Dernière mise à jour le 26 avril 2026
Les références complètes sur les données d'hallucination de l'IA. Chiffres bruts de Vectara,
AA-Omniscience, FACTS, fiches système d'OpenAI et plus de 50 sources.
Mis à jour mensuellement.
Mise à jour d'avril 2026 ajoutée : données Stanford AI Index, Claude Opus 4.7, Grok 4.20,
paradoxe GPT-5.5, escalade des affaires juridiques, intégration de l'indice de divergence multi-modèles
Chaque modèle d'IA majeur hallucine. L'IA générative, par sa conception même, ne peut être exempte d'hallucinations — mais le risque peut être atténué avant qu'il n'affecte votre décision et ne vous coûte de l'argent. Découvrez comment la vérification multi-modèles fonctionne comme stratégie d'atténuation.
Cette page suit les taux d'hallucination sur six critères d'évaluation, couvre chaque modèle Frontier de GPT-5.5 à Claude 4.7, Gemini 3.1 et Grok 4.20, et présente les données sans parti pris. Les chiffres ne concordent pas entre eux — et nous expliquons pourquoi cela est plus important que n'importe quel classement unique.
Chaque chiffre ci-dessous provient d'un critère d'évaluation différent mesurant un aspect différent de l'hallucination. Un faible Vectara + une forte hallucination AA-Omniscience signifie que le modèle est bon en synthèse mais mauvais pour admettre son ignorance. Un FACTS élevé + une faible précision AA-Omniscience signifie que le modèle est précis avec les outils mais tente trop de questions. Aucune colonne unique ne raconte toute l'histoire. Croisez au moins deux références.
Guide des colonnes :
| Modèle | Fournisseur | Vectara (Ancien) | Vectara (Nouveau) | AA-Omni Acc | AA-Omni Hall | AA-Omni Index | FACTS | HalluHard | Citation CJR |
|---|---|---|---|---|---|---|---|---|---|
| GPT-5.3 Codex | OpenAI | – | – | 51.8% | – | – | – | – | – |
| GPT-5.5 (xhigh) | OpenAI | – | – | 57% | 86% | 20 | – | – | – |
| GPT-5.2 (xhigh) | OpenAI | – | 10.8% | 43.8% | ~78% | – | 61.8 | 38.2% | – |
| GPT-5 | OpenAI | 1.4% | >10% | 40.7% | – | – | 61.8 | – | – |
| GPT-5.1 | OpenAI | – | – | 37.6% | 81% | Positif | 49.4 | – | – |
| GPT-4.1 | OpenAI | 2.0% | 5.6% | – | – | – | 50.5 | – | – |
| o3-mini-high | OpenAI | 0.8% | 4.8% | – | – | – | 52.0 | – | – |
| Claude 4.1 Opus | Anthropic | – | – | – | 0% | – | 46.5 | – | – |
| Claude Opus 4.6 | Anthropic | – | 12.2% | 46.4% | – | 14 | – | – | – |
| Claude Opus 4.7 | Anthropic | – | – | – | 36% | 26 | – | – | – |
| Claude Opus 4.5 | Anthropic | – | – | 45.7% | 58% | Négatif | 51.3 | 30% | – |
| Claude Sonnet 4.6 | Anthropic | – | 10.6% | 40.0% | ~38% | – | – | – | – |
| Claude Sonnet 4.5 | Anthropic | – | >10% | – | 48% | – | 49.1 | – | – |
| Claude 3.7 Sonnet | Anthropic | 4.4% | – | – | – | – | – | – | – |
| Claude 4.5 Haiku | Anthropic | – | – | – | 25% | – | – | – | – |
| Gemini 3.1 Pro | – | 10.4% | 55.3% | 50% | 33 | – | – | – | |
| Gemini 3 Pro | – | 13.6% | 55.9% | 88% | 16 | 68.8 | – | – | |
| Gemini 3 Flash | – | – | 54.0% | 91% | – | – | – | – | |
| Gemini 2.5 Pro | – | 7.0% | – | – | – | 62.1 | – | – | |
| Gemini 2.0 Flash | 0.7% | 3.3% | – | – | – | – | – | – | |
| Grok 4 | xAI | 4.8% | >10% | 41.4% | 64% | Positif | 53.6 | – | – |
| Grok 4.1 Fast | xAI | – | 20.2% | – | 72% | – | 36.0 | – | – |
| Grok 4.20 (Reasoning) | xAI | – | – | – | 17% | – | – | – | – |
| Grok-3 | xAI | 2.1% | 5.8% | – | – | – | – | – | 94% |
| Perplexity Sonar Pro | Perplexity | – | – | – | – | – | – | – | 37% |
| DeepSeek-V3 | DeepSeek | 3.9% | 6.1% | – | – | – | – | – | – |
| DeepSeek-R1 | DeepSeek | 14.3% | 11.3% | – | 83% | – | – | – | – |
| Llama 4 Maverick | Meta | 4.6% | – | – | 87.6% | – | – | – | – |
Sources : Vectara HHEM Leaderboard (avril 2025 + fév. 2026 + 20 avril 2026) [1], Artificial Analysis AA-Omniscience (nov. 2025 – avril 2026) [2], Google DeepMind FACTS Benchmark (déc. 2025) [3], HalluHard Benchmark (2025) [5], Columbia Journalism Review (mars 2025) [6]. Les tirets indiquent l'absence de données publiées sur ce critère pour ce modèle.
Taux d'hallucination le plus bas (tâches de connaissance) : Claude 4.1 Opus – 0 % sur AA-Omniscience (le modèle refuse de répondre en cas d'incertitude)
Plus grande amélioration unique : Gemini 3.1 Pro – l'hallucination a chuté de 38 points de pourcentage (88 % à 50 %) avec une perte de précision de 1 %
Taux d'hallucination le plus bas (lorsque les modèles tentent de répondre) : Grok 4.20 (Raisonnement) – 17 % sur AA-Omniscience (avril 2026)
Plus grande variable parmi tous les modèles : Accès à la recherche web – réduit l'hallucination de 73 à 86 % lorsqu'il est activé
Meilleure précision des citations : Perplexity Sonar Pro – 37 % d'hallucination sur CJR (le plus bas, mais toujours élevé)
Taux d'hallucination le plus bas (synthèse) : Gemini-2.0-Flash – 0,7 % sur le jeu de données original de Vectara
Meilleur dans les conversations réalistes : Claude Opus 4.5 – 30 % sur HalluHard (avec recherche web)
Meilleur indice de fiabilité des connaissances : Gemini 3.1 Pro – indice 33 sur AA-Omniscience
Score de facticité le plus élevé (multi-dimensionnel) : Gemini 3 Pro – 68,8 sur FACTS
Suprmind réduit les hallucinations en plaçant cinq modèles Frontier dans la même conversation structurée, où ils remettent en question les affirmations des uns et des autres, révèlent les contradictions, expriment des désaccords et testent les conclusions avant que le résultat n'atteigne votre travail.
Lorsque les modèles d'IA sont en désaccord, ce désaccord révèle la complexité et des segments souvent négligés du sujet ou d'un problème.
Suprmind le révèle, le quantifie et, en trois clics, le transforme en un livrable professionnel — afin que les questions difficiles soient résolues avant que la décision ne soit prise.
Écouter la recherche complète (51 min)
Une hallucination IA se produit lorsqu'un modèle d'IA invente quelque chose et le présente comme un fait. Il ne signale pas d'incertitude. Il ne dit pas « Je suppose ». Il fournit des statistiques fabriquées, des affaires juridiques inventées ou des documents de recherche inexistants avec la même confiance qu'il utilise pour l'arithmétique de base. Le résultat est parfait. C'est ce qui le rend dangereux.
L'hallucination fait référence à une sortie générée qui n'est pas fondée sur l'entrée fournie ou la réalité factuelle. Deux types :
Hallucination intrinsèque (échec de fidélité) : Le modèle contredit des informations qui lui ont été explicitement données. Donnez-lui un contrat et demandez un résumé — il ajoute des clauses qui n'existent pas dans le document original.
Hallucination extrinsèque (échec de facticité) : Le modèle génère des informations qui ne peuvent être vérifiées par aucune source connue. Il invente des faits, des statistiques, des citations ou des événements de toutes pièces. Aucun matériel source n'a été contredit car aucun matériel source n'a été consulté.
Des chercheurs du MIT ont découvert quelque chose de perturbant en janvier 2025 : les modèles d'IA utilisent un langage plus confiant lorsqu'ils hallucinent que lorsqu'ils énoncent des faits. Les modèles étaient 34 % plus susceptibles d'utiliser des phrases comme « absolument », « certainement » et « sans aucun doute » lors de la génération d'informations incorrectes.
Plus l'IA se trompe, plus elle semble certaine.
Les grands modèles de langage sont des moteurs de prédiction, pas des bases de connaissances. Ils génèrent du texte en prédisant le jeton statistiquement le plus probable suivant en se basant sur des modèles dans les données d'entraînement. Ils ne comprennent pas la vérité. Ils prédisent la plausibilité.
Lorsque le modèle atteint une lacune dans ses données d'entraînement ou fait face à une requête ambiguë, il comble cette lacune avec quelque chose de plausible plutôt que d'admettre qu'il ne sait pas. L'architecture n'a aucun mécanisme pour « Je ne suis pas sûr » — il choisit simplement le prochain mot le plus probable.
Et ce n'est pas un bug qui sera corrigé dans la prochaine mise à jour. Deux preuves mathématiques indépendantes ont maintenant démontré que l'hallucination est une limitation fondamentale, prouvable de l'architecture. Pas un manque d'ingénierie. Une certitude mathématique. (Plus d'informations dans la section Impossibilité mathématique ci-dessous.) [20][21]
Avant d'examiner les données sur les hallucinations, vous devez comprendre pourquoi différents critères d'évaluation donnent des scores très différents pour le même modèle.
Grok-3 obtient 2,1 % sur le critère de synthèse Vectara. Excellent. Le même modèle obtient 94 % sur le test de précision des citations de la Columbia Journalism Review. Catastrophique. Même modèle, même période, conclusions opposées.
Ce n'est pas une erreur. C'est mesurer des choses différentes. Et traiter un seul critère d'évaluation comme « le taux d'hallucination » vous induira en erreur.
Le tableau ci-dessous résume ce que chaque critère d'évaluation teste réellement. Cliquez sur n'importe quel nom de critère pour accéder à sa section dédiée.
| Critère | Ce qu'il mesure | Pour | Pas pour |
|---|---|---|---|
| Vectara HHEM | Fidélité de la synthèse — le modèle ajoute-t-il des faits non étayés lors de la synthèse de documents sources ? | Pipelines RAG, questions-réponses sur documents, recherche en base de connaissances | Questions de connaissance ouvertes |
| AA-Omniscience | Lorsque le modèle ne connaît pas une réponse, l'admet-il ou en fabrique-t-il une ? L'indice Omniscience pénalise les mauvaises réponses et récompense le refus. | Travail consultatif à forts enjeux — juridique, médical, financier | Synthèse ou tâches ancrées |
| FACTS | Facticité multi-dimensionnelle à travers l'ancrage, le multimodal, le paramétrique et la recherche. Chaque dimension notée séparément. | Comparer les points forts et faibles des modèles selon les types de tâches | Produire un taux d'hallucination unique |
| SimpleQA / PersonQA | Questions factuelles courtes et précision sur des personnes réelles. Les modèles de raisonnement récents se comportent souvent moins bien que leurs prédécesseurs. | Tests de factualité rapides sur des questions simples | Requêtes complexes, multi-étapes ou spécifiques à un domaine |
| HalluHard | Taux d'hallucination dans des contextes conversationnels réalistes. Même le meilleur modèle hallucine encore 30 % du temps. | Prédire les taux réels en production dans les applications de chat | Comparaisons de modèles contrôlées et reproductibles |
| Citation CJR | Si les modèles d'IA attribuent correctement les informations aux sources citées. Mode d'échec : vraies URL avec du contenu fabriqué associé. | Recherche, journalisme, toute tâche d'attribution de sources | Évaluation des connaissances générales ou de la synthèse |
Sources : Vectara HHEM [1], AA-Omniscience [2], FACTS [3], SimpleQA/PersonQA [4], HalluHard [5], CJR Citation Study [6]
TruthfulQA était autrefois l'étalon-or. Il est maintenant partiellement saturé — les modèles ont été entraînés sur ses questions. Pire encore, des chercheurs ont montré qu'un arbre de décision simple peut obtenir 79,6 % sur TruthfulQA à choix multiples sans même voir la question posée, simplement en exploitant les schémas structurels dans le formatage des réponses. Citer les scores TruthfulQA pour les modèles 2025-2026 est peu fiable. [29]
HaluEval a un problème similaire. Un classificateur basé sur la longueur atteint 93,3 % de précision sur HaluEval QA en signalant simplement les réponses de plus de 27 caractères comme hallucinées. Le critère mesure la longueur des réponses plus que la véracité. [30]
Aucun critère d'évaluation unique ne vous donne « le taux d'hallucination » d'un modèle. Si quelqu'un cite un seul chiffre, il simplifie par commodité ou cherry-picks pour le marketing.
L'approche responsable : recoupez au moins deux critères d'évaluation mesurant des choses différentes (une tâche ancrée comme Vectara, une tâche de connaissance ouverte comme AA-Omniscience), précisez la version exacte du modèle et les conditions d'appel, et notez si l'accès aux outils était activé. Les sections qui suivent font exactement cela.
Le classement Vectara est le critère d'évaluation des hallucinations le plus cité dans l'industrie. Il mesure la fidélité de la synthèse — à partir d'un document source, le résumé du modèle respecte-t-il ce qui est réellement dans le document, ou ajoute-t-il des faits non étayés ? Cela en fait un proxy direct pour le comportement de l'IA dans les pipelines RAG, les outils de recherche en entreprise et les flux de travail d'analyse de documents. Le classement existe en deux versions, et l'écart entre elles raconte une histoire importante. [1]
C'est le jeu de données que la plupart des articles référencent lorsqu'ils citent des taux d'hallucination. Les documents sont relativement courts et les tâches de synthèse sont simples.
| Modèle | Fournisseur | Taux d'hallucination | Cohérence factuelle |
|---|---|---|---|
| Gemini-2.0-Flash-001 | 0.7% | 99.3% | |
| Gemini-2.0-Pro-Exp | 0.8% | 99.2% | |
| o3-mini-high | OpenAI | 0.8% | 99.2% |
| Gemini-2.5-Pro-Exp | 1.1% | 98.9% | |
| GPT-4.5-Preview | OpenAI | 1.2% | 98.8% |
| Gemini-2.5-Flash-Preview | 1.3% | 98.7% | |
| o1-mini | OpenAI | 1.4% | 98.6% |
| GPT-5 / ChatGPT-5 | OpenAI | 1.4% | 98.6% |
| GPT-4o | OpenAI | 1.5% | 98.5% |
| GPT-4o-mini | OpenAI | 1.7% | 98.3% |
| GPT-4-Turbo | OpenAI | 1.7% | 98.3% |
| GPT-4 | OpenAI | 1.8% | 98.2% |
| antgroup/finix_s1_32b | Ant Group | 1.8% | 98.2% |
| Grok-2 | xAI | 1.9% | 98.1% |
| GPT-4.1 | OpenAI | 2.0% | 98.0% |
| Grok-3-Beta | xAI | 2.1% | 97.8% |
| GPT-5.4-nano | OpenAI | 3.1% | 96.9% |
| Claude-3.7-Sonnet | Anthropic | 4.4% | 95.6% |
| Claude-3.5-Sonnet | Anthropic | 4.6% | 95.4% |
| o4-mini | OpenAI | 4.6% | 95.4% |
| Llama-4-Maverick | Meta | 4.6% | 95.4% |
| Grok-4 | xAI | 4.8% | ~95.2% |
| Claude-3.5-Haiku | Anthropic | 4.9% | 95.1% |
| Gemma-4-26B | 5.2% | 94.8% | |
| DeepSeek-V3.2-Exp | DeepSeek | 5.3% | 94.7% |
| Qwen3-14B | Qwen/Alibaba | 5.4% | 94.6% |
| GPT-5.4-mini | OpenAI | 5.5% | 94.5% |
| Claude-3-Opus | Anthropic | 10.1% | 89.9% |
| DeepSeek-R1 | DeepSeek | 14.3% | 85.7% |
Source : Vectara HHEM Leaderboard, dépôt GitHub, jeu de données d'avril 2025 (dernière mise à jour le 20 avril 2026 avec l'ajout du finix_s1_32b du groupe Ant en tête à 1,8 %) [1]
Sur ce jeu de données, les chiffres semblent encourageants. Les modèles Gemini de Google dominent les trois premières places. La famille GPT d'OpenAI se regroupe entre 0,8 % et 2,0 %. Même les moins bons restent sous 15 %.
Mise à jour d'avril 2026 : le finix_s1_32b du groupe Ant a rejoint le classement à 1,8 % de taux d'hallucination, la première fois qu'un modèle d'entreprise chinois rivalise pour la première place sur le jeu de données original de Vectara. Le GPT-5.4 nano d'OpenAI (3,1 %) est entré nettement plus haut que GPT-4.1 (2,0 %), confirmant le schéma selon lequel les variantes OpenAI récentes et plus petites hallucinent souvent plus que les modèles de base plus anciens — conforme à la « taxe de raisonnement » discutée dans la section 10. [1]
Mais ce jeu de données est facile. Les documents sont courts, les tâches de synthèse sont propres, et le monde réel n'est ni l'un ni l'autre.
