



Última actualización el 26 de abril de 2026
Las referencias completas de datos sobre alucinaciones de IA. Cifras brutas de Vectara,
AA-Omniscience, FACTS, tarjetas de sistema de OpenAI y más de 50 fuentes.
Actualizado mensualmente.
La actualización de abril de 2026 añadió: datos del Stanford AI Index, Claude Opus 4.7, Grok 4.20,
la paradoja de GPT-5.5, escalada de casos legales e integración del Multi-Model Divergence Index
67.400 M$
Pérdidas empresariales globales por alucinaciones de IA en 2024 [31]
0.7%
Mejor tasa de alucinación en resúmenes básicos (Gemini-2.0-Flash) [1]
88%
Tasa de alucinación cuando Gemini 3 Pro no conoce la respuesta (Gemini 3.1 Pro mejoró esto al 50 %) [2]
4 / 40
Modelos que obtuvieron una puntuación mejor que el azar en preguntas de conocimiento complejo [2]
Del Multi-Model Divergence Index — Abril de 2026
2.63
Perspectivas únicas por turno multimodelo: puntos de vista que una sola IA no detectó (1.324 turnos de producción) [61]
51.4%
De las respuestas de alta confianza de Gemini fueron contradichas por otro modelo; la confianza no es precisión [61]
26.4%
Tasa de confianza contradicha en escenarios críticos de Claude: la más baja de cinco proveedores [61]
72.1%
De las preguntas financieras revelaron desacuerdos entre modelos; los dominios de mayor riesgo son los que más divergen [61]
Todos los modelos principales de IA alucinan. La IA generativa, por su propio diseño, no puede estar libre de alucinaciones, pero el riesgo puede mitigarse antes de que afecte a su toma de decisiones y le cueste dinero. Vea cómo la verificación multimodelo funciona como estrategia de mitigación.
Esta página rastrea las tasas de alucinación a través de seis comparativas, cubre todos los modelos de frontera desde GPT-5.5 hasta Claude 4.7, pasando por Gemini 3.1 y Grok 4.20, y presenta los datos de forma objetiva. Las cifras no coinciden entre sí, y explicamos por qué eso importa más que cualquier clasificación individual.
Referencia universal de alucinaciones entre comparativas (abril de 2026)
Cómo leer esta tabla
Cada cifra a continuación proviene de una comparativa diferente que mide un aspecto distinto de la alucinación. Una alucinación baja en Vectara + alta en AA-Omniscience significa que el modelo es bueno resumiendo pero malo admitiendo ignorancia. Una precisión alta en FACTS + baja en AA-Omniscience significa que el modelo es preciso con herramientas pero intenta responder demasiadas preguntas. Ninguna columna cuenta la historia completa. Compare al menos dos.
Guía de columnas:
- Vectara (Antiguo): Fidelidad del resumen en documentos cortos. Menor = mejor.
- Vectara (Nuevo): Fidelidad del resumen en documentos de longitud empresarial. Menor = mejor.
- AA-Omni Acc: Precisión en preguntas de conocimiento complejo en 42 temas. Mayor = mejor.
- AA-Omni Hall: Frecuencia con la que el modelo da respuestas incorrectas en lugar de negarse a responder. Menor = mejor.
- AA-Omni Index: Puntuación combinada de fiabilidad del conocimiento (-100 a +100). Mayor = mejor.
- FACTS: Veracidad multidimensional en fundamentación, multimodal, paramétrica y búsqueda. Mayor = mejor.
- HalluHard: Tasa de alucinación en conversaciones realistas. Menor = mejor.
- CJR Citation: Tasa de alucinación de citas (fuentes de noticias). Menor = mejor.
Clasificación de tasas de alucinación de modelos de IA de frontera
| Modelo | Proveedor | Vectara (Antiguo) | Vectara (Nuevo) | AA-Omni Acc | AA-Omni Hall | AA-Omni Index | FACTS | HalluHard | Citas CJR |
| GPT-5.3 Codex | OpenAI | – | – | 51.8% | – | – | – | – | – |
| GPT-5.5 (muy alto) | OpenAI | – | – | 57% | 86% | 20 | – | – | – |
| GPT-5.2 (muy alto) | OpenAI | – | 10.8% | 43.8% | ~78 % | – | 61.8 | 38.2% | – |
| GPT-5 | OpenAI | 1.4% | >10 % | 40.7% | – | – | 61.8 | – | – |
| GPT-5.1 | OpenAI | – | – | 37.6% | 81% | Positivo | 49.4 | – | – |
| GPT-4.1 | OpenAI | 2.0% | 5.6% | – | – | – | 50.5 | – | – |
| o3-mini-high | OpenAI | 0.8% | 4.8% | – | – | – | 52.0 | – | – |
| Claude 4.1 Opus | Anthropic | – | – | – | 0% | – | 46.5 | – | – |
| Claude Opus 4.6 | Anthropic | – | 12.2% | 46.4% | – | 14 | – | – | – |
| Claude Opus 4.7 | Anthropic | – | – | – | 36% | 26 | – | – | – |
| Claude Opus 4.5 | Anthropic | – | – | 45.7% | 58% | Negativo | 51.3 | 30% | – |
| Claude Sonnet 4.6 | Anthropic | – | 10.6% | 40.0% | ~38 % | – | – | – | – |
| Claude Sonnet 4.5 | Anthropic | – | >10 % | – | 48% | – | 49.1 | – | – |
| Claude 3.7 Sonnet | Anthropic | 4.4% | – | – | – | – | – | – | – |
| Claude 4.5 Haiku | Anthropic | – | – | – | 25% | – | – | – | – |
| Gemini 3.1 Pro | – | 10.4% | 55.3% | 50% | 33 | – | – | – | |
| Gemini 3 Pro | – | 13.6% | 55.9% | 88% | 16 | 68.8 | – | – | |
| Gemini 3 Flash | – | – | 54.0% | 91% | – | – | – | – | |
| Gemini 2.5 Pro | – | 7.0% | – | – | – | 62.1 | – | – | |
| Gemini 2.0 Flash | 0.7% | 3.3% | – | – | – | – | – | – | |
| Grok 4 | xAI | 4.8% | >10 % | 41.4% | 64% | Positivo | 53.6 | – | – |
| Grok 4.1 Fast | xAI | – | 20.2% | – | 72% | – | 36.0 | – | – |
| Grok 4.20 (Reasoning) | xAI | – | – | – | 17% | – | – | – | – |
| Grok-3 | xAI | 2.1% | 5.8% | – | – | – | – | – | 94% |
| Perplexity Sonar Pro | Perplexity | – | – | – | – | – | – | – | 37% |
| DeepSeek-V3 | DeepSeek | 3.9% | 6.1% | – | – | – | – | – | – |
| DeepSeek-R1 | DeepSeek | 14.3% | 11.3% | – | 83% | – | – | – | – |
| Llama 4 Maverick | Meta | 4.6% | – | – | 87.6% | – | – | – | – |
Fuentes: Vectara HHEM Leaderboard (capturas de abril de 2025 + feb. de 2026 + 20 de abril de 2026) [1], Artificial Analysis AA-Omniscience (nov. de 2025 – abril de 2026) [2], Google DeepMind FACTS Benchmark (dic. de 2025) [3], HalluHard Benchmark (2025) [5], Columbia Journalism Review (marzo de 2025) [6]. Los guiones indican que no hay datos publicados en esa comparativa para ese modelo.
Hallazgos de referencia rápida
Tasa de alucinación más baja (tareas de conocimiento): Claude 4.1 Opus – 0 % en AA-Omniscience (el modelo se niega a responder cuando no está seguro)
Mayor mejora individual: Gemini 3.1 Pro – la alucinación cayó 38 puntos porcentuales (del 88 % al 50 %) con una pérdida de precisión del 1 %
Tasa de alucinación más baja (cuando los modelos intentan responder): Grok 4.20 (Reasoning) – 17 % en AA-Omniscience (abril de 2026)
Mayor variable en todos los modelos: El acceso a la búsqueda web reduce la alucinación entre un 73 % y un 86 % cuando está activado
Mejor precisión de citas: Perplexity Sonar Pro – 37 % de alucinación en CJR (la más baja, pero aún alta)
Tasa de alucinación más baja (resumen): Gemini-2.0-Flash – 0,7 % en el conjunto de datos original de Vectara
Mejor en conversaciones realistas: Claude Opus 4.5 – 30 % en HalluHard (con búsqueda web)
Mejor índice de fiabilidad del conocimiento: Gemini 3.1 Pro – índice 33 en AA-Omniscience
Puntuación de veracidad más alta (multidimensional): Gemini 3 Pro – 68,8 en FACTS
Vea cómo el enfoque multi-IA de Suprmind mitiga las alucinaciones
Suprmind reduce las alucinaciones al situar cinco modelos de frontera en la misma conversación estructurada, donde desafían las afirmaciones de los demás, detectan contradicciones, discrepan y ponen a prueba las conclusiones antes de que el resultado llegue a su trabajo.
Cuando los modelos de IA discrepan, ese desacuerdo revela la complejidad y segmentos a menudo pasados por alto del tema o problema.
Suprmind lo saca a la luz, lo cuantifica y, en tres clics, lo convierte en un entregable profesional, para que las preguntas difíciles se respondan antes de tomar la decisión.
El desacuerdo es la función.
VÉALO USTED MISMO
Vea el modo Sequential de Suprmind en un escenario sencillo
Esta demostración interactiva de IA multi-modelo dura unos 90 segundos. Explore la barra lateral derecha y el Master Document mientras se reproduce. Desplácese hacia abajo para pausar; vuelva a desplazarse cuando esté listo y continuará donde lo dejó.
Tabla de contenidos
1. ¿Qué es una alucinación de IA?
2. El problema de las comparativas
3. Clasificación de alucinaciones de Vectara
5. Comparativa FACTS (Google DeepMind)
6. Perfiles de alucinación de modelos de frontera
7. Comparaciones directas entre modelos
8. Tasas de alucinación por dominio específico
9. Estadísticas de impacto empresarial
10. La paradoja del razonamiento
11. Por qué la alucinación cero es matemáticamente imposible
12. Qué reduce realmente la alucinación
14. Herramientas de detección de alucinaciones
16. Metodología y cómo leer estos datos
Escuche la investigación completa (51 min)
¿Qué es una alucinación de IA?
En lenguaje sencillo
Una alucinación de IA ocurre cuando un modelo de IA inventa algo y lo presenta como un hecho. No señala incertidumbre. No dice «estoy adivinando». Ofrece estadísticas fabricadas, casos legales inventados o artículos de investigación inexistentes con la misma confianza que utiliza para la aritmética básica. El resultado se lee perfectamente. Eso es lo que lo hace peligroso.
La definición técnica
La alucinación se refiere al contenido generado que no está fundamentado en la información proporcionada o en la realidad fáctica. Existen dos tipos:
Alucinación intrínseca (fallo de fidelidad): El modelo contradice la información que se le dio explícitamente. Entréguele un contrato y pídale un resumen; añade cláusulas que no existen en el documento original.
Alucinación extrínseca (fallo de veracidad): El modelo genera información que no puede verificarse con ninguna fuente conocida. Inventa hechos, estadísticas, citas o eventos desde cero. No se contradijo ningún material de origen porque no se consultó ninguno.
La paradoja de la confianza
Investigadores del MIT descubrieron algo inquietante en enero de 2025: los modelos de IA utilizan un lenguaje más seguro cuando alucinan que cuando exponen hechos. Los modelos tenían un 34 % más de probabilidades de usar frases como «definitivamente», «ciertamente» y «sin duda alguna» al generar información incorrecta.
Cuanto más equivocada está la IA, más segura suena.
Por qué sucede
Los modelos de lenguaje extensos son motores de predicción, no bases de conocimiento. Generan texto prediciendo el siguiente token estadísticamente más probable basándose en patrones de los datos de entrenamiento. No entienden la verdad. Predicen la verosimilitud.
Cuando el modelo encuentra un vacío en sus datos de entrenamiento o se enfrenta a una consulta ambigua, llena el vacío con algo verosímil en lugar de admitir que no lo sabe. La arquitectura no tiene un mecanismo para decir «no estoy seguro»; simplemente elige la siguiente palabra más probable.
Y esto no es un error que se corregirá en la próxima actualización. Dos pruebas matemáticas independientes han demostrado ahora que la alucinación es una limitación fundamental y demostrable de la arquitectura. No es una deficiencia de ingeniería. Es una certeza matemática. (Más sobre esto en la sección Imposibilidad matemática a continuación). [20][21]
El problema de las comparativas: por qué las cifras se contradicen entre sí
Antes de analizar cualquier dato sobre alucinaciones, debe entender por qué las diferentes comparativas arrojan puntuaciones radicalmente distintas para el mismo modelo.
