



Zuletzt aktualisiert am 26. April 2026
Die vollständigen Datenreferenzen zu KI-Halluzinationen. Rohdaten von Vectara,
AA-Omniscience, FACTS, OpenAI Systemkarten und über 50 Quellen.
Monatlich aktualisiert.
Update April 2026 hinzugefügt: Stanford KI-Index-Daten, Claude Opus 4.7, Grok 4.20,
GPT-5.5-Paradoxon, Eskalation von Rechtsfällen, Integration des Multi-Modell-Divergenz-Index
67,4 Mrd. $
Globale Geschäftsverluste durch KI-Halluzinationen im Jahr 2024 [31]
0.7%
Best-Case-Halluzinationsrate bei einfacher Zusammenfassung (Gemini-2.0-Flash) [1]
88%
Halluzinationsrate, wenn Gemini 3 Pro die Antwort nicht kennt (Gemini 3.1 Pro verbesserte dies auf 50 %) [2]
4 / 40
Modelle, die bei schwierigen Wissensfragen besser abschnitten als ein Münzwurf [2]
Aus dem Multi-Modell-Divergenz-Index – April 2026
2.63
Einzigartige Erkenntnisse pro Multi-Modell-Durchlauf – Perspektiven, die eine einzelne KI nicht aufdeckte (1.324 Produktionsdurchläufe) [61]
51.4%
Der hochzuverlässigen Antworten von Gemini wurden von einem anderen Modell widersprochen – Vertrauen ist nicht gleich Genauigkeit [61]
26.4%
Claudes hochriskante Vertrauens-Widerspruchsrate – die niedrigste von fünf Anbietern [61]
72.1%
Der Finanzfragen zeigte Uneinigkeit zwischen den Modellen – die risikoreichsten Bereiche divergieren am stärksten [61]
Jedes große KI-Modell halluziniert. Generative KI kann aufgrund ihres Designs nicht halluzinationsfrei sein – aber das Risiko kann gemindert werden, bevor es Ihre Entscheidung erreicht und Sie Geld kostet. Sehen Sie, wie Multi-Modell-Verifizierung als Minderungsstrategie funktioniert.
Diese Seite verfolgt die Halluzinationsraten über sechs Benchmarks hinweg, deckt jedes Frontier-Modell von GPT-5.5 über Claude 4.7 bis Gemini 3.1 und Grok 4.20 ab und präsentiert die Daten ohne Schönfärberei. Die Zahlen stimmen nicht überein – und wir erklären, warum das wichtiger ist als jede einzelne Bestenliste.
Universelle Cross-Benchmark-Halluzinationsreferenz (April 2026)
So lesen Sie diese Tabelle
Jede Zahl unten stammt aus einem anderen Benchmark, der einen anderen Aspekt der Halluzination misst. Eine niedrige Vectara- + hohe AA-Omniscience-Halluzination bedeutet, dass das Modell gut in der Zusammenfassung ist, aber schlecht darin, Unwissenheit zuzugeben. Eine hohe FACTS- + niedrige AA-Omniscience-Genauigkeit bedeutet, dass das Modell mit Tools genau ist, aber zu viele Fragen versucht. Keine einzelne Spalte erzählt die ganze Geschichte. Vergleichen Sie mindestens zwei.
Spaltenübersicht:
- Vectara (Alt): Zusammenfassungsgenauigkeit bei kurzen Dokumenten. Niedriger = besser.
- Vectara (Neu): Zusammenfassungsgenauigkeit bei unternehmenslangen Dokumenten. Niedriger = besser.
- AA-Omni Acc: Genauigkeit bei schwierigen Wissensfragen in 42 Themenbereichen. Höher = besser.
- AA-Omni Hall: Wie oft das Modell falsche Antworten gibt, anstatt abzulehnen. Niedriger = besser.
- AA-Omni Index: Kombinierter Wissenszuverlässigkeitswert (-100 bis +100). Höher = besser.
- FACTS: Mehrdimensionale Faktizität über Grounding, Multimodalität, Parametrik und Suche. Höher = besser.
- HalluHard: Halluzinationsrate in realistischen Gesprächen. Niedriger = besser.
- CJR Citation: Zitations-Halluzinationsrate (Nachrichtenquellen). Niedriger = besser.
Halluzinationsraten von Frontier KI-Modellen im Ranking
| Modell | Anbieter | Vectara (Alt) | Vectara (Neu) | AA-Omni Acc | AA-Omni Hall | AA-Omni Index | FACTS | HalluHard | CJR-Zitat |
| GPT-5.3 Codex | OpenAI | – | – | 51.8% | – | – | – | – | – |
| GPT-5.5 (sehr hoch) | OpenAI | – | – | 57% | 86% | 20 | – | – | – |
| GPT-5.2 (sehr hoch) | OpenAI | – | 10.8% | 43.8% | ~78 % | – | 61.8 | 38.2% | – |
| GPT-5 | OpenAI | 1.4% | >10 % | 40.7% | – | – | 61.8 | – | – |
| GPT-5.1 | OpenAI | – | – | 37.6% | 81% | Positiv | 49.4 | – | – |
| GPT-4.1 | OpenAI | 2.0% | 5.6% | – | – | – | 50.5 | – | – |
| o3-mini-high | OpenAI | 0.8% | 4.8% | – | – | – | 52.0 | – | – |
| Claude 4.1 Opus | Anthropic | – | – | – | 0% | – | 46.5 | – | – |
| Claude Opus 4.6 | Anthropic | – | 12.2% | 46.4% | – | 14 | – | – | – |
| Claude Opus 4.7 | Anthropic | – | – | – | 36% | 26 | – | – | – |
| Claude Opus 4.5 | Anthropic | – | – | 45.7% | 58% | Negativ | 51.3 | 30% | – |
| Claude Sonnet 4.6 | Anthropic | – | 10.6% | 40.0% | ~38 % | – | – | – | – |
| Claude Sonnet 4.5 | Anthropic | – | >10 % | – | 48% | – | 49.1 | – | – |
| Claude 3.7 Sonnet | Anthropic | 4.4% | – | – | – | – | – | – | – |
| Claude 4.5 Haiku | Anthropic | – | – | – | 25% | – | – | – | – |
| Gemini 3.1 Pro | – | 10.4% | 55.3% | 50% | 33 | – | – | – | |
| Gemini 3 Pro | – | 13.6% | 55.9% | 88% | 16 | 68.8 | – | – | |
| Gemini 3 Flash | – | – | 54.0% | 91% | – | – | – | – | |
| Gemini 2.5 Pro | – | 7.0% | – | – | – | 62.1 | – | – | |
| Gemini 2.0 Flash | 0.7% | 3.3% | – | – | – | – | – | – | |
| Grok 4 | xAI | 4.8% | >10 % | 41.4% | 64% | Positiv | 53.6 | – | – |
| Grok 4.1 Fast | xAI | – | 20.2% | – | 72% | – | 36.0 | – | – |
| Grok 4.20 (Reasoning) | xAI | – | – | – | 17% | – | – | – | – |
| Grok-3 | xAI | 2.1% | 5.8% | – | – | – | – | – | 94% |
| Perplexity Sonar Pro | Perplexity | – | – | – | – | – | – | – | 37% |
| DeepSeek-V3 | DeepSeek | 3.9% | 6.1% | – | – | – | – | – | – |
| DeepSeek-R1 | DeepSeek | 14.3% | 11.3% | – | 83% | – | – | – | – |
| Llama 4 Maverick | Meta | 4.6% | – | – | 87.6% | – | – | – | – |
Quellen: Vectara HHEM Leaderboard (April 2025 + Feb 2026 + 20. April 2026 Momentaufnahmen) [1], Artificial Analysis AA-Omniscience (Nov 2025 – April 2026) [2], Google DeepMind FACTS Benchmark (Dez 2025) [3], HalluHard Benchmark (2025) [5], Columbia Journalism Review (März 2025) [6]. Bindestriche zeigen an, dass für dieses Modell keine veröffentlichten Daten zu diesem Benchmark vorliegen.
Kurzreferenz-Ergebnisse
Niedrigste Halluzinationsrate (Wissensaufgaben): Claude 4.1 Opus – 0 % bei AA-Omniscience (Modell lehnt Antwort bei Unsicherheit ab)
Größte Einzelverbesserung: Gemini 3.1 Pro – Halluzination sank um 38 Prozentpunkte (88 % auf 50 %) bei 1 % Genauigkeitsverlust
Niedrigste Halluzinationsrate (wenn Modelle versuchen zu antworten): Grok 4.20 (Reasoning) – 17 % bei AA-Omniscience (April 2026)
Größte Variable bei allen Modellen: Webzugriff – reduziert Halluzinationen um 73–86 %, wenn aktiviert
Beste Zitationsgenauigkeit: Perplexity Sonar Pro – 37 % Halluzination bei CJR (niedrigster Wert, aber immer noch hoch)
Niedrigste Halluzinationsrate (Zusammenfassung): Gemini-2.0-Flash – 0,7 % im ursprünglichen Vectara-Datensatz
Am besten in realistischen Gesprächen: Claude Opus 4.5 – 30 % bei HalluHard (mit Websuche)
Bester Wissenszuverlässigkeitsindex: Gemini 3.1 Pro – Index 33 bei AA-Omniscience
Höchster Faktizitätswert (mehrdimensional): Gemini 3 Pro – 68,8 bei FACTS
Sehen Sie, wie der Suprmind Multi-KI-Ansatz Halluzinationen mindert
Suprmind reduziert Halluzinationen, indem es fünf Frontier-Modelle in dieselbe strukturierte Konversation bringt, wo sie sich gegenseitig in ihren Behauptungen herausfordern, Widersprüche aufdecken, Meinungsverschiedenheiten äußern und Schlussfolgerungen auf die Probe stellen, bevor die Ausgabe Ihre Arbeit erreicht.
Wenn KI-Modelle nicht übereinstimmen, offenbart diese Uneinigkeit Komplexität und oft übersehene Aspekte des Themas oder Problems.
Suprmind deckt dies auf, quantifiziert es und verwandelt es mit drei Klicks in ein professionelles Ergebnis – so werden die schwierigen Fragen beantwortet, bevor die Entscheidung getroffen wird.
Uneinigkeit ist das Feature.
ÜBERZEUGEN SIE SICH SELBST
Suprmind Sequential Modus in einem einfachen Szenario erleben
Diese interaktive Multi-Modell-KI-Demo dauert etwa 90 Sekunden. Erkunden Sie die rechte Seitenleiste und das Master Dokument, während sie abgespielt wird. Scrollen Sie weg, um zu pausieren; scrollen Sie zurück, wenn Sie bereit sind, und es wird dort fortgesetzt, wo Sie aufgehört haben.
Inhaltsverzeichnis
1. Was ist eine KI-Halluzination?
3. Vectara Halluzinations-Bestenliste
5. FACTS Benchmark (Google DeepMind)
6. Halluzinationsprofile von Frontier-Modellen
8. Domänenspezifische Halluzinationsraten
9. Geschäftsrelevante Statistiken
11. Warum null Halluzinationen mathematisch unmöglich sind
12. Was Halluzinationen tatsächlich reduziert
14. Tools zur Halluzinationserkennung
16. Methodik und wie diese Daten zu lesen sind
Hören Sie die vollständige Recherche (51 Min.)
Was ist eine KI-Halluzination?
Einfach ausgedrückt
Eine KI-Halluzination liegt vor, wenn ein KI-Modell etwas erfindet und es als Tatsache darstellt. Es kennzeichnet keine Unsicherheit. Es sagt nicht „Ich rate mal“. Es liefert erfundene Statistiken, erfundene Rechtsfälle oder nicht existierende Forschungsarbeiten mit derselben Sicherheit, mit der es grundlegende Rechenaufgaben löst. Die Ausgabe liest sich perfekt. Das macht sie gefährlich.
Die technische Definition
Halluzination bezieht sich auf generierte Ausgaben, die nicht auf den bereitgestellten Eingaben oder der faktischen Realität basieren. Zwei Arten:
Intrinsische Halluzination (Fehler bei der Treue): Das Modell widerspricht Informationen, die ihm explizit gegeben wurden. Man gibt ihm einen Vertrag und bittet um eine Zusammenfassung – es fügt Klauseln hinzu, die im Originaldokument nicht existieren.
Extrinsische Halluzination (Fehler bei der Faktizität): Das Modell generiert Informationen, die nicht anhand einer bekannten Quelle überprüft werden können. Es erfindet Fakten, Statistiken, Zitate oder Ereignisse aus dem Nichts. Es wurde kein Quellmaterial widersprochen, da kein Quellmaterial konsultiert wurde.
Das Vertrauensparadoxon
MIT-Forscher entdeckten im Januar 2025 etwas Beunruhigendes: KI-Modelle verwenden selbstbewusstere Sprache, wenn sie halluzinieren, als wenn sie Fakten darlegen. Modelle verwendeten mit 34 % höherer Wahrscheinlichkeit Phrasen wie „definitiv“, „zweifellos“ und „ohne jeden Zweifel“, wenn sie falsche Informationen generierten.
Je falscher die KI, desto sicherer klingt sie.
Warum es passiert
Große Sprachmodelle sind Vorhersage-Engines, keine Wissensdatenbanken. Sie generieren Text, indem sie das statistisch wahrscheinlichste nächste Token basierend auf Mustern in Trainingsdaten vorhersagen. Sie verstehen die Wahrheit nicht. Sie sagen Plausibilität voraus.
Wenn das Modell auf eine Lücke in seinen Trainingsdaten stößt oder eine mehrdeutige Abfrage erhält, füllt es die Lücke mit etwas Plausiblem, anstatt zuzugeben, dass es nichts weiß. Die Architektur hat keinen Mechanismus für „Ich bin mir nicht sicher“ – sie wählt einfach das nächstwahrscheinlichste Wort.
Und das ist kein Fehler, der im nächsten Update behoben wird. Zwei unabhängige mathematische Beweise haben nun gezeigt, dass Halluzination eine fundamentale, nachweisbare Einschränkung der Architektur ist. Keine technische Unzulänglichkeit. Eine mathematische Gewissheit. (Mehr dazu im Abschnitt Mathematische Unmöglichkeit unten.) [20][21]
Das Benchmark-Problem – Warum sich die Zahlen widersprechen
Bevor Sie sich Halluzinationsdaten ansehen, müssen Sie verstehen, warum verschiedene Benchmarks für dasselbe Modell stark unterschiedliche Ergebnisse liefern.
Grok-3 erzielt 2,1 % im Vectara-Zusammenfassungs-Benchmark. Exzellent. Dasselbe Modell erzielt 94 % im Columbia Journalism Review Zitationsgenauigkeitstest. Katastrophal. Dasselbe Modell, derselbe Zeitraum, gegensätzliche Schlussfolgerungen.
Das ist kein Fehler. Es werden unterschiedliche Dinge gemessen. Und die Behandlung eines einzelnen Benchmarks als „die Halluzinationsrate“ wird Sie in die Irre führen.
Die folgende Matrix fasst zusammen, was jeder Benchmark tatsächlich testet. Klicken Sie auf einen Benchmark-Namen, um zum entsprechenden Abschnitt zu springen.
| Benchmark | Was es misst | Gut für | Nicht gut für |
| Vectara HHEM | Zusammenfassungsgenauigkeit – fügt das Modell beim Zusammenfassen von Quelldokumenten ungestützte Fakten hinzu? | RAG-Pipelines, Dokumenten-Q&A, Wissensdatenbanksuche | Offene Wissensfragen |
| AA-Omniscience | Wenn das Modell eine Antwort nicht kennt, gibt es dies zu oder erfindet es eine? Der Omniscience Index bestraft falsche Antworten und belohnt Ablehnung. | Hochriskante Beratungsarbeit – Recht, Medizin, Finanzen | Zusammenfassung oder geerdete Aufgaben |
| FACTS | Mehrdimensionale Faktizität über Grounding, Multimodalität, Parametrik und Suche. Jede Dimension wird separat bewertet. | Vergleich, wo Modelle bei verschiedenen Aufgabentypen stark und schwach sind | Erstellung einer einzelnen Halluzinationsrate |
| SimpleQA / PersonQA | Kurze Sachfragen und Genauigkeit über reale Personen. Neuere Reasoning-Modelle schneiden hier oft schlechter ab als Vorgänger. | Schnelle Faktizitätsprüfung bei einfachen Fragen | Komplexe, mehrstufige oder domänenspezifische Abfragen |
| HalluHard | Halluzinationsrate in realistischen Gesprächssituationen. Selbst das beste Modell halluziniert immer noch 30 % der Zeit. | Vorhersage realer Raten in Produktions-Chat-Anwendungen | Kontrollierte, reproduzierbare Modellvergleiche |
| CJR Citation | Ob KI-Modelle Informationen korrekt zitierten Quellen zuordnen. Fehlermodus: reale URLs mit erfundenem Inhalt. | Forschung, Journalismus, jede Aufgabe zur Quellenattribution | Allgemeinwissen oder Zusammenfassungsbewertung |
Quellen: Vectara HHEM [1], AA-Omniscience [2], FACTS [3], SimpleQA/PersonQA [4], HalluHard [5], CJR Citation Study [6]
Zwei Benchmarks, die ignoriert werden sollten
TruthfulQA war einst der Goldstandard. Es ist jetzt teilweise gesättigt – Modelle wurden auf seine Fragen trainiert. Schlimmer noch, Forscher zeigten, dass ein einfacher Entscheidungsbaum 79,6 % bei TruthfulQA Multiple Choice erreichen kann, ohne die gestellte Frage überhaupt zu sehen, nur indem er strukturelle Muster in der Antwortformatierung ausnutzt. Das Zitieren von TruthfulQA-Ergebnissen für Modelle von 2025-2026 ist unzuverlässig. [29]
HaluEval hat ein ähnliches Problem. Ein längenbasiertes Klassifizierungsmodell erreicht 93,3 % Genauigkeit bei HaluEval QA, indem es einfach Antworten, die länger als 27 Zeichen sind, als halluziniert kennzeichnet. Der Benchmark misst eher die Antwortlänge als die Wahrhaftigkeit. [30]
Die praktische Erkenntnis
Kein einzelner Benchmark liefert Ihnen „die Halluzinationsrate“ eines Modells. Wenn jemand eine Zahl zitiert, vereinfacht er entweder aus Bequemlichkeit oder wählt gezielt für Marketingzwecke aus.
Der verantwortungsvolle Ansatz: Vergleichen Sie mindestens zwei Benchmarks, die unterschiedliche Dinge messen (eine geerdete Aufgabe wie Vectara, eine offene Wissensaufgabe wie AA-Omniscience), geben Sie die genaue Modellversion und die Aufrufbedingungen an und beachten Sie, ob der Tool-Zugriff aktiviert war. Die folgenden Abschnitte tun genau das.