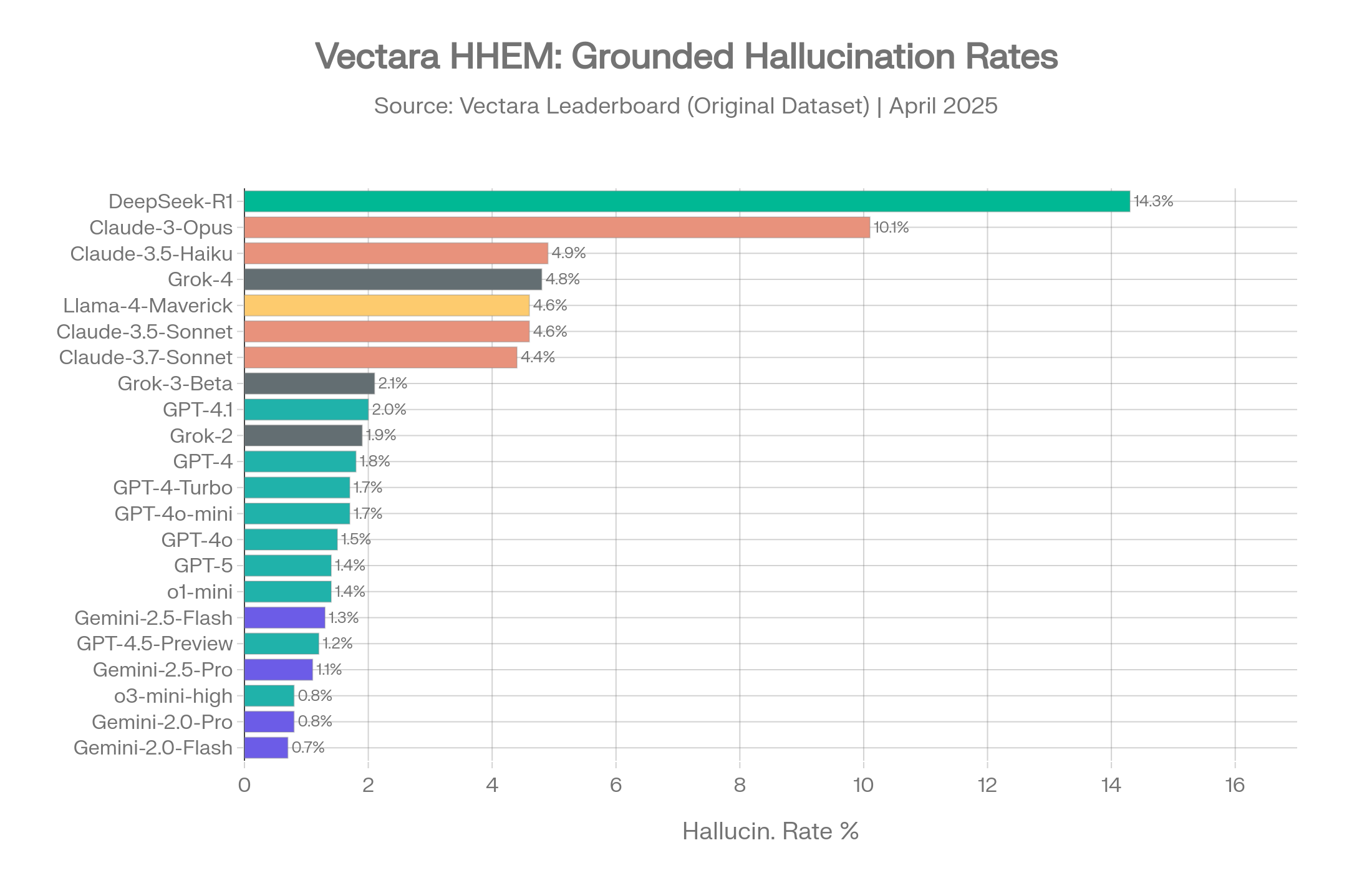
Classement HHEM Vectara : Classement complet des modèles avec code couleur par fournisseur sur le jeu de données original. Source : Vectara [1]
Vectara a lancé un benchmark actualisé fin 2025 avec des documents plus longs (jusqu'à 32 000 jetons) couvrant le droit, la médecine, la finance, la technologie et l'éducation. Cette version reflète mieux ce à quoi les systèmes d'IA en entreprise sont réellement confrontés.
Les taux ont augmenté sur l'ensemble du tableau :
| Modèle | Fournisseur | Taux d'hallucination |
|---|---|---|
| Gemini-2.5-Flash-Lite | 3.3% | |
| Mistral-Large | Mistral | 4.5% |
| DeepSeek-V3.2-Exp | DeepSeek | 5.3% |
| GPT-4.1 | OpenAI | 5.6% |
| Grok-3 | xAI | 5.8% |
| DeepSeek-R1-0528 | DeepSeek | 7.7% |
| Claude Sonnet 4.5 | Anthropic | >10% |
| GPT-5 | OpenAI | >10% |
| Grok-4 | xAI | >10% |
| Gemini-3-Pro | 13.6% |
Source : Vectara Hallucination Leaderboard, nouveau jeu de données, novembre 2025 [1]
L'instantané Vectara le plus récent ajoute les derniers modèles Frontier à l'évaluation du nouveau jeu de données :
| Modèle | Fournisseur | Taux d'hallucination |
|---|---|---|
| o3-mini-high | OpenAI | 4.8% |
| GPT-4.1 | OpenAI | 5.6% |
| Grok-3 | xAI | 5.8% |
| DeepSeek-V3 | DeepSeek | 6.1% |
| Command R+ | Cohere | 6.9% |
| Gemini 2.5 Pro | 7.0% | |
| Llama 4 Scout | Meta | 7.7% |
| GPT-5.2-low | OpenAI | 8.4% |
| Gemini 3.1 Pro Preview | 10.4% | |
| Claude Sonnet 4.6 | Anthropic | 10.6% |
| GPT-5.2-high | OpenAI | 10.8% |
| DeepSeek-R1 | DeepSeek | 11.3% |
| Claude Opus 4.6 | Anthropic | 12.2% |
| Grok-4-fast-reasoning | xAI | 20.2% |
Source : Vectara HHEM Leaderboard, instantané du rapport de recherche du 25 fév. 2026 [1]
Le nouveau jeu de données a mis en évidence quelque chose de contre-intuitif : les modèles de raisonnement — ceux commercialisés comme les plus capables — sont systématiquement moins bons sur la synthèse ancrée. GPT-5, Claude Sonnet 4.5, Grok-4 et Gemini-3-Pro ont tous dépassé 10 %. La variante Grok-4-fast-reasoning a atteint 20,2 %. [48][49]
L'hypothèse est simple. Les modèles de raisonnement investissent un effort computationnel à « réfléchir » aux réponses. Lors de la synthèse, cette réflexion les amène à ajouter des inférences, à établir des connexions et à générer des insights qui vont au-delà du contenu du document source. C'est utile pour l'analyse. C'est une hallucination sur un benchmark de synthèse.
Cela crée une décision critique pour les équipes d'entreprise : le mode de raisonnement aide sur les tâches ouvertes et nuit sur les tâches ancrées. Savoir quand l'activer et quand le désactiver n'est pas optionnel.
AA-Omniscience pose une question fondamentalement différente de Vectara. Au lieu de « puis-je synthétiser sans rien ajouter », il demande « lorsque tu ne sais pas quelque chose, l'admets-tu ou inventes-tu quelque chose ? » [2]
Le benchmark couvre 6 000 questions sur 42 sujets dans six domaines. L'indice Omniscience (échelle : -100 à +100) pénalise les mauvaises réponses et ne pénalise pas le refus. C'est le seul grand benchmark qui récompense explicitement les modèles pour connaître leurs propres limites.
| Modèle | Fournisseur | Précision | Taux d'hallucination | Indice Omniscience |
|---|---|---|---|---|
| Gemini 3 Pro Preview (high) | 55.9% | 88% | 16 | |
| Gemini 3.1 Pro Preview | 55.3% | 50% | 33 | |
| Gemini 3 Flash (Reasoning) | 54.0% | 92% | – | |
| GPT-5.5 (xhigh) | OpenAI | 57% | 86% | 20 |
| GPT-5.3 Codex (xhigh) | OpenAI | 51.8% | – | – |
| Claude Opus 4.6 (max) | Anthropic | 46.4% | – | 14 |
| Claude Opus 4.7 (Adaptive Reasoning, Max) | Anthropic | ~47% | 36% | 26 |
| Claude Opus 4.5 (thinking) | Anthropic | 45.7% | 58% | Négatif |
| GPT-5.2 (xhigh) | OpenAI | 43.8% | – | – |
| Grok 4 | xAI | 41.4% | 64% | Positif |
| Claude Opus 4.5 | Anthropic | 40.7% | – | – |
| GPT-5 (high) | OpenAI | 40.7% | – | – |
| Claude Sonnet 4.6 (max) | Anthropic | 40.0% | – | – |
| Claude Sonnet 4.6 | Anthropic | 38.0% | ~38% | – |
| GPT-5.1 (high) | OpenAI | 37.6% | 81% | Positif |
Source : Artificial Analysis AA-Omniscience, novembre 2025 – avril 2026 [2]
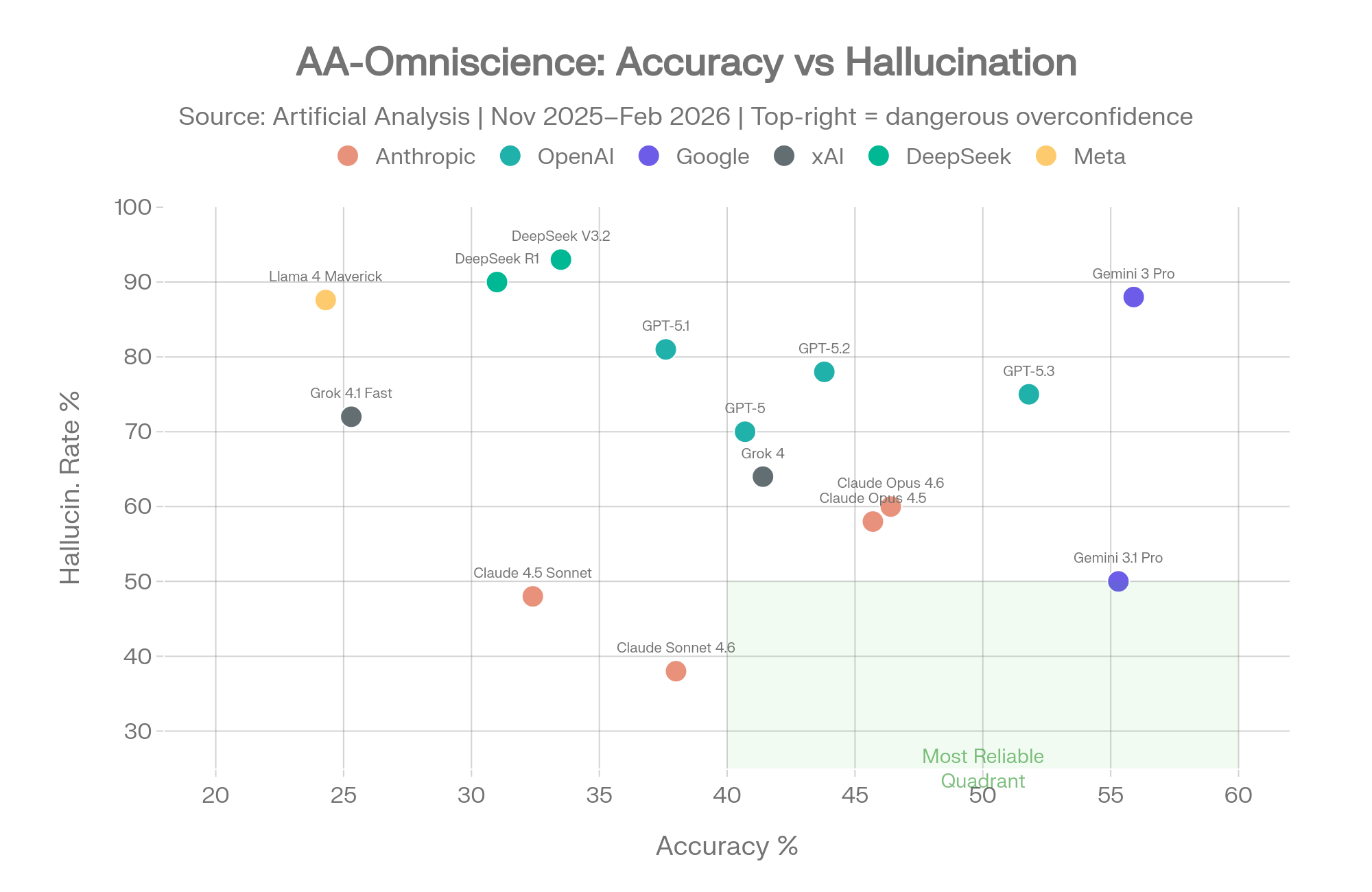
AA-Omniscience : Précision vs taux d'hallucination. Le quadrant vert montre les modèles fiables. Source : Artificial Analysis [2]
| Modèle | Fournisseur | Taux d'hallucination |
|---|---|---|
| Claude 4.1 Opus (Raisonnement) | Anthropic | 0%* |
| Claude 4 Opus (Raisonnement) | Anthropic | 0%* |
| Claude 4.5 Haiku | Anthropic | 25% |
| Claude Sonnet 4.6 | Anthropic | ~38% |
| Claude 4.5 Sonnet | Anthropic | 48% |
| Gemini 3.1 Pro Preview | 50% | |
| Claude Opus 4.5 | Anthropic | 58% |
| Grok 4 | xAI | 64% |
| Grok 4.1 Fast | xAI | 72% |
| DeepSeek R1 0528 | DeepSeek | 83% |
| Llama 4 Maverick | Meta | 87.6% |
| Gemini 3 Pro Preview | 88% |
Note : Le taux d'hallucination dans AA-Omniscience mesure la fréquence à laquelle le modèle répond incorrectement alors qu'il aurait dû refuser — la proportion de réponses incorrectes sur toutes les réponses non correctes. Il s'agit d'une métrique de surconfiance. *Astérisque : Claude 4.1 Opus atteint 0 % en refusant toutes les questions incertaines — il produit moins d'hallucinations en répondant à moins de questions. Grok 4.20 (Raisonnement) atteint 17 % tout en tentant une proportion plus élevée de réponses (avril 2026). La stratégie optimale dépend de ce qui est le plus coûteux : refuser de répondre ou donner des réponses erronées. Source : Artificial Analysis AA-Omniscience [2]
Gemini 3 Pro raconte l'histoire la plus intéressante dans ces données. Il a atteint la plus haute précision (55,9 %) avec une large marge — il en sait plus que tout autre modèle testé. Mais il a également montré un taux d'hallucination de 88 %. Lorsqu'il ne connaît pas une réponse, il en fabrique une 88 % du temps plutôt que d'admettre son incertitude. [2]
Haute connaissance + faible conscience de soi = un modèle brillant quand il a raison et dangereux quand il a tort.
La mise à jour de Gemini 3.1 Pro a partiellement résolu ce problème. Le réglage de calibration de Google a réduit le taux d'hallucination de 88 % à 50 % tout en maintenant une précision presque identique (55,3 % contre 55,9 %). L'indice Omniscience est passé de 16 à 33 — le plus élevé de tous les modèles. Cela a prouvé qu'une réduction spectaculaire des hallucinations est possible sans sacrifice significatif de la précision. [15]
GPT-5.5, publié par OpenAI début 2026, affiche la plus haute précision jamais enregistrée sur AA-Omniscience à 57 %. Il affiche également un taux d'hallucination de 86 % sur le même critère — l'écart le plus extrême entre précision et calibration jamais observé. Lorsque GPT-5.5 ne connaît pas une réponse, il en fabrique une 86 % du temps. Le schéma de Gemini 3 Pro (connaissance sans conscience de soi) semble s'être intensifié avec la dernière génération de modèles à haute capacité. [2][63]
Claude Opus 4.7, publié par Anthropic le 16 avril 2026, adopte le compromis inverse : 36 % de taux d'hallucination sur le même critère, avec une précision brute légèrement inférieure. Les deux décisions de publication, à six semaines d'intervalle, représentent la division la plus claire à ce jour entre l'optimisation de ce qu'un modèle sait et ce qu'un modèle sait de ses propres limites. [58][63]
Aucun modèle unique ne domine tous les domaines de connaissance :
| Domaine | Meilleur modèle |
|---|---|
| Droit | Claude 4.1 Opus |
| Ingénierie logicielle | Claude 4.1 Opus |
| Sciences humaines et sociales | Claude 4.1 Opus |
| Affaires | GPT-5.1.1 |
| Santé | Grok 4 |
| Sciences et mathématiques | Grok 4 |
Source : Artificial Analysis AA-Omniscience [2]
Les modèles Claude sont en tête dans les domaines où le raisonnement précis et la précision des citations sont importants. Grok est en tête dans les domaines où la couverture étendue des connaissances est importante. GPT est en tête dans les applications commerciales. Cette fragmentation est en soi une donnée — cela signifie qu'aucun modèle unique n'est le choix le plus sûr pour chaque cas d'utilisation professionnelle.
La précision est corrélée à la taille du modèle. Le taux d'hallucination ne l'est pas.
Les modèles plus grands en savent plus, mais ils ne savent pas nécessairement ce qu'ils ne savent pas.