Grok-3 obtiene un 2,1 % en la comparativa de resumen de Vectara. Excelente. Ese mismo modelo obtiene un 94 % en la prueba de precisión de citas de la Columbia Journalism Review. Catastrófico. El mismo modelo, el mismo periodo de tiempo, conclusiones opuestas.
Esto no es un error. Se están midiendo cosas diferentes. Y tratar cualquier comparativa individual como «la tasa de alucinación» le inducirá a error.
La siguiente matriz resume lo que cada comparativa evalúa realmente. Haga clic en el nombre de cualquier comparativa para ir a su sección dedicada.
| Benchmark | Qué mide | Ideal para | No apto para |
| Vectara HHEM | Fidelidad del resumen: ¿añade el modelo hechos no respaldados al resumir documentos de origen? | Flujos de RAG, preguntas y respuestas sobre documentos, búsqueda en bases de conocimiento | Preguntas de conocimiento abiertas |
| AA-Omniscience | Cuando el modelo no conoce una respuesta, ¿lo admite o fabrica una? El Omniscience Index penaliza las respuestas incorrectas y premia la negativa a responder. | Trabajo de asesoría de alto riesgo: legal, médico, financiero | Tareas de resumen o fundamentadas |
| FACTS | Veracidad multidimensional en fundamentación, multimodal, paramétrica y búsqueda. Cada dimensión se puntúa por separado. | Comparar dónde son fuertes o débiles los modelos según el tipo de tarea | Producir una cifra única de tasa de alucinación |
| SimpleQA / PersonQA | Preguntas fácticas cortas y precisión sobre personas reales. Los modelos de razonamiento más nuevos suelen rendir peor que sus predecesores aquí. | Pruebas rápidas de veracidad en preguntas directas | Consultas complejas, de varios pasos o de dominios específicos |
| HalluHard | Tasa de alucinación en entornos conversacionales realistas. Incluso el mejor modelo sigue alucinando el 30 % de las veces. | Predecir tasas del mundo real en aplicaciones de chat de producción | Comparaciones de modelos controladas y reproducibles |
| CJR Citation | Si los modelos de IA atribuyen correctamente la información a las fuentes citadas. Modo de fallo: URL reales con contenido fabricado adjunto. | Investigación, periodismo, cualquier tarea de atribución de fuentes | Evaluación de conocimiento general o resúmenes |
Fuentes: Vectara HHEM [1], AA-Omniscience [2], FACTS [3], SimpleQA/PersonQA [4], HalluHard [5], Estudio de citas de CJR [6]
Dos comparativas que se deben ignorar
TruthfulQA fue una vez el estándar de oro. Ahora está parcialmente saturado: los modelos han sido entrenados con sus preguntas. Peor aún, los investigadores demostraron que un simple árbol de decisiones puede obtener un 79,6 % en la opción múltiple de TruthfulQA sin siquiera ver la pregunta formulada, solo explotando patrones estructurales en el formato de las respuestas. Citar puntuaciones de TruthfulQA para modelos de 2025-2026 no es fiable. [29]
HaluEval tiene un problema similar. Un clasificador basado en la longitud logra una precisión del 93,3 % en HaluEval QA simplemente marcando como alucinadas las respuestas de más de 27 caracteres. La comparativa mide la longitud de la respuesta más que la veracidad. [30]
La conclusión práctica
Ninguna comparativa individual le ofrece «la tasa de alucinación» de ningún modelo. Si alguien cita una sola cifra, o bien está simplificando por conveniencia o está seleccionando datos a conveniencia para marketing.
El enfoque responsable: contrastar al menos dos comparativas que midan cosas diferentes (una tarea fundamentada como Vectara, una tarea de conocimiento abierta como AA-Omniscience), especificar la versión exacta del modelo y las condiciones de llamada, y señalar si el acceso a herramientas estaba activado. Las secciones que siguen hacen exactamente eso.
Clasificación de alucinaciones de IA de Vectara (HHEM)
La clasificación de Vectara es la comparativa de alucinaciones más citada en la industria. Mide la fidelidad del resumen: dado un documento de origen, ¿el resumen del modelo se ciñe a lo que realmente hay en el documento o añade hechos no respaldados? Esto lo convierte en un indicador directo de cómo se comporta la IA en flujos de RAG, herramientas de búsqueda empresarial y flujos de trabajo de análisis de documentos. La clasificación existe en dos versiones, y la brecha entre ellas cuenta una historia importante. [1]
Conjunto de datos original — ~1.000 documentos (abril de 2025)
Este es el conjunto de datos al que hacen referencia la mayoría de los artículos cuando citan tasas de alucinación. Los documentos son relativamente cortos y las tareas de resumen son directas.
| Modelo | Proveedor | Tasa de alucinación | Consistencia fáctica |
| Gemini-2.0-Flash-001 | 0.7% | 99.3% | |
| Gemini-2.0-Pro-Exp | 0.8% | 99.2% | |
| o3-mini-high | OpenAI | 0.8% | 99.2% |
| Gemini-2.5-Pro-Exp | 1.1% | 98.9% | |
| GPT-4.5-Preview | OpenAI | 1.2% | 98.8% |
| Gemini-2.5-Flash-Preview | 1.3% | 98.7% | |
| o1-mini | OpenAI | 1.4% | 98.6% |
| GPT-5 / ChatGPT-5 | OpenAI | 1.4% | 98.6% |
| GPT-4o | OpenAI | 1.5% | 98.5% |
| GPT-4o-mini | OpenAI | 1.7% | 98.3% |
| GPT-4-Turbo | OpenAI | 1.7% | 98.3% |
| GPT-4 | OpenAI | 1.8% | 98.2% |
| antgroup/finix_s1_32b | Ant Group | 1.8% | 98.2% |
| Grok-2 | xAI | 1.9% | 98.1% |
| GPT-4.1 | OpenAI | 2.0% | 98.0% |
| Grok-3-Beta | xAI | 2.1% | 97.8% |
| GPT-5.4-nano | OpenAI | 3.1% | 96.9% |
| Claude-3.7-Sonnet | Anthropic | 4.4% | 95.6% |
| Claude-3.5-Sonnet | Anthropic | 4.6% | 95.4% |
| o4-mini | OpenAI | 4.6% | 95.4% |
| Llama-4-Maverick | Meta | 4.6% | 95.4% |
| Grok-4 | xAI | 4.8% | ~95,2 % |
| Claude-3.5-Haiku | Anthropic | 4.9% | 95.1% |
| Gemma-4-26B | 5.2% | 94.8% | |
| DeepSeek-V3.2-Exp | DeepSeek | 5.3% | 94.7% |
| Qwen3-14B | Qwen/Alibaba | 5.4% | 94.6% |
| GPT-5.4-mini | OpenAI | 5.5% | 94.5% |
| Claude-3-Opus | Anthropic | 10.1% | 89.9% |
| DeepSeek-R1 | DeepSeek | 14.3% | 85.7% |
Fuente: Vectara HHEM Leaderboard, repositorio de GitHub, conjunto de datos de abril de 2025 (última actualización el 20 de abril de 2026 con nuevas incorporaciones de modelos, incluyendo finix_s1_32b de Ant Group liderando con un 1,8 %) [1]
En este conjunto de datos, las cifras parecen alentadoras. Los modelos Gemini de Google dominan los tres primeros puestos. La familia GPT de OpenAI se agrupa entre el 0,8 % y el 2,0 %. Incluso los de peor rendimiento se mantienen por debajo del 15 %.
Actualización de abril de 2026: El modelo finix_s1_32b de Ant Group se unió a la clasificación con una tasa de alucinación del 1,8 %, siendo la primera vez que un modelo empresarial chino compite por la primera posición en el conjunto de datos original de Vectara. El GPT-5.4 nano de OpenAI (3,1 %) entró con una tasa notablemente superior a la de GPT-4.1 (2,0 %), reforzando el patrón de que las variantes de OpenAI más pequeñas y recientes suelen alucinar más que los modelos base anteriores, lo cual es coherente con el coste del razonamiento analizado en la Sección 10. [1]
Pero este conjunto de datos es fácil. Los documentos son cortos, las tareas de resumen son nítidas y el mundo real no es ninguna de las dos cosas.
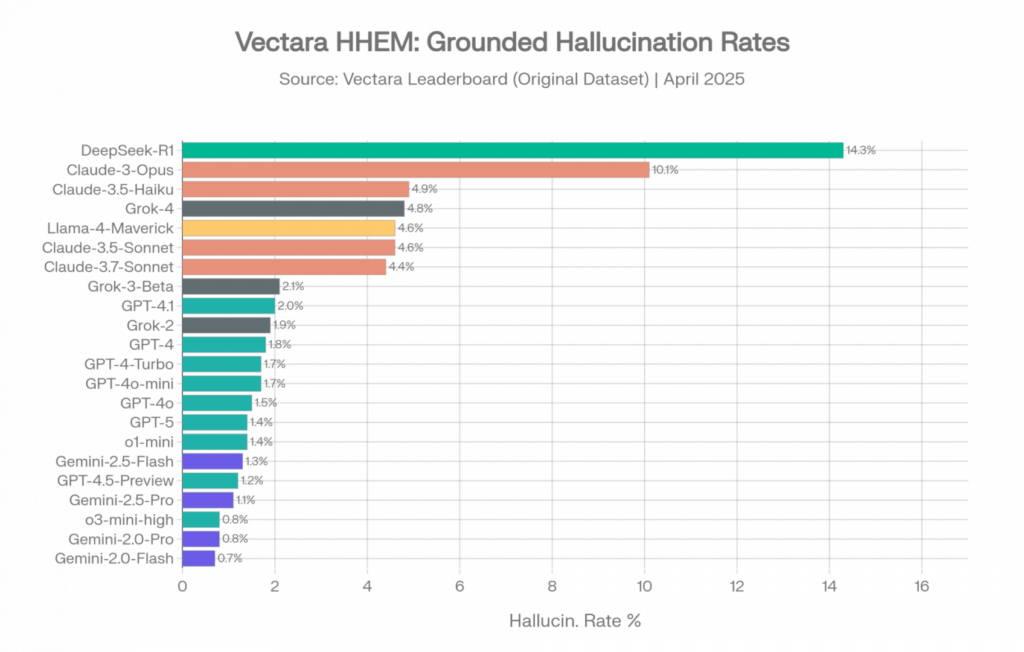
Vectara HHEM Leaderboard: Clasificación completa de modelos con código de colores por proveedor en el conjunto de datos original. Fuente: Vectara [1]
Nuevo conjunto de datos — 7.700 artículos (noviembre de 2025 – febrero de 2026)
Vectara lanzó una comparativa renovada a finales de 2025 con documentos más largos (hasta 32.000 tokens) que abarcan derecho, medicina, finanzas, tecnología y educación. Esta versión refleja mejor a lo que se enfrentan realmente los sistemas de IA empresariales.
Las tasas aumentaron de forma generalizada:
| Modelo | Proveedor | Tasa de alucinación |
| Gemini-2.5-Flash-Lite | 3.3% | |
| Mistral-Large | Mistral | 4.5% |
| DeepSeek-V3.2-Exp | DeepSeek | 5.3% |
| GPT-4.1 | OpenAI | 5.6% |
| Grok-3 | xAI | 5.8% |
| DeepSeek-R1-0528 | DeepSeek | 7.7% |
| Claude Sonnet 4.5 | Anthropic | >10 % |
| GPT-5 | OpenAI | >10 % |
| Grok-4 | xAI | >10 % |
| Gemini-3-Pro | 13.6% |
Fuente: Vectara Hallucination Leaderboard, nuevo conjunto de datos, noviembre de 2025 [1]
Captura del 25 de febrero de 2026 — Últimas incorporaciones de modelos
La captura más reciente de Vectara añade los modelos de frontera más nuevos a la evaluación del nuevo conjunto de datos:
| Modelo | Proveedor | Tasa de alucinación |
| o3-mini-high | OpenAI | 4.8% |
| GPT-4.1 | OpenAI | 5.6% |
| Grok-3 | xAI | 5.8% |
| DeepSeek-V3 | DeepSeek | 6.1% |
| Command R+ | Cohere | 6.9% |
| Gemini 2.5 Pro | 7.0% | |
| Llama 4 Scout | Meta | 7.7% |
| GPT-5.2-low | OpenAI | 8.4% |
| Gemini 3.1 Pro Preview | 10.4% | |
| Claude Sonnet 4.6 | Anthropic | 10.6% |
| GPT-5.2-high | OpenAI | 10.8% |
| DeepSeek-R1 | DeepSeek | 11.3% |
| Claude Opus 4.6 | Anthropic | 12.2% |
| Grok-4-fast-reasoning | xAI | 20.2% |
Fuente: Vectara HHEM Leaderboard, captura del informe de investigación del 25 de febrero de 2026 [1]
El coste del razonamiento
El nuevo conjunto de datos reveló algo contraintuitivo: los modelos de razonamiento —aquellos comercializados como los más capaces— rinden sistemáticamente peor en resúmenes fundamentados. GPT-5, Claude Sonnet 4.5, Grok-4 y Gemini-3-Pro superaron todos el 10 %. La variante Grok-4-fast-reasoning alcanzó el 20,2 %. [48][49]
La hipótesis es sencilla. Los modelos de razonamiento invierten esfuerzo computacional en «pensar» las respuestas. Durante el resumen, este pensamiento les lleva a añadir inferencias, establecer conexiones y generar ideas que van más allá de lo que hay en el documento de origen. Eso es útil para el análisis, pero es una alucinación en una comparativa de resúmenes.