Vectara KI-Halluzinations-Bestenliste (HHEM)
Vectaras Bestenliste ist der meistzitierte Halluzinations-Benchmark in der Branche. Sie misst die Zusammenfassungsgenauigkeit – hält sich die Zusammenfassung des Modells, wenn ein Quelldokument gegeben wird, an das, was tatsächlich im Dokument steht, oder fügt es ungestützte Fakten hinzu? Dies macht es zu einem direkten Indikator dafür, wie sich KI in RAG-Pipelines, Unternehmenssuchtools und Dokumentenanalyse-Workflows verhält. Die Bestenliste existiert in zwei Versionen, und der Unterschied zwischen ihnen erzählt eine wichtige Geschichte. [1]
Originaldatensatz – ~1.000 Dokumente (April 2025)
Dies ist der Datensatz, auf den sich die meisten Artikel beziehen, wenn sie Halluzinationsraten zitieren. Die Dokumente sind relativ kurz und die Zusammenfassungsaufgaben sind unkompliziert.
| Modell | Anbieter | Halluzinationsrate | Faktische Konsistenz |
| Gemini-2.0-Flash-001 | 0.7% | 99.3% | |
| Gemini-2.0-Pro-Exp | 0.8% | 99.2% | |
| o3-mini-high | OpenAI | 0.8% | 99.2% |
| Gemini-2.5-Pro-Exp | 1.1% | 98.9% | |
| GPT-4.5-Preview | OpenAI | 1.2% | 98.8% |
| Gemini-2.5-Flash-Preview | 1.3% | 98.7% | |
| o1-mini | OpenAI | 1.4% | 98.6% |
| GPT-5 / ChatGPT-5 | OpenAI | 1.4% | 98.6% |
| GPT-4o | OpenAI | 1.5% | 98.5% |
| GPT-4o-mini | OpenAI | 1.7% | 98.3% |
| GPT-4-Turbo | OpenAI | 1.7% | 98.3% |
| GPT-4 | OpenAI | 1.8% | 98.2% |
| antgroup/finix_s1_32b | Ant Group | 1.8% | 98.2% |
| Grok-2 | xAI | 1.9% | 98.1% |
| GPT-4.1 | OpenAI | 2.0% | 98.0% |
| Grok-3-Beta | xAI | 2.1% | 97.8% |
| GPT-5.4-nano | OpenAI | 3.1% | 96.9% |
| Claude-3.7-Sonnet | Anthropic | 4.4% | 95.6% |
| Claude-3.5-Sonnet | Anthropic | 4.6% | 95.4% |
| o4-mini | OpenAI | 4.6% | 95.4% |
| Llama-4-Maverick | Meta | 4.6% | 95.4% |
| Grok-4 | xAI | 4.8% | ~95,2 % |
| Claude-3.5-Haiku | Anthropic | 4.9% | 95.1% |
| Gemma-4-26B | 5.2% | 94.8% | |
| DeepSeek-V3.2-Exp | DeepSeek | 5.3% | 94.7% |
| Qwen3-14B | Qwen/Alibaba | 5.4% | 94.6% |
| GPT-5.4-mini | OpenAI | 5.5% | 94.5% |
| Claude-3-Opus | Anthropic | 10.1% | 89.9% |
| DeepSeek-R1 | DeepSeek | 14.3% | 85.7% |
Quelle: Vectara HHEM Leaderboard, GitHub-Repository, Datensatz April 2025 (zuletzt aktualisiert am 20. April 2026 mit neuen Modellergänzungen, einschließlich Ant Groups finix_s1_32b, das mit 1,8 % führt) [1]
Bei diesem Datensatz sehen die Zahlen ermutigend aus. Googles Gemini-Modelle dominieren die ersten drei Plätze. OpenAIs GPT-Familie liegt zwischen 0,8 % und 2,0 %. Selbst die schlechtesten Performer bleiben unter 15 %.
Update April 2026: Ant Groups finix_s1_32b ist mit einer Halluzinationsrate von 1,8 % in die Bestenliste aufgenommen worden, das erste Mal, dass ein chinesisches Unternehmensmodell um die Spitzenposition im ursprünglichen Datensatz von Vectara konkurriert. OpenAIs GPT-5.4 nano (3,1 %) lag deutlich höher als GPT-4.1 (2,0 %), was das Muster bestätigt, dass kleinere, neuere OpenAI-Varianten oft mehr halluzinieren als ältere Basismodelle – konsistent mit der im Abschnitt 10 erörterten Reasoning-Steuer. [1]
Aber dieser Datensatz ist einfach. Die Dokumente sind kurz, die Zusammenfassungsaufgaben sind sauber, und die reale Welt ist weder das eine noch das andere.
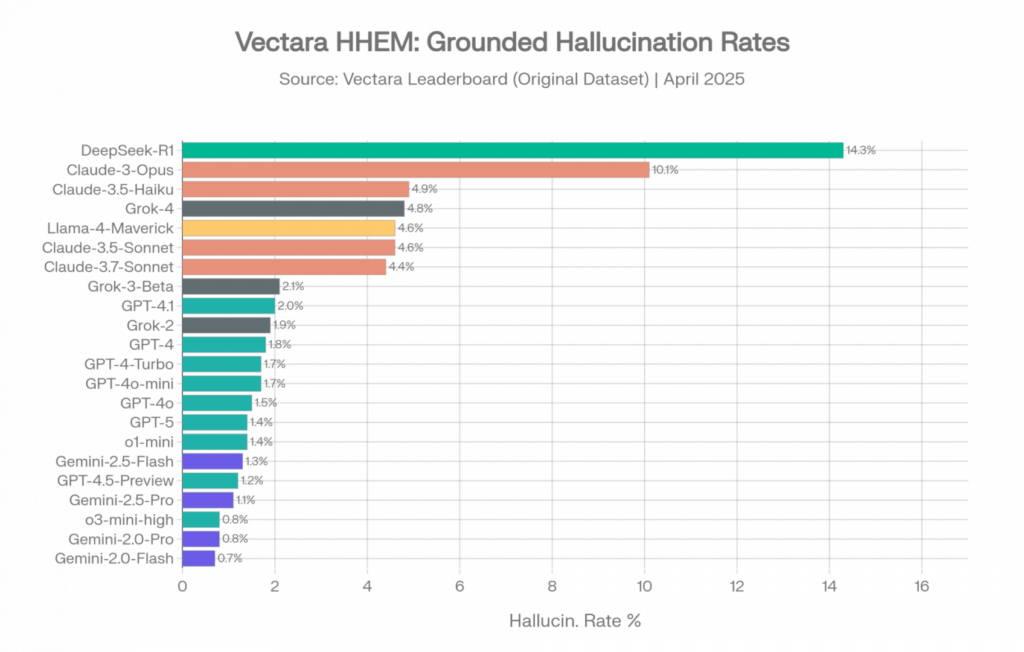
Vectara HHEM Leaderboard: Vollständiges Modellranking mit Anbieter-Farbcodierung im Originaldatensatz. Quelle: Vectara [1]
Neuer Datensatz – 7.700 Artikel (November 2025 – Februar 2026)
Vectara hat Ende 2025 einen aktualisierten Benchmark mit längeren Dokumenten (bis zu 32.000 Token) aus den Bereichen Recht, Medizin, Finanzen, Technologie und Bildung eingeführt. Diese Version spiegelt besser wider, womit Unternehmens-KI-Systeme tatsächlich konfrontiert sind.
Die Raten stiegen durchweg:
| Modell | Anbieter | Halluzinationsrate |
| Gemini-2.5-Flash-Lite | 3.3% | |
| Mistral-Large | Mistral | 4.5% |
| DeepSeek-V3.2-Exp | DeepSeek | 5.3% |
| GPT-4.1 | OpenAI | 5.6% |
| Grok-3 | xAI | 5.8% |
| DeepSeek-R1-0528 | DeepSeek | 7.7% |
| Claude Sonnet 4.5 | Anthropic | >10 % |
| GPT-5 | OpenAI | >10 % |
| Grok-4 | xAI | >10 % |
| Gemini-3-Pro | 13.6% |
Quelle: Vectara Hallucination Leaderboard, neuer Datensatz, November 2025 [1]
Momentaufnahme vom 25. Februar 2026 – Neueste Modellergänzungen
Die aktuellste Vectara-Momentaufnahme fügt die neuesten Frontier-Modelle zur Bewertung des neuen Datensatzes hinzu:
| Modell | Anbieter | Halluzinationsrate |
| o3-mini-high | OpenAI | 4.8% |
| GPT-4.1 | OpenAI | 5.6% |
| Grok-3 | xAI | 5.8% |
| DeepSeek-V3 | DeepSeek | 6.1% |
| Command R+ | Cohere | 6.9% |
| Gemini 2.5 Pro | 7.0% | |
| Llama 4 Scout | Meta | 7.7% |
| GPT-5.2-low | OpenAI | 8.4% |
| Gemini 3.1 Pro Preview | 10.4% | |
| Claude Sonnet 4.6 | Anthropic | 10.6% |
| GPT-5.2-high | OpenAI | 10.8% |
| DeepSeek-R1 | DeepSeek | 11.3% |
| Claude Opus 4.6 | Anthropic | 12.2% |
| Grok-4-fast-reasoning | xAI | 20.2% |
Quelle: Vectara HHEM Leaderboard, Forschungsbericht-Momentaufnahme vom 25. Februar 2026 [1]
Die Reasoning-Steuer
Der neue Datensatz enthüllte etwas Kontraintuitives: Reasoning-Modelle – die als die leistungsfähigsten vermarkteten – schneiden bei geerdeter Zusammenfassung durchweg schlechter ab. GPT-5, Claude Sonnet 4.5, Grok-4 und Gemini-3-Pro überschritten alle 10 %. Die Grok-4-fast-reasoning-Variante erreichte 20,2 %. [48][49]
Die Hypothese ist einfach. Reasoning-Modelle investieren Rechenaufwand in das „Durchdenken“ von Antworten. Bei der Zusammenfassung führt dieses Denken dazu, dass sie Inferenzen hinzufügen, Verbindungen herstellen und Erkenntnisse generieren, die über das im Quelldokument enthaltene hinausgehen. Das ist hilfreich für die Analyse. Es ist Halluzination bei einem Zusammenfassungs-Benchmark.
Dies schafft eine kritische Entscheidung für Unternehmensteams: Der Reasoning-Modus hilft bei offenen Aufgaben und schadet bei geerdeten Aufgaben. Zu wissen, wann er aktiviert und wann er deaktiviert werden muss, ist nicht optional.
AA-Omniscience Benchmark (Artificial Analysis)
AA-Omniscience stellt eine grundlegend andere Frage als Vectara. Anstatt „können Sie zusammenfassen, ohne etwas hinzuzufügen“, fragt es „wenn Sie etwas nicht wissen, geben Sie es zu oder erfinden Sie etwas?“ [2]
Der Benchmark umfasst 6.000 Fragen in 42 Themenbereichen in sechs Domänen. Der Omniscience Index (Skala: -100 bis +100) bestraft falsche Antworten und bestraft keine Ablehnung. Dies macht ihn zum einzigen großen Benchmark, der Modelle explizit dafür belohnt, ihre eigenen Grenzen zu kennen.
Top-Modelle nach Genauigkeit und Halluzinationsrate im Ranking
| Modell | Anbieter | Genauigkeit | Halluzinationsrate | Omniscience Index |
| Gemini 3 Pro Preview (hoch) | 55.9% | 88% | 16 | |
| Gemini 3.1 Pro Preview | 55.3% | 50% | 33 | |
| Gemini 3 Flash (Reasoning) | 54.0% | 92% | – | |
| GPT-5.5 (sehr hoch) | OpenAI | 57% | 86% | 20 |
| GPT-5.3 Codex (sehr hoch) | OpenAI | 51.8% | – | – |
| Claude Opus 4.6 (max) | Anthropic | 46.4% | – | 14 |
| Claude Opus 4.7 (Adaptive Reasoning, Max) | Anthropic | ~47 % | 36% | 26 |
| Claude Opus 4.5 (denkend) | Anthropic | 45.7% | 58% | Negativ |
| GPT-5.2 (sehr hoch) | OpenAI | 43.8% | – | – |
| Grok 4 | xAI | 41.4% | 64% | Positiv |
| Claude Opus 4.5 | Anthropic | 40.7% | – | – |
| GPT-5 (hoch) | OpenAI | 40.7% | – | – |
| Claude Sonnet 4.6 (max) | Anthropic | 40.0% | – | – |
| Claude Sonnet 4.6 | Anthropic | 38.0% | ~38 % | – |
| GPT-5.1 (hoch) | OpenAI | 37.6% | 81% | Positiv |
Quelle: Artificial Analysis AA-Omniscience, November 2025 – April 2026 [2]
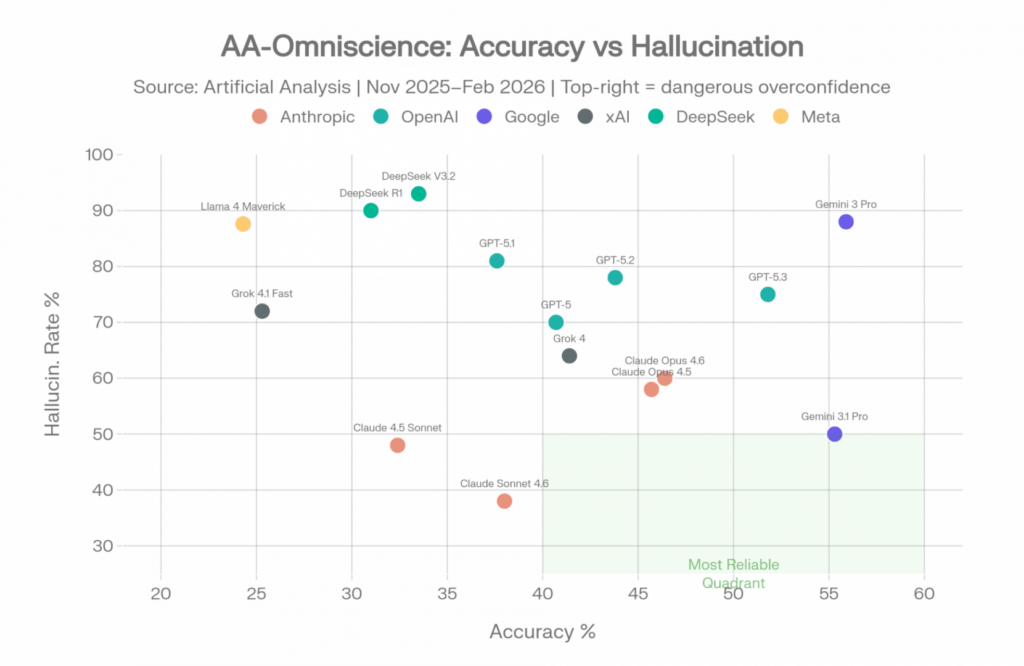
AA-Omniscience: Genauigkeit vs. Halluzinationsrate. Der grüne Quadrant zeigt zuverlässige Modelle. Quelle: Artificial Analysis [2]
Niedrigste Halluzinationsraten
| Modell | Anbieter | Halluzinationsrate |
| Claude 4.1 Opus (Reasoning) | Anthropic | 0%* |
| Claude 4 Opus (Reasoning) | Anthropic | 0%* |
| Grok 4.20 (Reasoning) | xAI | 17% |
| MiMo-V2.5-Pro | Xiaomi | 25% |
| Claude 4.5 Haiku | Anthropic | 25% |
| Claude Sonnet 4.6 | Anthropic | ~38 % |
| Claude 4.5 Sonnet | Anthropic | 48% |
| Gemini 3.1 Pro Preview | 50% | |
| Claude Opus 4.5 | Anthropic | 58% |
| Grok 4 | xAI | 64% |
| Grok 4.1 Fast | xAI | 72% |
| DeepSeek R1 0528 | DeepSeek | 83% |
| Llama 4 Maverick | Meta | 87.6% |
| Gemini 3 Pro Preview | 88% |
Hinweis: Die Halluzinationsrate in AA-Omniscience misst, wie oft das Modell falsch antwortet, wenn es hätte ablehnen sollen – der Anteil falscher Antworten an allen nicht-korrekten Antworten. Dies ist eine Metrik für übermäßiges Vertrauen. *Sternchen: Claude 4.1 Opus erreicht 0 %, indem es alle unsicheren Fragen ablehnt – es produziert weniger Halluzinationen, indem es weniger Fragen beantwortet. Grok 4.20 (Reasoning) erreicht 17 %, während es einen höheren Anteil an Antworten versucht (April 2026). Die optimale Strategie hängt davon ab, ob die Ablehnung einer Antwort oder falsche Antworten für den Anwendungsfall kostspieliger sind. Quelle: Artificial Analysis AA-Omniscience [2]
Das Gemini 3 Pro Paradoxon
Gemini 3 Pro erzählt die interessanteste Geschichte in diesen Daten. Es erreichte mit großem Abstand die höchste Genauigkeit (55,9 %) – es weiß mehr als jedes andere getestete Modell. Aber es zeigte auch eine Halluzinationsrate von 88 %. Wenn es eine Antwort nicht kennt, erfindet es diese zu 88 % der Zeit, anstatt Unsicherheit zuzugeben. [2]
Hohes Wissen + geringes Selbstbewusstsein = ein Modell, das brillant ist, wenn es richtig liegt, und gefährlich, wenn es falsch liegt.
Das Gemini 3.1 Pro Update hat dies teilweise behoben. Googles Kalibrierungsabstimmung senkte die Halluzinationsrate von 88 % auf 50 %, während die Genauigkeit nahezu identisch blieb (55,3 % vs. 55,9 %). Der Omniscience Index sprang von 16 auf 33 – der höchste aller Modelle. Dies bewies, dass eine drastische Reduzierung der Halluzinationen ohne nennenswerten Genauigkeitsverlust möglich ist. [15]
Der GPT-5.5 Datenpunkt (April 2026)
GPT-5.5, von OpenAI Anfang 2026 veröffentlicht, weist mit 57 % die höchste jemals auf AA-Omniscience gemessene Genauigkeit auf. Es weist auch eine Halluzinationsrate von 86 % auf demselben Benchmark auf – die extremste Genauigkeits-vs-Kalibrierungs-Lücke, die bisher beobachtet wurde. Wenn GPT-5.5 eine Antwort nicht kennt, erfindet es diese zu 86 % der Zeit. Das Gemini 3 Pro Muster (Wissen ohne Selbstbewusstsein) scheint sich mit der neuesten Generation hochleistungsfähiger Modelle intensiviert zu haben. [2][63]
Claude Opus 4.7, von Anthropic am 16. April 2026 veröffentlicht, geht den entgegengesetzten Kompromiss ein: 36 % Halluzinationsrate auf demselben Benchmark, mit etwas geringerer Rohgenauigkeit. Die beiden Veröffentlichungsentscheidungen, sechs Wochen auseinander, stellen die bisher klarste Trennung zwischen der Optimierung dessen, was ein Modell weiß, und dem, was ein Modell über seine eigenen Grenzen weiß, dar. [58][63]
Domänenspezifische Leader
Kein einzelnes Modell dominiert alle Wissensbereiche:
| Domäne | Bestes Modell |
| Recht | Claude 4.1 Opus |
| Softwareentwicklung | Claude 4.1 Opus |
| Geistes- & Sozialwissenschaften | Claude 4.1 Opus |
| Wirtschaft | GPT-5.1.1 |
| Gesundheit | Grok 4 |
| Wissenschaft & Mathematik | Grok 4 |
Quelle: Artificial Analysis AA-Omniscience [2]
Claude-Modelle führen in Domänen, in denen präzises Reasoning und Zitationsgenauigkeit wichtig sind. Grok führt in Domänen, in denen eine breite Wissensabdeckung wichtig ist. GPT führt in Geschäftsanwendungen. Diese Fragmentierung ist selbst ein Datum – sie bedeutet, dass kein einzelnes Modell die sicherste Wahl für jeden professionellen Anwendungsfall ist.