Jeter plus de paramètres sur le problème augmente les connaissances sans augmenter la conscience de soi. C'est pourquoi le problème des hallucinations ne disparaîtra pas simplement avec la prochaine génération de modèles.
Le critère FACTS de Google DeepMind, publié en décembre 2025, adopte une approche différente de la plupart des évaluations : au lieu de produire un seul score d'hallucination, il divise la facticité en quatre dimensions distinctes. Cette vue multi-dimensionnelle révèle que les modèles ont des forces considérablement différentes selon le type de tâche. Grok 4 obtient 75,3 sur la recherche mais seulement 25,7 sur le multimodal — un écart de 50 points au sein du même modèle. [3]
Ancrage : Le modèle peut-il utiliser fidèlement les informations des documents fournis ? Testé par des tâches de synthèse et d'extraction avec du matériel source.
Multimodal : Le modèle peut-il décrire et raisonner avec précision sur le contenu visuel en plus du texte ?
Paramétrique : Les connaissances internes du modèle (stockées dans ses poids d'entraînement) produisent-elles des réponses correctes sans outils externes ?
Recherche : Quelle est la précision du modèle lorsqu'il a accès à la recherche web et aux outils de récupération ?
| Modèle | Global | Ancrage | Multimodal | Paramétrique | Recherche |
|---|---|---|---|---|---|
| Gemini 3 Pro | 68.8 | 69.0 | 46.1 | 76.4 | 83.8 |
| Gemini 2.5 Pro | 62.1 | – | – | – | – |
| GPT-5 | 61.8 | – | – | – | 77.7 |
| Grok 4 | 53.6 | – | – | – | 75.3 |
| GPT o3 | 52.0 | 36.2 | – | 57.1 | – |
| Claude 4.5 Opus | 51.3 | – | – | – | – |
| GPT 4.1 | 50.5 | – | – | – | – |
| Gemini 2.5 Flash | 50.4 | – | – | – | – |
| GPT 5.1 | 49.4 | – | – | – | – |
| Claude 4.5 Sonnet Thinking | 49.1 | – | – | – | – |
| Claude 4.1 Opus | 46.5 | – | – | – | – |
| GPT 5 mini | 45.9 | – | – | – | – |
| Claude 4 Sonnet | 42.8 | – | – | – | – |
| GPT o4 mini | 37.6 | – | – | – | – |
| Grok 4 Fast | 36.0 | – | – | – | – |
Note : Les tirets indiquent que les scores au niveau des tranches ne sont pas rapportés séparément dans les sources publiées. Le score FACTS global est un agrégat des quatre tranches. Source : Suite de benchmarks FACTS, décembre 2025 [3]
Aucun modèle ne dépasse 70 %. Le meilleur score sur FACTS est de 68,8 pour Gemini 3 Pro. Chaque modèle se trompe plus de 30 % du temps sur cette évaluation de facticité multi-dimensionnelle.
La recherche est la tranche la plus forte pour tous. Gemini 3 Pro atteint 83,8 et GPT-5 atteint 77,7 sur la facticité activée par la recherche. Lorsque les modèles peuvent rechercher des informations, ils sont matériellement plus précis. Lorsqu'ils ne comptent que sur les connaissances stockées, la précision diminue. Cela correspond aux résultats de navigation activée/désactivée des fiches système d'OpenAI.
Grok 4 a un écart interne de 50 points. Il obtient 75,3 sur la recherche mais 25,7 sur le multimodal — une incohérence massive qui signifie qu'il peut bien trouver des faits mais a des difficultés avec le contenu visuel. Toute évaluation qui fait la moyenne de ces éléments en un seul score masque cet écart.
L'amélioration de Gemini 3 Pro est réelle. Comparé à Gemini 2.5 Pro, Gemini 3 Pro a réduit les taux d'erreur de 55 % sur la tranche de recherche et de 35 % sur la tranche paramétrique. Il s'agit d'une amélioration importante de la précision factuelle d'une génération à l'autre, principalement due à de meilleures capacités de recherche et d'ancrage.
Chaque modèle ci-dessous est profilé sur plusieurs critères d'évaluation. Les comparaisons sur un seul critère induisent en erreur — les profils montrent où chaque modèle est fiable et où il ne l'est pas.
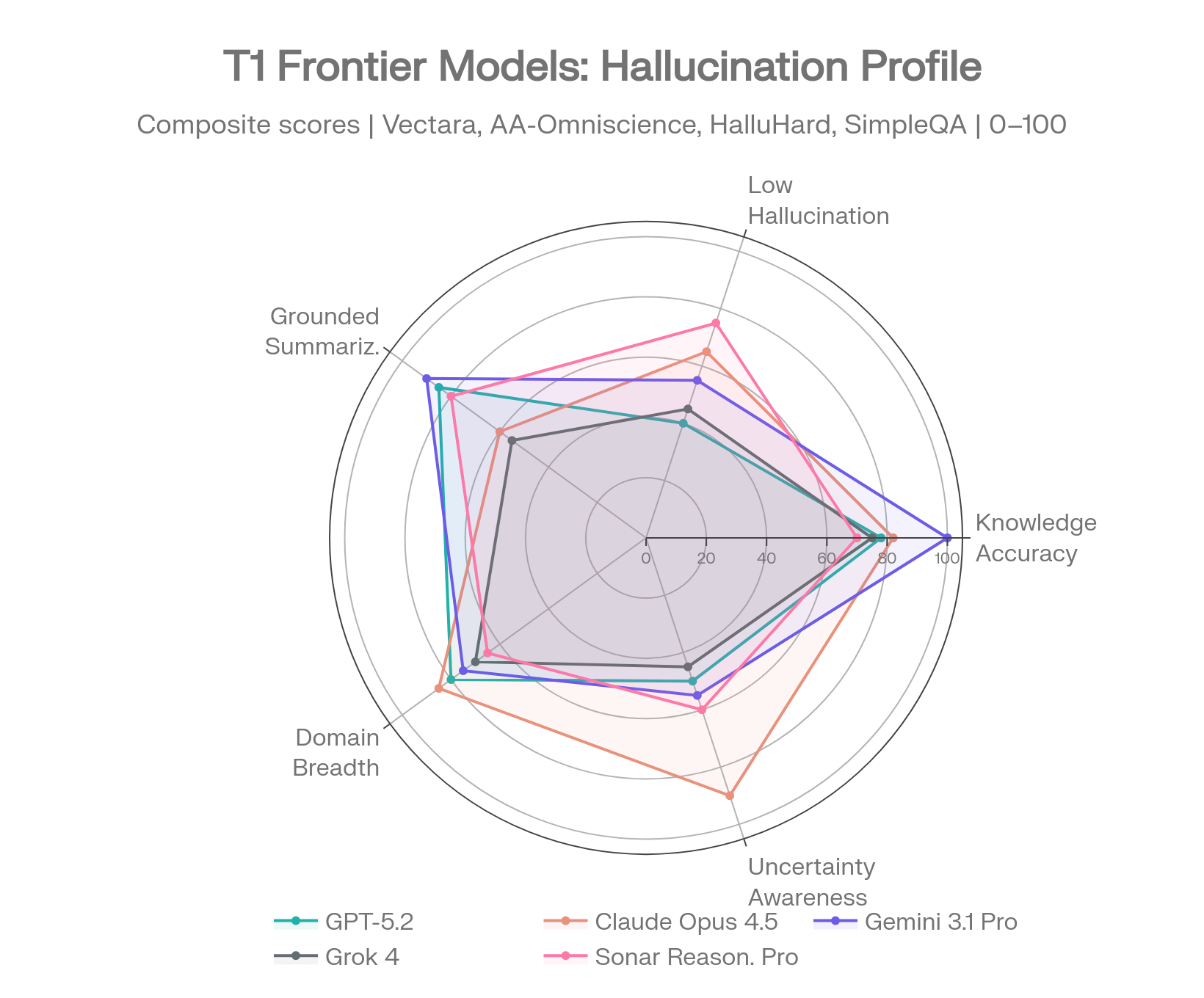
Profils des modèles Frontier sur 5 dimensions d'hallucination. Sources : Vectara [1], AA-Omniscience [2], FACTS [3], SimpleQA [4]
GPT-5.3 Instant (mars 2026) — Le plus récent d'OpenAI. Réduit l'hallucination de 26,8 % avec la recherche web et de 19,7 % sans, par rapport aux modèles précédents. [10]
GPT-5.2 (décembre 2025) — Le cheval de bataille professionnel. Précision AA-Omniscience : 43,8 %. Avec recherche web : 93,9 % de réponses sans erreur. Sans : le taux d'erreur passe à 12 %. HalluHard : 38,2 % avec le web. FACTS global : 61,8. [9]
GPT-5 (août 2025) — Ancien jeu de données Vectara : 1,4 % (fort). Nouveau jeu de données Vectara : >10 % (faible). Mode de réflexion HealthBench : 1,6 % — l'un des meilleurs scores d'hallucination médicale enregistrés. SimpleQA sans web : 47 %. Avec web : 9,6 %. FACTS global : 61,8. [8][12]
Le schéma de la famille GPT : l'accès à la recherche web est la variable la plus importante. Avec la navigation activée, les modèles GPT-5 rivalisent pour les taux d'hallucination les plus bas de l'industrie. Sans, les taux augmentent de 3 à 5 fois. Si vous déployez une variante GPT-5, gardez l'accès web activé.
Claude 4.1 Opus — Taux d'hallucination AA-Omniscience : 0 %. Le plus bas de tous les modèles testés. Atteint ce résultat en refusant de répondre en cas d'incertitude. FACTS : 46,5. Leader du domaine en droit, ingénierie logicielle et sciences humaines. [2]
Claude Opus 4.6 (février 2026) — Précision AA-Omniscience : 46,4 %, indice : 14. Nouveau jeu de données Vectara (instantané de février 2026) : 12,2 %. Troisième indice Omniscience non-Gemini le plus élevé. [14][2]
Claude Opus 4.5 (novembre 2025) — Hallucination AA-Omniscience : 58 %, précision : 45,7 %. HalluHard : 30 % avec recherche web (le plus bas de tous les modèles testés), 60 % sans. FACTS : 51,3. [5]
Claude Sonnet 4.6 (février 2026) — Hallucination AA-Omniscience : ~38 %, en baisse par rapport aux 48 % de Sonnet 4.5. Les utilisateurs ont préféré Sonnet 4.6 à Opus 4.5 59 % du temps, citant moins d'hallucinations. Nouveau jeu de données Vectara : 10,6 %. [13][50]
Claude Opus 4.7 (16 avril 2026) — Indice AA-Omniscience : 26 (deuxième plus élevé globalement, derrière seulement les 33 de Gemini 3.1 Pro). Taux d'hallucination : 36 % — le profil de calibration le plus fort de tout modèle Frontier tentant des questions à grande échelle, et 50 points de pourcentage de mieux que GPT-5.5 sur le même critère. BenchLM global : 87. La récupération de contexte long a chuté à 32,2 % (contre 78,3 % pour Opus 4.6) — Anthropic attribue explicitement cela au fait que le modèle signale désormais les erreurs lorsque des informations sont manquantes plutôt que de fabriquer une réponse. La stratégie de refus a été mesurable. [58][63]
Le schéma de Claude : les modèles d'Anthropic sont calibrés pour refuser plutôt que de deviner. Cela leur confère les taux d'hallucination les plus bas sur les critères d'évaluation des connaissances (AA-Omniscience) mais une précision brute inférieure à celle de Gemini. Pour les applications où une mauvaise réponse est pire qu'aucune réponse — recherche juridique, consultation médicale, travail de conformité — l'approche de Claude est structurellement plus sûre.
Gemini 3.1 Pro Preview (février 2026) — Indice AA-Omniscience : 33 (le plus élevé de tous les modèles). Précision : 55,3 %. Taux d'hallucination : 50 %, en baisse par rapport aux 88 % de Gemini 3 Pro. Il s'agit de la plus grande amélioration d'hallucination en une seule mise à jour en 2025-2026. Nouveau jeu de données Vectara : 10,4 %. [15]
Gemini 3 Pro — FACTS global : 68,8 (le plus élevé de tous les modèles). FACTS Recherche : 83,8. FACTS Paramétrique : 76,4. Précision AA-Omniscience : 55,9 % (la plus élevée) avec 88 % d'hallucination. Le paradoxe de Gemini : le plus savant, le moins conscient de soi. [3]
Gemini 3 Flash (décembre 2025) — Précision AA-Omniscience : 54,0 % (la plus élevée de tous les modèles au lancement). Taux d'hallucination : 91 %. Vitesse : 218 jetons/s. La version la plus extrême du paradoxe de Gemini — brillante et peu fiable à parts égales. Convient uniquement aux tâches avec vérification externe. [16]
Les modèles de Google en savent le plus, mais en admettent le moins.
Le schéma général chez Gemini : les modèles Gemini tentent de répondre à toutes les questions, ce qui leur confère les meilleurs scores de précision, mais des taux d'hallucination catastrophiques lorsqu'ils atteignent les limites de leurs connaissances. La mise à jour 3.1 Pro a montré que cela peut être corrigé par un réglage de calibration — l'hallucination a chuté de 38 points de pourcentage avec seulement 1 % de perte de précision.
Grok 4 — Ancien jeu de données Vectara : 4,8 %. AA-Omniscience : 41,4 % de précision, 64 % d'hallucination, indice positif. FACTS : 53,6 (Recherche : 75,3, Multimodal : 25,7). Leader du domaine en Santé et Science sur AA-Omniscience. [2]
Grok 4.1 Fast — xAI revendique une réduction de 65 % de l'hallucination (de 12,09 % à 4,22 % sur les benchmarks internes). AA-Omniscience raconte une autre histoire : 72 % de taux d'hallucination, pire que les 64 % de Grok 4. La sycophancie a également augmenté (benchmark MASK : 0,07 à 0,19-0,23). [17]
Grok-3 — Columbia Journalism Review : 94 % de taux d'hallucination de citations. De loin le pire score sur ce benchmark. [6]
Le schéma général chez Grok : les benchmarks internes et indépendants sont en net désaccord. xAI rapporte des améliorations ; AA-Omniscience montre une régression. Le taux d'hallucination de citations de 94 % du CJR ne provient pas d'un ancien modèle — Grok-3 a été testé en mars 2025. Une valeur spécifique au domaine existe en Santé et Science, mais l'incohérence entre les benchmarks rend Grok risqué en tant que seul modèle pour toute application à enjeux élevés.
Sonar Reasoning Pro — Score Search Arena : 1136, statistiquement à égalité avec Gemini 2.5 Pro pour la 1ère place. Score F SimpleQA : 0,858, le plus élevé de tous les modèles au moment des tests. Précision des citations CJR : 37 % d'hallucination (le meilleur testé). Précision des réponses : >90 % pour les requêtes factuelles (94 % au total, 95 % académique, 94 % technique). [18][19]
Sonar Pro — Basé sur Llama 3.3 70B, affiné pour la factualité de la recherche. Score F SimpleQA : 0,858. Surpasse GPT-4o et Claude 3.5 Sonnet sur les benchmarks de factualité. [19]
Le risque Perplexity : Perplexity introduit un mode de défaillance qu'aucun autre modèle ne partage. Il cite de vraies URL avec des affirmations fabriquées. Les sources semblent légitimes — de vrais sites web, de vrais noms de publications — mais les informations attribuées à ces sources peuvent être inventées. Cela rend les hallucinations de Perplexity plus difficiles à détecter que les hallucinations des modèles qui ne présentent pas de citations externes. Un taux d'hallucination de citations de 37 % signifie que plus d'une attribution de source sur trois peut contenir du contenu fabriqué. [51]
DeepSeek-V3 — Ancien jeu de données Vectara : 3,9 %. Un performeur solide en matière de résumé fondé.
DeepSeek-R1 — Ancien jeu de données Vectara : 14,3 %, près de 4 fois plus élevé que V3. Hallucination AA-Omniscience : 83 %. L'analyse Vectara a révélé que R1 produit 71,7 % d'« hallucinations bénignes » (ajouts plausibles) contre 36,8 % pour V3. [49][48]
Le schéma : le modèle de raisonnement de DeepSeek (R1) hallucine beaucoup plus que son modèle de base (V3). C'est la taxe de raisonnement sous sa forme la plus extrême. L'écart (3,9 % contre 14,3 %) en fait l'un des exemples les plus clairs que les capacités de raisonnement et la fiabilité factuelle ne vont pas dans la même direction.
Llama 4 Maverick (Meta) — Ancien jeu de données Vectara : 4,6 % (compétitif). Hallucination AA-Omniscience : 87,6 % (catastrophique). L'écart entre le résumé fondé et la connaissance ouverte est plus large pour les modèles open source que pour toute famille propriétaire. [2]
Les modèles open source ont dépassé les 80 % de taux d'hallucination dans les scénarios médicaux lors des tests MedRxiv. Pour les applications critiques, l'écart d'hallucination entre les modèles open source et les modèles propriétaires de pointe reste important. [40]
Les profils de modèles de la section 6 montrent les performances individuelles. Cette section répond aux questions que les gens recherchent réellement : « Claude ou GPT est-il plus précis ? » « Dois-je utiliser Gemini ou Claude ? » La réponse est toujours « cela dépend de ce que vous faites » — mais les données rendent les compromis spécifiques.