Esto plantea una decisión crítica para los equipos empresariales: el modo de razonamiento ayuda en tareas abiertas y perjudica en tareas fundamentadas. Saber cuándo activarlo y cuándo desactivarlo no es opcional.
Comparativa AA-Omniscience (Artificial Analysis)
AA-Omniscience plantea una pregunta fundamentalmente diferente a la de Vectara. En lugar de «¿puedes resumir sin añadir cosas?», pregunta «cuando no sabes algo, ¿lo admites o inventas algo?». [2]
La comparativa abarca 6.000 preguntas sobre 42 temas en seis dominios. El Omniscience Index (escala: -100 a +100) penaliza las respuestas incorrectas y no penaliza la negativa a responder. Esto la convierte en la única comparativa importante que premia explícitamente a los modelos por conocer sus propios límites.
Clasificación de los mejores modelos por precisión y tasa de alucinación
| Modelo | Proveedor | Precisión | Tasa de alucinación | Omniscience Index |
| Gemini 3 Pro Preview (alto) | 55.9% | 88% | 16 | |
| Gemini 3.1 Pro Preview | 55.3% | 50% | 33 | |
| Gemini 3 Flash (Reasoning) | 54.0% | 92% | – | |
| GPT-5.5 (muy alto) | OpenAI | 57% | 86% | 20 |
| GPT-5.3 Codex (muy alto) | OpenAI | 51.8% | – | – |
| Claude Opus 4.6 (máx.) | Anthropic | 46.4% | – | 14 |
| Claude Opus 4.7 (Adaptive Reasoning, Máx.) | Anthropic | ~47 % | 36% | 26 |
| Claude Opus 4.5 (thinking) | Anthropic | 45.7% | 58% | Negativo |
| GPT-5.2 (muy alto) | OpenAI | 43.8% | – | – |
| Grok 4 | xAI | 41.4% | 64% | Positivo |
| Claude Opus 4.5 | Anthropic | 40.7% | – | – |
| GPT-5 (alto) | OpenAI | 40.7% | – | – |
| Claude Sonnet 4.6 (máx.) | Anthropic | 40.0% | – | – |
| Claude Sonnet 4.6 | Anthropic | 38.0% | ~38 % | – |
| GPT-5.1 (alto) | OpenAI | 37.6% | 81% | Positivo |
Fuente: Artificial Analysis AA-Omniscience, noviembre de 2025 – abril de 2026 [2]
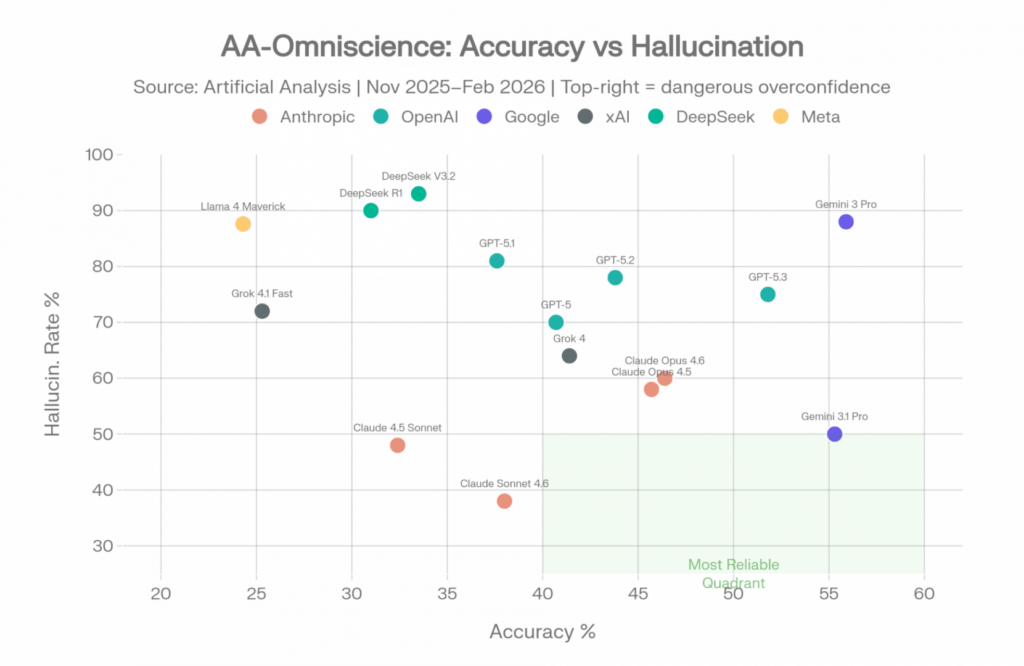
AA-Omniscience: Precisión frente a tasa de alucinación. El cuadrante verde muestra los modelos fiables. Fuente: Artificial Analysis [2]
Tasas de alucinación más bajas
| Modelo | Proveedor | Tasa de alucinación |
| Claude 4.1 Opus (Reasoning) | Anthropic | 0%* |
| Claude 4 Opus (Reasoning) | Anthropic | 0%* |
| Grok 4.20 (Reasoning) | xAI | 17% |
| MiMo-V2.5-Pro | Xiaomi | 25% |
| Claude 4.5 Haiku | Anthropic | 25% |
| Claude Sonnet 4.6 | Anthropic | ~38 % |
| Claude 4.5 Sonnet | Anthropic | 48% |
| Gemini 3.1 Pro Preview | 50% | |
| Claude Opus 4.5 | Anthropic | 58% |
| Grok 4 | xAI | 64% |
| Grok 4.1 Fast | xAI | 72% |
| DeepSeek R1 0528 | DeepSeek | 83% |
| Llama 4 Maverick | Meta | 87.6% |
| Gemini 3 Pro Preview | 88% |
Nota: La tasa de alucinación en AA-Omniscience mide con qué frecuencia el modelo responde incorrectamente cuando debería haberse negado a hacerlo; es la proporción de respuestas incorrectas sobre todas las respuestas no correctas. Esta es una métrica de exceso de confianza. *Asterisco: Claude 4.1 Opus logra un 0 % al rechazar todas las preguntas dudosas; produce menos alucinaciones al responder a menos preguntas. Grok 4.20 (Reasoning) logra un 17 % mientras intenta una mayor proporción de respuestas (abril de 2026). La estrategia óptima depende de si negarse a responder o dar respuestas incorrectas es más costoso para el caso de uso. Fuente: Artificial Analysis AA-Omniscience [2]
La paradoja de Gemini 3 Pro
Gemini 3 Pro cuenta la historia más interesante de estos datos. Logró la mayor precisión (55,9 %) por un amplio margen: sabe más que cualquier otro modelo probado. Pero también mostró una tasa de alucinación del 88 %. Cuando no conoce una respuesta, fabrica una el 88 % de las veces en lugar de admitir la incertidumbre. [2]
Alto conocimiento + baja autoconciencia = un modelo que es brillante cuando acierta y peligroso cuando se equivoca.
La actualización de Gemini 3.1 Pro abordó esto parcialmente. El ajuste de calibración de Google redujo la tasa de alucinación del 88 % al 50 % manteniendo una precisión casi idéntica (55,3 % frente a 55,9 %). El Omniscience Index saltó de 16 a 33, el más alto de cualquier modelo. Esto demostró que es posible una reducción drástica de las alucinaciones sin un sacrificio significativo de la precisión. [15]
El dato de GPT-5.5 (abril de 2026)
GPT-5.5, lanzado por OpenAI a principios de 2026, registra la precisión más alta jamás registrada en AA-Omniscience con un 57 %. También registra una tasa de alucinación del 86 % en la misma comparativa, la brecha más extrema entre precisión y calibración observada hasta ahora. Cuando GPT-5.5 no conoce una respuesta, fabrica una el 86 % de las veces. El patrón de Gemini 3 Pro (conocimiento sin autoconciencia) parece haberse intensificado con la última generación de modelos de alta capacidad. [2][63]
Claude Opus 4.7, lanzado por Anthropic el 16 de abril de 2026, toma el camino opuesto: una tasa de alucinación del 36 % en la misma comparativa, con una precisión bruta algo menor. Las dos decisiones de lanzamiento, con seis semanas de diferencia, representan la división más clara hasta ahora entre optimizar lo que un modelo sabe frente a lo que un modelo sabe sobre sus propios límites. [58][63]
Líderes por dominio específico
Ningún modelo individual domina todas las áreas de conocimiento:
| Dominio | Mejor modelo |
| Derecho | Claude 4.1 Opus |
| Ingeniería de software | Claude 4.1 Opus |
| Humanidades y Ciencias Sociales | Claude 4.1 Opus |
| Negocios | GPT-5.1.1 |
| Salud | Grok 4 |
| Ciencia y Matemáticas | Grok 4 |
Fuente: Artificial Analysis AA-Omniscience [2]
Los modelos Claude lideran en dominios donde el razonamiento preciso y la exactitud de las citas son fundamentales. Grok lidera en dominios donde importa una amplia cobertura de conocimientos. GPT lidera en aplicaciones empresariales. Esta fragmentación es en sí misma un dato: significa que ningún modelo es la opción más segura para todos los casos de uso profesional.
Una estadística que importa más que el resto
La precisión se correlaciona con el tamaño del modelo. La tasa de alucinación, no.
Los modelos más grandes saben más, pero no necesariamente saben lo que no saben.
Añadir más parámetros al problema aumenta el conocimiento sin aumentar la autoconciencia. Por eso el problema de las alucinaciones no desaparecerá simplemente con la próxima generación de modelos.
Comparativa FACTS (Google DeepMind)
El benchmark FACTS de Google DeepMind, publicado en diciembre de 2025, adopta un enfoque diferente al de la mayoría de las evaluaciones: en lugar de generar una única puntuación de alucinación, desglosa la factualidad en cuatro dimensiones distintas. Esta visión multidimensional revela que los modelos presentan fortalezas drásticamente diferentes según el tipo de tarea. Grok 4 obtiene una puntuación de 75,3 en Búsqueda, pero solo de 25,7 en Multimodal, lo que supone una diferencia de 50 puntos dentro del mismo modelo. [3]
Qué miden las cuatro secciones
Fundamentación: ¿Puede el modelo utilizar fielmente la información de los documentos proporcionados? Se evalúa mediante tareas de resumen y extracción con material de origen.
Multimodal: ¿Puede el modelo describir y razonar con precisión sobre contenido visual junto con el texto?
Paramétrica: ¿El conocimiento interno del modelo (almacenado en sus pesos tras el entrenamiento) produce respuestas correctas sin herramientas externas?
Búsqueda: ¿Qué precisión tiene el modelo cuando tiene acceso a herramientas de búsqueda web y recuperación?
Puntuaciones de los modelos en las cuatro secciones
| Modelo | Global | Fundamentación | Multimodal | Paramétrica | Búsqueda |
| Gemini 3 Pro | 68.8 | 69.0 | 46.1 | 76.4 | 83.8 |
| Gemini 2.5 Pro | 62.1 | – | – | – | – |
| GPT-5 | 61.8 | – | – | – | 77.7 |
| Grok 4 | 53.6 | – | – | – | 75.3 |
| GPT o3 | 52.0 | 36.2 | – | 57.1 | – |
| Claude 4.5 Opus | 51.3 | – | – | – | – |
| GPT 4.1 | 50.5 | – | – | – | – |
| Gemini 2.5 Flash | 50.4 | – | – | – | – |
| GPT 5.1 | 49.4 | – | – | – | – |
| Claude 4.5 Sonnet Thinking | 49.1 | – | – | – | – |
| Claude 4.1 Opus | 46.5 | – | – | – | – |
| GPT 5 mini | 45.9 | – | – | – | – |
| Claude 4 Sonnet | 42.8 | – | – | – | – |
| GPT o4 mini | 37.6 | – | – | – | – |
| Grok 4 Fast | 36.0 | – | – | – | – |
Nota: Los guiones indican puntuaciones por sección no reportadas por separado en las fuentes publicadas. La puntuación global de FACTS es un agregado de las cuatro secciones. Fuente: FACTS Benchmark Suite, diciembre de 2025 [3]
Qué revelan estos datos
Ningún modelo supera el 70 %. La mejor puntuación en FACTS es el 68,8 de Gemini 3 Pro. Todos los modelos se equivocan más del 30 % de las veces en esta evaluación de veracidad multidimensional.