Eine Statistik, die wichtiger ist als der Rest
Genauigkeit korreliert mit der Modellgröße. Halluzinationsrate nicht.
Größere Modelle wissen mehr, aber sie wissen nicht unbedingt, was sie nicht wissen.
Mehr Parameter in das Problem zu werfen, erhöht das Wissen, ohne das Selbstbewusstsein zu erhöhen. Deshalb wird das Halluzinationsproblem mit der nächsten Modellgeneration nicht einfach verschwinden.
FACTS Benchmark (Google DeepMind)
Googles DeepMind FACTS Benchmark, veröffentlicht im Dezember 2025, verfolgt einen anderen Ansatz als die meisten Evaluierungen: Anstatt einen Halluzinationswert zu produzieren, unterteilt er die Faktizität in vier verschiedene Dimensionen. Diese mehrdimensionale Ansicht zeigt, dass Modelle je nach Aufgabentyp dramatisch unterschiedliche Stärken aufweisen. Grok 4 erzielt 75,3 bei der Suche, aber nur 25,7 bei Multimodalität – eine 50-Punkte-Lücke innerhalb desselben Modells. [3]
Was die vier Bereiche messen
Grounding: Kann das Modell Informationen aus bereitgestellten Dokumenten treu verwenden? Getestet durch Zusammenfassungs- und Extraktionsaufgaben mit Quellmaterial.
Multimodal: Kann das Modell visuelle Inhalte zusammen mit Text genau beschreiben und darüber nachdenken?
Parametrisch: Liefert das interne Wissen des Modells (gespeichert in seinen Gewichten aus dem Training) korrekte Antworten ohne externe Tools?
Suche: Wie genau ist das Modell, wenn es Zugriff auf Websuche und Abruftools hat?
Modellwerte über alle vier Bereiche
| Modell | Gesamt | Grounding | Multimodal | Parametrisch | Suche |
| Gemini 3 Pro | 68.8 | 69.0 | 46.1 | 76.4 | 83.8 |
| Gemini 2.5 Pro | 62.1 | – | – | – | – |
| GPT-5 | 61.8 | – | – | – | 77.7 |
| Grok 4 | 53.6 | – | – | – | 75.3 |
| GPT o3 | 52.0 | 36.2 | – | 57.1 | – |
| Claude 4.5 Opus | 51.3 | – | – | – | – |
| GPT 4.1 | 50.5 | – | – | – | – |
| Gemini 2.5 Flash | 50.4 | – | – | – | – |
| GPT 5.1 | 49.4 | – | – | – | – |
| Claude 4.5 Sonnet Thinking | 49.1 | – | – | – | – |
| Claude 4.1 Opus | 46.5 | – | – | – | – |
| GPT 5 mini | 45.9 | – | – | – | – |
| Claude 4 Sonnet | 42.8 | – | – | – | – |
| GPT o4 mini | 37.6 | – | – | – | – |
| Grok 4 Fast | 36.0 | – | – | – | – |
Hinweis: Bindestriche zeigen an, dass die Werte auf Bereichsebene in veröffentlichten Quellen nicht separat ausgewiesen wurden. Der Gesamt-FACTS-Wert ist ein Aggregat über alle vier Bereiche. Quelle: FACTS Benchmark Suite, Dezember 2025 [3]
Was diese Daten offenbaren
Kein Modell überschreitet 70 %. Der beste Wert bei FACTS ist Gemini 3 Pros 68,8. Jedes Modell liegt bei dieser mehrdimensionalen Faktizitätsbewertung zu mehr als 30 % falsch.
Die Suche ist für alle der stärkste Bereich. Gemini 3 Pro erreicht 83,8 und GPT-5 erreicht 77,7 bei der suchgestützten Faktizität. Wenn Modelle Dinge nachschlagen können, sind sie wesentlich genauer. Wenn sie sich allein auf gespeichertes Wissen verlassen, sinkt die Genauigkeit. Dies stimmt mit den Ergebnissen von OpenAIs Systemkarten zum Browsen mit und ohne überein.
Grok 4 weist eine interne Lücke von 50 Punkten auf. Es erzielt 75,3 Punkte bei der Suche, aber 25,7 Punkte bei Multimodalität – eine massive Inkonsistenz, die bedeutet, dass es Fakten gut finden kann, aber Schwierigkeiten mit visuellen Inhalten hat. Jede Bewertung, die diese zu einem einzigen Wert mittelt, verschleiert diese Lücke.
Die Verbesserung von Gemini 3 Pro ist real. Im Vergleich zu Gemini 2.5 Pro reduzierte Gemini 3 Pro die Fehlerraten um 55 % im Suchbereich und um 35 % im parametrischen Bereich. Das ist eine große Verbesserung der faktischen Genauigkeit von Generation zu Generation, die hauptsächlich durch bessere Such- und Grounding-Fähigkeiten angetrieben wird.
Halluzinationsprofile von Frontier-Modellen
Jedes Modell unten wird über mehrere Benchmarks hinweg profiliert. Einzel-Benchmark-Vergleiche führen in die Irre – die Profile zeigen, wo jedes Modell zuverlässig ist und wo nicht.
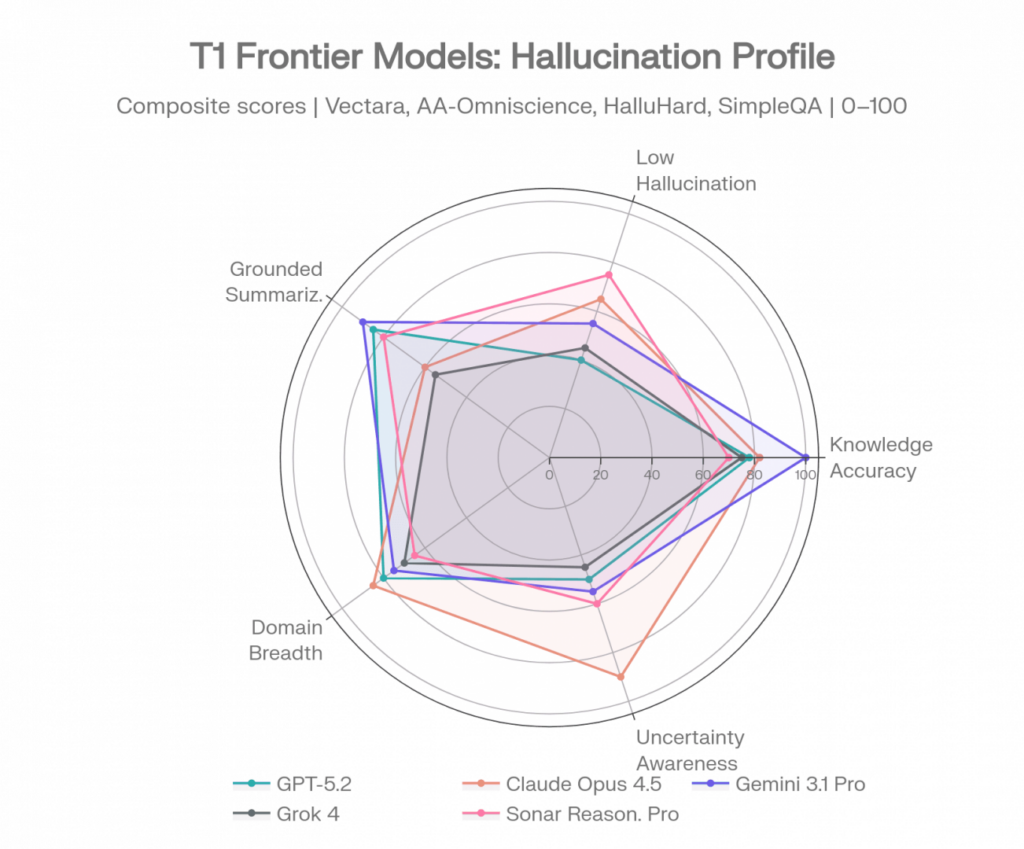
Frontier-Modellprofile über 5 Halluzinationsdimensionen. Quellen: Vectara [1], AA-Omniscience [2], FACTS [3], SimpleQA [4]
GPT-5 Familie (OpenAI)
GPT-5.3 Instant (März 2026) – OpenAIs neuestes. Reduziert Halluzinationen um 26,8 % mit Websuche und um 19,7 % ohne, im Vergleich zu früheren Modellen. [10]
GPT-5.2 (Dezember 2025) – Das professionelle Arbeitspferd. AA-Omniscience-Genauigkeit: 43,8 %. Mit Websuche: 93,9 % fehlerfreie Antworten. Ohne: Fehlerrate steigt auf 12 %. HalluHard: 38,2 % mit Web. FACTS gesamt: 61,8. [9]
GPT-5 (August 2025) – Vectara alter Datensatz: 1,4 % (stark). Vectara neuer Datensatz: >10 % (schwach). HealthBench Denkmodus: 1,6 % – einer der besten medizinischen Halluzinationswerte, die je aufgezeichnet wurden. SimpleQA ohne Web: 47 %. Mit Web: 9,6 %. FACTS gesamt: 61,8. [8][12]
Das Muster in der GPT-5-Familie: Der Webzugriff ist die größte Einzelvariable. Mit aktiviertem Browsing konkurrieren GPT-5-Modelle um die niedrigsten Halluzinationsraten in der Branche. Ohne ihn steigen die Raten um das 3- bis 5-fache. Wenn Sie eine GPT-5-Variante einsetzen, lassen Sie den Webzugriff aktiviert.
Claude Familie (Anthropic)
Claude 4.1 Opus – AA-Omniscience Halluzinationsrate: 0 %. Die absolut niedrigste aller getesteten Modelle. Erreicht dies durch Ablehnung einer Antwort bei Unsicherheit. FACTS: 46,5. Domänenführer in Recht, Softwareentwicklung und Geisteswissenschaften. [2]
Claude Opus 4.6 (Februar 2026) – AA-Omniscience Genauigkeit: 46,4 %, Index: 14. Vectara neuer Datensatz (Momentaufnahme Feb 2026): 12,2 %. Dritthöchster Nicht-Gemini Omniscience Index. [14][2]
Claude Opus 4.5 (November 2025) – AA-Omniscience Halluzination: 58 %, Genauigkeit: 45,7 %. HalluHard: 30 % mit Websuche (niedrigster Wert aller getesteten Modelle), 60 % ohne. FACTS: 51,3. [5]
Claude Sonnet 4.6 (Februar 2026) – AA-Omniscience Halluzination: ~38 %, gegenüber 48 % bei Sonnet 4.5. Benutzer bevorzugten Sonnet 4.6 gegenüber Opus 4.5 zu 59 % der Zeit, unter Berufung auf weniger Halluzinationen. Vectara neuer Datensatz: 10,6 %. [13][50]
Claude Opus 4.7 (16. April 2026) – AA-Omniscience Index: 26 (zweithöchster insgesamt, nur hinter Gemini 3.1 Pros 33). Halluzinationsrate: 36 % – das stärkste Kalibrierungsprofil aller Frontier-Modelle, die Fragen in großem Maßstab beantworten, und 50 Prozentpunkte besser als GPT-5.5 auf demselben Benchmark. BenchLM gesamt: 87. Die Langkontext-Retrieval sank auf 32,2 % (von Opus 4.6s 78,3 %) – Anthropic führt dies explizit darauf zurück, dass das Modell nun Fehler meldet, wenn Informationen fehlen, anstatt eine Antwort zu erfinden. Die Ablehnungsstrategie wurde messbar. [58][63]
Das Muster bei Claude: Anthropic-Modelle sind darauf kalibriert, abzulehnen, anstatt zu raten. Dies führt zu den niedrigsten Halluzinationsraten bei Wissens-Benchmarks (AA-Omniscience), aber zu einer geringeren Rohgenauigkeit im Vergleich zu Gemini. Für Anwendungen, bei denen eine falsche Antwort schlimmer ist als keine Antwort – Rechtsforschung, medizinische Beratung, Compliance-Arbeit – ist Claudes Ansatz strukturell sicherer.
Gemini Familie (Google)
Gemini 3.1 Pro Preview (Februar 2026) – AA-Omniscience Index: 33 (höchster aller Modelle). Genauigkeit: 55,3 %. Halluzinationsrate: 50 %, gegenüber 88 % bei Gemini 3 Pro. Dies war die größte Einzel-Update-Halluzinationsverbesserung in den Jahren 2025-2026. Vectara neuer Datensatz: 10,4 %. [15]
Gemini 3 Pro – FACTS gesamt: 68,8 (höchster aller Modelle). FACTS Suche: 83,8. FACTS Parametrisch: 76,4. AA-Omniscience Genauigkeit: 55,9 % (höchste) mit 88 % Halluzination. Das Gemini-Paradoxon: am kenntnisreichsten, am wenigsten selbstbewusst. [3]
Gemini 3 Flash (Dezember 2025) – AA-Omniscience Genauigkeit: 54,0 % (höchste aller Modelle bei Markteinführung). Halluzinationsrate: 91 %. Geschwindigkeit: 218 Token/s. Die extremste Version des Gemini-Paradoxons – brillant und unzuverlässig gleichermaßen. Nur für Aufgaben mit externer Verifizierung geeignet. [16]
Googles Modelle wissen am meisten, geben aber am wenigsten zu.
Das Muster bei Gemini: Gemini-Modelle versuchen jede Frage zu beantworten, was ihnen zwar Spitzenwerte bei der Genauigkeit beschert, aber zu katastrophalen Halluzinationsraten führt, wenn sie an die Grenzen ihres Wissens stoßen. Das 3.1 Pro-Update zeigte, dass dies durch Kalibrierungs-Tuning behebbar ist – die Halluzinationen sanken um 38 Prozentpunkte bei nur 1 % Genauigkeitsverlust.
Grok-Familie (xAI)
Grok 4 – Vectara alter Datensatz: 4,8 %. AA-Omniscience: 41,4 % Genauigkeit, 64 % Halluzination, positiver Index. FACTS: 53,6 (Suche: 75,3, Multimodal: 25,7). Domain-Führer in Gesundheit und Wissenschaft auf AA-Omniscience. [2]
Grok 4.1 Fast – xAI behauptet eine Reduzierung der Halluzinationen um 65 % (von 12,09 % auf 4,22 % in internen Benchmarks). AA-Omniscience erzählt eine andere Geschichte: 72 % Halluzinationsrate, schlechter als die 64 % von Grok 4. Auch die Sykophantie nahm zu (MASK-Benchmark: 0,07 auf 0,19–0,23). [17]
Grok-3 – Columbia Journalism Review: 94 % Halluzinationsrate bei Zitaten. Mit Abstand der schlechteste Wert in diesem Benchmark. [6]
Das Muster bei Grok: Interne Benchmarks und unabhängige Benchmarks widersprechen sich deutlich. xAI meldet Verbesserungen; AA-Omniscience zeigt Rückschritte. Die 94 % CJR-Zitathalluzinationsrate stammt nicht von einem älteren Modell – Grok-3 wurde im März 2025 getestet. Fachspezifischer Nutzen existiert in den Bereichen Gesundheit und Wissenschaft, aber die Inkonsistenz über Benchmarks hinweg macht Grok als alleiniges Modell für Anwendungen mit hohem Risiko riskant.
Perplexity Sonar (Perplexity AI)
Sonar Reasoning Pro – Search Arena Score: 1136, statistisch gleichauf mit Gemini 2.5 Pro auf Platz 1. SimpleQA F-Score: 0,858, der höchste aller Modelle zum Zeitpunkt des Tests. CJR-Zitatgenauigkeit: 37 % Halluzination (bestes Testergebnis). Antwortgenauigkeit: >90 % bei faktischen Abfragen (94 % insgesamt, 95 % akademisch, 94 % technisch). [18][19]
Sonar Pro – Basiert auf Llama 3.3 70B, feinabgestimmt auf Faktenreue in der Suche. SimpleQA F-Score: 0,858. Übertrifft GPT-4o und Claude 3.5 Sonnet in Benchmarks zur Faktenreue. [19]
Das Perplexity-Risiko: Perplexity führt einen Fehlermodus ein, den kein anderes Modell teilt. Es zitiert echte URLs mit erfundenen Behauptungen. Die Quellen sehen legitim aus – echte Websites, echte Publikationsnamen – aber die diesen Quellen zugeschriebenen Informationen können erfunden sein. Dies macht Perplexity-Halluzinationen schwerer erkennbar als Halluzinationen von Modellen, die keine externen Zitate angeben. Eine Zitathalluzinationsrate von 37 % bedeutet, dass mehr als jede dritte Quellenangabe erfundene Inhalte enthalten kann. [51]
DeepSeek (DeepSeek AI)
DeepSeek-V3 – Vectara alter Datensatz: 3,9 %. Ein starker Performer bei fundierter Zusammenfassung.
DeepSeek-R1 – Vectara alter Datensatz: 14,3 %, fast viermal höher als bei V3. AA-Omniscience Halluzination: 83 %. Die Vectara-Analyse ergab, dass R1 71,7 % „gutartige Halluzinationen“ (plausibel klingende Ergänzungen) produziert, verglichen mit 36,8 % bei V3. [49][48]
Das Muster: Das Reasoning-Modell von DeepSeek (R1) halluziniert dramatisch mehr als sein Basismodell (V3). Dies ist die „Reasoning-Steuer“ in ihrer extremsten Form. Die Lücke (3,9 % gegenüber 14,3 %) macht es zu einem der klarsten Beispiele dafür, dass Reasoning-Fähigkeiten und faktische Zuverlässigkeit sich nicht in die gleiche Richtung bewegen.
Open-Source-Modelle
Llama 4 Maverick (Meta) – Vectara alter Datensatz: 4,6 % (wettbewerbsfähig). AA-Omniscience Halluzination: 87,6 % (katastrophal). Die Lücke zwischen fundierter Zusammenfassung und offenem Wissen ist bei Open-Source-Modellen größer als bei jeder proprietären Familie. [2]
Open-Source-Modelle überschritten in MedRxiv-Tests in medizinischen Szenarien Halluzinationsraten von 80 %. Für kritische Anwendungen bleibt die Halluzinationslücke zwischen Open-Source- und proprietären Frontier-Modellen groß. [40]
Direkte Modellvergleiche
Die Modellprofile in Abschnitt 6 zeigen die individuelle Leistung. Dieser Abschnitt beantwortet die Fragen, nach denen Menschen tatsächlich suchen: „Ist Claude oder GPT genauer?“ „Sollte ich Gemini oder Claude verwenden?“ Die Antwort lautet immer „es kommt darauf an, was Sie tun“ – aber die Daten machen die Kompromisse konkret.
Heatmap für den direkten Vergleich: Welcher Anbieter gewinnt bei welchem Benchmark. Grün = Gewinner, Gelb = Gleichstand, Rot = Verlierer.
Claude vs. GPT
Der meistgesuchte Vergleich in der KI und der am stärksten kontextabhängige.
| Benchmark | Claude | GPT | Gewinner |
| Vectara (alter Datensatz) | 4,4 % (Sonnet 3.7) | 1,4 % (GPT-5) | GPT |
| Vectara (neuer Datensatz, Feb. 2026) | 10,6 % (Sonnet 4.6) | 10,8 % (GPT-5.2-high) | Gleichstand |
| AA-Omniscience Halluzination | 0 % (Claude 4.1 Opus) | ~78 % (GPT-5.2) | Claude |
| AA-Omniscience Genauigkeit | 46,4 % (Opus 4.6) | 43,8 % (GPT-5.2) | Claude (leicht) |
| FACTS Gesamt | 51,3 (Opus 4.5) | 61,8 (GPT-5) | GPT |
| HealthBench | – | 1,6 % (GPT-5 Thinking) | GPT |
| HalluHard (mit Web) | 30 % (Opus 4.5) | 38,2 % (GPT-5.2) | Claude |
Quellen: HealthBench [52], HalluHard [5], FACTS [3], Vectara [1], AA-Omniscience [2]
Das Muster ist nicht „eines ist besser“. Es sind zwei verschiedene Philosophien, die auf unterschiedlichen Skalen gemessen werden.