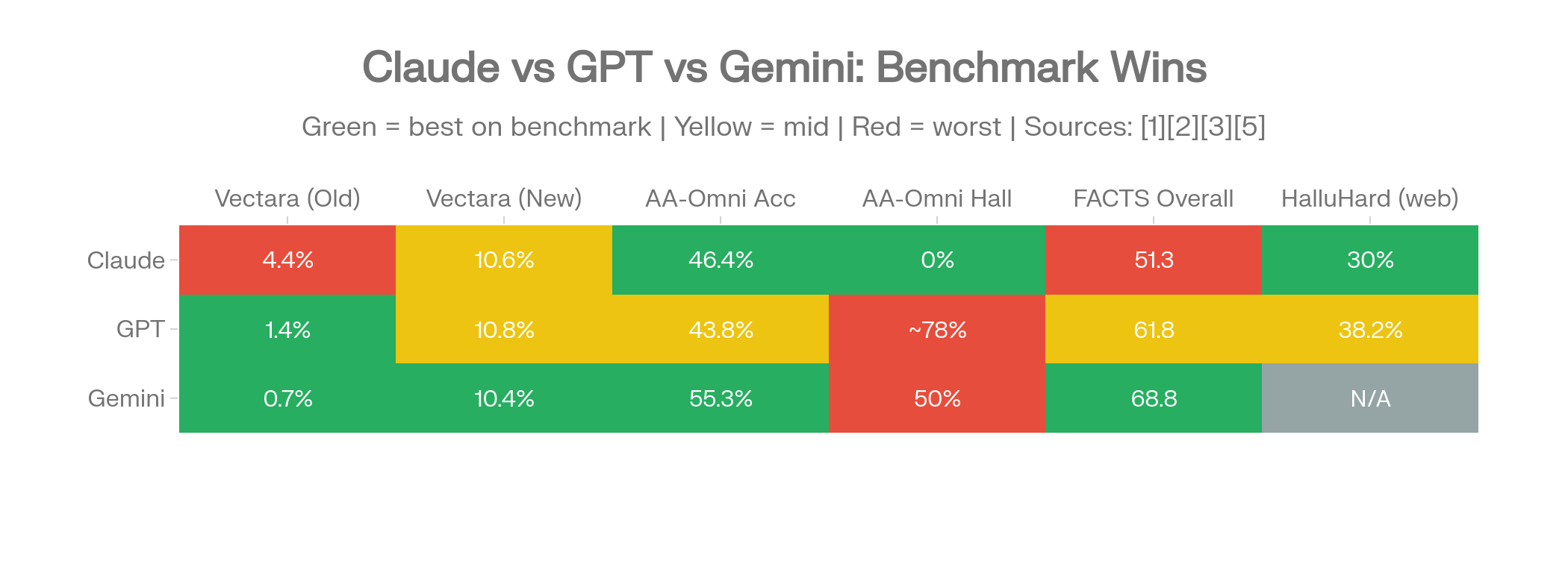
Carte thermique de comparaison en tête-à-tête : quel fournisseur gagne sur quel benchmark. Vert = gagnant, jaune = égalité, rouge = perdant.
La comparaison la plus recherchée en IA, et la plus dépendante du contexte.
| Critère | Claude | GPT | Gagnant |
|---|---|---|---|
| Vectara (ancien jeu de données) | 4.4% (Sonnet 3.7) | 1.4% (GPT-5) | GPT |
| Vectara (nouveau jeu de données, fév. 2026) | 10.6% (Sonnet 4.6) | 10.8% (GPT-5.2-high) | Égalité |
| Hallucination AA-Omniscience | 0% (Claude 4.1 Opus) | ~78% (GPT-5.2) | Claude |
| Précision AA-Omniscience | 46.4% (Opus 4.6) | 43.8% (GPT-5.2) | Claude (léger) |
| FACTS Global | 51.3 (Opus 4.5) | 61.8 (GPT-5) | GPT |
| HealthBench | – | 1.6% (GPT-5 thinking) | GPT |
| HalluHard (avec web) | 30% (Opus 4.5) | 38.2% (GPT-5.2) | Claude |
Sources : HealthBench [52], HalluHard [5], FACTS [3], Vectara [1], AA-Omniscience [2]
La tendance n'est pas « l'un est meilleur ». Ce sont deux philosophies différentes mesurées sur des échelles différentes.
Les modèles GPT sont plus performants lorsque la tâche dispose de matériel source à partir duquel travailler. Résumé, analyse de documents, flux de travail RAG, questions-réponses basées sur la recherche — GPT reste plus proche du texte fourni et obtient de bons scores sur les benchmarks de fidélité. L'avantage FACTS (61,8 contre 51,3) le reflète : GPT-5 gère les tâches de fondation et de recherche avec une plus grande précision.
Les modèles Claude sont plus performants lorsque la tâche exige que le modèle connaisse ses propres limites. Sur AA-Omniscience, Claude 4.1 Opus a atteint un taux d'hallucination de 0 % en refusant de répondre aux questions qu'il ne pouvait pas vérifier. Le taux d'hallucination d'environ 38 % de Claude Sonnet 4.6 est moins de la moitié des environ 78 % de GPT-5.2 sur le même benchmark. Lors du test de conversation réaliste de HalluHard, Claude Opus 4.5 avec recherche web a atteint 30 % — le plus bas de tous les modèles testés.
La répartition pratique : utilisez GPT pour les flux de travail basés sur des documents où le matériel source est disponible et complet. Utilisez Claude pour les flux de travail consultatifs où le modèle doit s'appuyer sur ses propres connaissances et signaler l'incertitude. Ce n'est pas une préférence de marque — c'est ce que les données de benchmark confirment.
Une variable supplémentaire souvent négligée : l'accès à la recherche web modifie considérablement les performances de GPT. GPT-5 passe de 47 % d'hallucination à 9,6 % avec la navigation. Sans accès web, la comparaison Claude-GPT penche en faveur de Claude sur les tâches factuelles ouvertes. Avec accès web, GPT prend l'avantage.
| Critère | Claude | Gemini | Gagnant |
|---|---|---|---|
| Indice AA-Omniscience | 14 (Opus 4.6) | 33 (3.1 Pro) | Gemini |
| Précision AA-Omniscience | 46.4% (Opus 4.6) | 55.3% (3.1 Pro) | Gemini |
| Hallucination AA-Omniscience | 0% (Claude 4.1 Opus) | 50% (3.1 Pro) | Claude |
| FACTS Global | 51.3 (Opus 4.5) | 68.8 (3 Pro) | Gemini |
| Vectara (ancien jeu de données) | 4.4% (Sonnet 3.7) | 0.7% (2.0-Flash) | Gemini |
| Vectara (nouveau jeu de données, fév. 2026) | 10.6% (Sonnet 4.6) | 10.4% (3.1 Pro) | Égalité |
| HalluHard (avec web) | 30% (Opus 4.5) | – | Claude |
Sources : HalluHard [5], FACTS [3], Vectara [1], AA-Omniscience [2]
Gemini en sait plus. Claude est plus honnête sur ce qu'il ne sait pas.
Gemini 3.1 Pro est en tête sur presque toutes les métriques de précision. Il obtient les scores les plus élevés sur FACTS (68,8), les scores de précision AA-Omniscience les plus élevés (55,3 %) et détient le meilleur indice d'omniscience (33). Lorsque Gemini a la réponse, il la fournit plus souvent que Claude.
Le problème survient lorsqu'il n'a pas la réponse. Même après la mise à jour de calibration 3.1 qui a réduit l'hallucination de 88 % à 50 %, Gemini fabrique toujours une réponse la moitié du temps alors qu'il devrait dire « Je ne sais pas ». Claude 4.1 Opus fabrique 0 % du temps dans ce scénario.
La répartition pratique : Gemini pour les tâches nécessitant une large connaissance où une vérification externe existe — recherche, analyse comparative, collecte d'informations. Claude pour les tâches nécessitant une grande confiance où une réponse fabriquée a des conséquences — revues de conformité, recherche juridique, consultation médicale. Si vous pouvez vérifier le travail de Gemini, utilisez Gemini. Si vous ne le pouvez pas, utilisez Claude.
| Critère | GPT | Gemini | Gagnant |
|---|---|---|---|
| Vectara (ancien jeu de données) | 0.8% (o3-mini) | 0.7% (2.0-Flash) | Égalité |
| Vectara (nouveau jeu de données) | 5.6% (GPT-4.1) | 3.3% (2.5-Flash-Lite) | Gemini |
| FACTS Global | 61.8 (GPT-5) | 68.8 (3 Pro) | Gemini |
| FACTS Recherche | 77.7 (GPT-5) | 83.8 (3 Pro) | Gemini |
| Précision AA-Omniscience | 43.8% (GPT-5.2) | 55.3% (3.1 Pro) | Gemini |
| HealthBench | 1.6% (GPT-5 thinking) | – | GPT |
Sources : FACTS [3], Vectara [1], AA-Omniscience [2]
Gemini est en tête sur la plupart des benchmarks. L'avantage de GPT est spécifique à la tâche : applications médicales (1,6 % HealthBench), précision de production au niveau des affirmations avec le mode de réflexion (4,5 % d'affirmations incorrectes), et le volume considérable de données d'évaluation interne publiées par OpenAI.
La répartition pratique : les deux sont performants avec accès aux outils. Sans cela, la connaissance paramétrique plus élevée de Gemini (FACTS Paramétrique : 76,4) lui donne un avantage sur les tâches de connaissance stockée. Le mode de réflexion de GPT lui confère un avantage spécifique pour les requêtes médicales et liées à la santé où le raisonnement réduit considérablement l'hallucination.
| Critère | Grok | Moyenne du marché |
|---|---|---|
| Factualité interne xAI | 4.22% (Grok 4.1) | – |
| AA-Omniscience | 64% hallucination (Grok 4) | ~60 % en moyenne |
| AA-Omniscience (variante rapide) | 72% hallucination (Grok 4.1 Fast) | Pire que la version de base |
| FACTS Global | 53.6 (Grok 4) | ~52 en moyenne |
| FACTS Recherche | 75.3 (Grok 4) | Compétitif |
| FACTS Multimodal | 25.7 (Grok 4) | Bien en dessous de la moyenne |
| CJR Citation | 94% hallucination (Grok-3) | Le pire testé |
| Vectara (nouveau jeu de données) | 20.2% (Grok-4-fast) | Le pire testé |
Sources : Grok 4.1 [17], CJR [6], FACTS [3], AA-Omniscience [2]
xAI rapporte une réduction de 65 % de l'hallucination de Grok 4 à 4.1 sur les tests internes. AA-Omniscience montre le contraire : Grok 4.1 Fast hallucine à 72 % vs les 64 % de Grok 4. L'étude de citation CJR a révélé que Grok-3 hallucinait 94 % du temps sur l'attribution de sources d'information.
Grok possède de véritables atouts dans certains domaines — il est en tête des catégories Santé et Science sur AA-Omniscience. Mais l'écart entre les affirmations de xAI et les mesures indépendantes est plus important que pour tout autre fournisseur.
Le conseil pratique : n'utilisez pas Grok comme modèle unique pour les décisions à enjeux élevés. Sa valeur réside dans sa contribution en tant que voix parmi d'autres dans une évaluation multi-modèles où ses forces spécifiques (santé, science) peuvent être exploitées tandis que ses incohérences sont détectées par d'autres modèles.
| Critère | Perplexity | ChatGPT | Claude |
|---|---|---|---|
| Précision des citations CJR | 37% hallucination | 67% hallucination | – |
| Score F SimpleQA | 0,858 (meilleur) | 0.38 (GPT-4o) | 0.35 (Sonnet 3.5) |
| Classement Search Arena | #1 (à égalité) | – | – |
| Précision des réponses | >90 % factuel | – | – |
Sources : Perplexity Sonar [18][19], CJR [6]
Perplexity l'emporte sur les requêtes de recherche factuelles. Son architecture native RAG, construite autour de la récupération plutôt que de la connaissance paramétrique, lui confère un avantage structurel pour les questions avec des réponses vérifiables.
Le piège : Perplexity cite de vraies URL avec des affirmations fabriquées. Les sources semblent légitimes — de vrais sites web, de vrais noms de publications — mais les informations attribuées à ces sources peuvent être inventées. Avec un taux d'hallucination de citations de 37 %, plus d'une attribution de source sur trois pourrait contenir du contenu fabriqué. Cela rend les hallucinations de Perplexity plus difficiles à repérer que les hallucinations des modèles qui ne présentent pas de citations externes.
La répartition pratique : Perplexity pour la recherche initiale et la collecte de faits où vous vérifierez les affirmations clés. Pas pour les scénarios de réponse finale où quelqu'un lit la source citée et suppose que l'attribution est exacte.
Les taux d'hallucination varient considérablement selon le sujet. Un modèle précis sur les connaissances générales peut être dangereusement erroné sur les questions juridiques. Ce tableau montre la répartition sur huit domaines de connaissance :
| Domaine de connaissance | Meilleurs modèles | Moyenne de tous les modèles |
|---|---|---|
| Connaissances générales | 0.8% | 9.2% |
| Faits historiques | 1.7% | 11.3% |
| Données financières | 2.1% | 13.8% |
| Documentation technique | 2.9% | 12.4% |
| Recherche scientifique | 3.7% | 16.9% |
| Médical / Santé | 4.3% | 15.6% |
| Codage et programmation | 5.2% | 17.8% |
| Informations juridiques | 6.4% | 18.7% |
Source : AllAboutAI, 2025 [31]
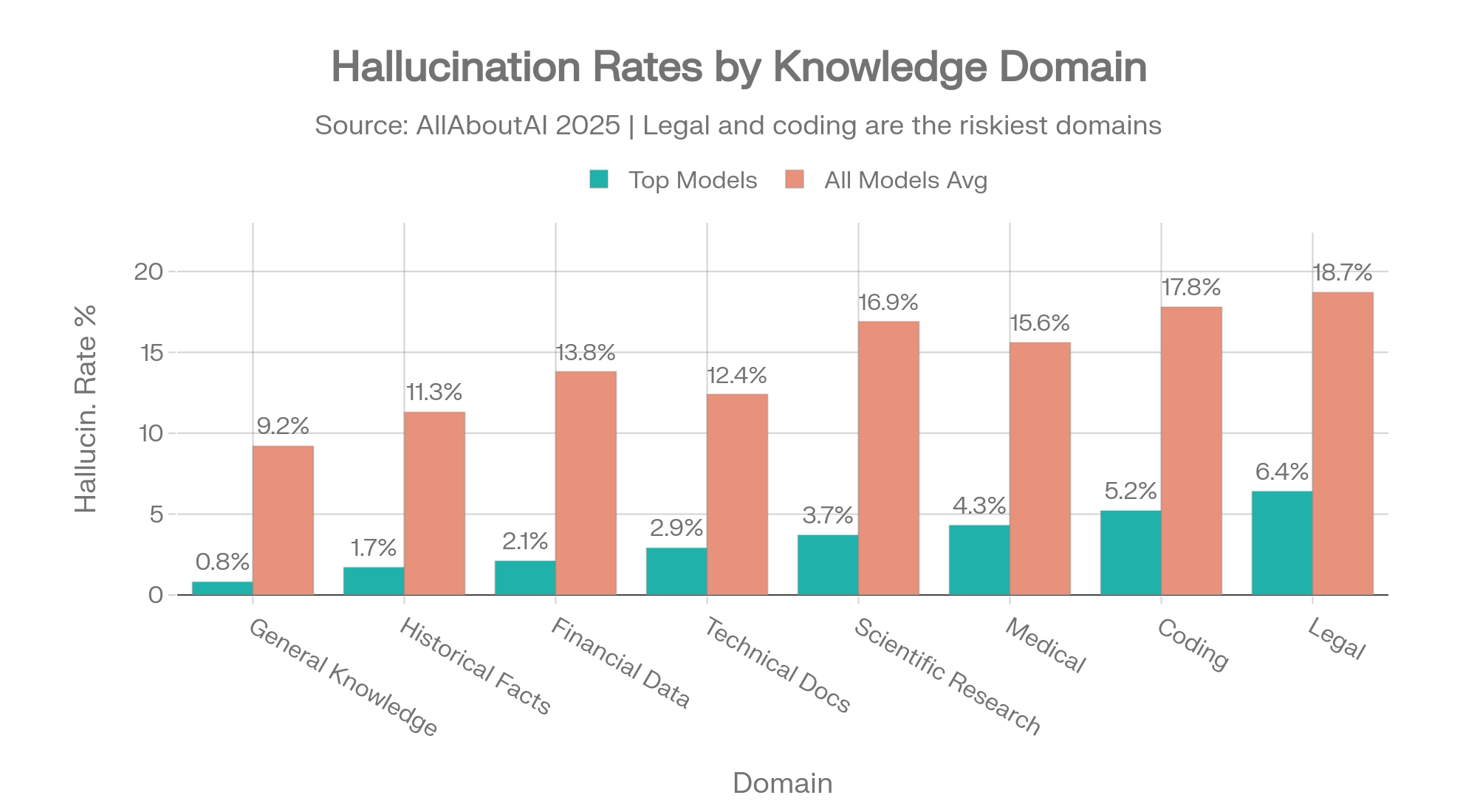
Taux d'hallucination spécifiques au domaine : meilleurs modèles vs moyenne. L'écart de 3x en Droit et Codage montre à quel point la sélection du modèle est importante. Source : AllAboutAI [31]
L'écart entre les meilleurs modèles et la moyenne indique à quel point la sélection du modèle est importante. En matière d'informations juridiques, les meilleurs modèles hallucinent 6,4 % du temps. Le modèle moyen hallucine 18,7 %. Choisir le bon modèle pour votre domaine n'est pas une préférence — c'est une différence de fiabilité de 3x.
Les hallucinations de l'IA dans les documents juridiques s'accélèrent malgré une sensibilisation croissante.