La búsqueda es la sección más fuerte para todos. Gemini 3 Pro alcanza un 83,8 y GPT-5 un 77,7 en veracidad con búsqueda activada. Cuando los modelos pueden consultar información, son sustancialmente más precisos. Cuando dependen solo del conocimiento almacenado, la precisión cae. Esto coincide con los hallazgos de «navegación activada» frente a «desactivada» de las tarjetas de sistema de OpenAI.
Grok 4 tiene una brecha interna de 50 puntos. Obtiene un 75,3 en Búsqueda pero un 25,7 en Multimodal, una inconsistencia masiva que significa que puede encontrar hechos bien pero tiene dificultades con el contenido visual. Cualquier evaluación que promedie estos datos en una sola puntuación oculta esta brecha.
La mejora de Gemini 3 Pro es real. En comparación con Gemini 2.5 Pro, Gemini 3 Pro redujo las tasas de error en un 55 % en la sección de Búsqueda y en un 35 % en la sección Paramétrica. Se trata de una gran mejora generacional en la precisión fáctica, impulsada principalmente por mejores capacidades de búsqueda y fundamentación.
Perfiles de alucinación de modelos de frontera
Cada modelo a continuación se perfila a través de múltiples comparativas. Las comparaciones de una sola comparativa inducen a error; los perfiles muestran dónde es fiable cada modelo y dónde no.
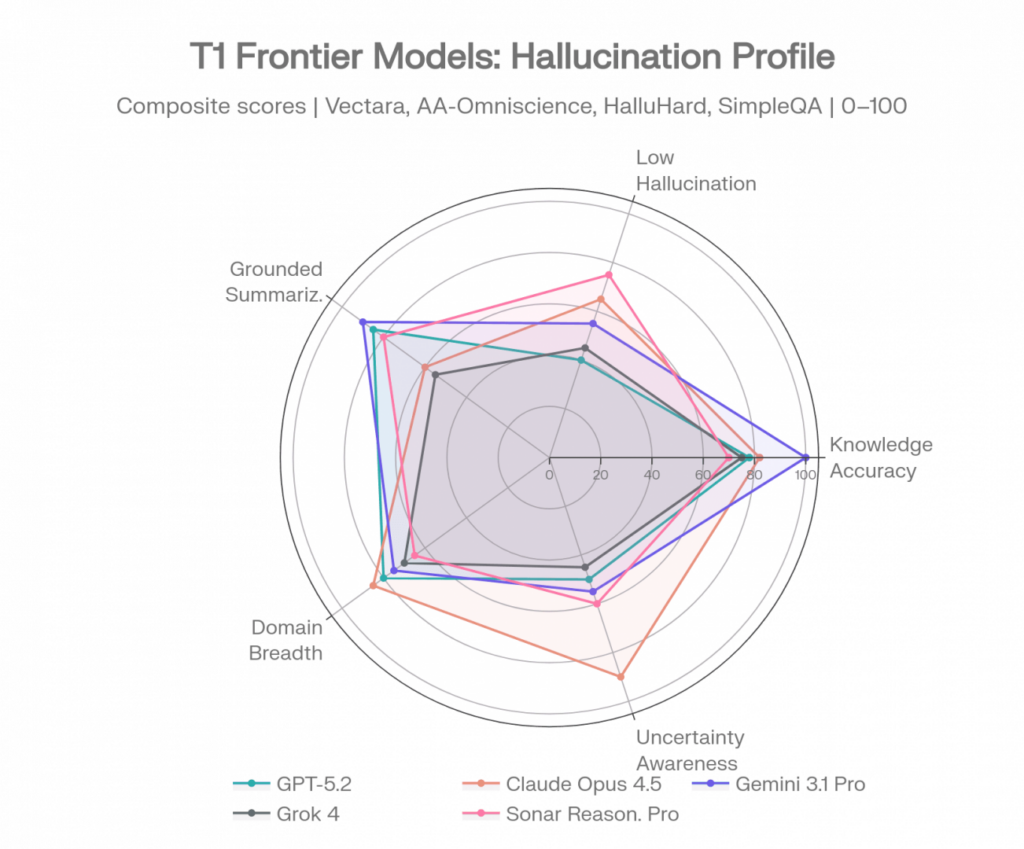
Perfiles de modelos de frontera a través de 5 dimensiones de alucinación. Fuentes: Vectara [1], AA-Omniscience [2], FACTS [3], SimpleQA [4]
Familia GPT-5 (OpenAI)
GPT-5.3 Instant (marzo de 2026) — El más nuevo de OpenAI. Reduce la alucinación en un 26,8 % con búsqueda web y en un 19,7 % sin ella, en relación con los modelos anteriores. [10]
GPT-5.2 (diciembre de 2025) — El caballo de batalla profesional. Precisión en AA-Omniscience: 43,8 %. Con búsqueda web: 93,9 % de respuestas sin errores. Sin ella: la tasa de error salta al 12 %. HalluHard: 38,2 % con web. FACTS global: 61,8. [9]
GPT-5 (agosto de 2025) — Conjunto de datos antiguo de Vectara: 1,4 % (fuerte). Nuevo conjunto de datos de Vectara: >10 % (débil). Modo de pensamiento HealthBench: 1,6 %, una de las mejores puntuaciones de alucinación médica registradas. SimpleQA sin web: 47 %. Con web: 9,6 %. FACTS global: 61,8. [8][12]
El patrón en la familia GPT-5: el acceso a la búsqueda web es la variable individual más importante. Con la navegación activada, los modelos GPT-5 compiten por las tasas de alucinación más bajas de la industria. Sin ella, las tasas se multiplican por 3-5. Si va a implementar una variante de GPT-5, mantenga activado el acceso a la web.
Familia Claude (Anthropic)
Claude 4.1 Opus — Tasa de alucinación en AA-Omniscience: 0 %. La más baja de todos los modelos probados. Lo logró negándose a responder cuando no estaba seguro. FACTS: 46,5. Líder de dominio en Derecho, Ingeniería de software y Humanidades. [2]
Claude Opus 4.6 (febrero de 2026) — Precisión en AA-Omniscience: 46,4 %, índice: 14. Nuevo conjunto de datos de Vectara (captura de feb. de 2026): 12,2 %. Tercer Omniscience Index más alto fuera de Gemini. [14][2]
Claude Opus 4.5 (noviembre de 2025) — Alucinación en AA-Omniscience: 58 %, precisión: 45,7 %. HalluHard: 30 % con búsqueda web (la más baja de todos los modelos probados), 60 % sin ella. FACTS: 51,3. [5]
Claude Sonnet 4.6 (febrero de 2026) — Alucinación en AA-Omniscience: ~38 %, por debajo del 48 % de Sonnet 4.5. Los usuarios prefirieron Sonnet 4.6 sobre Opus 4.5 el 59 % de las veces, citando menos alucinaciones. Nuevo conjunto de datos de Vectara: 10,6 %. [13][50]
Claude Opus 4.7 (16 de abril de 2026) — Índice AA-Omniscience: 26 (segundo más alto globalmente, solo por detrás del 33 de Gemini 3.1 Pro). Tasa de alucinación: 36 %, el perfil de calibración más sólido de cualquier modelo de frontera que intente responder preguntas a escala, y 50 puntos porcentuales mejor que GPT-5.5 en la misma comparativa. BenchLM global: 87. La recuperación de contexto largo cayó al 32,2 % (frente al 78,3 % de Opus 4.6); Anthropic lo atribuye explícitamente a que el modelo ahora informa de errores cuando falta información en lugar de fabricar una respuesta. La estrategia de rechazo hecha medible. [58][63]
El patrón en Claude: los modelos de Anthropic están calibrados para negarse a responder en lugar de adivinar. Esto les otorga las tasas de alucinación más bajas en comparativas de conocimiento (AA-Omniscience), pero una precisión bruta menor en comparación con Gemini. Para aplicaciones donde una respuesta incorrecta es peor que ninguna respuesta —investigación legal, consulta médica, trabajo de cumplimiento—, el enfoque de Claude es estructuralmente más seguro.
Familia Gemini (Google)
Gemini 3.1 Pro Preview (febrero de 2026) — Índice AA-Omniscience: 33 (el más alto de cualquier modelo). Precisión: 55,3 %. Tasa de alucinación: 50 %, por debajo del 88 % de Gemini 3 Pro. Esta fue la mayor mejora individual en alucinaciones mediante una actualización en 2025-2026. Nuevo conjunto de datos de Vectara: 10,4 %. [15]
Gemini 3 Pro — FACTS global: 68,8 (el más alto de cualquier modelo). FACTS Búsqueda: 83,8. FACTS Paramétrica: 76,4. Precisión en AA-Omniscience: 55,9 % (la más alta) con un 88 % de alucinación. La paradoja de Gemini: el más conocedor, el menos autoconsciente. [3]
Gemini 3 Flash (diciembre de 2025) — Precisión en AA-Omniscience: 54,0 % (la más alta de cualquier modelo en su lanzamiento). Tasa de alucinación: 91 %. Velocidad: 218 tokens/s. La versión más extrema de la paradoja de Gemini: brillante y poco fiable a partes iguales. Adecuado solo para tareas con verificación externa. [16]
Los modelos de Google son los que más saben, pero los que menos lo admiten.
El patrón en Gemini es claro: los modelos Gemini intentan responder a todas las preguntas, lo que les da las mejores puntuaciones de precisión, pero tasas de alucinación catastróficas cuando alcanzan los límites de su conocimiento. La actualización 3.1 Pro demostró que esto se puede abordar mediante ajuste de calibración: la alucinación cayó 38 puntos porcentuales con solo un 1% de pérdida de precisión.
Familia Grok (xAI)
Grok 4 — conjunto de datos antiguo de Vectara: 4,8%. AA-Omniscience: 41,4% de precisión, 64% de alucinación, índice positivo. FACTS: 53,6 (Búsqueda: 75,3; Multimodal: 25,7). Líder por dominio en Salud y Ciencia en AA-Omniscience. [2]
Grok 4.1 Fast — xAI afirma una reducción del 65% de alucinaciones (del 12,09% al 4,22% en benchmarks internos). AA-Omniscience cuenta otra historia: 72% de tasa de alucinación, peor que el 64% de Grok 4. También aumentó la complacencia (benchmark MASK: de 0,07 a 0,19-0,23). [17]
Grok-3 — Columbia Journalism Review: 94% de tasa de alucinación en citas. Con diferencia, la peor puntuación en este benchmark. [6]
El patrón en Grok: los benchmarks internos y los independientes discrepan de forma marcada. xAI informa de mejoras; AA-Omniscience muestra regresión. La tasa de alucinación del 94% en citas de CJR no procede de un modelo antiguo: Grok-3 se probó en marzo de 2025. Existe valor específico por dominio en Salud y Ciencia, pero la inconsistencia entre benchmarks hace que Grok sea arriesgado como único modelo para cualquier aplicación de alto riesgo.
Perplexity Sonar (Perplexity AI)
Sonar Reasoning Pro — puntuación en Search Arena: 1136, estadísticamente empatado con Gemini 2.5 Pro en el #1. F-score de SimpleQA: 0,858, el más alto de cualquier modelo en el momento de la prueba. Precisión de citas CJR: 37% de alucinación (el mejor probado). Precisión de respuesta: >90% para consultas factuales (94% en general, 95% académicas, 94% técnicas). [18][19]
Sonar Pro — basado en Llama 3.3 70B, ajustado para factualidad en búsqueda. F-score de SimpleQA: 0,858. Supera a GPT-4o y Claude 3.5 Sonnet en benchmarks de factualidad. [19]
El riesgo de Perplexity: Perplexity introduce un modo de fallo que ningún otro modelo comparte. Cita URL reales con afirmaciones inventadas. Las fuentes parecen legítimas — sitios web reales, nombres de publicaciones reales—, pero la información atribuida a esas fuentes puede estar inventada. Esto hace que las alucinaciones de Perplexity sean más difíciles de detectar que las de modelos que no presentan citas externas. Una tasa de alucinación en citas del 37% significa que más de una de cada tres atribuciones de fuente puede contener contenido fabricado. [51]
DeepSeek (DeepSeek AI)
DeepSeek-V3 — conjunto de datos antiguo de Vectara: 3,9%. Un rendimiento sólido en resumen con base (grounded summarization).