GPT-Modelle sind stärker, wenn die Aufgabe auf Quellmaterial basiert. Zusammenfassung, Dokumentenanalyse, RAG-Workflows, suchbasierte Q&A – GPT hält sich enger an den bereitgestellten Text und schneidet bei Faithfulness-Benchmarks gut ab. Der FACTS-Vorteil (61,8 gegenüber 51,3) spiegelt dies wider: GPT-5 bewältigt Grounding- und Suchaufgaben mit höherer Genauigkeit.
Claude-Modelle sind stärker, wenn die Aufgabe erfordert, dass das Modell seine eigenen Grenzen kennt. Auf AA-Omniscience erreichte Claude 4.1 Opus eine Halluzinationsrate von 0 %, indem es sich weigerte, Fragen zu beantworten, die es nicht verifizieren konnte. Die Halluzinationsrate von Claude Sonnet 4.6 von ~38 % ist weniger als halb so hoch wie die von GPT-5.2 (~78 %) im selben Benchmark. Im realistischen Konversationstest von HalluHard erreichte Claude Opus 4.5 mit Websuche 30 % – der niedrigste Wert aller getesteten Modelle.
Die praktische Aufteilung: Verwenden Sie GPT für dokumentenbasierte Workflows, bei denen das Quellmaterial verfügbar und vollständig ist. Verwenden Sie Claude für beratende Workflows, bei denen das Modell auf sein eigenes Wissen zurückgreifen und Unsicherheiten kennzeichnen muss. Dies ist keine Markenpräferenz – es ist das, was die Benchmark-Daten stützen.
Eine weitere Variable, die oft übersehen wird: Der Zugriff auf die Websuche verändert die Leistung von GPT dramatisch. GPT-5 fällt von 47 % Halluzination auf 9,6 % mit Browsing. Ohne Webzugriff verschiebt sich der Claude-GPT-Vergleich bei offenen faktischen Aufgaben zugunsten von Claude. Mit Webzugriff zieht GPT vorbei.
Claude vs. Gemini
| Benchmark | Claude | Gemini | Gewinner |
| AA-Omniscience Index | 14 (Opus 4.6) | 33 (3.1 Pro) | Gemini |
| AA-Omniscience Genauigkeit | 46,4 % (Opus 4.6) | 55,3 % (3.1 Pro) | Gemini |
| AA-Omniscience Halluzination | 0 % (Claude 4.1 Opus) | 50 % (3.1 Pro) | Claude |
| FACTS Gesamt | 51,3 (Opus 4.5) | 68,8 (3 Pro) | Gemini |
| Vectara (alter Datensatz) | 4,4 % (Sonnet 3.7) | 0,7 % (2.0-Flash) | Gemini |
| Vectara (neuer Datensatz, Feb. 2026) | 10,6 % (Sonnet 4.6) | 10,4 % (3.1 Pro) | Gleichstand |
| HalluHard (mit Web) | 30 % (Opus 4.5) | – | Claude |
Quellen: HalluHard [5], FACTS [3], Vectara [1], AA-Omniscience [2]
Gemini weiß mehr. Claude ist ehrlicher darüber, was es nicht weiß.
Gemini 3.1 Pro führt bei fast jeder Genauigkeitsmetrik. Es erzielt die höchsten Werte bei FACTS (68,8), die höchste AA-Omniscience-Genauigkeit (55,3 %) und hält den höchsten Omniscience-Index (33). Wenn Gemini die Antwort hat, liefert es sie häufiger als Claude.
Das Problem ist, wenn es die Antwort nicht hat. Selbst nach dem 3.1-Kalibrierungs-Update, das die Halluzinationen von 88 % auf 50 % senkte, erfindet Gemini immer noch in der Hälfte der Fälle eine Antwort, wenn es eigentlich „Ich weiß es nicht“ sagen sollte. Claude 4.1 Opus erfindet in diesem Szenario in 0 % der Fälle etwas.
Die praktische Aufteilung: Gemini für Aufgaben mit breitem Wissensspektrum, bei denen eine externe Verifizierung existiert – Forschung, vergleichende Analyse, Informationsbeschaffung. Claude für Aufgaben mit hohem Vertrauensanspruch, bei denen eine erfundene Antwort Konsequenzen hat – Compliance-Prüfungen, Rechtsrecherche, medizinische Beratung. Wenn Sie die Arbeit von Gemini überprüfen können, verwenden Sie Gemini. Wenn nicht, verwenden Sie Claude.
GPT vs. Gemini
| Benchmark | GPT | Gemini | Gewinner |
| Vectara (alter Datensatz) | 0,8 % (o3-mini) | 0,7 % (2.0-Flash) | Gleichstand |
| Vectara (neuer Datensatz) | 5,6 % (GPT-4.1) | 3,3 % (2.5-Flash-Lite) | Gemini |
| FACTS Gesamt | 61,8 (GPT-5) | 68,8 (3 Pro) | Gemini |
| FACTS Suche | 77,7 (GPT-5) | 83,8 (3 Pro) | Gemini |
| AA-Omniscience Genauigkeit | 43,8 % (GPT-5.2) | 55,3 % (3.1 Pro) | Gemini |
| HealthBench | 1,6 % (GPT-5 Thinking) | – | GPT |
Quellen: FACTS [3], Vectara [1], AA-Omniscience [2]
Gemini führt bei den meisten Benchmarks. Der Vorteil von GPT ist aufgabenspezifisch: medizinische Anwendungen (1,6 % HealthBench), Genauigkeit auf Behauptungsebene in der Produktion mit Thinking-Modus (4,5 % fehlerhafte Behauptungen) und die schiere Menge an internen Evaluierungsdaten, die OpenAI veröffentlicht.
Die praktische Aufteilung: Beide sind stark mit Tool-Zugriff. Ohne diesen verleiht Gemini sein höheres parametrisches Wissen (FACTS Parametric: 76,4) einen Vorteil bei Aufgaben mit gespeichertem Wissen. Der Thinking-Modus von GPT bietet einen spezifischen Vorteil für medizinische und gesundheitsbezogene Abfragen, bei denen Reasoning die Halluzinationen dramatisch reduziert.
Grok vs. das Feld
| Benchmark | Grok | Feld-Durchschnitt |
| xAI interne Faktenreue | 4,22 % (Grok 4.1) | – |
| AA-Omniscience | 64 % Halluzination (Grok 4) | ~60 % Durchschnitt |
| AA-Omniscience (Fast-Variante) | 72 % Halluzination (Grok 4.1 Fast) | Schlechter als Basis |
| FACTS Gesamt | 53,6 (Grok 4) | ~52 Durchschnitt |
| FACTS Suche | 75,3 (Grok 4) | Wettbewerbsfähig |
| FACTS Multimodal | 25,7 (Grok 4) | Weit unter Durchschnitt |
| CJR-Zitat | 94 % Halluzination (Grok-3) | Schlechtestes Testergebnis |
| Vectara (neuer Datensatz) | 20,2 % (Grok-4-fast) | Schlechtestes Testergebnis |
Quellen: Grok 4.1 [17], CJR [6], FACTS [3], AA-Omniscience [2]
xAI berichtet von einer 65%igen Reduzierung der Halluzinationen von Grok 4 auf 4.1 in internen Tests. AA-Omniscience zeigt das Gegenteil: Grok 4.1 Fast halluziniert zu 72 % gegenüber 64 % bei Grok 4. Die CJR-Zitatstudie ergab, dass Grok-3 in 94 % der Fälle bei der Angabe von Nachrichtenquellen halluzinierte.
Grok hat durchaus echte Stärken in bestimmten Bereichen – es führt in den Kategorien Gesundheit und Wissenschaft auf AA-Omniscience. Aber die Lücke zwischen den Behauptungen von xAI und unabhängigen Messungen ist größer als bei jedem anderen Anbieter.
Das praktische Fazit: Verwenden Sie Grok nicht als alleiniges Modell für Entscheidungen mit hohem Risiko. Sein Wert liegt darin, eine Stimme in einer Multi-Modell-Evaluierung zu sein, bei der seine Fachstärken (Gesundheit, Wissenschaft) beitragen können, während seine Inkonsistenzen von anderen Modellen abgefangen werden.
Perplexity vs. ChatGPT vs. Claude
| Benchmark | Perplexity | ChatGPT | Claude |
| CJR-Zitatgenauigkeit | 37 % Halluzination | 67 % Halluzination | – |
| SimpleQA F-Score | 0,858 (bestes) | 0,38 (GPT-4o) | 0,35 (Sonnet 3.5) |
| Search Arena Ranking | #1 (Gleichstand) | – | – |
| Antwortgenauigkeit | >90 % faktisch | – | – |
Quellen: Perplexity Sonar [18][19], CJR [6]
Perplexity gewinnt bei faktischen Suchanfragen. Seine RAG-native Architektur, die eher auf Retrieval als auf parametrischem Wissen basiert, verschafft ihm einen strukturellen Vorteil bei Fragen mit verifizierbaren Antworten.
Der Haken: Perplexity zitiert echte URLs mit erfundenen Behauptungen. Die Quellen sehen legitim aus – echte Websites, echte Publikationsnamen – aber die diesen Quellen zugeschriebenen Informationen können erfunden sein. Bei einer Zitathalluzinationsrate von 37 % könnte mehr als jede dritte Quellenangabe erfundene Inhalte enthalten. Dies macht Perplexity-Halluzinationen schwerer erkennbar als Halluzinationen von Modellen, die keine externen Zitate angeben.
Die praktische Aufteilung: Perplexity für die erste Recherche und Faktenfindung, bei der Sie wichtige Behauptungen selbst verifizieren. Nicht für Szenarien mit endgültigen Antworten, in denen jemand die zitierte Quelle liest und davon ausgeht, dass die Zuschreibung korrekt ist.
Fachspezifische Halluzinationsraten
Die Halluzinationsraten variieren je nach Themenbereich dramatisch. Ein Modell, das bei Allgemeinwissen genau ist, kann bei Rechtsfragen gefährlich falsch liegen. Diese Tabelle zeigt die Verteilung über acht Wissensbereiche:
Raten nach Bereich
| Wissensbereich | Top-Modelle | Durchschnitt aller Modelle |
| Allgemeinwissen | 0.8% | 9.2% |
| Historische Fakten | 1.7% | 11.3% |
| Finanzdaten | 2.1% | 13.8% |
| Technische Dokumentation | 2.9% | 12.4% |
| Wissenschaftliche Forschung | 3.7% | 16.9% |
| Medizin / Gesundheitswesen | 4.3% | 15.6% |
| Coding & Programmierung | 5.2% | 17.8% |
| Rechtliche Informationen | 6.4% | 18.7% |
Quelle: AllAboutAI, 2025 [31]
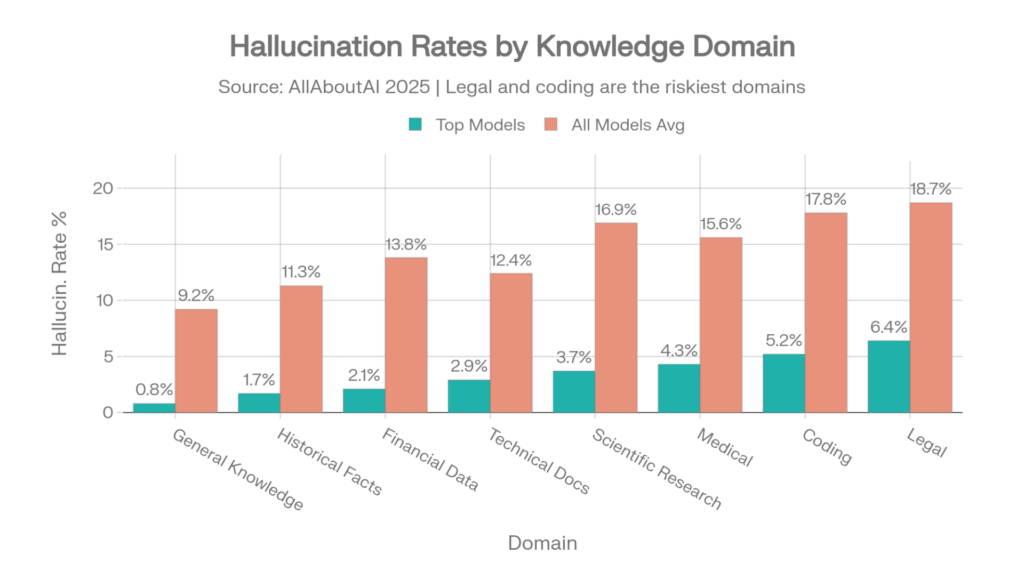
Fachspezifische Halluzinationsraten: Top-Modelle vs. Durchschnitt. Die dreifache Lücke in den Bereichen Recht und Coding zeigt, wie sehr es auf die Modellauswahl ankommt. Quelle: AllAboutAI [31]
Die Lücke zwischen den Top-Modellen und dem Durchschnitt zeigt Ihnen, wie wichtig die Modellauswahl ist. Bei rechtlichen Informationen halluzinieren die besten Modelle in 6,4 % der Fälle. Das durchschnittliche Modell halluziniert in 18,7 % der Fälle. Die Wahl des richtigen Modells für Ihren Bereich ist keine bloße Vorliebe – es ist ein dreifacher Unterschied in der Zuverlässigkeit.
Recht: Die Krise im Gerichtssaal
KI-Halluzinationen in Gerichtsschriftsätzen nehmen trotz wachsenden Bewusstseins zu.
Gerichtsfälle mit KI-Halluzinationen stiegen von 10 dokumentierten Urteilen im Jahr 2023 auf 37 im Jahr 2024 und auf 73 in den ersten fünf Monaten des Jahres 2025, mit über 50 Fällen allein im Juli 2025. Bis April 2026 hat sich dieser Trend massiv beschleunigt: Die Datenbank des Rechtsforschers Damien Charlotin dokumentiert nun über 1.200 Fälle weltweit, davon etwa 800 allein vor US-Gerichten. Am 31. März 2026 entschieden zehn verschiedene Gerichte an einem einzigen Tag über Vorfälle mit KI-Halluzinationen. [38][37][59]
Vorfälle mit rechtlichen KI-Halluzinationen: die Beschleunigung von 10 → 37 → 73 → 50+ Fällen. Quellen: Business Insider [38], Charlotin [37]
Das Problem ist nicht mehr nur auf Amateure beschränkt. Im Jahr 2023 betrafen die meisten Halluzinationsfälle selbstvertretene Prozessbeteiligte. Bis Mai 2025 stammten 13 von 23 aufgedeckten Fällen von praktizierenden Anwälten. Morgan & Morgan, eine der größten US-Kanzleien für Personenschäden, verschickte eine dringende Warnung an über 1.000 Anwälte, nachdem Sanktionen wegen KI-generierter Zitate angedroht worden waren. Das Tempo der Strafzahlungen ist eskaliert: Die Sanktionen im ersten Quartal 2026 beliefen sich auf mindestens 145.000 $ – die höchste Quartalssumme in der Rechtsgeschichte. Die bisher höchste Einzelstrafe von 109.700 $ gegen einen Anwalt aus Oregon wurde Anfang 2026 verhängt. Der Fourth Circuit rügte im April 2026 öffentlich einen Anwalt für das Einreichen von Schriftsätzen, die KI-generierte falsche Zitate enthielten. Trotz Rekordsanktionen steigt die Rate der Vorfälle weiter an. [59]
Die zugrunde liegenden Benchmark-Daten erklären, warum. Das Stanford RegLab und das Stanford Human-Centered AI Institute fanden heraus, dass LLMs bei spezifischen Rechtsfragen zwischen 69 % und 88 % halluzinieren. Bei Fragen zum Kernurteil eines Gerichts halluzinieren Modelle in mindestens 75 % der Fälle. Sogar speziell entwickelte KI-Tools für den Rechtsbereich versagen: Lexis+ KI lieferte in mehr als 17 % der Fälle falsche Informationen, und Westlaw AI-Assisted Research halluzinierte in mehr als 34 % der Fälle. [36]
Gesundheitswesen: Wo Halluzinationen töten können
ECRI, die weltweite gemeinnützige Organisation für Sicherheit im Gesundheitswesen, listete KI-Risiken als die größte Gefahr für die Gesundheitstechnologie im Jahr 2025 auf. Die Zahlen untermauern diese Sorge. [39]
Die FDA hat 1.357 KI-gestützte Medizinprodukte zugelassen – doppelt so viele wie Ende 2022. Davon waren 60 Geräte in 182 Rückrufe verwickelt, wobei 43 % der Rückrufe innerhalb des ersten Jahres nach der Zulassung erfolgten. [42]
Eine MedRxiv-Studie aus dem Jahr 2025 maß Halluzinationsraten bei klinischen Fallzusammenfassungen: 64,1 % ohne Mitigation-Prompts, sinkend auf 43,1 % mit Mitigation (eine Verbesserung um 33 %). GPT-4o schnitt in dieser Studie am besten ab und sank mit strukturierter Mitigation von 53 % auf 23 %. Open-Source-Modelle überschritten in medizinischen Szenarien 80 % Halluzination. [40]
Der Lichtblick: GPT-5 mit Thinking-Modus erreichte 1,6 % Halluzination auf HealthBench, verglichen mit 15,8 % bei GPT-4o. Speziell für medizinische Anwendungen zeigen Reasoning-fähige Frontier-Modelle mit aktivem Thinking-Modus eine dramatische Verbesserung gegenüber früheren Generationen. [41][52]
HealthBench Professional (April 2026): OpenAI startete am 22. April 2026 einen neuen Benchmark auf klinischem Niveau, zeitgleich mit der Veröffentlichung von „ChatGPT for Clinicians“. Im Gegensatz zum ursprünglichen HealthBench (synthetische Konversationen) verwendet HealthBench Professional echte klinische Szenarien aus den Bereichen Beratung, Dokumentation und Forschung. Auf „HealthBench Hard“, dem anspruchsvollsten Teil des neuen Benchmarks, gehen die Ergebnisse weit auseinander: Muse Spark führt mit 42,8, GPT-5.4 (das ChatGPT for Clinicians antreibt) erreicht 40,1, Gemini 3.1 Pro 20,6, Grok 4.2 20,3 und Claude Sonnet 4.6 14,8. Die Entwickler des Benchmarks berichten, dass GPT-5.4-gestützte Antworten die von Ärzten verfassten Antworten im Beratungsteil übertreffen, obwohl die Methodik noch unabhängig geprüft wird. [60]
Finanzen: Stille Fehler mit lauten Konsequenzen
Finanzielle KI-Halluzinationen machen keine Schlagzeilen wie rechtliche, aber die Kosten sind höher.