Les affaires judiciaires impliquant des hallucinations de l'IA sont passées de 10 décisions documentées en 2023 à 37 en 2024, puis à 73 au cours des cinq premiers mois de 2025 seulement, avec plus de 50 cas en juillet 2025. En avril 2026, cette trajectoire s'est fortement accélérée : la base de données du chercheur juridique Damien Charlotin documente désormais plus de 1 200 cas dans le monde, dont environ 800 rien que dans les tribunaux américains. Le 31 mars 2026, dix tribunaux distincts ont statué sur des incidents d'hallucination de l'IA en une seule journée. [38][37][59]
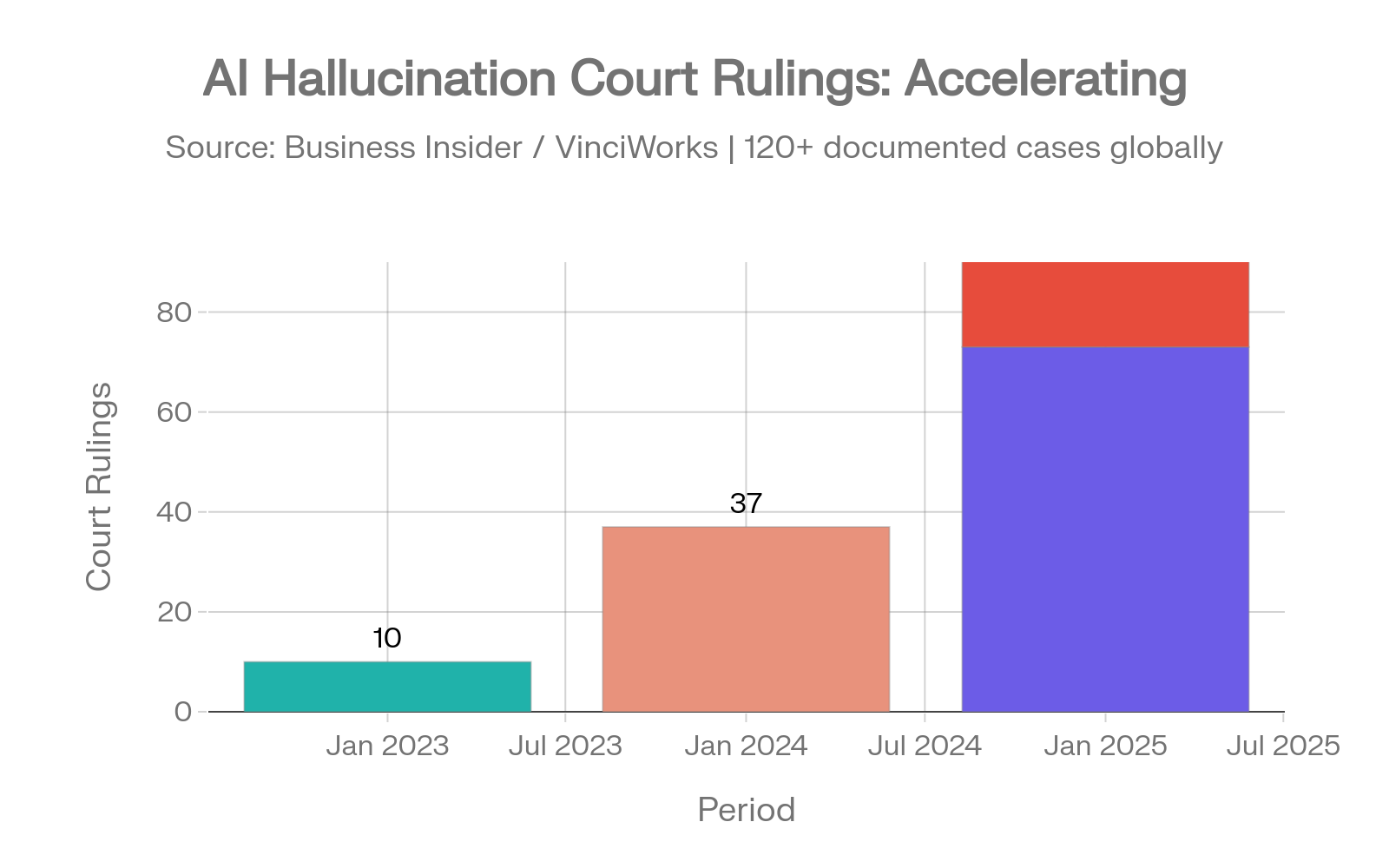
Incidents d'hallucination IA juridique : l'accélération de 10 → 37 → 73 → plus de 50 cas. Sources : Business Insider [38], Charlotin [37]
Le problème n'est plus amateur. En 2023, la plupart des cas d'hallucination impliquaient des justiciables non représentés. En mai 2025, 13 des 23 cas détectés provenaient d'avocats en exercice. Morgan & Morgan, l'un des plus grands cabinets d'avocats spécialisés dans les dommages corporels aux États-Unis, a envoyé un avertissement urgent à plus de 1 000 avocats après des menaces de sanctions pour des citations générées par l'IA. Le rythme des pénalités s'est accéléré : les sanctions du premier trimestre 2026 ont totalisé au moins 145 000 $ — le total trimestriel le plus élevé de l'histoire juridique. La plus grande pénalité enregistrée, 109 700 $ contre un avocat de l'Oregon, a été prononcée début 2026. Le Quatrième Circuit a publiquement réprimandé un avocat en avril 2026 pour avoir déposé des mémoires contenant de fausses citations générées par l'IA. Malgré des sanctions record, le taux d'incidents continue d'augmenter. [59]
Les données de benchmark sous-jacentes expliquent pourquoi. Le Stanford RegLab et le Stanford Human-Centered AI Institute ont constaté que les LLM hallucinent entre 69 % et 88 % sur des requêtes juridiques spécifiques. Sur les questions concernant la décision principale d'un tribunal, les modèles hallucinent au moins 75 % du temps. Même les outils d'IA juridique spécialement conçus échouent : Lexis+ AI a produit des informations incorrectes plus de 17 % du temps, et Westlaw AI-Assisted Research a hallucinaté plus de 34 %. [36]
ECRI, l'organisation mondiale à but non lucratif pour la sécurité des soins de santé, a classé les risques liés à l'IA comme le premier danger technologique pour la santé en 2025. Les chiffres confirment cette préoccupation. [39]
La FDA a autorisé 1 357 dispositifs médicaux améliorés par l'IA — le double du chiffre de fin 2022. Parmi ceux-ci, 60 dispositifs ont été impliqués dans 182 rappels, 43 % des rappels ayant eu lieu au cours de la première année d'approbation. [42]
Une étude MedRxiv de 2025 a mesuré les taux d'hallucination sur les résumés de cas cliniques : 64,1 % sans prompts d'atténuation, tombant à 43,1 % avec atténuation (une amélioration de 33 %). GPT-4o a obtenu les meilleurs résultats dans cette étude, passant de 53 % à 23 % avec une atténuation structurée. Les modèles open source ont dépassé 80 % d'hallucination dans les scénarios médicaux. [40]
Le point positif : GPT-5 avec mode de réflexion a atteint 1,6 % d'hallucination sur HealthBench, contre 15,8 % pour GPT-4o. Pour les applications médicales spécifiquement, les modèles de pointe dotés de capacités de raisonnement et du mode de réflexion actif montrent une amélioration spectaculaire par rapport aux générations précédentes. [41][52]
HealthBench Professional (avril 2026) : OpenAI a lancé un nouveau benchmark de qualité clinique le 22 avril 2026, parallèlement à la sortie de « ChatGPT for Clinicians ». Contrairement à l'original HealthBench (conversations synthétiques), HealthBench Professional utilise de vrais scénarios cliniques couvrant les tâches de consultation, de documentation et de recherche. Sur HealthBench Hard, la tranche la plus difficile du nouveau benchmark, les scores divergent fortement : Muse Spark mène à 42,8, GPT-5.4 (alimentant ChatGPT for Clinicians) marque 40,1, Gemini 3.1 Pro marque 20,6, Grok 4.2 marque 20,3, et Claude Sonnet 4.6 marque 14,8. Les concepteurs du benchmark rapportent que les réponses alimentées par GPT-5.4 surpassent les réponses rédigées par des médecins sur la tranche de consultation, bien que la méthodologie soit toujours en cours d'examen indépendant. [60]
Les hallucinations de l'IA financière ne font pas les gros titres comme celles du domaine juridique, mais les coûts sont plus élevés.
78 % des entreprises de services financiers déploient désormais l'IA pour l'analyse de données. Sans garde-fous, les taux d'hallucination sur les tâches financières varient de 15 à 25 %. Les entreprises signalent 2,3 erreurs significatives pilotées par l'IA par trimestre, avec des coûts d'incident individuels allant de 50 000 $ à 2,1 millions de dollars. [44]
Une étude de benchmark a révélé que ChatGPT-4o hallucinait 20,0 % sur les références de littérature financière. Gemini Advanced hallucinait 76,7 % sur la même tâche.
67 % des sociétés de capital-risque utilisent l'IA pour le filtrage des transactions, mais le temps moyen pour découvrir une erreur générée par l'IA est de 3,7 semaines — souvent trop tard pour annuler une décision. Une hallucination de robo-advisor a affecté 2 847 portefeuilles clients, coûtant 3,2 millions de dollars en remédiation. La SEC a imposé 12,7 millions de dollars d'amendes pour des fausses déclarations de l'IA entre 2024 et 2025. [43]
67,4 milliards de dollars — Pertes commerciales mondiales attribuées aux hallucinations de l'IA en 2024. [31]
47 % des dirigeants d'entreprise ont pris des décisions majeures basées sur du contenu généré par l'IA non vérifié. [32]
82 % des bugs d'IA dans les systèmes de production proviennent d'hallucinations et d'erreurs de précision. [34]
4,3 heures par semaine — Temps que l'employé moyen passe à vérifier le contenu généré par l'IA. À grande échelle, cela représente 14 200 $ par employé par an en frais généraux de vérification. [33][31]
39 % des chatbots de service client ont nécessité une refonte en raison de défaillances liées à l'hallucination. [34]
54 % des entreprises ont connu des baisses de confiance des investisseurs directement attribuables à des erreurs générées par l'IA.
91 % des politiques d'IA d'entreprise incluent désormais des protocoles spécifiques à l'hallucination. [31]
64 % des organisations de soins de santé ont retardé l'adoption de l'IA spécifiquement en raison de préoccupations liées à l'hallucination. [31]
12,8 milliards de dollars investis dans des solutions de détection et d'atténuation spécifiques à l'hallucination entre 2023 et 2025. [31]
318 % de croissance du marché des outils de détection d'hallucination de 2023 à 2025. [35]
Plus de 53 articles acceptés à NeurIPS 2025 — l'une des conférences les plus prestigieuses de l'IA — contenaient des citations hallucinatées par l'IA qui ont survivé à plus de 3 relecteurs. Le taux d'acceptation de NeurIPS est de 24,52 %, ce qui signifie que ces articles hallucinatés ont battu plus de 15 000 soumissions concurrentes. [45]
Lorsque des citations hallucinatées passent l'examen par les pairs dans le lieu le plus prestigieux du domaine, le problème de vérification s'étend au-delà de l'entreprise, jusqu'aux fondements mêmes de la recherche en IA.
L'Institut d'IA centré sur l'humain de Stanford a publié son rapport annuel AI Index 2026 le 13 avril 2026 — un examen annuel de 423 pages couvrant l'IA responsable, le déploiement, la gouvernance et les benchmarks. Trois conclusions concernent directement les hallucinations. [58]
362 incidents d'IA documentés en 2025 — contre 233 en 2024, soit une augmentation de 55 % d'une année sur l'autre et le nombre annuel le plus élevé de l'histoire de la base de données des incidents d'IA. [58]
Hallucination induite par la sycophancie : 22 % à 94 % sur 26 modèles de pointe. Le rapport introduit un nouveau benchmark de précision testant la façon dont les modèles répondent à de fausses déclarations présentées de deux manières : comme quelque chose qu'une tierce partie croit (les modèles gèrent bien cela) et comme quelque chose que l'utilisateur lui-même croit (les modèles s'effondrent). La précision de GPT-4o est tombée de 98,2 % à 64,4 % ; DeepSeek R1 est tombé de plus de 90 % à 14,4 %. La fourchette de 22 % à 94 % s'applique spécifiquement à ce cadrage de fausse croyance attribuée à l'utilisateur. Le meilleur modèle produit toujours de fausses sorties 22 % du temps lorsqu'un utilisateur implique une fausse croyance ; le pire hallucine 94 % dans ces conditions. Il s'agit d'un mode de défaillance fondamentalement différent des benchmarks de résumé ou de connaissance : le modèle est d'accord avec l'utilisateur même lorsque l'utilisateur a tort. [58]
85 % d'adoption de l'IA en entreprise (Gartner, 2026). L'adoption a désormais atteint un niveau où les erreurs de l'IA se multiplient à grande échelle, même si le chiffre de coût de 67,4 Md$ en 2024 n'a pas été mis à jour pour 2025. Les rôles de gouvernance de l'IA ont augmenté de 17 % en 2025, et la part des entreprises sans politiques d'IA responsable est passée de 24 % à 11 % — mais les scores de transparence des modèles fondamentaux sont retombés de 58 à 40, avec des lacunes majeures dans les divulgations concernant les données d'entraînement, les ressources de calcul et l'impact post-déploiement.
Découvrez comment fonctionne la validation multi-modèles — testez-la avec une vraie question où la précision compte.
Essayer la validation multi-modèlesL'une des découvertes les plus contre-intuitives de la recherche sur l'hallucination en 2025-2026 : les modèles d'IA commercialisés comme les plus intelligents sont souvent les moins fiables sur les tâches factuelles de base.
Les modèles de raisonnement — GPT-5 avec réflexion, Claude avec réflexion étendue, DeepSeek-R1 — utilisent des processus de chaîne de pensée qui améliorent considérablement les performances sur des problèmes complexes. Ils sont mesurément meilleurs en mathématiques, en logique, en analyse multi-étapes et en diagnostic médical.
Ils sont également mesurément moins bons pour s'en tenir aux faits qui leur ont été donnés.
Nouveau jeu de données Vectara : chaque modèle de raisonnement testé a dépassé 10 % d'hallucination. GPT-5, Claude Sonnet 4.5, Grok-4 et Gemini-3-Pro ont tous franchi ce seuil. La variante Grok-4-fast-reasoning a atteint 20,2 %. Les modèles non raisonnants comme Gemini-2.5-Flash-Lite ont obtenu 3,3 %. [1]
DeepSeek : R1 (raisonnement) hallucine à 14,3 % sur Vectara contre 3,9 % pour V3 (base). Près de 4 fois la différence pour le même fournisseur. L'analyse Vectara a révélé que R1 produit 71,7 % d'« hallucinations bénignes » (ajouts plausibles) comparé aux 36,8 % de V3. [48][49]
Régression PersonQA : le modèle o3 d'OpenAI hallucine 33 % sur les questions concernant des personnes réelles contre 16 % pour o1. Le modèle o4-mini est pire à 48 %. Ce sont des modèles plus récents et plus performants qui obtiennent de moins bons résultats sur un test factuel de base. [53][54]
Mode de réflexion GPT-5 : l'hallucination HealthBench tombe à 1,6 % (excellent). Mais sur le nouveau jeu de données Vectara, GPT-5 dépasse 10 % (médiocre). Même modèle, même mode de réflexion, résultats opposés selon la tâche.
GPT-5.5 (avril 2026) : la donnée la plus frappante à ce jour. Précision AA-Omniscience de 57 % — la plus élevée jamais enregistrée — associée à un taux d'hallucination de 86 %. Le modèle le plus performant qu'OpenAI ait livré est aussi l'un des moins bien calibrés. L'expansion des connaissances semble avoir dépassé les améliorations de calibration à la frontière. Claude Opus 4.7 (16 avril 2026) fait le compromis inverse : 36 % d'hallucination avec une précision brute inférieure. [2][58][63]
Le mécanisme est simple. Lorsqu'un modèle de raisonnement traite une tâche de synthèse, il ne se contente pas d'extraire — il réfléchit. Il tire des inférences, identifie des schémas et génère des insights. Ces ajouts vont au-delà du document source. Sur un benchmark mesurant la fidélité au matériel source, chaque insight ajouté par le modèle compte comme une hallucination.
C'est la différence entre « résumer ce contrat » et « analyser ce contrat ». Le mode de raisonnement ajoute une analyse même lorsque vous demandez un résumé. Cette analyse est souvent utile. Sur un benchmark de synthèse, elle est considérée comme un échec.