DeepSeek-R1 — conjunto de datos antiguo de Vectara: 14,3%, casi 4 veces más que V3. Alucinación en AA-Omniscience: 83%. El análisis de Vectara encontró que R1 produce un 71,7% de “alucinaciones benignas” (añadidos plausibles) frente al 36,8% de V3. [49][48]
El patrón: el modelo de razonamiento de DeepSeek (R1) alucina de forma drásticamente mayor que su modelo base (V3). Este es el “impuesto del razonamiento” en su forma más extrema. La brecha (3,9% frente a 14,3%) lo convierte en uno de los ejemplos más claros de que las capacidades de razonamiento y la fiabilidad factual no avanzan en la misma dirección.
Modelos de código abierto
Llama 4 Maverick (Meta) — conjunto de datos antiguo de Vectara: 4,6% (competitivo). Alucinación en AA-Omniscience: 87,6% (catastrófico). La brecha entre el resumen con base y el conocimiento abierto es mayor en los modelos de código abierto que en cualquier familia propietaria. [2]
Los modelos de código abierto superaron el 80% de tasa de alucinación en escenarios médicos en las pruebas de MedRxiv. Para aplicaciones críticas, la brecha de alucinación entre los modelos de frontera de código abierto y los propietarios sigue siendo grande. [40]
Comparaciones directas entre modelos
Los perfiles de modelos de la Sección 6 muestran el rendimiento individual. Esta sección responde a las preguntas que la gente realmente busca: “¿Es Claude o GPT más preciso?” “¿Debería usar Gemini o Claude?” La respuesta siempre es “depende de lo que esté haciendo”, pero los datos concretan los compromisos.
Mapa de calor de comparación directa: qué proveedor gana en qué benchmark. Verde = ganador, amarillo = empate, rojo = perdedor.
Claude vs GPT
La comparación más buscada en IA, y la más dependiente del contexto.
| Benchmark | Claude | GPT | Ganador |
| Vectara (conjunto de datos antiguo) | 4,4% (Sonnet 3.7) | 1,4% (GPT-5) | GPT |
| Vectara (nuevo conjunto de datos, feb 2026) | 10,6% (Sonnet 4.6) | 10,8% (GPT-5.2-high) | Empate |
| Alucinación AA-Omniscience | 0% (Claude 4.1 Opus) | ~78% (GPT-5.2) | Claude |
| Precisión AA-Omniscience | 46,4% (Opus 4.6) | 43,8% (GPT-5.2) | Claude (ligeramente) |
| FACTS general | 51,3 (Opus 4.5) | 61,8 (GPT-5) | GPT |
| HealthBench | – | 1,6% (GPT-5 thinking) | GPT |
| HalluHard (con web) | 30% (Opus 4.5) | 38,2% (GPT-5.2) | Claude |
Fuentes: HealthBench [52], HalluHard [5], FACTS [3], Vectara [1], AA-Omniscience [2]
El patrón no es “uno es mejor”. Son dos filosofías distintas medidas en escalas diferentes.
Los modelos GPT son más fuertes cuando la tarea tiene material fuente con el que trabajar. Resumen, análisis de documentos, canalizaciones RAG, preguntas y respuestas con base en búsqueda — GPT se ciñe más al texto proporcionado y puntúa bien en benchmarks de fidelidad. La ventaja en FACTS (61,8 frente a 51,3) lo refleja: GPT-5 gestiona tareas de grounding y búsqueda con mayor precisión.
Los modelos Claude son más fuertes cuando la tarea requiere que el modelo conozca sus propios límites. En AA-Omniscience, Claude 4.1 Opus logró una tasa de alucinación del 0% al negarse a responder preguntas que no podía verificar. La tasa de alucinación de ~38% de Claude Sonnet 4.6 es menos de la mitad del ~78% de GPT-5.2 en el mismo benchmark. En la prueba de conversación realista de HalluHard, Claude Opus 4.5 con búsqueda web alcanzó el 30% — la más baja de cualquier modelo probado.
La división práctica: use GPT para flujos de trabajo basados en documentos cuando el material fuente esté disponible y completo. Use Claude para flujos de trabajo de asesoramiento cuando el modelo deba apoyarse en su propio conocimiento y señalar la incertidumbre. Esto no es preferencia de marca: es lo que respaldan los datos de los benchmarks.
Una variable más que a menudo se pasa por alto: el acceso a búsqueda web cambia de forma drástica el rendimiento de GPT. GPT-5 baja del 47% de alucinación al 9,6% con navegación. Sin acceso web, la comparación Claude-GPT se inclina a favor de Claude en tareas factuales abiertas. Con acceso web, GPT se adelanta.
Claude vs Gemini
| Benchmark | Claude | Gemini | Ganador |
| Índice AA-Omniscience | 14 (Opus 4.6) | 33 (3.1 Pro) | Gemini |
| Precisión AA-Omniscience | 46,4% (Opus 4.6) | 55,3% (3.1 Pro) | Gemini |
| Alucinación AA-Omniscience | 0% (Claude 4.1 Opus) | 50% (3.1 Pro) | Claude |
| FACTS general | 51,3 (Opus 4.5) | 68,8 (3 Pro) | Gemini |
| Vectara (conjunto de datos antiguo) | 4,4% (Sonnet 3.7) | 0,7% (2.0-Flash) | Gemini |
| Vectara (nuevo conjunto de datos, feb 2026) | 10,6% (Sonnet 4.6) | 10,4% (3.1 Pro) | Empate |
| HalluHard (con web) | 30% (Opus 4.5) | – | Claude |
Fuentes: HalluHard [5], FACTS [3], Vectara [1], AA-Omniscience [2]
Gemini sabe más. Claude es más honesto sobre lo que no sabe.
Gemini 3.1 Pro lidera en casi todas las métricas de precisión. Obtiene la puntuación más alta en FACTS (68,8), la mayor precisión en AA-Omniscience (55,3%) y mantiene el mejor Omniscience Index (33). Cuando Gemini tiene la respuesta, la ofrece con más frecuencia que Claude.
El problema es cuando no la tiene. Incluso después de la actualización de calibración 3.1 que redujo la alucinación del 88% al 50%, Gemini sigue inventándose una respuesta la mitad de las veces cuando debería decir “no lo sé”. Claude 4.1 Opus se la inventa el 0% de las veces en ese escenario.
La división práctica: Gemini para tareas de amplitud de conocimiento donde exista verificación externa — investigación, análisis comparativo, recopilación de información. Claude para tareas de profundidad de confianza donde una respuesta inventada tenga consecuencias — revisiones de cumplimiento, investigación jurídica, consulta médica. Si puede comprobar el trabajo de Gemini, use Gemini. Si no puede, use Claude.
GPT vs Gemini
| Benchmark | GPT | Gemini | Ganador |
| Vectara (conjunto de datos antiguo) | 0,8% (o3-mini) | 0,7% (2.0-Flash) | Empate |
| Vectara (nuevo conjunto de datos) | 5,6% (GPT-4.1) | 3,3% (2.5-Flash-Lite) | Gemini |
| FACTS general | 61,8 (GPT-5) | 68,8 (3 Pro) | Gemini |
| FACTS Búsqueda | 77,7 (GPT-5) | 83,8 (3 Pro) | Gemini |
| Precisión AA-Omniscience | 43,8% (GPT-5.2) | 55,3% (3.1 Pro) | Gemini |
| HealthBench | 1,6% (GPT-5 thinking) | – | GPT |
Fuentes: FACTS [3], Vectara [1], AA-Omniscience [2]
Gemini lidera en la mayoría de los benchmarks. La ventaja de GPT es específica de la tarea: aplicaciones médicas (1,6% en HealthBench), precisión a nivel de afirmación en producción con modo thinking (4,5% de afirmaciones incorrectas) y el enorme volumen de datos de evaluación interna que publica OpenAI.
La división práctica: ambos son sólidos con acceso a herramientas. Sin él, el mayor conocimiento paramétrico de Gemini (FACTS Parametric: 76,4) le da ventaja en tareas de conocimiento almacenado. El modo thinking de GPT le da una ventaja específica en consultas médicas y relacionadas con la salud, donde el razonamiento reduce de forma drástica la alucinación.
Grok vs el resto
| Benchmark | Grok | Media del sector |
| Factualidad interna de xAI | 4,22% (Grok 4.1) | – |
| AA-Omniscience | 64% de alucinación (Grok 4) | ~60% de media |
| AA-Omniscience (variante Fast) | 72% de alucinación (Grok 4.1 Fast) | Peor que el base |
| FACTS general | 53,6 (Grok 4) | ~52 de media |
| FACTS Búsqueda | 75,3 (Grok 4) | Competitivo |
| FACTS Multimodal | 25,7 (Grok 4) | Muy por debajo de la media |
| Citas CJR | 94% de alucinación (Grok-3) | El peor probado |
| Vectara (nuevo conjunto de datos) | 20,2% (Grok-4-fast) | El peor probado |
Fuentes: Grok 4.1 [17], CJR [6], FACTS [3], AA-Omniscience [2]
xAI informa de una reducción del 65% de alucinaciones de Grok 4 a 4.1 en pruebas internas. AA-Omniscience muestra lo contrario: Grok 4.1 Fast alucina al 72% frente al 64% de Grok 4. El estudio de citas de CJR encontró que Grok-3 alucinó el 94% de las veces en la atribución de fuentes de noticias.
Grok sí tiene fortalezas reales por dominio: lidera las categorías de Salud y Ciencia en AA-Omniscience. Pero la brecha entre las afirmaciones de xAI y las mediciones independientes es mayor que la de cualquier otro proveedor.
Conclusión práctica: no use Grok como único modelo para decisiones de alto riesgo. Su valor está en ser una voz dentro de una evaluación multimodelo, donde sus fortalezas por dominio (salud, ciencia) puedan aportar mientras otras IA detectan sus inconsistencias.
Perplexity vs ChatGPT vs Claude
| Benchmark | Perplexity | ChatGPT | Claude |
| Precisión de citas CJR | 37% de alucinación | 67% de alucinación | – |
| F-score de SimpleQA | 0,858 (mejor) | 0,38 (GPT-4o) | 0,35 (Sonnet 3.5) |
| Ranking en Search Arena | #1 (empatado) | – | – |
| Precisión de respuesta | >90% factual | – | – |
Fuentes: Perplexity Sonar [18][19], CJR [6]
Perplexity gana en consultas factuales de búsqueda. Su arquitectura nativa de RAG, construida en torno a la recuperación en lugar del conocimiento paramétrico, le da una ventaja estructural para preguntas con respuestas verificables.
La trampa: Perplexity cita URL reales con afirmaciones inventadas. Las fuentes parecen legítimas — sitios web reales, nombres de publicaciones reales—, pero la información atribuida a esas fuentes puede estar inventada. Con una tasa de alucinación en citas del 37%, más de una de cada tres atribuciones de fuente podría contener contenido fabricado. Esto hace que las alucinaciones de Perplexity sean más difíciles de detectar que las de modelos que no presentan citas externas.
La división práctica: Perplexity para investigación inicial y verificación de hechos, cuando vaya a comprobar las afirmaciones clave. No para escenarios de respuesta final en los que alguien lea la fuente citada y asuma que la atribución es correcta.