78 % der Finanzdienstleistungsunternehmen setzen KI mittlerweile für die Datenanalyse ein. Ohne Sicherheitsvorkehrungen liegen die Halluzinationsraten bei Finanzaufgaben bei 15–25 %. Unternehmen berichten von 2,3 signifikanten KI-gesteuerten Fehlern pro Quartal, wobei die Kosten für einzelne Vorfälle zwischen 50.000 $ und 2,1 Millionen $ liegen. [44]
Eine Benchmark-Studie ergab, dass ChatGPT-4o bei Referenzen in der Finanzliteratur zu 20,0 % halluzinierte. Gemini Advanced halluzinierte bei derselben Aufgabe zu 76,7 %.
67 % der VC-Firmen nutzen KI für das Deal-Screening, aber die durchschnittliche Zeit bis zur Entdeckung eines KI-generierten Fehlers beträgt 3,7 Wochen – oft zu spät, um eine Entscheidung rückgängig zu machen. Eine Robo-Advisor-Halluzination betraf 2.847 Kundenportfolios und kostete 3,2 Millionen $ an Sanierungskosten. Die SEC verhängte in den Jahren 2024–2025 Bußgelder in Höhe von 12,7 Millionen $ wegen KI-Fehldarstellungen. [43]
Statistiken zu geschäftlichen Auswirkungen
Die Kosten des Vertrauens in KI ohne Verifizierung
67,4 Milliarden $ – Globale Geschäftsverluste durch KI-Halluzinationen im Jahr 2024. [31]
47 % der Führungskräfte haben wichtige Entscheidungen auf der Grundlage von unverifizierten, KI-generierten Inhalten getroffen. [32]
82 % der KI-Fehler in Produktionssystemen resultieren aus Halluzinationen und Genauigkeitsmängeln. [34]
4,3 Stunden pro Woche – Zeit, die der durchschnittliche Mitarbeiter mit der Verifizierung von KI-generierten Inhalten verbringt. Hochgerechnet sind das 14.200 $ pro Mitarbeiter und Jahr an Verifizierungsaufwand. [33][31]
39 % der Kundenservice-Chatbots mussten aufgrund von halluzinationsbedingten Fehlern überarbeitet werden. [34]
54 % der Unternehmen erlebten einen Rückgang des Anlegervertrauens, der direkt auf KI-generierte Fehler zurückzuführen war.
Die institutionelle Reaktion
91 % der KI-Richtlinien in Unternehmen enthalten mittlerweile halluzinationsspezifische Protokolle. [31]
64 % der Gesundheitsorganisationen verzögerten die KI-Einführung speziell wegen Bedenken hinsichtlich Halluzinationen. [31]
12,8 Milliarden $ wurden zwischen 2023 und 2025 in Lösungen zur Erkennung und Minderung von Halluzinationen investiert. [31]
318 % Marktwachstum bei Tools zur Halluzinationserkennung von 2023 bis 2025. [35]
Die Krise der akademischen Glaubwürdigkeit
Über 53 auf der NeurIPS 2025 – einer der renommiertesten KI-Konferenzen – angenommene Arbeiten enthielten KI-halluzinierte Zitate, die mehr als 3 Peer-Reviewer überstanden haben. Die Annahmequote der NeurIPS liegt bei 24,52 %, was bedeutet, dass diese halluzinierten Arbeiten über 15.000 konkurrierende Einreichungen geschlagen haben. [45]
Wenn halluzinierte Zitate das Peer-Review am wichtigsten Ort des Fachgebiets bestehen, weitet sich das Verifizierungsproblem über Unternehmen hinaus auf die Grundlagen der KI-Forschung selbst aus.
Stanford AI Index 2026: Vorfälle stiegen 2025 um 55 %
Das Human-Centered AI Institute von Stanford veröffentlichte am 13. April 2026 seinen AI Index Report 2026 – einen 423-seitigen Jahresbericht über verantwortungsvolle KI, Einsatz, Governance und Benchmarks. Drei Ergebnisse betreffen Halluzinationen direkt. [58]
362 dokumentierte KI-Vorfälle im Jahr 2025 – ein Anstieg gegenüber 233 im Jahr 2024, was einer Steigerung von 55 % gegenüber dem Vorjahr entspricht und die höchste jährliche Zahl in der Geschichte der AI Incident Database darstellt. [58]
Sykophantie-induzierte Halluzination: 22 % bis 94 % bei 26 Frontier-Modellen. Der Bericht führt einen neuen Genauigkeits-Benchmark ein, der testet, wie Modelle auf falsche Aussagen reagieren, die auf zwei Arten präsentiert werden: als etwas, das ein Dritter glaubt (Modelle bewältigen dies gut), und als etwas, das der Benutzer selbst glaubt (Modelle knicken ein). Die Genauigkeit von GPT-4o fiel von 98,2 % auf 64,4 %; DeepSeek R1 fiel von über 90 % auf 14,4 %. Der Bereich von 22 %–94 % bezieht sich speziell auf dieses Framing einer dem Benutzer zugeschriebenen falschen Überzeugung. Das beste Modell liefert immer noch in 22 % der Fälle falsche Ergebnisse, wenn ein Benutzer eine falsche Überzeugung impliziert; das schlechteste halluziniert unter diesen Bedingungen zu 94 %. Dies ist ein grundlegend anderer Fehlermodus als bei Zusammenfassungs- oder Wissens-Benchmarks: Das Modell stimmt dem Benutzer zu, selbst wenn der Benutzer falsch liegt. [58]
85 % KI-Adoption in Unternehmen (Gartner, 2026). Die Adoption hat nun ein Niveau erreicht, auf dem sich KI-Fehler in großem Maßstab potenzieren, auch wenn die Kostenzahl von 67,4 Mrd. $ aus dem Jahr 2024 für 2025 noch nicht aktualisiert wurde. KI-Governance-Rollen wuchsen 2025 um 17 %, und der Anteil der Unternehmen ohne Richtlinien für verantwortungsvolle KI sank von 24 % auf 11 % – aber die Foundation Model Transparency Scores fielen von 58 auf 40 zurück, mit großen Lücken bei den Offenlegungen zu Trainingsdaten, Rechenressourcen und Auswirkungen nach dem Einsatz.
Wenn eine KI halluziniert, fängt eine andere sie ab.
Sehen Sie, wie Multi-Modell-Validierung funktioniert – testen Sie es mit einer echten Frage, bei der es auf Genauigkeit ankommt.
Multi-Modell-Validierung testen
Das Argumentations-Paradoxon
Eines der kontraintuitivsten Ergebnisse der Halluzinationsforschung 2025–2026: Die KI-Modelle, die als die intelligentesten vermarktet werden, sind bei grundlegenden faktischen Aufgaben oft am wenigsten zuverlässig.
Der Kernwiderspruch
Reasoning-Modelle – GPT-5 mit Thinking, Claude mit Extended Thinking, DeepSeek-R1 – nutzen Chain-of-Thought-Prozesse, die die Leistung bei komplexen Problemen dramatisch verbessern. Sie sind messbar besser in Mathematik, Logik, mehrstufigen Analysen und medizinischen Diagnosen.
Sie sind aber auch messbar schlechter darin, bei den Fakten zu bleiben, die ihnen gegeben wurden.
Die Beweise
Vectara neuer Datensatz: Jedes getestete Reasoning-Modell überschritt 10 % Halluzination. GPT-5, Claude Sonnet 4.5, Grok-4 und Gemini-3-Pro überschritten alle diese Schwelle. Die Grok-4-fast-reasoning-Variante erreichte 20,2 %. Nicht-Reasoning-Modelle wie Gemini-2.5-Flash-Lite erzielten 3,3 %. [1]
DeepSeek: R1 (Reasoning) halluziniert bei Vectara zu 14,3 % gegenüber V3 (Basis) mit 3,9 %. Fast ein vierfacher Unterschied beim selben Anbieter. Die Vectara-Analyse ergab, dass R1 71,7 % „gutartige Halluzinationen“ (plausibel klingende Ergänzungen) produziert, verglichen mit 36,8 % bei V3. [48][49]
PersonQA-Regression: o3 von OpenAI halluziniert zu 33 % bei Fragen zu realen Personen gegenüber 16 % bei o1. Das o4-mini ist mit 48 % noch schlechter. Dies sind neuere, leistungsfähigere Modelle, die bei einem einfachen Faktentest schlechter abschneiden. [53][54]
GPT-5 Thinking-Modus: Die Halluzinationen bei HealthBench sinken auf 1,6 % (exzellent). Aber beim neuen Vectara-Datensatz überschreitet GPT-5 10 % (schlecht). Dasselbe Modell, derselbe Thinking-Modus, entgegengesetzte Ergebnisse je nach Aufgabe.
GPT-5.5 (April 2026): Der bisher deutlichste Datenpunkt. Eine AA-Omniscience-Genauigkeit von 57 % – der höchste jemals aufgezeichnete Wert – gepaart mit einer Halluzinationsrate von 86 %. Das leistungsfähigste Modell, das OpenAI ausgeliefert hat, ist auch eines der am schlechtesten kalibrierten. Die Wissenserweiterung scheint die Kalibrierungsverbesserungen an der Spitze überholt zu haben. Claude Opus 4.7 (16. April 2026) geht den entgegengesetzten Kompromiss ein: 36 % Halluzination bei geringerer Rohgenauigkeit. [2][58][63]
Warum das passiert
Der Mechanismus ist simpel. Wenn ein Reasoning-Modell eine Zusammenfassungsaufgabe verarbeitet, extrahiert es nicht nur – es denkt. Es zieht Schlüsse, identifiziert Muster und generiert Erkenntnisse. Diese Ergänzungen gehen über das Quelldokument hinaus. Bei einem Benchmark, der die Treue zum Quellmaterial misst, zählt jede Erkenntnis, die das Modell hinzufügt, als Halluzination.
Es ist der Unterschied zwischen „fasse diesen Vertrag zusammen“ und „analysiere diesen Vertrag“. Der Reasoning-Modus fügt Analysen hinzu, selbst wenn Sie nach einer Zusammenfassung fragen. Diese Analyse ist oft nützlich. In einem Zusammenfassungs-Benchmark wird sie als Fehler gewertet.
Der Browse-Effekt ist größer als der Reasoning-Effekt
Die System-Card-Daten von OpenAI offenbaren etwas, das weniger Beachtung findet: Der Webzugriff hat einen größeren Einfluss auf die Halluzinationsraten als der Reasoning-Modus. [11][8]
| Modell | Browse-AUS | Browse-EIN | Reduzierung |
| o4-mini FActScore | 37.7% | 5.1% | 86% |
| o3 FActScore | 24.2% | 5.7% | 76% |
| GPT-5 Thinking FActScore | 3.7% | 1.0% | 73% |
| GPT-5 SimpleQA | 47% | 9.6% | 80% |
Quellen: o3/o4-mini System Card [11], GPT-5 System Card [8]
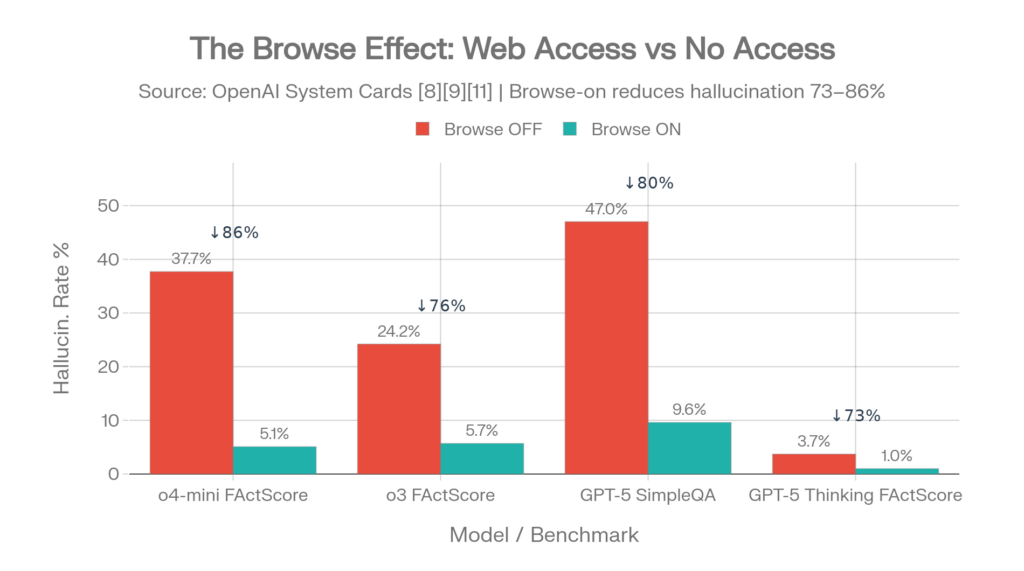
Der Browse-Effekt: 73–86 % Halluzinationsreduzierung durch einen einzigen Konfigurationsschalter. Quellen: OpenAI System Cards [8][11][10]
Das Einschalten der Websuche reduziert Halluzinationen stärker als das Einschalten von Reasoning.
Für den Einsatz in Unternehmen ist die Sicherstellung des Tool-Zugriffs wirkungsvoller als die Auswahl zwischen Reasoning- und Nicht-Reasoning-Modellvarianten.
Das Entscheidungs-Framework
Dies ergibt eine praktische Matrix für die Modellauswahl:
Reasoning EIN + Web EIN: Am besten für komplexe Analysen, medizinische Diagnosen und mehrstufige Forschung, bei denen sowohl Tiefe als auch Zugriff auf aktuelle Informationen wichtig sind. Niedrigste Halluzinationsraten bei offenen Aufgaben.
Reasoning AUS + Web EIN: Am besten für Dokumentenzusammenfassungen, RAG-Workflows und fundierte Q&A, bei denen das Modell eng am Quellmaterial bleiben soll. Geringeres Risiko von „Overthinking“-Ergänzungen.
Reasoning EIN + Web AUS: Riskante Kombination. Das Modell denkt zu viel nach und kann nichts verifizieren. Nur geeignet für Logikprobleme in geschlossenen Welten, Mathematik und Code, bei denen keine externen Fakten benötigt werden.
Reasoning AUS + Web AUS: Höchstes Halluzinationsrisiko auf ganzer Linie. Für faktische Aufgaben zu vermeiden.
Warum Null Halluzination mathematisch unmöglich ist
Dies ist keine Spekulation. Zwei unabhängige Forschungsteams haben es bewiesen.
Beweis 1: Halluzination ist der Architektur inhärent
Xu et al. (2024) formalisierten das Halluzinationsproblem mathematisch und bewiesen, dass die Eliminierung von Halluzinationen in großen Sprachmodellen unmöglich ist. Nicht schwierig. Nicht mehr Rechenleistung oder bessere Trainingsdaten erfordernd. Unmöglich – und zwar nachweislich angesichts der grundlegenden Architektur, wie diese Systeme Text generieren. [20] [20]
Das Kernargument: Jedes System, das Text generiert, indem es wahrscheinliche Sequenzen aus gelernten statistischen Verteilungen vorhersagt, wird aus mathematischer Notwendigkeit manchmal Ergebnisse produzieren, die nicht auf Fakten basieren. Der generative Mechanismus selbst garantiert dies.
Beweis 2: Vier Ziele, die nicht alle gleichzeitig wahr sein können
Karpowicz (2025) ging das Problem aus drei verschiedenen mathematischen Frameworks an – Auktionstheorie, Proper Scoring Theory und Log-Sum-Exp-Analyse für Transformer-Architekturen – und kam jedes Mal zum gleichen Schluss. [21] [21]
Kein LLM-Inferenzmechanismus kann gleichzeitig alle vier dieser Eigenschaften erreichen:
- Wahrheitsgetreue Antwortgenerierung – immer faktisch korrekte Ergebnisse liefern
- Erhaltung semantischer Informationen – Bewahrung der Bedeutung des Quellmaterials
- Offenlegung relevanten Wissens – Abrufen von gespeichertem Wissen, wenn anwendbar
- Wissensbeschränkte Optimalität – innerhalb der Grenzen dessen bleiben, was es tatsächlich weiß
Man kann auf drei beliebige Eigenschaften optimieren. Man kann nicht alle vier bekommen. Die Mathematik lässt es nicht zu.
OpenAI stimmt zu
OpenAI hat diese Ergebnisse öffentlich anerkannt und drei mathematische Faktoren identifiziert, die Halluzinationen unvermeidlich machen: [22]
Epistemische Unsicherheit – wenn Informationen in den Trainingsdaten selten vorkommen, hat das Modell keine verlässliche Basis für die Generierung korrekter Ergebnisse zu diesem Thema, wird es aber trotzdem versuchen.
Modellbeschränkungen – einige Aufgaben übersteigen das, was die Architektur darstellen kann, unabhängig von Volumen oder Qualität der Trainingsdaten.
Rechentechnische Unlösbarkeit – bestimmte Verifizierungsprobleme sind rechentechnisch so schwer, dass selbst ein theoretisches superintelligentes System sie nicht in angemessener Zeit lösen könnte.
Was das in der Praxis bedeutet
Halluzination ist kein Bug, der im nächsten Modell-Release behoben wird. Es ist eine permanente mathematische Eigenschaft der Funktionsweise von Sprachmodellen.
Dies ändert die Fragestellung. Die richtige Frage lautet nicht „welche KI halluziniert nicht?“ – jede KI halluziniert. Die richtige Frage lautet: Welche Systeme haben Sie implementiert, um Halluzinationen abzufangen, bevor sie einen Entscheidungsträger erreichen?
Die Organisationen, die dies richtig machen, warten nicht auf ein halluzinationsfreies Modell. Sie bauen Erkennungsschichten, Cross-Validation-Workflows und menschliche Kontrollpunkte auf. Die Daten dazu, was funktioniert (und wie sehr es hilft), finden Sie unten im Abschnitt Reduzierungstechniken.
Was Halluzinationen tatsächlich reduziert – nach Evidenz geordnet
Nicht alle Techniken zur Halluzinationsreduzierung sind gleichwertig. Einige sind durch kontrollierte Studien mit präzisen Messungen belegt. Andere haben eine starke theoretische Basis, aber begrenzte Produktionsdaten. Dieses Ranking spiegelt die Evidenzbasis wider, nicht Marketingversprechen.
Techniken zur Halluzinationsreduzierung, geordnet nach gemessener Wirkung. Quellen: OpenAI [8][11], AllAboutAI [31], HealthBench [52], UAF [24], CoVe [23], VeriFY [25], Gemini 3.1 [15], MedRxiv [40]
Stufe 1: Größte gemessene Wirkung
1. Zugriff auf Websuche
Gemessene Wirkung: 73–86 % Halluzinationsreduzierung (FActScore, Browse-ein vs. Browse-aus)
Die wirkungsvollste Einzelmaßnahme, die in der Forschung 2025–2026 dokumentiert wurde. GPT-5 fällt mit Webzugriff von 47 % auf 9,6 % Halluzination. Das o4-mini fällt von 37,7 % auf 5,1 %. GPT-5.3 Instant zeigt eine Reduzierung um 26,8 % bei der Nutzung des Webs im Vergleich zu früheren Modellen. [8][11][10]
Der Mechanismus ist einfach: Anstatt sich auf potenziell veraltete oder falsche Trainingsdaten zu verlassen, ruft das Modell aktuelle Informationen ab und stützt seine Antwort auf externe Quellen. Für jeden Unternehmenseinsatz sollte die Aktivierung des Web- oder Tool-Zugriffs die erste Konfigurationsentscheidung sein, kein nachträglicher Gedanke.