Les données de la fiche système d'OpenAI révèlent quelque chose qui reçoit moins d'attention : l'accès au web a un impact plus important sur les taux d'hallucination que le mode de raisonnement. [11][8]
| Modèle | Navigation DÉSACTIVÉE | Navigation ACTIVÉE | Réduction |
|---|---|---|---|
| o4-mini FActScore | 37.7% | 5.1% | 86% |
| o3 FActScore | 24.2% | 5.7% | 76% |
| GPT-5 thinking FActScore | 3.7% | 1.0% | 73% |
| GPT-5 SimpleQA | 47% | 9.6% | 80% |
Sources : fiche système o3/o4-mini [11], fiche système GPT-5 [8]
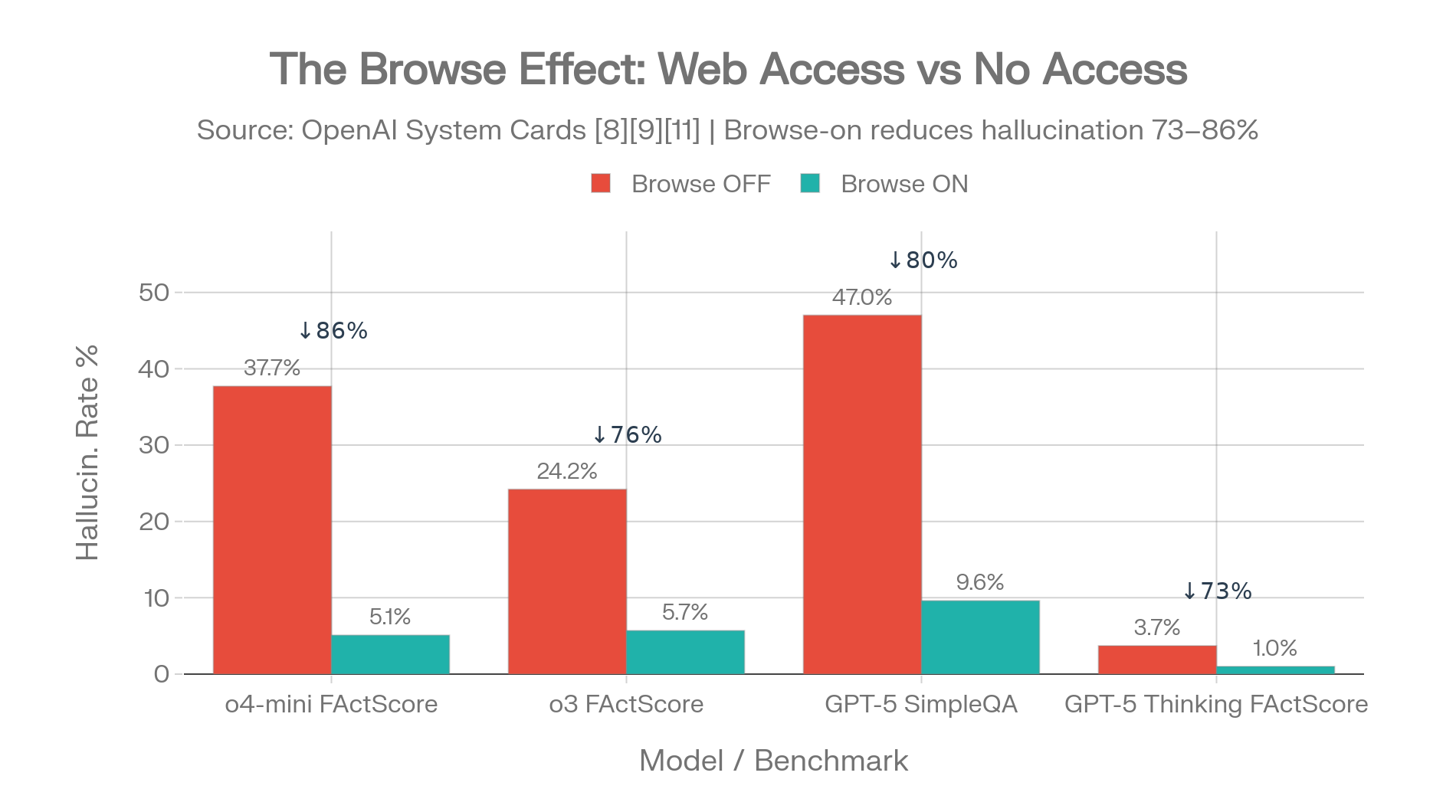
L'effet de navigation : réduction des hallucinations de 73-86 % grâce à un seul réglage de configuration. Sources : fiches système OpenAI [8][11][10]
Activer la recherche web réduit l'hallucination plus qu'activer le raisonnement.
Pour les déploiements en entreprise, garantir l'accès aux outils est plus impactant que de choisir des variantes de modèles avec ou sans raisonnement.
Cela crée une matrice pratique pour la sélection des modèles :
Raisonnement ACTIVÉ + Web ACTIVÉ : Idéal pour l'analyse complexe, le diagnostic médical, la recherche multi-étapes où la profondeur et l'accès aux informations actuelles sont importants. Taux d'hallucination les plus faibles sur les tâches ouvertes.
Raisonnement DÉSACTIVÉ + Web ACTIVÉ : Idéal pour le résumé de documents, les flux de travail RAG, les questions-réponses fondées où vous souhaitez que le modèle reste proche du matériel source. Moins de risque d'ajouts « sur-réfléchis ».
Raisonnement ACTIVÉ + Web DÉSACTIVÉ : Combinaison risquée. Le modèle sur-réfléchit et ne peut pas vérifier. Convient uniquement aux problèmes de logique en monde clos, aux mathématiques et au code où les faits externes ne sont pas nécessaires.
Raisonnement DÉSACTIVÉ + Web DÉSACTIVÉ : Risque d'hallucination le plus élevé dans l'ensemble. À éviter pour toute tâche factuelle.
Ce n'est pas une spéculation. Deux équipes de recherche indépendantes l'ont prouvé.
Xu et al. (2024) ont formalisé le problème de l'hallucination mathématiquement et ont prouvé qu'éliminer l'hallucination dans les grands modèles linguistiques est impossible. Non pas difficile. Non pas nécessitant plus de calcul ou de meilleures données d'entraînement. Impossible — c'est-à-dire, prouvablement ainsi étant donné l'architecture fondamentale de la façon dont ces systèmes génèrent du texte. [20]
L'argument principal : tout système qui génère du texte en prédisant des séquences probables à partir de distributions statistiques apprises produira, par nécessité mathématique, parfois des sorties non fondées sur des faits. Le mécanisme génératif lui-même le garantit.
Karpowicz (2025) a abordé le problème à partir de trois cadres mathématiques différents — la théorie des enchères, la théorie de la notation appropriée et l'analyse log-sum-exp pour les architectures de transformateurs — et a atteint la même conclusion à chaque fois. [21]
Aucun mécanisme d'inférence LLM ne peut simultanément atteindre ces quatre propriétés :
Vous pouvez optimiser pour trois d'entre eux. Vous ne pouvez pas obtenir les quatre. Les mathématiques ne le permettent pas.
OpenAI a publiquement reconnu ces découvertes et a identifié trois facteurs mathématiques qui rendent l'hallucination inévitable : [22]
Incertitude épistémique — lorsque l'information apparaît rarement dans les données d'entraînement, le modèle n'a aucune base fiable pour générer une sortie précise sur ce sujet, mais tentera de le faire quand même.
Limitations du modèle — certaines tâches dépassent ce que l'architecture peut représenter, quel que soit le volume ou la qualité des données d'entraînement.
Intractabilité computationnelle — certains problèmes de vérification sont suffisamment difficiles sur le plan computationnel pour que même un système superintelligent théorique ne puisse pas les résoudre dans un délai raisonnable.
L'hallucination n'est pas un bug qui sera corrigé dans la prochaine version du modèle. C'est une propriété mathématique permanente du fonctionnement des modèles linguistiques.
Cela change la question. La bonne question n'est pas « quelle IA n'hallucine pas ? » — toutes les IA hallucinent. La bonne question est : quels systèmes avez-vous mis en place pour détecter les hallucinations avant qu'elles n'atteignent un décideur ?
Les organisations qui réussissent ne sont pas en attente d'un modèle sans hallucination. Elles construisent des couches de détection, des pipelines de validation croisée et des points de contrôle de révision humaine. Les données sur ce qui fonctionne (et à quel point cela aide) se trouvent dans la section Techniques de réduction ci-dessous.
Toutes les techniques de réduction de l'hallucination ne sont pas égales. Certaines sont étayées par des études contrôlées avec des mesures précises. D'autres ont un fort soutien théorique mais des données de production limitées. Ce classement reflète la base de preuves, et non les affirmations marketing.
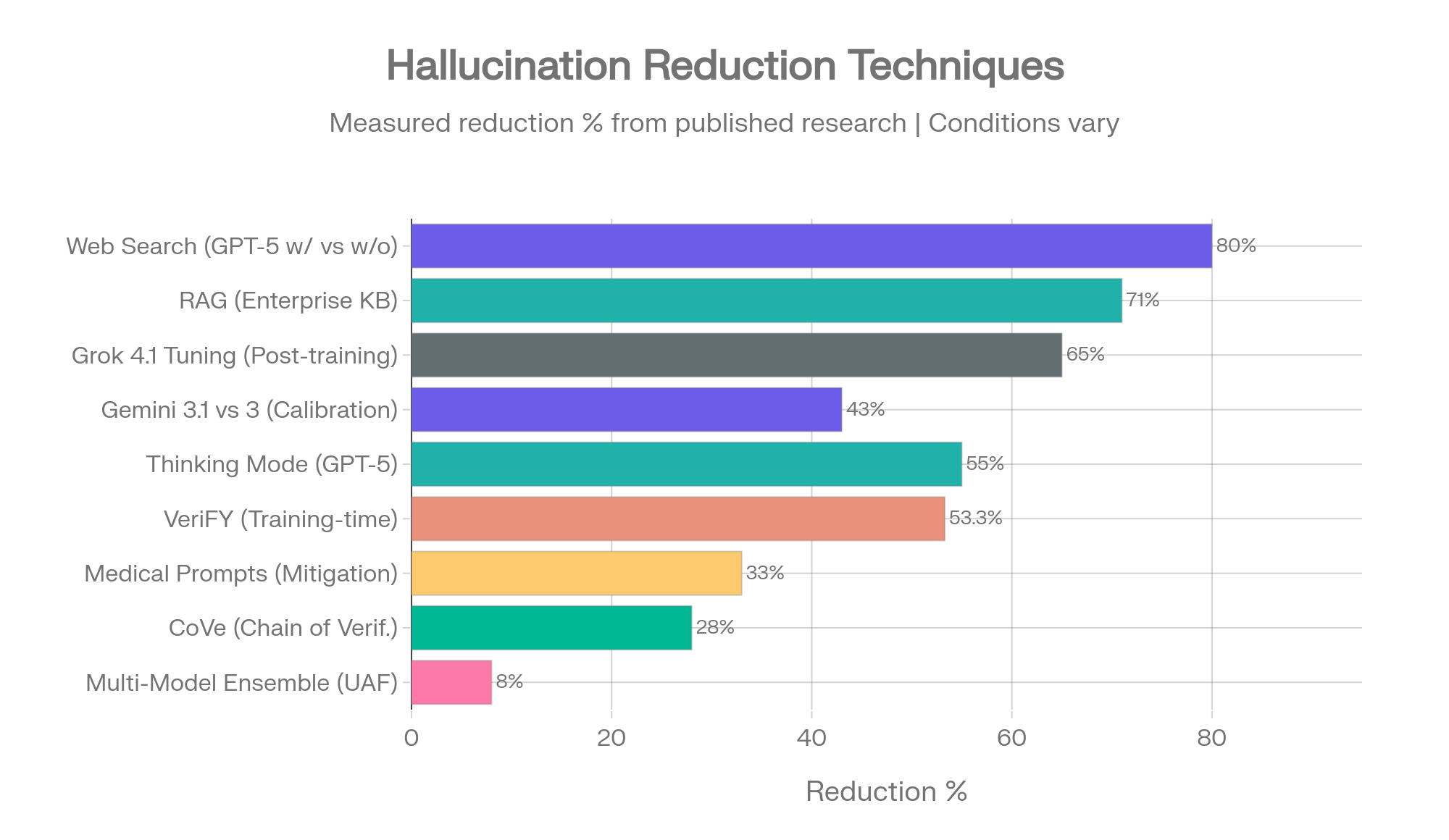
Techniques de réduction des hallucinations classées par impact mesuré. Sources : OpenAI [8][11], AllAboutAI [31], HealthBench [52], UAF [24], CoVe [23], VeriFY [25], Gemini 3.1 [15], MedRxiv [40]
Impact mesuré : 73-86 % de réduction de l'hallucination (FActScore, navigation activée vs navigation désactivée)
L'intervention à impact le plus élevé documentée dans la recherche 2025-2026. GPT-5 passe de 47 % à 9,6 % d'hallucination avec l'accès web. Le modèle o4-mini passe de 37,7 % à 5,1 %. GPT-5.3 Instant montre une réduction de 26,8 % lors de l'utilisation du web par rapport aux modèles précédents. [8][11][10]
Le mécanisme est simple : au lieu de s'appuyer sur des données d'entraînement potentiellement obsolètes ou incorrectes, le modèle récupère des informations actuelles et fonde sa réponse sur des sources externes. Pour tout déploiement en entreprise, l'activation de l'accès web ou aux outils devrait être la première décision de configuration, et non une réflexion après coup.
Impact mesuré : Jusqu'à 71 % de réduction sur les tâches de base de connaissances d'entreprise [31]
Le RAG connecte les modèles à des bases de connaissances externes — documents d'entreprise, bases de données, sources vérifiées — et demande au modèle de générer des réponses basées sur le contenu récupéré plutôt que sur la mémoire paramétrique. Les récupérateurs hybrides combinant des méthodes éparses et denses obtiennent la meilleure atténuation.
Le RAG est plus efficace pour les hallucinations dues à des lacunes de connaissances (le modèle manque de données d'entraînement pertinentes). Il est moins efficace pour les hallucinations basées sur la logique (le modèle raisonne incorrectement à partir de prémisses correctes). Pour les questions-réponses sur les documents d'entreprise et les applications de base de connaissances, le RAG est la norme de soins.
Impact mesuré : 55-75 % de réduction sur les tâches médicales et factuelles ouvertes ; augmente l'hallucination sur le résumé fondé [52]
Mode de réflexion GPT-5 : HealthBench passe de 3,6 % à 1,6 %. Trafic ChatGPT en production : 4,8 % des réponses contiennent des affirmations incorrectes majeures contre 11,6 % sans réflexion. Ce sont des améliorations significatives.
Mais le mode de raisonnement augmente l'hallucination sur le benchmark de résumé de Vectara (voir Section 10). L'impact dépend de la tâche. Activez le raisonnement pour l'analyse, le diagnostic et les requêtes complexes. Désactivez-le pour le résumé, l'extraction et les tâches fidèles à la source.
Impact mesuré : 8 % d'amélioration de la précision par rapport aux approches mono-modèles (cadre UAF) [24]
Le cadre de Fusion sensible à l'incertitude d'Amazon (publié à l'ACM WWW 2025) a combiné plusieurs LLM pondérés par leur précision et leur qualité d'auto-évaluation. La conclusion clé : différents modèles excellent sur différents types de questions, donc leur combinaison permet de capturer des forces complémentaires.
La détection des désaccords entre modèles repère les hallucinations, car les modèles fabriquent rarement la même fausse information. Lorsqu'un modèle avance une affirmation non étayée, les autres signalent généralement l'incohérence ou fournissent des données contradictoires. Les recherches sur la « sagesse de la foule de silicium » montrent que des ensembles de LLM peuvent rivaliser avec la précision des prévisions d'une foule humaine grâce à une simple agrégation.
Le chiffre de 8 % sous-estime la valeur pratique. En production, les approches multi-modèles détectent des erreurs qu'aucune vérification mono-modèle ne signalerait — parce que le modèle de vérification a des données d'entraînement différentes, des biais différents et des angles morts différents.
Impact mesuré : amélioration de 28 % du FActScore [23]
Un pipeline en quatre étapes : générer une réponse de base, planifier des questions de vérification, répondre à ces questions de vérification de manière indépendante, puis affiner la sortie finale. Publié à l'ACL 2024, il surpasse le prompting zero-shot, few-shot et chain-of-thought en précision de génération longue.
Le coût, c'est la latence et le calcul : quatre étapes au lieu d'une. Pour les applications où la précision compte plus que la vitesse — génération de rapports, synthèse de recherche, documentation de conformité — le compromis en vaut la peine.
Impact mesuré : réduction des hallucinations de 9,7 à 53,3 % selon les familles de modèles [25]
Publié à l'ICML 2025, VeriFY apprend aux modèles à évaluer l'incertitude factuelle pendant la génération plutôt que de s'appuyer sur une vérification a posteriori. Le modèle apprend à vérifier ses propres affirmations au fur et à mesure qu'il les produit. La perte de rappel est modeste : 0,4 à 5,7 %.
Il s'agit d'une intervention au moment de l'entraînement, ce qui signifie que les utilisateurs finaux ne la contrôlent pas. Son intérêt est d'indiquer la direction du domaine : les futures générations de modèles intégreront probablement la vérification comme capacité centrale, plutôt que de l'ajouter après la génération.
Impact mesuré : réduction de 38 points de pourcentage des hallucinations de l'IA (Gemini 3.1 Pro, de 88 % à 50 %) avec seulement 1 % de perte de précision [15]
Google a montré que l'ajustement de la calibration d'un modèle — sa capacité à faire correspondre son niveau de confiance à sa précision réelle — peut réduire fortement les hallucinations sans sacrifier les connaissances. L'indice Omniscience de Gemini 3.1 Pro est passé de 16 à 33 avec cette approche.
Comme VeriFY, il s'agit d'une intervention côté fournisseur. Les utilisateurs en bénéficient en sélectionnant des versions plus récentes du modèle, mais ne peuvent pas l'appliquer eux-mêmes.
Impact mesuré : réduction de 33 % sur des tâches médicales (de 64,1 % à 43,1 %) ; GPT-4o est passé de 53 % à 23 % [40]
Des prompts structurés qui demandent au modèle de limiter ses sorties à des informations vérifiées, de signaler l'incertitude et d'éviter la spéculation. Ils fonctionnent le mieux dans des domaines étroits, aux frontières claires et à la terminologie bien définie.