Tasas de alucinación específicas por dominio
Las tasas de alucinación varían de forma drástica según la materia. Un modelo que es preciso en conocimiento general puede estar peligrosamente equivocado en cuestiones legales. Esta tabla muestra la dispersión en ocho dominios de conocimiento:
Tasas por dominio
| Dominio de conocimiento | Mejores modelos | Media de todos los modelos |
| Conocimiento general | 0.8% | 9.2% |
| Hechos históricos | 1.7% | 11.3% |
| Datos financieros | 2.1% | 13.8% |
| Documentación técnica | 2.9% | 12.4% |
| Investigación científica | 3.7% | 16.9% |
| Medicina / atención sanitaria | 4.3% | 15.6% |
| Código y programación | 5.2% | 17.8% |
| Información legal | 6.4% | 18.7% |
Fuente: AllAboutAI, 2025 [31]
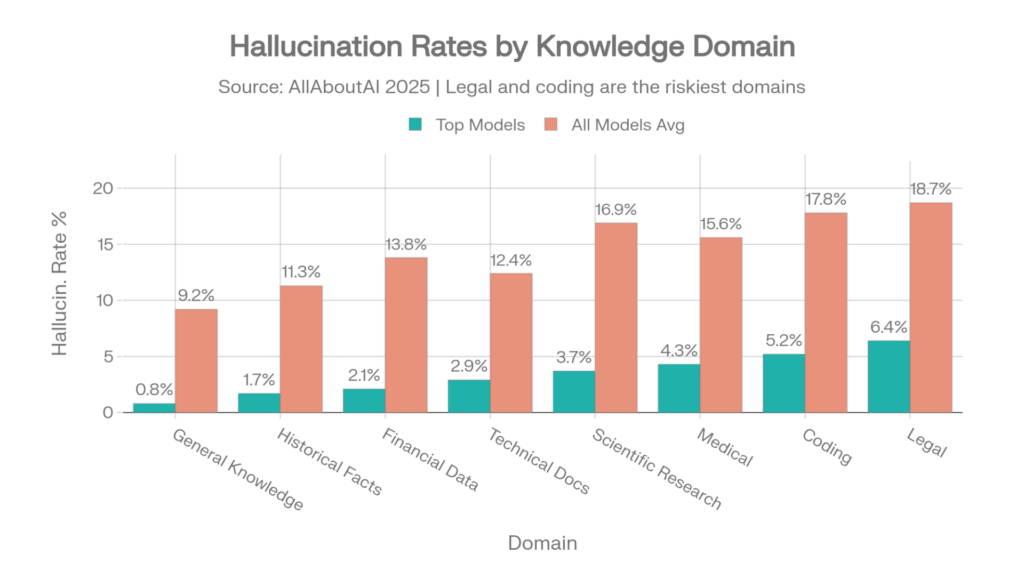
Tasas de alucinación específicas por dominio: mejores modelos vs. media. La brecha de 3x en Legal y Programación muestra cuánto importa la selección del modelo. Fuente: AllAboutAI [31]
La brecha entre los mejores modelos y la media le indica cuánto importa la selección del modelo. En información legal, los mejores modelos alucinan el 6,4% de las veces. El modelo medio alucina el 18,7%. Elegir el modelo adecuado para su dominio no es una preferencia: es una diferencia de 3x en fiabilidad.
Legal: la crisis en los tribunales
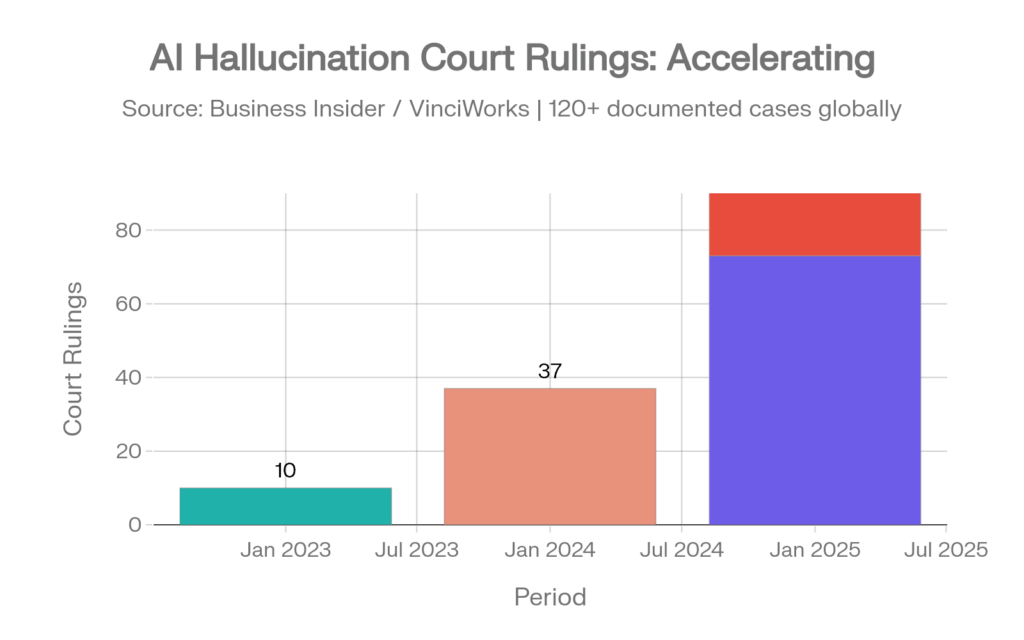
Las alucinaciones de IA en escritos judiciales se están acelerando pese a la creciente concienciación.
Los casos judiciales que implican alucinaciones de IA pasaron de 10 resoluciones documentadas en 2023 a 37 en 2024 y a 73 solo en los primeros cinco meses de 2025, con más de 50 casos solo en julio de 2025. A fecha de abril de 2026, esa trayectoria se ha acelerado con fuerza: la base de datos del investigador jurídico Damien Charlotin documenta ya más de 1.200 casos a nivel mundial, con aproximadamente 800 solo en tribunales de EE. UU. El 31 de marzo de 2026, diez tribunales distintos dictaron resoluciones sobre incidentes de alucinación de IA en un solo día. [38][37][59]
Incidentes legales de alucinación de IA: la aceleración de 10 → 37 → 73 → 50+ casos. Fuentes: Business Insider [38], Charlotin [37]
El problema ya no es de aficionados. En 2023, la mayoría de los casos de alucinación implicaban a litigantes sin representación. Para mayo de 2025, 13 de 23 casos detectados procedían de abogados en ejercicio. Morgan & Morgan, uno de los mayores bufetes de lesiones personales de Estados Unidos, envió una advertencia urgente a más de 1.000 abogados tras amenazas de sanciones por citas generadas por IA. El ritmo de las sanciones se ha intensificado: en el T1 de 2026, las sanciones sumaron al menos 145.000 $ — el mayor total trimestral en la historia legal. La mayor sanción individual registrada, 109.700 $ contra un abogado de Oregón, se impuso a principios de 2026. El Cuarto Circuito amonestó públicamente a un abogado en abril de 2026 por presentar escritos que contenían citas falsas generadas por IA. Pese a las sanciones récord, la tasa de incidentes sigue aumentando. [59]
Los datos subyacentes de los benchmarks explican por qué. Stanford RegLab y el Stanford Human-Centered AI Institute encontraron que los LLM alucinan entre el 69% y el 88% en consultas legales específicas. En preguntas sobre el fallo principal de un tribunal, los modelos alucinan al menos el 75% de las veces. Incluso las herramientas de IA legal diseñadas específicamente fallan: Lexis+ AI produjo información incorrecta en más del 17% de las ocasiones, y Westlaw AI-Assisted Research alucinó en más del 34%. [36]
Sanidad: donde las alucinaciones pueden matar
ECRI, la organización sin ánimo de lucro global de seguridad sanitaria, incluyó los riesgos de la IA como el peligro tecnológico sanitario #1 para 2025. Los números respaldan la preocupación. [39]
La FDA ha autorizado 1.357 dispositivos médicos mejorados con IA — el doble que a finales de 2022. De ellos, 60 dispositivos estuvieron implicados en 182 retiradas, y el 43% de las retiradas se produjo dentro del primer año desde la aprobación. [42]
Un estudio de MedRxiv de 2025 midió las tasas de alucinación en resúmenes de casos clínicos: 64,1% sin prompts de mitigación, bajando a 43,1% con mitigación (una mejora del 33%). GPT-4o fue el que mejor rindió en este estudio, bajando del 53% al 23% con mitigación estructurada. Los modelos de código abierto superaron el 80% de alucinación en escenarios médicos. [40]
El punto positivo: GPT-5 con modo thinking logró un 1,6% de alucinación en HealthBench, frente al 15,8% de GPT-4o. En aplicaciones médicas específicamente, los modelos de frontera con capacidad de razonamiento y el modo thinking activo muestran una mejora drástica respecto a generaciones anteriores. [41][52]
HealthBench Professional (abril de 2026): OpenAI lanzó un nuevo benchmark de nivel clínico el 22 de abril de 2026, junto con el lanzamiento de “ChatGPT for Clinicians”. A diferencia del HealthBench original (conversaciones sintéticas), HealthBench Professional utiliza escenarios clínicos reales en tareas de consulta, documentación e investigación. En HealthBench Hard, el segmento más exigente del nuevo benchmark, las puntuaciones divergen con fuerza: Muse Spark lidera con 42,8; GPT-5.4 (que impulsa ChatGPT for Clinicians) obtiene 40,1; Gemini 3.1 Pro obtiene 20,6; Grok 4.2 obtiene 20,3; y Claude Sonnet 4.6 obtiene 14,8. Los diseñadores del benchmark informan de que las respuestas impulsadas por GPT-5.4 superan a las respuestas redactadas por médicos en el segmento de consulta, aunque la metodología sigue bajo revisión independiente. [60]
Finanzas: fallos silenciosos con consecuencias ruidosas
Las alucinaciones de IA en finanzas no acaparan titulares como las legales, pero los costes son mayores.
El 78% de las empresas de servicios financieros ya despliegan IA para análisis de datos. Sin salvaguardas, las tasas de alucinación en tareas financieras se sitúan entre el 15% y el 25%. Las empresas informan de 2,3 errores significativos impulsados por IA por trimestre, con costes por incidente que oscilan entre 50.000 $ y 2,1 millones de $. [44]
Un estudio de benchmarks encontró que ChatGPT-4o alucinó un 20,0% en referencias a literatura financiera. Gemini Advanced alucinó un 76,7% en la misma tarea.
El 67% de las firmas de capital riesgo usan IA para el filtrado de oportunidades, pero el tiempo medio para descubrir un error generado por IA es de 3,7 semanas — a menudo demasiado tarde para revertir una decisión. Una alucinación de un robo-advisor afectó a 2.847 carteras de clientes, con un coste de 3,2 millones de $ en remediación. La SEC impuso 12,7 millones de $ en multas por tergiversaciones relacionadas con IA durante 2024-2025. [43]
Estadísticas de impacto empresarial
El coste de confiar en la IA sin verificación
67,4 mil millones de $ — pérdidas empresariales globales atribuidas a alucinaciones de IA en 2024. [31]
El 47% de los directivos empresariales ha tomado decisiones importantes basadas en contenido generado por IA sin verificar. [32]
El 82% de los fallos de IA en sistemas en producción proviene de alucinaciones y fallos de precisión. [34]
4,3 horas por semana — tiempo que el empleado medio dedica a verificar contenido generado por IA. A escala, eso supone 14.200 $ por empleado al año en costes de verificación. [33][31]
El 39% de los chatbots de atención al cliente requirió retrabajo debido a fallos relacionados con alucinaciones. [34]
El 54% de las empresas experimentó caídas de confianza de los inversores directamente atribuibles a errores generados por IA.
La respuesta institucional
El 91% de las políticas de IA empresarial ya incluye protocolos específicos para alucinaciones. [31]
El 64% de las organizaciones sanitarias retrasó la adopción de IA específicamente por preocupaciones sobre alucinaciones. [31]
12,8 mil millones de $ invertidos en soluciones específicas de detección y mitigación de alucinaciones entre 2023 y 2025. [31]
Crecimiento del mercado del 318% en herramientas de detección de alucinaciones de 2023 a 2025. [35]
La crisis de credibilidad académica
Más de 53 artículos aceptados en NeurIPS 2025 — una de las conferencias más prestigiosas de IA— contenían citas alucinadas por IA que sobrevivieron a más de 3 revisores. La tasa de aceptación de NeurIPS es del 24,52%, lo que significa que estos artículos con alucinaciones superaron a más de 15.000 envíos competidores. [45]
Cuando las citas alucinadas pasan la revisión por pares en el principal foro del campo, el problema de verificación se extiende más allá de la empresa y alcanza los cimientos de la propia investigación en IA.
Stanford AI Index 2026: los incidentes aumentaron un 55% en 2025
El Stanford Human-Centered AI Institute publicó su AI Index Report 2026 el 13 de abril de 2026 — una revisión anual de 423 páginas que cubre IA responsable, despliegue, gobernanza y benchmarks. Tres hallazgos se refieren directamente a las alucinaciones. [58]
362 incidentes de IA documentados en 2025 — frente a 233 en 2024, un aumento interanual del 55% y el mayor recuento anual en la historia de la AI Incident Database. [58]
Alucinación inducida por complacencia: del 22% al 94% en 26 modelos de frontera. El informe introduce un nuevo benchmark de precisión que prueba cómo responden los modelos a afirmaciones falsas presentadas de dos maneras: como algo que cree un tercero (los modelos lo gestionan bien) y como algo que cree el propio usuario (los modelos colapsan). La precisión de GPT-4o cayó del 98,2% al 64,4%; DeepSeek R1 cayó de más del 90% al 14,4%. El rango 22%-94% se aplica específicamente a este encuadre de falsa creencia atribuida al usuario. El mejor modelo sigue produciendo salidas falsas el 22% de las veces cuando el usuario insinúa una creencia falsa; el peor alucina el 94% en esas condiciones. Este es un modo de fallo fundamentalmente distinto de los benchmarks de resumen o conocimiento: el modelo está de acuerdo con el usuario incluso cuando el usuario se equivoca. [58]
85% de adopción de IA empresarial (Gartner, 2026). La adopción ha alcanzado ya un nivel en el que los errores de IA se acumulan a escala, aunque la cifra de coste de 67,4 mil millones de $ de 2024 no se ha actualizado para 2025. Los roles de gobernanza de IA crecieron un 17% en 2025, y la proporción de empresas sin políticas de IA responsable cayó del 24% al 11% — pero las puntuaciones de transparencia de modelos fundacionales volvieron a bajar de 58 a 40, con grandes lagunas en divulgaciones sobre datos de entrenamiento, recursos de cómputo e impacto posterior al despliegue.