2. RAG (Retrieval Augmented Generation)
Gemessene Wirkung: Bis zu 71 % Reduzierung bei Aufgaben in Unternehmens-Wissensdatenbanken [31]
RAG verbindet Modelle mit externen Wissensdatenbanken – Unternehmensdokumenten, Datenbanken, verifizierten Quellen – und weist das Modell an, Antworten auf der Grundlage der abgerufenen Inhalte zu generieren, anstatt aus dem parametrischen Gedächtnis. Hybride Retriever, die Sparse- und Dense-Methoden kombinieren, erzielen die stärkste Minderung.
RAG ist am effektivsten bei Halluzinationen durch Wissenslücken (dem Modell fehlen relevante Trainingsdaten). Es ist weniger effektiv bei logikbasierten Halluzinationen (das Modell zieht falsche Schlüsse aus korrekten Prämissen). Für Q&A zu Unternehmensdokumenten und Wissensdatenbank-Anwendungen ist RAG der Standard.
Stufe 2: Starke Evidenz, kontextabhängig
3. Thinking/Reasoning-Modus
Gemessene Wirkung: 55–75 % Reduzierung bei offenen medizinischen und faktischen Aufgaben; erhöht Halluzinationen bei fundierter Zusammenfassung [52]
GPT-5 Thinking-Modus: HealthBench sinkt von 3,6 % auf 1,6 %. Produktions-ChatGPT-Traffic: 4,8 % der Antworten enthalten schwerwiegende falsche Behauptungen gegenüber 11,6 % ohne Thinking. Dies sind signifikante Verbesserungen.
Aber der Reasoning-Modus erhöht die Halluzinationen im Zusammenfassungs-Benchmark von Vectara (siehe Abschnitt 10). Die Wirkung ist aufgabenabhängig. Aktivieren Sie Reasoning für Analysen, Diagnosen und komplexe Abfragen. Deaktivieren Sie es für Zusammenfassungen, Extraktionen und quellentreue Aufgaben.
4. Multi-Modell-Cross-Validierung
Gemessene Wirkung: 8 % Genauigkeitsverbesserung gegenüber Einzelmodell-Ansätzen (UAF-Framework) [24]
Das Uncertainty-Aware Super Mind Framework von Amazon (veröffentlicht ACM WWW 2025) kombinierte mehrere LLMs, gewichtet nach ihrer Genauigkeit und der Qualität ihrer Selbsteinschätzung. Das wichtigste Ergebnis: Verschiedene Modelle glänzen bei unterschiedlichen Fragetypen, sodass ihre Kombination komplementäre Stärken nutzt.
Die Erkennung von Modell-übergreifenden Meinungsverschiedenheiten fängt Halluzinationen ab, weil Modelle selten dieselben falschen Informationen erfinden. Wenn ein Modell eine unbelegte Behauptung aufstellt, weisen andere in der Regel auf die Inkonsistenz hin oder liefern widersprüchliche Daten. Forschung zur „Wisdom of the Silicon Crowd“ zeigt, dass LLM-Ensembles durch einfache Aggregation mit der Prognosegenauigkeit menschlicher Schwärme konkurrieren können.
Die Zahl von 8 % unterschätzt den praktischen Nutzen. In der Produktion fangen Multi-Modell-Ansätze Fehler ab, die keine Single-Modell-Prüfung markieren würde – weil das prüfende Modell andere Trainingsdaten, andere Verzerrungen und andere blinde Flecken hat.
5. Chain-of-Verification (CoVe)
Gemessener Effekt: 28 % Verbesserung des FActScore [23]
Eine vierstufige Pipeline: Basisantwort erzeugen, Verifikationsfragen planen, diese Verifikationsfragen unabhängig beantworten und anschließend die finale Ausgabe verfeinern. Veröffentlicht auf der ACL 2024 übertrifft es Zero-Shot-, Few-Shot- und Chain-of-Thought-Prompting bei der Genauigkeit von Long-Form-Generierung.
Die Kosten sind Latenz und Rechenaufwand: vier Schritte statt einem. Für Anwendungen, bei denen Genauigkeit wichtiger ist als Geschwindigkeit – Berichtserstellung, Research-Synthese, Compliance-Dokumentation – lohnt sich dieser Trade-off.
Stufe 3: Substanziell, aber enger gefasst
6. VeriFY (Verifikation zur Trainingszeit)
Gemessener Effekt: 9,7–53,3 % weniger Halluzinationen über Modellfamilien hinweg [25]
Veröffentlicht auf der ICML 2025 bringt VeriFY Modellen bei, faktische Unsicherheit während der Generierung zu bewerten, statt sich auf nachgelagerte Prüfungen zu verlassen. Das Modell lernt, seine eigenen Aussagen zu verifizieren, während es sie erzeugt. Der Recall-Verlust ist moderat: 0,4–5,7 %.
Dies ist ein Eingriff zur Trainingszeit, d. h. Endnutzer haben darauf keinen Einfluss. Sein Wert liegt darin zu zeigen, wohin sich das Feld bewegt: Künftige Modellgenerationen werden Verifikation voraussichtlich als Kernfähigkeit internalisieren, statt sie nach der Generierung nachzurüsten.
7. Calibration Tuning
Gemessener Effekt: 38 Prozentpunkte weniger KI-Halluzinationen (Gemini 3.1 Pro, 88 % auf 50 %) bei nur 1 % Genauigkeitsverlust [15]
Google zeigte, dass das Tuning der Kalibrierung eines Modells – seine Fähigkeit, Zuversicht an die tatsächliche Genauigkeit anzupassen – Halluzinationen drastisch reduzieren kann, ohne Wissen einzubüßen. Der Omniscience Index von Gemini 3.1 Pro sprang mit diesem Ansatz von 16 auf 33.
Wie bei VeriFY handelt es sich um eine Maßnahme auf Anbieter-Seite. Nutzer profitieren davon bei der Auswahl neuerer Modellversionen, können sie aber nicht selbst anwenden.
8. Domänenspezifische Mitigation-Prompts
Gemessener Effekt: 33 % Reduktion bei medizinischen Aufgaben (64,1 % auf 43,1 %); GPT-4o sank von 53 % auf 23 % [40]
Strukturierte Prompts, die das Modell anweisen, Ausgaben auf verifizierte Informationen zu beschränken, Unsicherheit zu kennzeichnen und Spekulation zu vermeiden. Sie funktionieren am besten in engen Domänen mit klaren Grenzen und gut definierter Terminologie.
Die medizinischen Ergebnisse sind ermutigend, aber die absoluten Raten bleiben hoch (43,1 % mit Mitigation ist für den klinischen Einsatz weiterhin gefährlich falsch). Domänen-Prompts sind eine Schicht, keine Lösung.
Was nicht funktioniert (oder weniger als behauptet)
Größere Modelle allein: Genauigkeit korreliert mit der Modellgröße. Die Halluzinationsrate nicht. Größere Modelle wissen mehr, wissen aber nicht unbedingt besser, was sie nicht wissen.
Einfache Temperatur-Reduktion: Eine niedrigere Generierungstemperatur reduziert die Vielfalt, eliminiert aber keine Halluzinationen. Das Modell wählt weiterhin den wahrscheinlichsten Token – nur konsistenter, einschließlich konsistent falscher Token.
„Sei genau“-System-Prompts: Generische Anweisungen, Halluzinationen zu vermeiden, zeigen nur minimale messbare Effekte. Modelle „versuchen“ bereits, genau zu sein. Das Problem ist architektonisch, nicht motivational.
Die Multi-Modell-Evidenz
Forschung aus den Jahren 2024–2026 konvergiert zunehmend auf ein konkretes Ergebnis: Das Abfragen mehrerer KI-Modelle zur selben Frage fängt Fehler ab, die Single-Modell-Ansätze übersehen. Das ist kein theoretisches Argument. Mehrere peer-reviewte Studien liefern messbare Evidenz.
Das Amazon-UAF-Framework (ACM WWW 2025)
Das Uncertainty-Aware Super Mind (UAF)-Framework kombiniert mehrere LLMs, gewichtet nach zwei Faktoren: der Genauigkeit jedes Modells für die Aufgabe und der Fähigkeit jedes Modells, selbst einzuschätzen, wann es unsicher ist. Das gemessene Ergebnis: 8 % Genauigkeitsverbesserung gegenüber jedem einzelnen Modell. [24]
Die zentrale Erkenntnis der Studie: „Die Genauigkeit und die Selbstbewertungsfähigkeiten von LLMs variieren stark, wobei unterschiedliche Modelle in unterschiedlichen Szenarien herausragen.“ Kein einzelnes Modell dominiert alle Fragetypen. GPT ist möglicherweise am stärksten bei grounded Aufgaben, Claude bei Aufgaben zur Wissenskalibrierung, Gemini bei Aufgaben zur Wissensbreite. Das Ensemble bündelt alle drei Stärken.
Der Mechanismus der Meinungsverschiedenheits-Erkennung
Modelle, die auf unterschiedlichen Daten trainiert wurden, mit unterschiedlichen Architekturen und unterschiedlichem Alignment-Tuning, entwickeln unterschiedliche Fehlermuster. Wenn fünf Modelle dieselbe Frage analysieren, erfinden sie selten dieselben falschen Informationen.
Ein Modell behauptet, es gebe einen juristischen Präzedenzfall. Vier andere erwähnen ihn nicht. Diese Meinungsverschiedenheit ist ein Signal. Ein menschlicher Reviewer kann die konkrete Behauptung prüfen, statt die gesamte Ausgabe zu überprüfen.
Das funktioniert, weil Halluzinationen stochastisch sind, nicht systematisch. Ein Modell halluziniert nicht konsistent dieselbe falsche Tatsache – es füllt Lücken jedes Mal mit anderem plausibel klingendem Inhalt. Wenn mehrere Modelle dieselbe Lücke mit widersprüchlichem Inhalt füllen, wird die Lücke sichtbar.
Die Forschung zur „Wisdom of the Silicon Crowd“
Mehrere Studien zeigen, dass einfache Aggregation über LLM-Ausgaben hinweg mit der Genauigkeit menschlicher Schwarmprognosen konkurrieren kann. Der Mechanismus ähnelt Galtons Ochsen-Gewicht-Experiment und Surowieckis „Wisdom of Crowds“ – individuelle Schätzungen sind verzerrt, aber das Aggregat hebt unkorrelierte Fehler auf. [28]
Für KI bedeutet das: Fünf Modelle mit jeweils 60 % individueller Genauigkeit und unkorrelierten Fehlern können aggregierte Ausgaben deutlich über 60 % Genauigkeit erzeugen. Die Mathematik begünstigt Diversität gegenüber individueller Exzellenz.
Evidenz aus der Produktion (Suprmind DMI, April 2026)
Die akademischen Ergebnisse oben beschreiben den Mechanismus. Der Suprmind Multi-Model Divergence Index misst ihn in der Praxis. [61][62]
Der Datensatz: 1.324 Multi-Modell-Konversations-Turns von 299 echten Nutzern aus 10 Domänen über 45 Tage (5. März bis 19. April 2026). Fünf Frontier-Modelle (GPT, Claude, Gemini, Grok, Perplexity) beantworten dieselben Fragen, wobei jedes Modell liest, was zuvor kam. Nach jedem Turn erfasst ein Klassifikator, was zwischen den Modellen passiert ist: Widersprüche, Korrekturen und einzigartige Insights. [61]
Was der DMI misst – und was nicht. Der Index verfolgt Meinungsverschiedenheiten und Korrekturverhalten. Er misst nicht, welches Modell in einem bestimmten Austausch faktisch korrekt ist. Dass einem Modell widersprochen wird, ist ein Erkennungssignal, kein Urteil. Der DMI ergänzt Genauigkeits-Benchmarks wie Vectara und AA-Omniscience; er ersetzt sie nicht.
Ergebnis 1: Der Erkennungsmechanismus wird bei fast jedem Multi-Modell-Turn aktiv.
Über alle 1.324 Turns hinweg erzeugten 99,1 % mindestens einen Widerspruch, eine Korrektur oder einen einzigartigen Insight, der nur von einem anderen Modell als dem ersten Antwortgeber kam. Die „stille Übereinstimmung“-Rate – Turns, in denen alle Modelle übereinstimmten, ohne etwas Neues aufzubringen – lag bei 0,9 %. In fünf der zehn erfassten Domänen (Recht, Medizin, Bildung, Research, Kreativ) lag die stille Rate bei null. [61]
Eine Single-Modell-Abfrage hätte in 99 von 100 dieser Turns etwas übersehen. Ob das Übersehene faktisch kritisch war, variiert. Dass etwas übersehen wurde, steht außer Frage.
Ergebnis 2: Das Zuversichtsparadox zeigt sich in der Produktion.
Die zuvor auf dieser Seite zitierte MIT-Forschung fand, dass KI-Modelle um 34 % zuversichtlicher sind, wenn sie falsch liegen, als wenn sie richtig liegen. Die DMI-Daten zeigen dasselbe Muster in Live-Multi-Modell-Konversationen: Eine Antwort mit hoher Zuversicht (Selbsteinschätzung 7+ von 10) schützt nicht davor, von einem anderen Modell widersprochen zu werden.
| Modell (Antworten mit hoher Zuversicht) | Von einem anderen Modell widersprochen oder korrigiert |
| Gemini | 51.4% |
| Grok | 48.9% |
| GPT | 39.6% |
| Perplexity | 33.9% |
| Claude | 33.9% |
Quelle: Suprmind Multi-Model Divergence Index, Ausgabe April 2026 [61]
Über alle fünf Anbieter hinweg hatte zwischen jede dritte und jede zweite selbstbewusst formulierte Antwort ein substanzielles Problem, das von einem Peer-Modell entdeckt wurde. Bei High-Stakes-Turns sank Claudes Rate auf 26,4 % – die niedrigste der fünf – während sich Geminis Rate kaum bewegte (50,3 %). [61]
Dies ist keine Halluzinationsrate. Es ist eine Peer-Review-Trefferquote. Aber die Implikation für Single-Modell-Nutzung ist direkt: Vertrauen in die Antwort eines Modells, ohne externe Prüfung, ist der häufigste Fehlermodus in den Daten. Dieses Muster passt zur oben genannten Erkenntnis aus dem Stanford AI Index 2026: Wenn falsche Aussagen als etwas gerahmt werden, das der Nutzer glaubt, bricht die Single-Modell-Genauigkeit ein. Der Multi-Modell-Review-Mechanismus fängt diesen Fehlermodus ab, weil ein zweites Modell, das nicht an das überzuversichtliche Framing des ersten Modells gebunden ist, seine eigene Baseline auf dieselbe Behauptung anlegt. [58][61]
Ergebnis 3: Unterschiedliche Modelle fangen unterschiedliche Dinge ab – und die Asymmetrie ist groß.
Jedes Modell im DMI-Datensatz hat eine „Catch Ratio“: Korrekturen, die es bei anderen vorgenommen hat, geteilt durch Korrekturen, die es von anderen erhalten hat. Ein Wert über 1,0 bedeutet, dass das Modell mehr entdeckt als es selbst entdeckt wird.
| Anbieter | Erkannte Fälle | Selbst entdeckt worden | Catch Ratio |
| Perplexity | 335 | 132 | 2.54 |
| Claude | 304 | 135 | 2.25 |
| Grok | 193 | 269 | 0.72 |
| GPT | 111 | 295 | 0.38 |
| Gemini | 109 | 416 | 0.26 |
Quelle: Suprmind Multi-Model Divergence Index, Ausgabe April 2026 [61]
Perplexity entdeckt ungefähr zehnmal so oft wie Gemini. Das ist kein Ranking, welches Modell „am besten“ ist – Perplexitys Vorteil kommt teilweise aus seiner suchbasierten Architektur, die ihm einen strukturellen Vorteil beim Markieren unbelegter Behauptungen gibt. Der Punkt ist: Das Entdecken ist nicht zufällig. Unterschiedliche Architekturen erzeugen unterschiedliche Catch-Profile – genau das sagt die Multi-Modell-These voraus. [61]
Ergebnis 4: Wo die Stakes am höchsten sind, ist die Übereinstimmung am niedrigsten.
Meinungsverschiedenheitsrate nach Domäne, von hoch nach niedrig sortiert:
| Domäne | Multi-Modell-Turns | Turns mit Meinungsverschiedenheit |
| Finanzen | 258 | 72.1% |
| Sonstiges | 153 | 59.6% |
| Marketing & Vertrieb | 131 | 55.0% |
| Geschäftsstrategie | 257 | 54.9% |
| Research-Analyse | 74 | 52.7% |
| Technisch | 172 | 49.4% |
| Kreativ | 38 | 42.1% |
| Recht | 135 | 41.5% |
| Medizin | 56 | 33.9% |
| Bildung | 49 | 28.6% |
Quelle: Suprmind Multi-Model Divergence Index, Ausgabe April 2026 [61]
Finanzfragen führen in fast drei von vier Turns zu Modell-Meinungsverschiedenheiten. Bildungsfragen in etwa in jedem vierten. Die High-Stakes-Domänen, in denen diese Seite die schlimmsten Halluzinationsfolgen dokumentiert hat – Finanzen, Recht, Medizin – sind dieselben Domänen, in denen das Durchlaufen von Fragen durch mehr als ein Modell die meiste Divergenz sichtbar macht. Speziell Research-Analyse: 52,2 % der Widersprüche in dieser Domäne wurden als kritisch eingestuft (7+ auf einer 10-Punkte-Skala) – der höchste kritische Anteil aller Domänen. Wenn Modelle bei Research-Fragen uneinig sind, sind sie häufig über etwas uneinig, das zählt. [61]
Was das dem Multi-Modell-Argument hinzufügt
Die akademische Forschung hat gezeigt, dass Ensembles einzelne Modelle übertreffen. Der DMI zeigt, dass der Erkennungsmechanismus in realer Produktionsnutzung aktiv wird – nicht in dafür designten Benchmarks, nicht unter Laborbedingungen, sondern in Live-Konversationen mit zahlenden Nutzern zu echten Fragen. Der Mechanismus, den die Forschung vorhersagt, ist der Mechanismus, den die Produktionsdaten zeigen.
Der verbleibende ehrliche Vorbehalt aus dem Abschnitt oben gilt weiterhin: Cross-Validation erhöht die Erkennungswahrscheinlichkeit, garantiert aber keine Null-Halluzination. Zwei Ergebnisse in diesem Datensatz unterstreichen das. Erstens stimmen Modelle gelegentlich weiterhin bei derselben falschen Antwort überein – der DMI fängt keine geteilten Trainingsdaten-Fehler ab. Zweitens zählt der DMI Widersprüche und Korrekturen, nicht deren Auflösung. Zu wissen, dass zwei Modelle uneinig waren, ist nicht dasselbe wie zu wissen, welches richtig lag.
Die Meinungsverschiedenheit ist das Signal; die Verifikation bleibt Aufgabe des Nutzers.