Les résultats médicaux sont encourageants, mais les taux absolus restent élevés (43,1 % avec atténuation reste dangereusement erroné pour un usage clinique). Les prompts de domaine sont une couche, pas une solution.
Les modèles plus grands, à eux seuls : la précision est corrélée à la taille du modèle. Le taux d'hallucination ne l'est pas. Les modèles plus grands en savent plus, mais ne savent pas nécessairement ce qu'ils ne savent pas.
Simple réduction de la température : baisser la température de génération réduit la variété, mais n'élimine pas les hallucinations. Le modèle choisit toujours le jeton le plus probable — il le fait simplement de façon plus cohérente, y compris en choisissant de façon cohérente des jetons erronés.
Prompts système « Soyez précis » : des instructions génériques pour éviter les hallucinations ont un effet mesuré minimal. Les modèles « essaient » déjà d'être précis. Le problème est architectural, pas motivationnel.
Les recherches publiées entre 2024 et 2026 convergent de plus en plus vers un constat précis : interroger plusieurs modèles d'IA sur la même question permet de détecter des erreurs que les approches mono-modèle manquent. Ce n'est pas un argument théorique. Plusieurs études évaluées par les pairs fournissent des preuves mesurées.
Le framework Uncertainty-Aware Fusion (UAF) combine plusieurs LLM pondérés par deux facteurs : la précision de chaque modèle sur la tâche et sa capacité à s'auto-évaluer lorsqu'il est incertain. Résultat mesuré : amélioration de 8 % de la précision par rapport à tout modèle individuel. [24]
L'idée clé de l'étude : « La précision des LLM et leurs capacités d'auto-évaluation varient fortement, différents modèles excellant dans différents scénarios. » Aucun modèle ne domine tous les types de questions. GPT peut être le plus fort sur les tâches ancrées, Claude sur les tâches de calibration des connaissances, Gemini sur les tâches de couverture des connaissances. L'ensemble capture ces trois forces.
Des modèles entraînés sur des données différentes, avec des architectures différentes et des réglages d'alignement différents, développent des schémas d'échec différents. Lorsque cinq modèles analysent la même question, ils fabriquent rarement la même fausse information.
Un modèle affirme qu'un précédent juridique existe. Quatre autres ne le mentionnent pas. Ce désaccord est un signal. Un relecteur humain peut enquêter sur l'affirmation précise plutôt que de relire l'ensemble de la sortie.
Cela fonctionne parce que les hallucinations sont stochastiques, pas systématiques. Un modèle n'hallucine pas systématiquement le même fait incorrect — il comble les lacunes avec un contenu plausible différent à chaque fois. Lorsque plusieurs modèles comblent la même lacune avec un contenu contradictoire, la lacune devient visible.
Plusieurs études montrent qu'une simple agrégation des sorties de LLM peut rivaliser avec la précision des prévisions d'une foule humaine. Le mécanisme fait écho à l'expérience de Galton sur le poids d'un bœuf et à la « sagesse des foules » de Surowiecki — les estimations individuelles sont biaisées, mais l'agrégat annule les erreurs non corrélées. [28]
Pour l'IA, cela signifie : cinq modèles avec 60 % de précision individuelle, avec des erreurs non corrélées, peuvent produire des sorties agrégées nettement au-dessus de 60 % de précision. Les mathématiques favorisent la diversité plutôt que l'excellence individuelle.
Les résultats académiques ci-dessus décrivent le mécanisme. Le Suprmind Multi-Model Divergence Index le mesure sur le terrain. [61][62]
Le jeu de données : 1 324 tours de conversation multi-modèles provenant de 299 utilisateurs réels, sur 10 domaines, sur 45 jours (du 5 mars au 19 avril 2026). Cinq modèles de pointe (GPT, Claude, Gemini, Grok, Perplexity) répondant aux mêmes questions, chaque modèle lisant ce qui précède. Après chaque tour, un classificateur enregistre ce qui s'est passé entre les modèles : contradictions, corrections et insights uniques. [61]
Ce que mesure le DMI, et ce qu'il ne mesure pas. L'indice suit les désaccords et les comportements de correction. Il ne mesure pas quel modèle est factuellement correct dans un échange donné. Le fait qu'un modèle soit contredit est un signal de détection, pas un verdict. Le DMI complète des benchmarks de précision comme Vectara et AA-Omniscience ; il ne les remplace pas.
Sur l'ensemble des 1 324 tours, 99,1 % ont produit au moins une contradiction, une correction ou un insight unique provenant d'un modèle autre que le premier répondant. Le taux d'« accord silencieux » — des tours où chaque modèle était d'accord sans faire émerger quoi que ce soit de nouveau — était de 0,9 %. Dans cinq des dix domaines suivis (Juridique, Médical, Éducation, Recherche, Créatif), le taux silencieux était nul. [61]
Une requête mono-modèle aurait manqué quelque chose dans 99 tours sur 100. Le caractère factuellement critique de ce qui a été manqué varie. Le fait que quelque chose ait été manqué ne fait pas débat.
La recherche du MIT citée plus haut sur cette page a montré que les modèles d'IA sont 34 % plus confiants lorsqu'ils ont tort que lorsqu'ils ont raison. Les données du DMI montrent le même schéma dans des conversations multi-modèles en conditions réelles : une réponse à forte confiance (évaluée à 7+ sur 10) ne protège pas d'être contredite par un autre modèle.
| Modèle (réponses à forte confiance) | Contredit ou corrigé par un autre modèle |
|---|---|
| Gemini | 51.4% |
| Grok | 48.9% |
| GPT | 39.6% |
| Perplexity | 33.9% |
| Claude | 33.9% |
Source : Suprmind Multi-Model Divergence Index, édition d'avril 2026 [61]
Sur l'ensemble des cinq fournisseurs, entre une réponse sur trois et une sur deux formulées avec confiance présentait un problème substantiel détecté par un modèle pair. Sur les tours à forts enjeux en particulier, le taux de Claude est descendu à 26,4 % — le plus bas des cinq — tandis que celui de Gemini a à peine bougé (50,3 %). [61]
Ce n'est pas un taux d'hallucination. C'est un taux de détection par revue par les pairs. Mais l'implication pour l'usage mono-modèle est directe : la confiance dans la réponse d'un modèle, en l'absence de toute vérification externe, est le mode d'échec le plus courant dans les données. Ce schéma s'aligne avec le constat de l'AI Index 2026 de Stanford cité plus haut : lorsque des affirmations fausses sont formulées comme quelque chose que l'utilisateur croit, la précision mono-modèle s'effondre. Le mécanisme de revue multi-modèle capture ce mode d'échec parce qu'un second modèle, non ancré dans le cadrage trop confiant du premier, applique sa propre base à la même affirmation. [58][61]
Chaque modèle du jeu de données DMI a un « ratio de détection » : corrections qu'il a apportées aux autres, divisées par les corrections qu'il a reçues des autres. Un ratio supérieur à 1,0 signifie que le modèle détecte plus qu'il n'est détecté.
| Fournisseur | Détections effectuées | Nombre de fois détecté | Ratio de détection |
|---|---|---|---|
| Perplexity | 335 | 132 | 2.54 |
| Claude | 304 | 135 | 2.25 |
| Grok | 193 | 269 | 0.72 |
| GPT | 111 | 295 | 0.38 |
| Gemini | 109 | 416 | 0.26 |
Source : Suprmind Multi-Model Divergence Index, édition d'avril 2026 [61]
Perplexity détecte environ dix fois plus souvent que Gemini. Ce n'est pas un classement du « meilleur » modèle — l'avantage de Perplexity vient en partie de son architecture ancrée sur la recherche, qui lui donne un avantage structurel pour signaler des affirmations non étayées. L'essentiel est que la détection n'est pas aléatoire. Des architectures différentes produisent des profils de détection différents, ce que la thèse multi-modèle prédit précisément. [61]
Taux de désaccord par domaine, classé du plus élevé au plus faible :
| Domaine | Tours multi-modèles | Tours avec désaccord |
|---|---|---|
| Finance | 258 | 72.1% |
| Autre | 153 | 59.6% |
| Marketing & ventes | 131 | 55.0% |
| Stratégie d'entreprise | 257 | 54.9% |
| Analyse de recherche | 74 | 52.7% |
| Technique | 172 | 49.4% |
| Créatif | 38 | 42.1% |
| Juridique | 135 | 41.5% |
| Médical | 56 | 33.9% |
| Éducation | 49 | 28.6% |
Source : Suprmind Multi-Model Divergence Index, édition d'avril 2026 [61]
Les questions financières produisent des désaccords entre modèles sur près de trois tours sur quatre. Les questions d'éducation en produisent sur environ un tour sur quatre. Les domaines à forts enjeux où cette page a documenté les pires conséquences des hallucinations — finance, juridique, médical — sont les mêmes domaines où faire passer les questions par plus d'un modèle fait apparaître le plus de divergence. Analyse de recherche en particulier : 52,2 % des contradictions dans ce domaine ont été classées de gravité critique (7+ sur une échelle de 10), la part critique la plus élevée de tous les domaines. Lorsque les modèles sont en désaccord sur des questions de recherche, ils ont tendance à être en désaccord sur quelque chose d'important. [61]
La recherche académique a établi que les ensembles surpassent les modèles individuels. Le DMI montre le mécanisme de détection s'activer en usage réel en production — pas dans des benchmarks conçus pour cela, pas en conditions de laboratoire, mais dans des conversations en direct avec des utilisateurs payants sur de vraies questions. Le mécanisme prédit par la recherche est le mécanisme observé dans les données de production.
La réserve honnête restante de la section ci-dessus reste valable : la validation croisée augmente la probabilité de détection, elle ne garantit pas zéro hallucination. Deux constats dans ce jeu de données renforcent ce point. Premièrement, les modèles s'accordent encore parfois sur la même mauvaise réponse — le DMI ne détecte pas les erreurs partagées issues des données d'entraînement. Deuxièmement, le DMI compte les contradictions et les corrections, pas leurs résolutions. Savoir que deux modèles sont en désaccord n'est pas la même chose que savoir lequel avait raison.
Le désaccord est le signal ; la vérification reste le travail de l'utilisateur.
Détecte bien :
Détecte moins bien :
La validation multi-modèle est une couche de détection, pas une garantie. Elle augmente la probabilité de repérer des hallucinations. Elle ne les élimine pas. Les organisations qui obtiennent les meilleurs résultats combinent la validation croisée multi-modèle avec une vérification spécifique au domaine, des points de contrôle de revue humaine et un ancrage via des outils. [27]
Il existe encore peu de rapports publics standardisés mesurant « la validation croisée à cinq modèles réduit les hallucinations de X % » selon les domaines, dans des conditions contrôlées. L'amélioration de 8 % du framework UAF est le chiffre unique le plus solide. Des études de cas en production provenant de plateformes multi-modèles émergent, mais ne sont pas encore publiées dans des revues à comité de lecture.
La position la plus sûre, fondée sur les preuves : l'orchestration multi-modèle est une architecture de réduction du risque qui augmente la probabilité de détection. Elle ne garantit pas zéro hallucination. Aucune approche n'atteint cette garantie — comme le démontrent les preuves mathématiques de la Section 11.
Posez une question où la précision compte. Regardez cinq modèles d'IA répondre — et voyez où ils sont en désaccord.
Ouvrir le PlaygroundLe marché de la détection des hallucinations a progressé de 318 % entre 2023 et 2025, avec 12,8 milliards de dollars investis dans des solutions dédiées. Ce taux de croissance reflète à quel point les entreprises prennent le problème au sérieux — et à quel point les garde-fous intégrés aux modèles sont insuffisants pour un usage en production. [35]
| Outil | Précision de détection | Atout clé |
|---|---|---|
| W&B Weave | 91% | Raisonnement chain-of-thought, intégration au pipeline de production |
| Arize Phoenix | 90% | Sorties basées sur des labels, scoring de confiance, monitoring en temps réel |
| Comet Opik | 72% | 100 % de précision (zéro faux positifs), approche conservatrice |
| Galileo | N/A | Scoring Hallucination Index, blocage en temps réel, intégration CI/CD |
| GPTZero Citation Check | 99%+ | Citations vérifiées par rapport à des bases web/académiques |
| Future AGI | N/A | Détection des hallucinations spécifique au RAG, monitoring d'expériences |
| Pythia | N/A | Vérification des faits basée sur un graphe de connaissances, secteurs réglementés |
Sources : benchmark AIMultiple (2026) [46], Future AGI (2025) [47], GPTZero/Fortune [45]
Les meilleurs outils de détection repèrent 90 à 91 % des hallucinations. Cela signifie qu'environ 1 sortie hallucinatée sur 10 passe encore inaperçue, même avec la meilleure vérification automatisée disponible. Pour les applications où une seule hallucination non détectée a des conséquences matérielles — dépôts juridiques, décisions médicales, reporting financier — la détection automatisée est une couche nécessaire, mais pas suffisante.
L'approche de Comet Opik mérite d'être mentionnée à part. Avec 72 % de précision de détection, il repère moins d'hallucinations. Mais il a 100 % de précision — zéro faux positifs. Il ne signale jamais une affirmation correcte comme hallucinatée. Pour des flux de travail où les fausses alertes sont coûteuses (interrompre un médecin en plein diagnostic, signaler une citation juridique correcte pour relecture), ce compromis peut être préférable.
| Année | Meilleur taux d'hallucination | Contexte |
|---|---|---|
| 2021 | ~21,8 % | Début de l'ère GPT-3 |
| 2022 | ~15,0 % | Améliorations d'alignement RLHF |
| 2023 | ~8,0 % | Lancement de GPT-4 et pression concurrentielle |
| 2024 | ~3,0 % | Itération rapide chez tous les fournisseurs |
| 2025 | 0,7 % | Gemini-2.0-Flash sur le jeu de données original de Vectara |
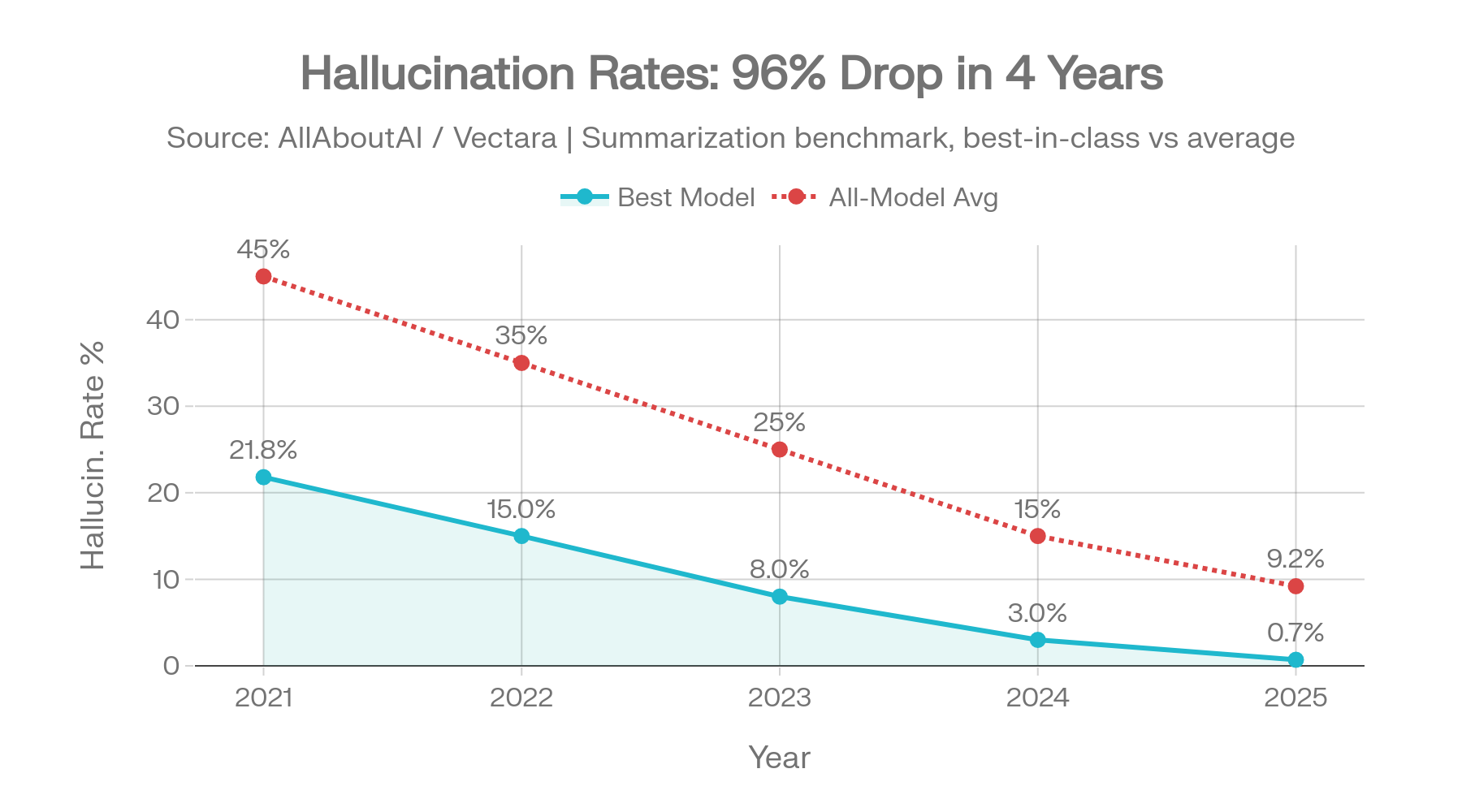
Quatre ans d'amélioration des hallucinations sur des tâches simples de synthèse : 21,8 % → 0,7 %. Sources : Vectara [1], AllAboutAI [31]
Cela représente une réduction de 96 % des meilleurs taux d'hallucination des modèles en quatre ans sur le benchmark de synthèse Vectara. La tendance est réelle et elle est marquée.