Cuando una IA alucina, otra lo detecta.
Vea cómo funciona la validación multimodelo — pruébelo con una pregunta real en la que la precisión importe.
Probar la validación multimodelo
La paradoja del razonamiento
Uno de los hallazgos más contraintuitivos de la investigación sobre alucinaciones en 2025-2026: los modelos de IA comercializados como los más inteligentes suelen ser los menos fiables en tareas factuales básicas.
La contradicción central
Los modelos de razonamiento — GPT-5 con thinking, Claude con thinking extendido, DeepSeek-R1— utilizan procesos de cadena de pensamiento que mejoran de forma drástica el rendimiento en problemas complejos. Son mediblemente mejores en matemáticas, lógica, análisis de varios pasos y diagnóstico médico.
También son mediblemente peores a la hora de ceñirse a los hechos que se les han proporcionado.
La evidencia
Nuevo conjunto de datos de Vectara: todos los modelos de razonamiento probados superaron el 10% de alucinación. GPT-5, Claude Sonnet 4.5, Grok-4 y Gemini-3-Pro superaron ese umbral. La variante Grok-4-fast-reasoning alcanzó el 20,2%. Los modelos sin razonamiento, como Gemini-2.5-Flash-Lite, obtuvieron un 3,3%. [1]
DeepSeek: R1 (razonamiento) alucina al 14,3% en Vectara frente al 3,9% de V3 (base). Casi una diferencia de 4x del mismo proveedor. El análisis de Vectara encontró que R1 produce un 71,7% de “alucinaciones benignas” (añadidos plausibles) en comparación con el 36,8% de V3. [48][49]
Regresión en PersonQA: el o3 de OpenAI alucina un 33% en preguntas sobre personas reales frente al 16% de o1. El o4-mini es peor, con un 48%. Son modelos más nuevos y más capaces que rinden peor en una prueba factual básica. [53][54]
Modo thinking de GPT-5: la alucinación en HealthBench baja al 1,6% (excelente). Pero en el nuevo conjunto de datos de Vectara, GPT-5 supera el 10% (malo). Mismo modelo, mismo modo thinking, resultados opuestos según la tarea.
GPT-5.5 (abril de 2026): el dato más contundente hasta ahora. Precisión AA-Omniscience del 57% — la más alta jamás registrada— junto con una tasa de alucinación del 86%. El modelo más capaz que OpenAI ha lanzado también es uno de los peor calibrados. La expansión del conocimiento parece haber superado las mejoras de calibración en la frontera. Claude Opus 4.7 (16 de abril de 2026) hace el intercambio opuesto: 36% de alucinación con menor precisión bruta. [2][58][63]
Por qué ocurre esto
El mecanismo es sencillo. Cuando un modelo de razonamiento procesa una tarea de resumen, no solo extrae: piensa. Extrae inferencias, identifica patrones y genera ideas. Estas adiciones van más allá del documento fuente. En un benchmark que mide la fidelidad al material fuente, cada idea que añade el modelo cuenta como una alucinación.
Es la diferencia entre “resuma este contrato” y “analice este contrato”. El modo de razonamiento añade análisis incluso cuando usted pide un resumen. Ese análisis suele ser útil. En un benchmark de resumen, se puntúa como un fallo.
El efecto de la navegación es mayor que el efecto del razonamiento
Los datos de la system card de OpenAI revelan algo a lo que se presta menos atención: el acceso web tiene un impacto mayor en las tasas de alucinación que el modo de razonamiento. [11][8]
| Modelo | Navegación DESACTIVADA | Navegación ACTIVADA | Reducción |
| o4-mini FActScore | 37.7% | 5.1% | 86% |
| o3 FActScore | 24.2% | 5.7% | 76% |
| GPT-5 thinking FActScore | 3.7% | 1.0% | 73% |
| GPT-5 SimpleQA | 47% | 9.6% | 80% |
Fuentes: system card de o3/o4-mini [11], system card de GPT-5 [8]
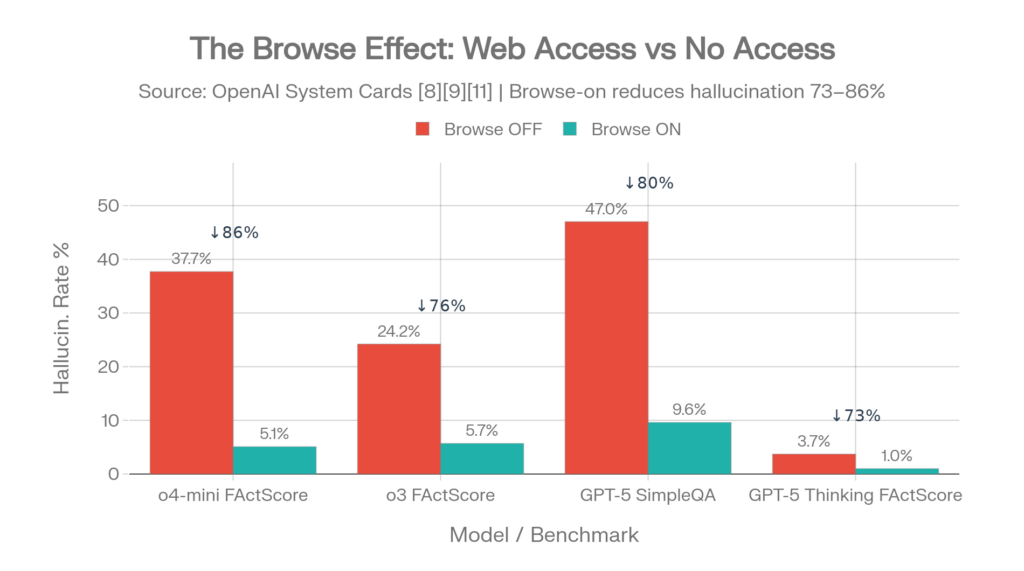
El efecto de la navegación: reducción del 73-86% de alucinaciones con un único cambio de configuración. Fuentes: system cards de OpenAI [8][11][10]
Activar la búsqueda web reduce más las alucinaciones que activar el razonamiento.
En despliegues empresariales, garantizar el acceso a herramientas es más determinante que elegir entre variantes de modelo con o sin razonamiento.
El marco de decisión
Esto crea una matriz práctica para la selección de modelos:
Razonamiento ACTIVADO + Web ACTIVADA: lo mejor para análisis complejos, diagnóstico médico e investigación de varios pasos, donde importan tanto la profundidad como el acceso a información actual. Las tasas de alucinación más bajas en tareas abiertas.
Razonamiento DESACTIVADO + Web ACTIVADA: lo mejor para resumen de documentos, canalizaciones RAG y preguntas y respuestas con base (grounded Q&A), cuando se quiere que el modelo se mantenga cerca del material fuente. Menor riesgo de añadidos por “sobrepensar”.
Razonamiento ACTIVADO + Web DESACTIVADA: combinación arriesgada. El modelo sobrepiensa y no puede verificar. Adecuado solo para problemas de lógica de mundo cerrado, matemáticas y código donde no se necesitan hechos externos.
Razonamiento DESACTIVADO + Web DESACTIVADA: el mayor riesgo de alucinación en general. Evítelo para cualquier tarea factual.
Por qué la alucinación cero es matemáticamente imposible
Esto no es especulación. Dos equipos de investigación independientes lo demostraron.
Prueba 1: la alucinación es inherente a la arquitectura
Xu et al. (2024) formalizaron el problema de la alucinación matemáticamente y demostraron que eliminar la alucinación en los modelos de lenguaje grandes es imposible. No difícil. No requiere más cómputo ni mejores datos de entrenamiento. Imposible — es decir, demostrablemente imposible dada la arquitectura fundamental de cómo estos sistemas generan texto. [20]
El argumento central: cualquier sistema que genere texto prediciendo secuencias probables a partir de distribuciones estadísticas aprendidas, por necesidad matemática, a veces producirá salidas no fundamentadas en hechos. El propio mecanismo generativo lo garantiza.
Prueba 2: cuatro objetivos que no pueden ser todos ciertos
Karpowicz (2025) atacó el problema desde tres marcos matemáticos distintos — teoría de subastas, teoría de puntuación propia y análisis log-sum-exp para arquitecturas transformer— y llegó a la misma conclusión en cada caso. [21]
Ningún mecanismo de inferencia de LLM puede lograr simultáneamente estas cuatro propiedades:
- Generación de respuestas veraces — producir siempre una salida factualmente correcta
- Conservación de la información semántica — preservar el significado del material fuente
- Revelación de conocimiento relevante — aflorar conocimiento almacenado cuando sea aplicable
- Optimalidad restringida por el conocimiento — mantenerse dentro de los límites de lo que realmente sabe
Puede optimizar cualquiera de tres. No puede obtener las cuatro. Las matemáticas no lo permiten.
OpenAI está de acuerdo
OpenAI reconoció públicamente estos hallazgos e identificó tres factores matemáticos que hacen inevitable la alucinación: [22]
Incertidumbre epistémica — cuando la información aparece raramente en los datos de entrenamiento, el modelo no tiene una base fiable para generar una salida precisa sobre ese tema, pero aun así lo intentará.
Limitaciones del modelo — algunas tareas exceden lo que la arquitectura puede representar, independientemente del volumen o la calidad de los datos de entrenamiento.
Intratabilidad computacional — ciertos problemas de verificación son computacionalmente tan difíciles que ni siquiera un sistema superinteligente teórico podría resolverlos en un tiempo razonable.
Qué significa esto en la práctica
La alucinación no es un bug que se vaya a arreglar en el próximo lanzamiento de modelo. Es una propiedad matemática permanente de cómo funcionan los modelos de lenguaje.
Esto cambia la pregunta. La pregunta correcta no es “¿qué IA no alucina?”: toda IA alucina. La pregunta correcta es: ¿qué sistemas tiene usted implantados para detectar alucinaciones antes de que lleguen a quien toma decisiones?
Las organizaciones que hacen esto bien no están esperando un modelo sin alucinaciones. Están construyendo capas de detección, canalizaciones de validación cruzada y puntos de control de revisión humana. Los datos sobre lo que funciona (y cuánto ayuda) están en la sección Técnicas de reducción a continuación.
Qué reduce realmente la alucinación — clasificado por evidencia
No todas las técnicas de reducción de alucinaciones son iguales. Algunas están respaldadas por estudios controlados con mediciones precisas. Otras tienen un fuerte soporte teórico pero datos de producción limitados. Esta clasificación refleja la base de evidencia, no las afirmaciones de marketing.
Técnicas de reducción de alucinaciones clasificadas por impacto medido. Fuentes: OpenAI [8][11], AllAboutAI [31], HealthBench [52], UAF [24], CoVe [23], VeriFY [25], Gemini 3.1 [15], MedRxiv [40]
Nivel 1: mayor impacto medido
1. Acceso a búsqueda web
Impacto medido: reducción del 73-86% de alucinaciones (FActScore, navegación activada vs desactivada)
La intervención individual de mayor impacto documentada en la investigación de 2025-2026. GPT-5 baja del 47% al 9,6% de alucinación con acceso web. El o4-mini baja del 37,7% al 5,1%. GPT-5.3 Instant muestra una reducción del 26,8% al usar web frente a modelos anteriores. [8][11][10]
El mecanismo es simple: en lugar de depender de datos de entrenamiento potencialmente obsoletos o incorrectos, el modelo recupera información actual y fundamenta su respuesta en fuentes externas. Para cualquier despliegue empresarial, habilitar el acceso web o a herramientas debería ser la primera decisión de configuración, no algo secundario.
2. RAG (Retrieval Augmented Generation)
Impacto medido: hasta un 71% de reducción en tareas de base de conocimiento empresarial [31]
RAG conecta los modelos con bases de conocimiento externas — documentos de la empresa, bases de datos, fuentes verificadas— e instruye al modelo para generar respuestas fundamentadas en el contenido recuperado en lugar de en la memoria paramétrica. Los recuperadores híbridos que combinan métodos dispersos y densos logran la mitigación más sólida.