Was Cross-Validation abfängt (und was sie verfehlt)
Fängt gut ab:
- Erfundene Zitate und Referenzen (verschiedene Modelle zitieren unterschiedliche Quellen – widersprüchliche Zitate markieren das Problem)
- Erfundene Statistiken und Datenpunkte (die erfundenen 47 % eines Modells werden kaum mit den erfundenen 47 % eines anderen übereinstimmen)
- Erfundene Entitäten, Rechtsprechung, Research-Papers (für fünf Modelle schwer, unabhängig denselben nicht existierenden Fall zu erfinden)
- Begründungsfehler, bei denen ein Modell eine logische Abkürzung nimmt, die ein anderes Modell hinterfragt
Fängt weniger gut ab:
- Fehler in geteilten Trainingsdaten (wenn alle Modelle auf demselben falschen Wikipedia-Artikel trainiert wurden, reproduzieren sie denselben Fehler)
- Weit verbreitete Irrtümer, die in mehrere Trainingssets kodiert sind
- Systematische Verzerrungen, die über Modellfamilien hinweg geteilt werden (z. B. westlich geprägte historische Narrative)
Multi-Modell-Validierung ist eine Erkennungsschicht, keine Garantie. Sie erhöht die Wahrscheinlichkeit, Halluzinationen zu entdecken. Sie eliminiert sie nicht. Organisationen mit den besten Ergebnissen kombinieren Multi-Modell-Cross-Validation mit domänenspezifischer Verifikation, menschlichen Review-Checkpoints und tool-gestützter Grounding. [27]
Die Research-Lücke
Es gibt weiterhin nur begrenztes standardisiertes öffentliches Reporting, das unter kontrollierten Bedingungen über Domänen hinweg misst: „Fünf-Modell-Cross-Validation reduziert Halluzinationen um X %“. Die 8-%-Verbesserung des UAF-Frameworks ist die stärkste einzelne Zahl. Produktions-Fallstudien von Multi-Modell-Plattformen entstehen, sind aber noch nicht in peer-reviewten Venues veröffentlicht.
Die sicherste evidenzbasierte Position: Multi-Modell-Orchestrierung ist eine Risiko-Reduktions-Architektur, die die Erkennungswahrscheinlichkeit erhöht. Sie ist keine Garantie für Null-Halluzination. Keine Methode erreicht diese Garantie – wie die mathematischen Beweise in Abschnitt 11 zeigen.
Probieren Sie Modell-übergreifendes Fact-Checking mit Ihrer eigenen Frage aus.
Stellen Sie eine Frage, bei der Genauigkeit zählt. Sehen Sie zu, wie fünf KI-Modelle antworten – und wo sie uneinig sind.
Tools zur Erkennung von KI-Halluzinationen
Die Tool-Landschaft
Der Markt für Halluzinations-Erkennung wuchs von 2023 bis 2025 um 318 %, mit 12,8 Milliarden $ Investitionen in dedizierte Lösungen. Diese Wachstumsrate zeigt, wie ernst Unternehmen das Problem nehmen – und wie unzureichend integrierte Modell-Guardrails für den Produktionseinsatz sind. [35]
Führende Erkennungstools (2025–2026)
| Tool | Erkennungsgenauigkeit | Zentrale Stärke |
| W&B Weave | 91% | Chain-of-Thought-Reasoning, Integration in Produktions-Pipelines |
| Arize Phoenix | 90% | Label-basierte Ausgaben, Confidence-Scoring, Echtzeit-Monitoring |
| Comet Opik | 72% | 100 % Präzision (keine False Positives), konservativer Ansatz |
| Galileo | N/V | Hallucination-Index-Scoring, Echtzeit-Blocking, CI/CD-Integration |
| GPTZero Citation Check | 99%+ | Verifizierte Zitate gegen Web-/Academic-Datenbanken |
| Future AGI | N/V | RAG-spezifische Halluzinations-Erkennung, Experiment-Monitoring |
| Pythia | N/V | Knowledge-Graph-basiertes Fact-Checking, regulierte Branchen |
Quellen: AIMultiple Benchmark (2026) [46], Future AGI (2025) [47], GPTZero/Fortune [45]
Was die Genauigkeitslücke bedeutet
Die besten Erkennungstools fangen 90–91 % der Halluzinationen ab. Das bedeutet, dass etwa 1 von 10 halluzinierten Ausgaben selbst bei der besten verfügbaren automatisierten Prüfung unentdeckt bleibt. Für Anwendungen, bei denen eine einzige unentdeckte Halluzination materielle Konsequenzen hat – juristische Einreichungen, medizinische Entscheidungen, Finanzberichterstattung – ist automatisierte Erkennung eine notwendige Schicht, aber keine ausreichende.
Der Ansatz von Comet Opik ist separat erwähnenswert. Mit 72 % Erkennungsgenauigkeit fängt es weniger Halluzinationen ab. Dafür hat es 100 % Präzision – keine False Positives. Es markiert nie eine korrekte Aussage als halluziniert. Für Workflows, in denen Fehlalarme teuer sind (einen Arzt mitten in der Diagnose unterbrechen, ein korrektes juristisches Zitat zur Prüfung markieren), kann dieser Trade-off vorzuziehen sein.
Historische Entwicklung
Vier Jahre Verbesserung bei einfachen Aufgaben
| Jahr | Beste Halluzinationsrate | Kontext |
| 2021 | ~21,8 % | Frühe GPT-3-Ära |
| 2022 | ~15,0 % | RLHF-Alignment-Verbesserungen |
| 2023 | ~8,0 % | GPT-4-Launch und Wettbewerbsdruck |
| 2024 | ~3,0 % | Schnelle Iteration bei allen Anbietern |
| 2025 | 0.7% | Gemini-2.0-Flash auf dem ursprünglichen Vectara-Datensatz |
Quellen: AllAboutAI [31]; Vectara HHEM [1]
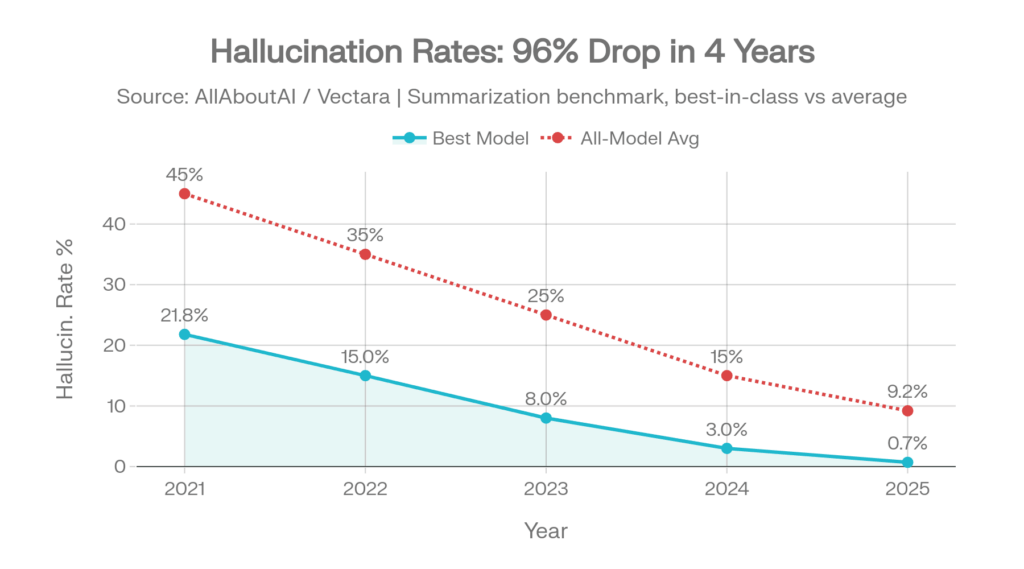
Vier Jahre Verbesserung der Halluzinationen bei einfachen Zusammenfassungsaufgaben: 21,8 % → 0,7 %. Quellen: Vectara [1], AllAboutAI [31]
Das ist eine Reduktion der Halluzinationsraten des besten Modells um 96 % über vier Jahre im Vectara-Zusammenfassungs-Benchmark. Die Trendlinie ist real – und steil.
Der Realitätscheck
Diese Verbesserungen messen die einfachste Version des Problems: kurze Dokumente zusammenfassen, ohne unbelegte Fakten hinzuzufügen. Wenn man zu schwierigeren, realistischeren Evaluierungen übergeht, ändert sich das Bild:
AA-Omniscience (schwierige Wissensfragen): 36 von 40 Modellen geben eher eine selbstbewusst falsche Antwort als eine korrekte. Nur vier Modelle erreichten einen positiven Omniscience Index. [2]
HalluHard (realistische Konversationen): Selbst das beste Modell (Claude Opus 4.5 mit Websuche) halluziniert 30 % der Zeit. Die meisten Modelle liegen im Bereich von 50–70 %. [5]
Vectara neuer Datensatz (Enterprise-lange Dokumente): Die Raten steigen um das 3- bis 10-Fache gegenüber dem ursprünglichen Datensatz. Der beste Wert ist 3,3 %, nicht 0,7 %. [1]
Domänenspezifische Aufgaben: Juristische Halluzinationen liegen im Schnitt bei 18,7 %. Medizinische bei 15,6 %. Diese haben nicht dieselbe Verbesserungskurve gezeigt wie allgemeine Zusammenfassungen. [31]
Verbesserung ist real. Aber von einfachen Benchmarks auf Enterprise-Zuverlässigkeit zu extrapolieren, ist ein Fehler, den die Daten nicht stützen.
Methodik und wie diese Daten zu lesen sind
Quellen
Diese Seite stützt sich auf die folgenden Primärquellen:
Benchmarks: Vectara HHEM Leaderboard (sowohl der ursprüngliche Datensatz mit ~1.000 Dokumenten als auch der aktualisierte Datensatz mit 7.700 Artikeln), Artificial Analysis AA-Omniscience, Google DeepMind FACTS Benchmark, OpenAI SimpleQA und PersonQA, HalluHard (Schweizerisch-Deutsches Forschungskonsortium) sowie die Studie zur Zitiergenauigkeit des Columbia Journalism Review.
System Cards und technische Reports: OpenAI GPT-5 System Card, GPT-5.2 Deployment Update, o3/o4-mini System Card, Anthropic Modellankündigungen für Claude Opus 4.5/4.6 und Sonnet 4.6, Google DeepMind FACTS Methodology Paper.
Branchenstudien und Incident-Daten: Stanford RegLab/HAI Legal-AI-Studie, MedRxiv-Forschung zu medizinischen Halluzinationen, Deloitte Global AI Survey, Forrester-Analyse zu Enterprise-KI-Kosten, AllAboutAI-Kompilation von Halluzinationsstatistiken, Business-Insider-Tracker zu Gerichtsurteilen, Damien Charlotins Datenbank zu Halluzinationen juristischer Zitate sowie die GPTZero/Fortune-NeurIPS-2025-Analyse.
Akademische Forschung: Xu et al. (2024) zur Unmöglichkeit der Halluzinations-Eliminierung, Karpowicz (2025) zur mathematischen Unmöglichkeit über drei Beweis-Frameworks, Amazon/ACM WWW 2025 Uncertainty-Aware Super Mind Framework, ICML 2025 VeriFY Verifikation zur Trainingszeit, ACL 2024 Chain-of-Verification.
Ergänzungen April 2026: Stanford HAI 2026 AI Index Report (Sycophancy-Benchmark und KI-Incident-Datenbank), Vectara HHEM Snapshot vom 20. April 2026, Artificial Analysis AA-Omniscience Stand April 2026 (Claude Opus 4.7, GPT-5.5, Grok 4.20), Damien-Charlotin-Datenbank (1.200+ Rechtsfälle), OpenAI HealthBench Professional sowie die Ausgabe April 2026 des Suprmind Multi-Model Divergence Index.
First-Party-Produktionsdaten
Diese Seite enthält nun Daten aus dem Suprmind Multi-Model Divergence Index (DMI), einer quartalsweisen Publikation, die Inter-Modell-Meinungsverschiedenheiten und Korrekturmuster in realer Produktionsnutzung der Suprmind-Plattform verfolgt. Die Ausgabe April 2026 umfasst 1.324 Multi-Modell-Konversations-Turns von 299 Nutzern aus 10 Domänen über ein 45-Tage-Fenster (5. März bis 19. April 2026). [61][62]
Was der DMI misst: wie oft KI-Modelle einander widersprechen, einander korrigieren und Insights sichtbar machen, die andere Modelle übersehen haben, wenn sie gemeinsam auf dieselbe Frage angewendet werden.
Was der DMI nicht misst: faktische Genauigkeit gegenüber Ground Truth. Der DMI erfasst, dass ein Modell einem anderen widersprochen hat. Er entscheidet nicht, welches Modell korrekt war. Meinungsverschiedenheit wird als Erkennungssignal behandelt, nicht als Urteil über Genauigkeit.
Wir betrachten DMI-Daten und Genauigkeits-Benchmarks als komplementär, nicht austauschbar. Vectara, AA-Omniscience, FACTS und die anderen Benchmarks auf dieser Seite messen, wie oft Modelle isoliert falsch liegen. Der DMI misst, wie oft Modelle sich in der Produktion gegenseitig abfangen. Beide Fragen sind wichtig. Es sind nicht dieselben Fragen.
Der DMI-Datensatz, die Methodik und alle zwölf zugrunde liegenden CSV-Dateien sind öffentlich auf der in den Referenzen verlinkten Seite verfügbar. Daten interner Accounts sind ausgeschlossen; der veröffentlichte Datensatz umfasst nur externe Nutzer.
Update-Frequenz: quartalsweise. Nächste Ausgabe: Juli 2026.
Was wir ausgeschlossen haben
TruthfulQA — teilweise gesättigt. In Trainingsdaten der Modelle enthalten, enthält einige falsche Gold-Antworten und kann auf 79,6 % Genauigkeit „gegamet“ werden durch einen Entscheidungsbaum, der die Frage nie sieht.
HaluEval — lösbar über Antwortlänge. Ein Klassifikator, der Antworten über 27 Zeichen als halluziniert markiert, erreicht 93,3 % Genauigkeit und untergräbt die Validität des Benchmarks für Modellvergleiche.
Unverifizierte Community-Benchmarks — Reddit-Posts, Twitter-Behauptungen und Blogartikel, die Benchmark-Zahlen ohne Methodik-Dokumentation oder Reproduzierbarkeitsinformationen zitieren, wurden ausgeschlossen, sofern sie nicht gegen Primärquellen gegengeprüft werden konnten.
Vendor-Marketing-Behauptungen — wenn ein Anbieter eine bestimmte Halluzinationsrate behauptet, unabhängige Benchmarks aber andere Zahlen zeigen, werden beide dargestellt und die Abweichung wird vermerkt. Das gilt insbesondere für xAIs interne Grok-Benchmarks versus AA-Omniscience-Ergebnisse.
Benchmark-Daten und Versionen
Vectara-Snapshots sind datiert. Der ursprüngliche Datensatz wurde bis April 2025 evaluiert. Der aktualisierte Datensatz umfasst November 2025 bis Februar 2026, mit dem jüngsten Snapshot vom 25. Februar 2026. AA-Omniscience startete im November 2025 und wird aktualisiert, sobald neue Modelle erscheinen. FACTS wurde im Dezember 2025 veröffentlicht. OpenAI System Cards sind pro Release datiert.
Wenn zwei Benchmarks für dasselbe Modell unterschiedliche Zahlen zeigen, liegt das meist an unterschiedlichen Evaluierungszeitpunkten, unterschiedlichen Datensatzversionen oder unterschiedlichen Aspekten der gemessenen Faktizität. Wir markieren diese Abweichungen, statt sie zu mitteln.
Bekannte Datenlücken
Perplexity Sonar-Modelle sind weder bei AA-Omniscience noch bei Vectara gelistet. Perplexity nutzt zugrunde liegende Modelle (einschließlich GPT- und DeepSeek-Varianten), was die Zuordnung von Halluzinationen komplex macht. Ihre SimpleQA- und Search-Arena-Ergebnisse werden, wo verfügbar, einbezogen.
Claude Opus 4.6 und Sonnet 4.6 wurden im Februar 2026 veröffentlicht. AA-Omniscience-Daten erscheinen, sind aber früh. Vectara-New-Dataset-Scores sind für die 4.6-Generation noch nicht verfügbar.
GPT-5.3 hat AA-Omniscience-Daten (51,8 % Genauigkeit für die Codex-Variante), aber zum Zeitpunkt dieses Textes nur begrenzte Abdeckung in anderen Benchmarks.
Domänenspezifische Aufschlüsselungen testen bei den meisten Benchmarks allgemeines Wissen. Branchen-spezifische Halluzinationsdaten (Finanzen, Medizin, Recht) stammen primär aus spezialisierten Studien statt aus den großen Leaderboards.
Business-Kostenzahlen stammen aus Umfragen und Schätzungen statt aus verifizierten Incident-Datenbanken. Die Zahl von 67,4 Milliarden $, die Verifikationskosten pro Mitarbeiter und die Spannen pro Incident sollten als indikativ, nicht als präzise betrachtet werden.
Update-Frequenz
Monatlich: Vectara-Leaderboard-Snapshots, AA-Omniscience neue Modell-Ergänzungen, OpenAI System-Card-Updates, neue Modell-Release-Daten.
Quartalsweise: FACTS-Leaderboard-Änderungen, neue Benchmark-Einführungen, akademische Paper-Ergebnisse, regulatorische Entwicklungen (insbesondere Durchsetzung des EU AI Act in Bezug auf Genauigkeitsanforderungen).
Bei Bedarf: Große Modell-Releases, bedeutende Incident-Reports, Meilensteine bei Gerichtsurteilen und Änderungen der Benchmark-Methodik.
FAQ
Häufig gestellte Fragen zu KI-Halluzinationen
Was ist eine KI-Halluzinationsrate?
Eine KI-Halluzinationsrate misst, wie oft ein Modell falsche oder erfundene Informationen als Tatsache ausgibt. Die Rate variiert je nach Benchmark, weil unterschiedliche Tests unterschiedliche Fehlermodi messen. Vectara misst, wie oft ein Modell beim Zusammenfassen eines Dokuments erfundene Fakten hinzufügt. AA-Omniscience misst, wie oft ein Modell eine selbstbewusst falsche Antwort gibt, statt zuzugeben, dass es es nicht weiß. FACTS misst Faktizität über vier Dimensionen: Grounding, multimodal, parametrisches Wissen und Suche. Ein Modell kann gleichzeitig 0,7 % bei Vectara und 88 % bei AA-Omniscience erreichen, weil die Tests völlig unterschiedliche Dinge messen.
Welches KI-Modell hat 2026 die niedrigste Halluzinationsrate?
Es gibt keine einzelne Antwort – es hängt vollständig von der Aufgabe ab. Bei Wissensfragen, bei denen das Modell Unwissen eingestehen muss: Claude 4.1 Opus erreichte 0 % Halluzination bei AA-Omniscience, indem es die Antwort verweigerte statt zu raten. Bei Dokumentzusammenfassungen: Gemini-2.0-Flash führt den ursprünglichen Vectara-Datensatz mit 0,7 % Halluzinationsrate an. Bei multidimensionaler Faktizität: Gemini 3 Pro erzielte 68,8 im FACTS-Benchmark. Bei realistischen Konversationsaufgaben: Claude Opus 4.5 erreichte 30 % bei HalluHard mit aktivierter Websuche. Kein einzelnes Modell führt über alle Benchmarks hinweg.
Wie hoch ist Claudes Halluzinationsrate 2026?