Ces améliorations mesurent la version la plus facile du problème : résumer de courts documents sans ajouter de faits non étayés. Lorsque vous passez à des évaluations plus difficiles et plus réalistes, le tableau change :
AA-Omniscience (questions de connaissances difficiles) : 36 modèles sur 40 sont plus susceptibles de donner une réponse fausse avec confiance qu'une réponse correcte. Seuls quatre modèles ont obtenu un indice Omniscience positif. [2]
HalluHard (conversations réalistes) : Même le meilleur modèle (Claude Opus 4.5 avec recherche web) hallucine 30 % du temps. La plupart des modèles se situent dans la fourchette 50-70 %. [5]
Nouveau jeu de données Vectara (documents de longueur entreprise) : Les taux augmentent de 3 à 10 fois par rapport au jeu de données original. Le meilleur score est de 3,3 %, pas 0,7 %. [1]
Tâches spécifiques au domaine : Les hallucinations juridiques atteignent en moyenne 18,7 %. Le médical atteint en moyenne 15,6 %. Ces domaines n'ont pas montré la même trajectoire d'amélioration que la synthèse générale. [31]
L'amélioration est réelle. Mais extrapoler des benchmarks simples vers la fiabilité en entreprise est une erreur que les données ne soutiennent pas.
Cette page s'appuie sur les sources primaires suivantes :
Benchmarks : Vectara HHEM Leaderboard (à la fois le jeu de données original d'environ 1 000 documents et le jeu de données actualisé de 7 700 articles), Artificial Analysis AA-Omniscience, Google DeepMind FACTS Benchmark, OpenAI SimpleQA et PersonQA, HalluHard (consortium de recherche suisse-allemand) et l'étude de la Columbia Journalism Review sur la précision des citations.
Fiches système et rapports techniques : fiche système OpenAI GPT-5, mise à jour de déploiement GPT-5.2, fiche système o3/o4-mini, annonces de modèles Anthropic pour Claude Opus 4.5/4.6 et Sonnet 4.6, article méthodologique Google DeepMind FACTS.
Études sectorielles et données d'incidents : étude Stanford RegLab/HAI sur l'IA juridique, recherche MedRxiv sur les hallucinations médicales, Deloitte Global AI Survey, analyse Forrester des coûts de l'IA en entreprise, compilation AllAboutAI des statistiques d'hallucination, suivi Business Insider des décisions de justice, base de données Damien Charlotin sur les hallucinations de citations juridiques, et analyse GPTZero/Fortune NeurIPS 2025.
Recherche académique : Xu et al. (2024) sur l'impossibilité d'éliminer les hallucinations, Karpowicz (2025) sur l'impossibilité mathématique selon trois cadres de preuve, framework Uncertainty-Aware Fusion Amazon/ACM WWW 2025, vérification au moment de l'entraînement VeriFY (ICML 2025), Chain-of-Verification (ACL 2024).
Ajouts d'avril 2026 : Stanford HAI 2026 AI Index Report (benchmark de sycophancy et base de données d'incidents IA), instantané Vectara HHEM du 20 avril 2026, état Artificial Analysis AA-Omniscience d'avril 2026 (Claude Opus 4.7, GPT-5.5, Grok 4.20), base Damien Charlotin (1 200+ affaires juridiques), OpenAI HealthBench Professional, et édition d'avril 2026 du Suprmind Multi-Model Divergence Index.
Cette page inclut désormais des données du Suprmind Multi-Model Divergence Index (DMI), une publication trimestrielle qui suit les schémas de désaccord et de correction inter-modèles en usage réel en production de la plateforme Suprmind. L'édition d'avril 2026 couvre 1 324 tours de conversation multi-modèles provenant de 299 utilisateurs, sur 10 domaines, sur une fenêtre de 45 jours (du 5 mars au 19 avril 2026). [61][62]
Ce que mesure le DMI : la fréquence à laquelle les modèles d'IA se contredisent, se corrigent et font émerger des insights manqués par d'autres modèles lorsqu'ils sont exécutés ensemble sur la même question.
Ce que le DMI ne mesure pas : la précision factuelle par rapport à la vérité terrain. Le DMI enregistre qu'un modèle en a contredit un autre. Il ne tranche pas lequel avait raison. Le désaccord est traité comme un signal de détection, pas comme un verdict de précision.
Nous considérons les données du DMI et les benchmarks de précision comme complémentaires, et non interchangeables. Vectara, AA-Omniscience, FACTS et les autres benchmarks de cette page mesurent la fréquence à laquelle les modèles se trompent en isolation. Le DMI mesure la fréquence à laquelle les modèles se détectent mutuellement en production. Les deux questions comptent. Ce ne sont pas les mêmes questions.
Le jeu de données DMI, la méthodologie et les douze fichiers CSV sous-jacents sont publiquement disponibles sur la page liée dans les références. Les données de comptes internes sont exclues ; le jeu de données publié ne concerne que des utilisateurs externes.
Cadence de mise à jour : trimestrielle. Prochaine édition : juillet 2026.
TruthfulQA — partiellement saturé. Inclus dans les données d'entraînement des modèles, contient certaines réponses de référence incorrectes, et peut être « optimisé » jusqu'à 79,6 % de précision par un arbre de décision qui ne voit jamais la question.
HaluEval — résoluble par la longueur de la réponse. Un classificateur qui signale comme hallucinatées les réponses de plus de 27 caractères atteint 93,3 % de précision, ce qui compromet la validité du benchmark pour comparer les modèles.
Benchmarks communautaires non vérifiés — les posts Reddit, affirmations sur Twitter et articles de blog citant des chiffres de benchmark sans documentation méthodologique ni informations de reproductibilité ont été exclus, sauf s'ils pouvaient être recoupés avec des sources primaires.
Allégations marketing des fournisseurs — lorsqu'un fournisseur revendique un taux d'hallucination spécifique mais que des benchmarks indépendants montrent des chiffres différents, les deux sont présentés avec la divergence signalée. Cela s'applique en particulier aux benchmarks Grok internes de xAI par rapport aux résultats AA-Omniscience.
Les instantanés Vectara sont datés. Le jeu de données original a été évalué jusqu'en avril 2025. Le jeu de données actualisé couvre novembre 2025 à février 2026, avec l'instantané le plus récent daté du 25 février 2026. AA-Omniscience a été lancé en novembre 2025 et a été mis à jour au fur et à mesure des sorties de nouveaux modèles. FACTS a été publié en décembre 2025. Les fiches système OpenAI sont datées selon les sorties.
Lorsque deux benchmarks affichent des chiffres différents pour le même modèle, cela reflète généralement des dates d'évaluation différentes, des versions de jeu de données différentes ou des aspects différents de la factualité mesurés. Nous signalons ces écarts plutôt que de les moyenner.
Les modèles Perplexity Sonar ne sont pas listés sur AA-Omniscience ni sur Vectara. Perplexity utilise des modèles sous-jacents (dont GPT et des variantes DeepSeek), ce qui rend l'attribution des hallucinations complexe. Leurs résultats SimpleQA et Search Arena sont inclus lorsque disponibles.
Claude Opus 4.6 et Sonnet 4.6 ont été publiés en février 2026. Les données AA-Omniscience apparaissent, mais elles sont encore précoces. Les scores Vectara sur le nouveau jeu de données ne sont pas encore disponibles pour la génération 4.6.
GPT-5.3 dispose de données AA-Omniscience (51,8 % de précision pour la variante Codex), mais la couverture sur les autres benchmarks reste limitée à ce jour.
Les ventilations par domaine de la plupart des benchmarks testent des connaissances générales. Les données d'hallucination spécifiques à l'industrie (finance, médical, juridique) proviennent principalement d'études spécialisées plutôt que des principaux leaderboards.
Les chiffres de coûts business proviennent d'enquêtes et d'estimations plutôt que de bases d'incidents vérifiées. Le chiffre de 67,4 milliards de dollars, les coûts de vérification par employé et les fourchettes par incident doivent être considérés comme indicatifs plutôt que précis.
Mensuel : instantanés du leaderboard Vectara, ajouts de nouveaux modèles AA-Omniscience, mises à jour des fiches système OpenAI, données de sortie de nouveaux modèles.
Trimestriel : changements du leaderboard FACTS, introduction de nouveaux benchmarks, résultats d'articles académiques, évolutions réglementaires (notamment l'application de l'EU AI Act liée aux exigences de précision).
Au besoin : sorties majeures de modèles, rapports d'incidents significatifs, jalons de décisions de justice et changements de méthodologie des benchmarks.
Un taux d'hallucination de l'IA mesure la fréquence à laquelle un modèle génère des informations fausses ou fabriquées présentées comme des faits. Le taux varie selon les benchmarks car différents tests mesurent différents modes d'échec. Vectara mesure la fréquence à laquelle un modèle ajoute des faits inventés en résumant un document. AA-Omniscience mesure la fréquence à laquelle un modèle donne une réponse fausse avec confiance au lieu d'admettre qu'il ne sait pas. FACTS mesure la facticité selon quatre dimensions : ancrage, multimodal, connaissances paramétriques et recherche. Un modèle peut obtenir 0,7 % sur Vectara et 88 % sur AA-Omniscience simultanément, car les tests mesurent des choses complètement différentes.
Il n'y a pas de réponse unique — cela dépend entièrement de la tâche. Sur des questions de connaissances où le modèle doit admettre son ignorance : Claude 4.1 Opus a atteint 0 % d'hallucination sur AA-Omniscience en refusant de répondre plutôt qu'en devinant. Sur la synthèse de documents : Gemini-2.0-Flash est en tête du jeu de données original Vectara avec un taux d'hallucination de 0,7 %. Sur la facticité multidimensionnelle : Gemini 3 Pro a obtenu 68,8 sur le benchmark FACTS. Sur des tâches conversationnelles réalistes : Claude Opus 4.5 a atteint 30 % sur HalluHard avec la recherche web activée. Aucun modèle n'est en tête sur tous les benchmarks.
Le taux d'hallucination de Claude varie fortement selon la version du modèle et le benchmark. Claude 4.1 Opus : 0 % d'hallucination sur AA-Omniscience (refuse plutôt que devine), score FACTS 46,5. Claude Opus 4.6 : 12,2 % sur le nouveau jeu de données Vectara, 46,4 % de précision sur AA-Omniscience, indice Omniscience 14. Claude Opus 4.5 : 45,7 % de précision sur AA-Omniscience avec 58 % de taux d'hallucination, score FACTS 51,3, 30 % sur HalluHard. Claude Sonnet 4.6 : 10,6 % sur le nouveau Vectara, environ 38 % de taux d'hallucination sur AA-Omniscience. Claude 4.5 Haiku : 25 % de taux d'hallucination sur AA-Omniscience, troisième plus faible de tous les modèles testés. Sur le nouveau jeu de données Vectara plus difficile, les modèles Claude dépassent systématiquement 10 %.
GPT-5.3 Codex : 51,8 % de précision sur AA-Omniscience, pas encore de données Vectara. GPT-5.2 (xhigh) : 10,8 % sur le nouveau jeu de données Vectara, 43,8 % de précision sur AA-Omniscience avec environ 78 % de taux d'hallucination, score FACTS 61,8, HalluHard 38,2 %. GPT-5 : 1,4 % sur Vectara original, plus de 10 % sur le nouveau jeu de données, 40,7 % de précision sur AA-Omniscience. GPT-4.1 : 2,0 % sur Vectara original, 5,6 % sur le nouveau, score FACTS 50,5. GPT-5.2 obtient le meilleur score parmi les modèles OpenAI sur FACTS (61,8), mais hallucine à environ 78 % sur les questions de connaissances difficiles AA-Omniscience.
Grok 4 : 4,8 % sur Vectara original, plus de 10 % sur le nouveau jeu de données, 41,4 % de précision sur AA-Omniscience avec 64 % de taux d'hallucination, score FACTS 53,6. Grok 4.1 Fast Reasoning : 20,2 % sur le nouveau jeu de données Vectara (le plus élevé de tous les modèles Frontier testés), 72 % de taux d'hallucination sur AA-Omniscience, score FACTS 36,0. Grok-3 : 2,1 % sur Vectara original, 5,8 % sur le nouveau, 94 % d'hallucination de citations sur CJR. La variante Grok 4.1 Fast Reasoning performe nettement moins bien que Grok 4 de base, ce qui suggère que le mode de raisonnement ajoute des inférences qui deviennent des hallucinations sur des tâches factuelles.
Gemini 3.1 Pro : 10,4 % sur le nouveau jeu de données Vectara, 55,3 % de précision sur AA-Omniscience (le plus élevé de tous les modèles) avec 50 % de taux d'hallucination, indice Omniscience 33 (le plus élevé au total). Gemini 3 Pro : 13,6 % sur le nouveau Vectara, 55,9 % de précision mais 88 % d'hallucination sur AA-Omniscience, score FACTS 68,8 (le plus élevé au total). Gemini 2.0 Flash : 0,7 % sur Vectara original (le plus faible de tous les modèles), 3,3 % sur le nouveau jeu de données. La mise à jour 3.1 Pro a été significative : les hallucinations sont passées de 88 % à 50 % avec seulement 1 % de perte de précision. Les modèles Gemini savent le plus, mais fabriquent le plus agressivement lorsqu'ils sont incertains.
Perplexity Sonar Pro a obtenu 37 % d'hallucination de citations sur le benchmark de la Columbia Journalism Review — le plus faible de tous les modèles testés, mais cela signifie tout de même que plus d'une source citée sur trois contenait des affirmations fabriquées. ChatGPT a atteint 67 % sur le même test. Gemini a atteint 76 %. Grok-3 est monté à 94 %. Le mode d'échec de Perplexity est particulièrement dangereux : les URL citées sont réelles, mais l'information attribuée à ces sources est parfois fabriquée. Il n'existe pas de données de benchmark Vectara ou AA-Omniscience pour les modèles Perplexity Sonar.
Différents benchmarks mesurent des modes d'échec fondamentalement différents. Vectara teste la fidélité de la synthèse. AA-Omniscience teste la calibration des connaissances. FACTS teste la facticité multi-dimensionnelle à travers l'ancrage, le multimodal, le paramétrique et la recherche. CJR teste la précision des citations. Un modèle comme Grok-3 obtient 2,1 % sur Vectara (reste bien fidèle aux documents sources) mais 94 % sur CJR (fabrique presque chaque citation). Les deux chiffres sont exacts. Ils mesurent des compétences différentes. L'approche responsable : recoupez au moins deux benchmarks mesurant des choses différentes, précisez la version exacte du modèle et les réglages, et notez si la recherche web ou le mode de raisonnement était activé.
Non. Deux preuves mathématiques indépendantes ont démontré que l'hallucination est une limitation fondamentale de l'architecture des modèles de langage. Ce n'est pas un problème d'ingénierie en attente d'une correction. Les meilleurs taux d'hallucination sont passés de 21,8 % à 0,7 % en quatre ans sur des tâches simples de synthèse. Mais sur des tâches plus difficiles — questions juridiques (18,7 % en moyenne), requêtes médicales (15,6 %), questions de connaissances nécessitant que le modèle s'appuie sur ses propres données d'entraînement — les taux restent élevés pour tous les modèles. La communauté de recherche est passée de l'élimination des hallucinations à la gestion du risque d'hallucination via la détection, le signalement, le confinement et la validation croisée. L'accès à la recherche web est le plus grand facteur de réduction, diminuant les taux d'hallucination de 73 à 86 % lorsqu'il est activé.
Les pertes mondiales des entreprises dues aux hallucinations de l'IA ont atteint une estimation de 67,4 milliards de dollars en 2024. 47 % des dirigeants ont déclaré avoir pris des décisions majeures sur la base de contenus générés par l'IA non vérifiés. 66 % des utilisateurs s'appuient sur les sorties de l'IA sans en évaluer la précision. Il existe plus de 944 affaires juridiques documentées impliquant de fausses informations générées par l'IA. Les coûts spécifiques au domaine vont de 18 000 $ par incident de service client à 2,4 millions de dollars dans des affaires de faute médicale. La FDA a autorisé plus de 1 350 dispositifs médicaux améliorés par l'IA, dont 60 dispositifs impliqués dans 182 rappels.
Les recherches le soutiennent de plus en plus. Différents modèles d'IA hallucinent rarement la même fausse information car ils ont des données d'entraînement différentes, des architectures différentes et des angles morts différents. Une étude sur le framework UAF a mesuré une amélioration de 8 % de la précision via des approches d'ensemble multi-modèles. Le désaccord inter-modèles détecte les fabrications précisément parce que les modes d'échec ne se recouvrent pas. Lorsque trois modèles analysent la même question et que deux sont en désaccord avec le troisième, le désaccord lui-même est un signal qu'une affirmation nécessite une revue humaine. C'est le principe des plateformes d'orchestration multi-IA qui routent les questions vers plusieurs modèles Frontier simultanément. Voir comment Suprmind utilise cette approche →
Cinq modèles de pointe. Une seule conversation. Chaque réponse est recoupée. Découvrez pourquoi les professionnels qui ne peuvent pas se permettre de se tromper passent à la validation multi-modèles.
Sélectionnez votre offre -->


