシネーション率 72%(Fastバリアント) | xAIは3倍の改善を主張しているが、データは混在している [16][19] |
| Grok 3 | 2.1% | 5.8% | — | ニュース引用テストで94% [17] |
Google Geminiモデル
| モデル | Vectara (旧) | Vectara (新) | AA-Omniscience | 備考 |
| Gemini 3 Pro | — | 13.6% | ハルシネーション率 88%、正確性 53%、Index: 13 | 最高の正確性だが、極端な過信が見られる [5][12] |
| Gemini 2.5-Pro | 1.1% | — | — | 旧ベンチマークで強力 [10] |
| Gemini 2.5-Flash | 1.3% | — | — | [10] |
| Gemini 2.5-Flash-Lite | — | 3.3% | — | 新Vectaraベンチマークで最良 [13] |
Perplexity / Sonar
- Perplexity独自のモデルについては、VectaraやAA-Omniscienceの直接的な掲載はありません
- Perplexityは基盤となるモデルを使用しています(歴史的には、Vectaraで約14.3%のハルシネーション率を示すDeepSeek-R1などを含みます)[34]
- Columbia Journalism Reviewのテスト:Perplexityは引用の正確性において37%のハルシネーション率(そのテストでは最良ですが、依然として3つに1つは誤り)[20]
- Perplexity Pro:同じテストで45%のハルシネーション率[20]
- 独自のリスクプロファイル:「実在するソースを捏造された主張と共に引用する」— URLは本物ですが、帰属する情報は作り話です[21]
最も危険なハルシネーション:気づかないもの
データは、ほとんどのAIユーザーが見落としている重要な洞察を明らかにしています。ハルシネーションは時折発生するバグではなく、これらのモデルがどのように機能するかという根本的な特徴であるということです。これを示す主要な統計は以下の通りです:
- エグゼクティブの47%が、ハルシネーションを起こしたAIコンテンツに基づいて行動しています。つまり、AIを活用したビジネス上の意思決定の約半分が、捏造された土台の上に築かれている可能性があります[1]
- AIのバグの82%は、クラッシュや目に見えるエラーではなく、ハルシネーションや正確性の欠如に起因しています。システムは完璧に動作しているように見えながら、間違った答えを出しているのです[27]
- 従業員1人あたり週4.3時間がAI出力の検証に費やされています。しかもこれは、チェックすべきだと知っている組織での話です[28]
- 重大なハルシネーション事件1件あたりの平均コストは、カスタマーサービスでの18,000ドルから、医療過誤での240万ドルにまで及びます[1]
ダウンロード可能なデータ資産
コンテンツ開発の生のデータ基盤として、3つのCSVファイルが用意されています:
- ai_hallucination_data.csv — すべてのベンチマークにおけるモデル別の包括的なハルシネーション率
- domain_hallucination_rates.csv — トップモデル対全モデルのドメイン別ハルシネーション率
- business_impact_data.csv — 出典と年次を含む22の主要なビジネス影響指標
主要用語集
| 用語 | 定義 |
| ハルシネーション | 事実として誤っている、あるいは捏造されたAI生成コンテンツが、自信を持って提示されること |
| 根拠のあるハルシネーション | 提供された文書の要約中に導入される誤った情報 |
| 事実のハルシネーション | 現実に根拠のない、捏造された事実、統計、または引用 |
| RAG (検索拡張生成) | ハルシネーションを減らすためにAIを外部ナレッジベースに接続する技術。ハルシネーション率を約71%削減します [4] |
| HHEM (Hughes Hallucination Evaluation Model) | 要約におけるハルシネーションを検出するためのVectaraのモデル(スコア0-1、0.5未満はハルシネーション) [8] |
| Omniscience Index | 正解を評価し、自信満々な誤答を罰するAA-Omniscienceの指標(-100から+100) [6] |
| 事実の一貫性率 | 100%からハルシネーション率を引いたもの。ソース資料に忠実な出力の割合 |
| 推論コスト | 「思考」モデルの方が、根拠のあるタスクにおいてハルシネーションを多く起こすという観察された現象 [15] |
| 追従性(Sycophancy) | ユーザーが間違っている場合でも、ユーザーに同意しようとするモデルの傾向 |
| モデル崩壊 | モデルがAI生成コンテンツでトレーニングされたときに起こる、段階的な品質低下 |
ソースサマリー
参照された主なベンチマークと研究:
- Vectara HHEM Leaderboard(オリジナルおよび更新されたデータセット、2023-2026年)[10][12][13]
- AA-Omniscience Benchmark by Artificial Analysis(2025年11月)[5][6]
- AllAboutAI Hallucination Report 2026(包括的な業界分析)[4]
- Columbia Journalism Review 引用の正確性調査(2025年3月)[20][17]
- Stanford RegLab/HAI 法的ハルシネーション研究[25][9]
- Deloitte Global Survey 企業のAI意思決定に関する調査[26]
- Forrester Research ハルシネーション軽減の経済的影響に関する調査[26]
- Gartner AI Market Analysis 検出ツール市場の成長に関する分析[26]
- MedRxiv 2025 医療症例のハルシネーションに関する研究[23]
- International Journal of Data Science and Analytics 金融AIハルシネーションに関する研究[17]
- ECRI 2025年医療技術ハザードレポート[24]
- Reuters 法的AIインシデントに関する報道[31]
- Business Insider 裁判所でのAIハルシネーション事例データベース[30]
- VinciWorks 2025年7月の法的引用危機の分析[29]