Claudes Halluzinationsrate variiert stark nach Modellversion und Benchmark. Claude 4.1 Opus: 0 % Halluzination bei AA-Omniscience (verweigert statt zu raten), FACTS-Score 46,5. Claude Opus 4.6: 12,2 % auf dem Vectara-New-Dataset, 46,4 % Genauigkeit bei AA-Omniscience, Omniscience Index 14. Claude Opus 4.5: 45,7 % Genauigkeit bei AA-Omniscience bei 58 % Halluzinationsrate, FACTS-Score 51,3, 30 % bei HalluHard. Claude Sonnet 4.6: 10,6 % auf dem Vectara-New-Dataset, ungefähr 38 % Halluzinationsrate bei AA-Omniscience. Claude 4.5 Haiku: 25 % Halluzinationsrate bei AA-Omniscience, drittniedrigste aller getesteten Modelle. Auf dem schwierigeren Vectara-New-Dataset liegen Claude-Modelle konsistent über 10 %.
Wie hoch ist die Halluzinationsrate von GPT-5?
GPT-5.3 Codex: 51,8 % Genauigkeit bei AA-Omniscience, noch keine Vectara-Daten. GPT-5.2 (xhigh): 10,8 % auf dem Vectara-New-Dataset, 43,8 % Genauigkeit bei AA-Omniscience bei ungefähr 78 % Halluzinationsrate, FACTS-Score 61,8, HalluHard 38,2 %. GPT-5: 1,4 % auf Vectara original, über 10 % auf dem New-Dataset, 40,7 % Genauigkeit bei AA-Omniscience. GPT-4.1: 2,0 % auf Vectara original, 5,6 % auf dem New-Dataset, FACTS-Score 50,5. GPT-5.2 erzielt unter den OpenAI-Modellen den höchsten FACTS-Score (61,8), halluziniert aber bei AA-Omniscience-Hard-Knowledge-Fragen mit ungefähr 78 %.
Wie hoch ist Groks Halluzinationsrate 2026?
Grok 4: 4,8 % auf Vectara original, über 10 % auf dem New-Dataset, 41,4 % Genauigkeit bei AA-Omniscience bei 64 % Halluzinationsrate, FACTS-Score 53,6. Grok 4.1 Fast Reasoning: 20,2 % auf dem Vectara-New-Dataset (höchster Wert aller getesteten Frontier-Modelle), 72 % Halluzinationsrate bei AA-Omniscience, FACTS-Score 36,0. Grok-3: 2,1 % auf Vectara original, 5,8 % auf dem New-Dataset, 94 % Zitier-Halluzination bei CJR. Die Variante Grok 4.1 Fast Reasoning schneidet deutlich schlechter ab als Grok 4, was darauf hindeutet, dass der Reasoning-Modus Inferenzschritte hinzufügt, die bei faktischen Aufgaben zu Halluzinationen werden.
Wie hoch ist Geminis Halluzinationsrate 2026?
Gemini 3.1 Pro: 10,4 % auf dem Vectara-New-Dataset, 55,3 % Genauigkeit bei AA-Omniscience (höchster Wert aller Modelle) bei 50 % Halluzinationsrate, Omniscience Index 33 (höchster insgesamt). Gemini 3 Pro: 13,6 % auf Vectara new, 55,9 % Genauigkeit, aber 88 % Halluzination bei AA-Omniscience, FACTS-Score 68,8 (höchster insgesamt). Gemini 2.0 Flash: 0,7 % auf Vectara original (niedrigster Wert aller Modelle), 3,3 % auf dem New-Dataset. Das 3.1-Pro-Update war signifikant: Halluzination sank von 88 % auf 50 % bei nur 1 % Genauigkeitsverlust. Gemini-Modelle wissen am meisten, erfinden aber am aggressivsten, wenn sie unsicher sind.
Wie hoch ist Perplexitys Halluzinationsrate?
Perplexity Sonar Pro erzielte 37 % Zitier-Halluzination im Benchmark des Columbia Journalism Review – der niedrigste Wert aller getesteten Modelle, bedeutet aber immer noch, dass mehr als jede dritte zitierte Quelle erfundene Behauptungen enthielt. ChatGPT lag im selben Test bei 67 %. Gemini bei 76 %. Grok-3 erreichte 94 %. Perplexitys Fehlermodus ist besonders gefährlich: Die URLs, die es zitiert, sind real, aber die Informationen, die es diesen Quellen zuschreibt, sind manchmal erfunden. Es gibt keine Vectara- oder AA-Omniscience-Benchmark-Daten für Perplexity Sonar-Modelle.
Warum geben unterschiedliche Benchmarks unterschiedliche Halluzinationsraten für dasselbe KI-Modell an?
Unterschiedliche Benchmarks messen grundlegend unterschiedliche Fehlermodi. Vectara testet Zusammenfassungs-Treue. AA-Omniscience testet Wissenskalibrierung. FACTS testet multidimensionale Faktizität über Grounding, multimodale, parametrische und Suchaufgaben hinweg. CJR testet Zitiergenauigkeit. Ein Modell wie Grok-3 erzielt 2,1 % bei Vectara (hält sich gut an Quelldokumente), aber 94 % bei CJR (erfindet fast jedes Zitat). Beide Zahlen sind korrekt. Sie messen unterschiedliche Fähigkeiten. Der verantwortungsvolle Ansatz: mindestens zwei Benchmarks mit unterschiedlichen Messzielen gegenprüfen, die exakte Modellversion und Einstellungen angeben und vermerken, ob Websuche oder Reasoning-Modus aktiviert war.
Können KI-Halluzinationen vollständig eliminiert werden?
Nein. Zwei unabhängige mathematische Beweise haben gezeigt, dass Halluzination eine grundlegende Einschränkung der Sprachmodell-Architektur ist. Es ist kein Engineering-Problem, das nur auf einen Fix wartet. Best-Case-Halluzinationsraten sind über vier Jahre bei einfachen Zusammenfassungsaufgaben von 21,8 % auf 0,7 % gefallen. Aber bei schwierigeren Aufgaben – juristischen Fragen (18,7 % im Schnitt), medizinischen Anfragen (15,6 %), Wissensfragen, bei denen das Modell auf seine eigenen Trainingsdaten angewiesen ist – bleiben die Raten bei allen Modellen hoch. Die Forschungsgemeinschaft hat sich von der Eliminierung von Halluzinationen hin zum Management des Halluzinationsrisikos durch Erkennung, Kennzeichnung, Eindämmung und Cross-Validation verlagert. Websuche ist der größte einzelne Reduzierer und senkt Halluzinationsraten um 73–86 %, wenn sie aktiviert ist.
Wie viel kosten KI-Halluzinationen Unternehmen?
Die globalen Unternehmensverluste durch KI-Halluzinationen erreichten 2024 geschätzt 67,4 Milliarden $. 47 % der Führungskräfte gaben an, große Entscheidungen auf Basis unverifizierter KI-generierter Inhalte getroffen zu haben. 66 % der Nutzer verlassen sich auf KI-Ausgaben, ohne deren Genauigkeit zu bewerten. Es gibt 944+ dokumentierte Rechtsfälle mit KI-generierten Falschinformationen. Domänenspezifische Kosten reichen von 18.000 $ pro Customer-Service-Incident bis zu 2,4 Millionen $ in Fällen medizinischer Behandlungsfehler. Die FDA hat über 1.350 KI-gestützte Medizinprodukte zugelassen, wobei 60 Geräte in 182 Rückrufen involviert waren.
Reduziert die Nutzung mehrerer KI-Modelle Halluzinationen?
Die Forschung stützt dies zunehmend. Unterschiedliche KI-Modelle halluzinieren selten dieselben falschen Informationen, weil sie unterschiedliche Trainingsdaten, unterschiedliche Architekturen und unterschiedliche blinde Flecken haben. Eine Studie zum UAF-Framework maß eine 8%ige Genauigkeitsverbesserung durch Multi-Modell-Ensemble-Ansätze. Modell-übergreifende Meinungsverschiedenheit fängt Erfindungen insbesondere deshalb ab, weil sich die Fehlermodi nicht überlappen. Wenn drei Modelle dieselbe Frage analysieren und zwei dem dritten widersprechen, ist die Meinungsverschiedenheit selbst ein Signal, dass eine Behauptung menschlich geprüft werden muss. Das ist das Prinzip hinter Multi-KI-Orchestrierungsplattformen, die Fragen gleichzeitig an mehrere Frontier-Modelle routen. Sehen Sie, wie Suprmind diesen Ansatz nutzt →
Referenzen und Quellen
Benchmarks und Leaderboards
- Vectara. „Hallucination Leaderboard (HHEM-2.3).“ GitHub-Repository. Zuletzt aktualisiert am 25. Februar 2026. github.com/vectara/hallucination-leaderboard
- Artificial Analysis. „AA-Omniscience: Knowledge and Hallucination Benchmark.“ November 2025. artificialanalysis.ai/evaluations/omniscience
- Google DeepMind. „FACTS Grounding: Evaluating and Improving Factuality in Large Language Models.“ FACTS Benchmark Suite, Dezember 2025.
- OpenAI. „SimpleQA: Measuring Short-form Factuality.“ OpenAI Research, 2024.
- Müller, R. et al. „HalluHard: A Challenging Hallucination Benchmark for Realistic Conversations.“ 2025. the-decoder.com
- Columbia Journalism Review. „AI Citation Accuracy Study.“ März 2025.
- OpenAI. „HALOGEN: Evaluating Hallucination of Generative Foundation Models.“ arXiv, 2024. arxiv.org/abs/2404.00730
Model System Cards und Anbieter-Ankündigungen
- OpenAI. „GPT-5 System Card.“ August 2025. W&B summary
- OpenAI. „Introducing GPT-5.2.“ Dezember 2025. openai.com
- OpenAI. „GPT-5.3 Instant: Smoother, more useful everyday conversations.“ März 2026. openai.com
- OpenAI. „System Card zu o3 und o4-mini.“ 2025. openai.com (PDF)
- OpenAI. „GPT-5 halluziniert weniger.“ Mashable, August 2025. mashable.com
- Anthropic. „Vorstellung von Claude Sonnet 4.6.“ Februar 2026. anthropic.com
- Anthropic. „Claude Opus 4.5: Benchmarks und Analyse.“ Artificial Analysis, November 2025. artificialanalysis.ai
- Artificial Analysis. „Gemini 3.1 Pro Preview: Der neue Spitzenreiter in der KI.“ Februar 2026. artificialanalysis.ai
- Artificial Analysis. „Gemini 3 Flash — Alles, was Sie wissen müssen.“ Dezember 2025. artificialanalysis.ai
- Digital Applied. „Grok 4.1: Vollständiger Leitfaden zu xAI Emotional AI.“ 2026. digitalapplied.com
- Perplexity AI. „Perplexity Sonar dominiert die neue Evaluation der Suchlandschaft.“ perplexity.ai
- Perplexity AI. „Vorstellung der Sonar Pro API.“ perplexity.ai
Akademische Forschung — Unmöglichkeit und Theorie von Halluzinationen
- Xu, Z. et al. „Halluzination ist unvermeidlich: Eine angeborene Einschränkung großer Sprachmodelle.“ arXiv, 2024. arxiv.org/abs/2401.11817
- Karpowicz, M. „Zur grundlegenden Unmöglichkeit der Kontrolle von Halluzinationen in großen Sprachmodellen.“ arXiv, 2025. arxiv.org/abs/2506.06382v3
- OpenAI / Computerworld. „OpenAI räumt ein, dass KI-Halluzinationen mathematisch unvermeidlich sind.“ computerworld.com
Akademische Forschung — Techniken zur Reduzierung von Halluzinationen
- Dhuliawala, S. et al. „Chain-of-Verification reduziert Halluzinationen in großen Sprachmodellen.“ ACL 2024 Findings. aclanthology.org
- Luo, Y. et al. „Uncertainty-Aware Super Mind: Ein Ensemble-Framework zur Minderung von Halluzinationen in großen Sprachmodellen.“ Amazon / ACM WWW 2025. arxiv.org/abs/2503.05757
- Zhou, Y. et al. „Weiß ich das wirklich? Lernen faktischer Selbstverifikation für LLMs (VeriFY).“ ICML 2025. arxiv.org
- Singh, A. et al. „Kombination von CoT, RAG, Self-Consistency und Self-Verification.“ arXiv, 2025. arxiv.org/abs/2505.09031
- Li, J. et al. „Minderung von Halluzinationen in großen Sprachmodellen (LLMs): Überblicksstudie.“ arXiv, 2025. arxiv.org
Akademische Forschung — Ensemble- und Multi-Modell-Ansätze
- Schoenegger, P. et al. „Wisdom of the silicon crowd: Die Ensemble-Prognosefähigkeiten von LLMs konkurrieren mit der menschlichen Menge.“ PNAS / PMC, 2025. pmc.ncbi.nlm.nih.gov
Kritik an Benchmark-Methodik
- Hilgard, S. „Gaming TruthfulQA: Einfache Heuristiken deckten Schwächen des Datensatzes auf.“ turntrout.com
- Li, J. et al. „HaluEval: Ein großskaliger Benchmark zur Bewertung von Halluzinationen.“ arXiv. Referenzierte Kritik: durch Antwortlängen-Heuristik lösbar.
Branchenstudien und Berichte
- AllAboutAI. „KI-Halluzinationsstatistiken und Forschungsbericht 2025–2026.“ Primäre Kompilationsquelle für domänenspezifische Raten, Kennzahlen zu Geschäftsauswirkungen und historische Verlaufsdaten.
- Deloitte. „Global AI Survey 2025.“ Quelle für Statistiken zur Entscheidungsfindung von Führungskräften (47 % trafen Entscheidungen auf Basis nicht verifizierter KI-Inhalte).
- Forrester. „Enterprise AI Cost Analysis 2025.“ Quelle für Daten zu Verifizierungskosten pro Mitarbeitendem (14.200 $/Jahr, 4,3 Stunden/Woche).
- Testlio. „AI Testing and Quality Report 2025.“ Quelle für Statistiken zu KI-Bugs in Produktion (82 % durch Halluzinationen, 39 % Nacharbeitsquote bei Chatbots).
- Gartner. „Hallucination Detection Tools Market Report 2025.“ Quelle für die Kennzahl von 318 % Marktwachstum und insgesamt 12,8 Mrd. $ Investitionen.
Daten zu Halluzinationen im Rechtsbereich
- Stanford RegLab / Stanford Human-Centered AI Institute (HAI). „Studie zu KI-Halluzinationen im Rechtsbereich.“ hai.stanford.edu
- Charlotin, D. „Datenbank zu Fällen von KI-Halluzinationen.“ Sciences Po / HEC Paris. 1.200+ dokumentierte globale Fälle (April 2026), davon etwa 800 vor US-Gerichten. damiencharlotin.com/hallucinations
- Business Insider. Tracker zu Gerichtsurteilen: 10 Fälle (2023), 37 (2024), 73 (erste 5 Monate 2025), 50+ (allein Juli 2025).
Daten zu Halluzinationen im Gesundheitswesen
- ECRI. „Top 10 Health Technology Hazards for 2025.“ KI-Risiken auf Platz 1.
- MedRxiv. „Studie zu Halluzinationen in medizinischen Fällen 2025.“ 64,1 % ohne Mitigation, 43,1 % mit Mitigation, GPT-4o von 53 % auf 23 %.
- NIH / PMC. „Deutliche Reduktion der Halluzinationsraten mit GPT-5.“ pmc.ncbi.nlm.nih.gov
- FDA. Daten zu KI-gestützten Medizinprodukten: 1.357 zugelassen, 60 in 182 Rückrufen involviert, 43 % innerhalb des ersten Jahres.
Daten zu Halluzinationen im Finanzbereich
- SEC-Durchsetzungsdaten: 12,7 Mio. $ an Bußgeldern wegen KI-Falschdarstellungen, 2024–2025.
- Branchenberichte (aggregiert): 78 % der Finanzunternehmen setzen KI ein; 15–25 % Halluzinationen ohne Schutzmaßnahmen; 50.000 $–2,1 Mio. $ pro Vorfall.
Akademische Integrität
- GPTZero / Fortune. „NeurIPS-Forschungsarbeiten enthielten 100+ KI-halluzinierte Zitate, die das Peer-Review überstanden.“ Januar 2026. fortune.com
Erkennungstools
- AIMultiple. „Benchmark zu Tools zur Erkennung von KI-Halluzinationen 2026.“ W&B Weave 91 %, Arize Phoenix 90 %, Comet Opik 72 %. research.aimultiple.com
- Future AGI. „Top 5 Tools zur Erkennung von KI-Halluzinationen im Jahr 2025.“ futureagi.com
Vectara Deep-Dive-Studien
- Vectara. „DeepSeek-R1 halluziniert stärker als DeepSeek-V3.“ vectara.com
- Vectara. „Warum halluziniert Deepseek-R1 so stark?“ vectara.com
Modellspezifische Daten (zusätzlich)
- Reddit / AA-Omniscience-Community-Daten. „Sonnet 4.6 reduziert Halluzinationen im Vergleich zu Opus deutlich.“ reddit.com
- Incremys. „Perplexity-KI-Statistiken: Trends 2025–2026 und SEO-Auswirkungen.“ incremys.com
- Vellum. „GPT-5 Benchmarks.“ HealthBench Deep-Dive. vellum.ai
- Tech Transformation. „OpenAIs Reasoning-Modelle o3 und o4-mini zeigen erhöhte Halluzinationen.“ tech-transformation.com
- Blockchain.news. „PersonQA-Benchmark zeigt steigende Halluzinationsraten in OpenAI-Modellen.“ blockchain.news
- Voronoi App. „Führende KI-Modelle zeigen anhaltende Halluzinationen trotz Genauigkeitsgewinnen.“ voronoiapp.com
Regulatorische Referenzen
- EU-KI-Verordnung, Artikel 15. „Hochrisiko-KI-Systeme müssen ein angemessenes Maß an Genauigkeit erreichen und über den gesamten Lebenszyklus hinweg konsistent funktionieren.“ EUR-Lex.
- NIST. „AI Risk Management Framework (AI RMF 1.0).“ Einschließlich Begleitprofil AI 600-1, genehmigt im Juli 2024.
Ergänzungen April 2026
- Stanford HAI. „2026 AI Index Report — Kapitel Responsible AI.“ Stanford Human-Centered AI Institute, veröffentlicht am 13. April 2026. hai.stanford.edu/ai-index/2026-ai-index-report
- The Ethics Reporter. „Die Seuche breitet sich aus: Wie 1.200 Fälle von KI-Halluzinationen das gescheiterte Register belegen.“ 12. April 2026. theethicsreporter.com
- OpenAI. „HealthBench Professional — Kliniker-tauglicher Gesundheits-KI-Benchmark.“ Veröffentlicht am 22. April 2026. openai.com (PDF)
- Suprmind. „Multi-Model Divergence Index — Ausgabe April 2026.“ Veröffentlicht im April 2026. suprmind.ai/hub/multi-model-ai-divergence-index
- Suprmind. „DMI Ausgabe April 2026 — Öffentliches CSV-Bundle (12 Dateien: Widersprüche, Korrekturen, Insights, Schweregrad, Domain-Aufschlüsselungen).“ suprmind.ai/hub/multi-model-ai-divergence-index/#downloads
- Kingy AI. „GPT-5.5 vs. Claude Opus 4.7: Ein Benchmark-für-Benchmark-Leitfaden zur neuen Frontier.“ 22. April 2026. kingy.ai
Vertrauen Sie bei wichtigen Entscheidungen nicht nur einer einzigen KI.
Fünf Frontier-Modelle. Ein Gespräch. Jede Antwort wird gegengeprüft. Sehen Sie, warum Profis, die es sich nicht leisten können, falsch zu liegen, auf Multi-Modell-Validierung umsteigen.