RAG es más eficaz para alucinaciones por brecha de conocimiento (el modelo carece de datos de entrenamiento relevantes). Es menos eficaz para alucinaciones basadas en lógica (el modelo razona de forma incorrecta a partir de premisas correctas). Para preguntas y respuestas sobre documentos empresariales y aplicaciones de base de conocimiento, RAG es el estándar de referencia.
Nivel 2: evidencia sólida, dependiente del contexto
3. Modo thinking/razonamiento
Impacto medido: reducción del 55-75% en tareas médicas y factuales abiertas; aumenta la alucinación en resumen con base [52]
Modo thinking de GPT-5: HealthBench baja del 3,6% al 1,6%. Tráfico de ChatGPT en producción: el 4,8% de las respuestas contiene afirmaciones incorrectas importantes frente al 11,6% sin thinking. Son mejoras significativas.
Pero el modo de razonamiento aumenta la alucinación en el benchmark de resumen de Vectara (véase la Sección 10). El impacto depende de la tarea. Active el razonamiento para análisis, diagnóstico y consultas complejas. Desactívelo para resumen, extracción y tareas fieles a la fuente.
4. Validación cruzada multimodelo
Impacto medido: mejora del 8% en precisión frente a enfoques de un solo modelo (marco UAF) [24]
El marco Uncertainty-Aware Super Mind de Amazon (publicado en ACM WWW 2025) combinó varios LLM ponderados por su precisión y la calidad de su autoevaluación. El hallazgo clave: distintos modelos destacan en distintos tipos de preguntas, por lo que combinarlos captura fortalezas complementarias.
La detección de desacuerdos entre modelos detecta alucinaciones porque los modelos rara vez fabrican la misma información falsa. Cuando un modelo hace una afirmación sin fundamento, otros suelen señalar la inconsistencia o proporcionar datos contradictorios. La investigación sobre la «sabiduría de la multitud de silicio» muestra que los conjuntos de LLM pueden rivalizar con la precisión de la predicción humana colectiva mediante una agregación simple.
La cifra del 8% subestima el valor práctico. En producción, los enfoques multimodelos detectan errores que ninguna verificación de un solo modelo señalaría, porque el modelo de verificación tiene diferentes datos de entrenamiento, diferentes sesgos y diferentes puntos ciegos.
5. Cadena de Verificación (CoVe)
Impacto medido: mejora del 28% en FActScore [23]
Un flujo de trabajo de cuatro pasos: generar una respuesta de referencia, planificar preguntas de verificación, responder a esas preguntas de verificación de forma independiente y, a continuación, refinar el resultado final. Publicado en ACL 2024, supera al prompt de cero-shot, few-shot y cadena de pensamiento en la precisión de la generación de formato largo.
El coste es la latencia y la computación: cuatro pasos en lugar de uno. Para aplicaciones donde la precisión importa más que la velocidad —generación de informes, síntesis de investigación, documentación de cumplimiento—, la compensación merece la pena.
Nivel 3: Significativo, pero más limitado
6. VeriFY (Verificación en Tiempo de Entrenamiento)
Impacto medido: reducción de la alucinación del 9,7-53,3% en familias de modelos [25]
Publicado en ICML 2025, VeriFY enseña a los modelos a evaluar la incertidumbre fáctica durante la generación en lugar de depender de una verificación post-hoc. El modelo aprende a verificar sus propias afirmaciones a medida que las produce. La pérdida de recuperación es modesta: 0,4-5,7%.
Esta es una intervención en tiempo de entrenamiento, lo que significa que los usuarios finales no la controlan. Su valor radica en señalar hacia dónde se dirige el campo: las futuras generaciones de modelos probablemente internalizarán la verificación como una capacidad central en lugar de añadirla después de la generación.
7. Ajuste de Calibración
Impacto medido: reducción de 38 puntos porcentuales en la alucinación de la IA (Gemini 3.1 Pro, del 88% al 50%) con solo un 1% de pérdida de precisión [15]
Google demostró que ajustar la calibración de un modelo —su capacidad para hacer coincidir la confianza con la precisión real— puede reducir drásticamente la alucinación sin sacrificar el conocimiento. El Índice de Omnisciencia de Gemini 3.1 Pro saltó de 16 a 33 con este enfoque.
Al igual que VeriFY, esta es una intervención del lado del proveedor. Los usuarios se benefician de ella al seleccionar versiones de modelos más nuevas, pero no pueden aplicarla ellos mismos.
8. Prompts de Mitigación Específicos del Dominio
Impacto medido: reducción del 33% en tareas médicas (del 64,1% al 43,1%); GPT-4o bajó del 53% al 23% [40]
Prompts estructurados que instruyen al modelo para que restrinja las salidas a información verificada, señale la incertidumbre y evite la especulación. Funcionan mejor en dominios estrechos con límites claros y terminología bien definida.
Los resultados médicos son alentadores, pero las tasas absolutas siguen siendo altas (el 43,1% con mitigación sigue siendo peligrosamente incorrecto para uso clínico). Los prompts de dominio son una capa, no una solución.
Lo que no funciona (o funciona menos de lo que se afirma)
Solo modelos más grandes: la precisión se correlaciona con el tamaño del modelo. La tasa de alucinación no. Los modelos más grandes saben más, pero no necesariamente saben lo que no saben.
Reducción simple de la temperatura: reducir la temperatura de generación reduce la variedad, pero no elimina la alucinación. El modelo sigue eligiendo el token más probable, solo que lo hace de forma más consistente, incluyendo tokens consistentemente incorrectos.
Prompts de sistema para «ser preciso»: las instrucciones genéricas para evitar alucinaciones muestran un efecto medido mínimo. Los modelos ya «intentan» ser precisos. El problema es estructural, no motivacional.
La evidencia multimodelos
La investigación publicada entre 2024 y 2026 converge cada vez más en un hallazgo específico: consultar a múltiples modelos de IA sobre la misma pregunta detecta errores que los enfoques de un solo modelo pasan por alto. Esto no es un argumento teórico. Múltiples estudios revisados por pares proporcionan evidencia medida.
El marco UAF de Amazon (ACM WWW 2025)
El marco de Fusión Consciente de la Incertidumbre (UAF) combina múltiples LLM ponderados por dos factores: la precisión de cada modelo en la tarea y la capacidad de cada modelo para autoevaluarse cuando no está seguro. El resultado medido: una mejora del 8% en la precisión sobre cualquier modelo individual. [24]
La idea crítica del estudio: «Las capacidades de precisión y autoevaluación de los LLM varían ampliamente, con diferentes modelos destacando en diferentes escenarios». Ningún modelo único domina todos los tipos de preguntas. GPT puede ser el más fuerte en tareas fundamentadas, Claude en tareas de calibración de conocimiento, Gemini en tareas de amplitud de conocimiento. El conjunto captura las tres fortalezas.
El mecanismo de detección de desacuerdos
Los modelos entrenados con diferentes datos, con diferentes arquitecturas y diferentes ajustes de alineación, desarrollan diferentes patrones de fallo. Cuando cinco modelos analizan la misma pregunta, rara vez fabrican la misma información falsa.
Un modelo afirma que existe un precedente legal. Otros cuatro no lo mencionan. Ese desacuerdo es una señal. Un revisor humano puede investigar la afirmación específica en lugar de revisar todo el resultado.
Esto funciona porque las alucinaciones son estocásticas, no sistemáticas. Un modelo no alucina consistentemente el mismo hecho incorrecto, sino que rellena los huecos con contenido diferente que suena plausible cada vez. Cuando varios modelos rellenan el mismo hueco con contenido contradictorio, el hueco se hace visible.
La investigación sobre la «sabiduría de la multitud de silicio»
Múltiples estudios muestran que la agregación simple de las salidas de los LLM puede rivalizar con la precisión de la predicción humana colectiva. El mecanismo es paralelo al experimento del peso del buey de Galton y a la «Sabiduría de las multitudes» de Surowiecki: las estimaciones individuales están sesgadas, pero el agregado anula los errores no correlacionados. [28]
Para la IA, esto significa: cinco modelos con un 60% de precisión individual, con errores no correlacionados, pueden producir resultados agregados significativamente por encima del 60% de precisión. Las matemáticas favorecen la diversidad sobre la excelencia individual.
Evidencia de producción (Suprmind DMI, abril de 2026)
Los hallazgos académicos anteriores describen el mecanismo. El Índice de Divergencia Multimodelo de Suprmind lo mide en la práctica. [61][62]
El conjunto de datos: 1.324 turnos de conversación multimodelos de 299 usuarios reales en 10 dominios durante 45 días (del 5 de marzo al 19 de abril de 2026). Cinco modelos de vanguardia (GPT, Claude, Gemini, Grok y Perplexity) respondiendo a las mismas preguntas, con cada modelo leyendo lo que se dijo antes. Después de cada turno, un clasificador registra lo que sucedió entre los modelos: contradicciones, correcciones e ideas únicas. [61]
Lo que mide el DMI y lo que no. El índice rastrea el comportamiento de desacuerdo y corrección. No mide qué modelo es fácticamente correcto en un intercambio dado. Que un modelo sea contradicho es una señal de detección, no un veredicto. El DMI complementa los puntos de referencia de precisión como Vectara y AA-Omniscience; no los reemplaza.
Hallazgo 1: El mecanismo de detección se activa en casi cada turno multimodelos.
En los 1.324 turnos, el 99,1% produjo al menos una contradicción, corrección o idea única que provino solo de un modelo diferente al del primer respondedor. La tasa de «acuerdo silencioso» —turnos en los que todos los modelos estuvieron de acuerdo sin sacar nada nuevo— fue del 0,9%. En cinco de los diez dominios rastreados (Legal, Médico, Educación, Investigación, Creativo), la tasa silenciosa fue cero. [61]
Una consulta de un solo modelo habría pasado por alto algo en 99 de cada 100 de estos turnos. Si lo que se pasó por alto fue fácticamente crítico varía. Que se pasó por alto algo no está en discusión.
Hallazgo 2: La paradoja de la confianza aparece en producción.
La investigación del MIT citada anteriormente en esta página encontró que los modelos de IA tienen un 34% más de confianza cuando se equivocan que cuando aciertan. Los datos del DMI muestran el mismo patrón en conversaciones multimodelos en vivo: una respuesta de alta confianza (autoevaluada con 7 o más sobre 10) no es un escudo contra ser contradicha por otro modelo.
| Modelo (respuestas de alta confianza) | Contradecido o corregido por otro modelo |
| Gemini | 51.4% |
| Grok | 48.9% |
| GPT | 39.6% |
| Perplexity | 33.9% |
| Claude | 33.9% |
Fuente: Índice de Divergencia Multimodelo de Suprmind, edición de abril de 2026 [61]
En los cinco proveedores, entre una de cada tres y una de cada dos respuestas declaradas con confianza tuvieron un problema sustantivo detectado por un modelo par. Específicamente en los turnos de alto riesgo, la tasa de Claude bajó al 26,4% —la más baja de los cinco—, mientras que la de Gemini apenas se movió (50,3%). [61]
Esta no es una tasa de alucinación. Es una tasa de detección por revisión por pares. Pero la implicación para el uso de un solo modelo es directa: la confianza en la respuesta de un modelo, sin ninguna verificación externa, es el modo de fallo más común en los datos. Este patrón se alinea con el hallazgo del Stanford AI Index 2026 anterior: cuando las declaraciones falsas se enmarcan como algo que el usuario cree, la precisión de un solo modelo colapsa. El mecanismo de revisión multimodelos captura este modo de fallo porque un segundo modelo, no anclado al marco demasiado confiado del primer modelo, aplica su propia base a la misma afirmación. [58][61]
Hallazgo 3: Diferentes modelos detectan cosas diferentes, y la asimetría es grande.
Cada modelo en el conjunto de datos DMI tiene una «tasa de detección»: correcciones que hizo a otros, divididas por las correcciones que recibió de otros. Una tasa superior a 1,0 significa que el modelo detecta más de lo que es detectado.
| Proveedor | Detecciones realizadas | Veces detectado | Tasa de detección |
| Perplexity | 335 | 132 | 2.54 |
| Claude | 304 | 135 | 2.25 |
| Grok | 193 | 269 | 0.72 |
| GPT | 111 | 295 | 0.38 |
| Gemini | 109 | 416 | 0.26 |
Fuente: Índice de Divergencia Multimodelo de Suprmind, edición de abril de 2026 [61]
Perplexity detecta aproximadamente diez veces más a menudo que Gemini. Esto no es una clasificación de qué modelo es «mejor»; la ventaja de Perplexity proviene en parte de su arquitectura basada en la búsqueda, que le otorga una ventaja estructural para señalar afirmaciones sin fundamento. El punto es que la detección no es aleatoria. Diferentes arquitecturas producen diferentes perfiles de detección, que es exactamente lo que predice la tesis multimodelos. [61]
Hallazgo 4: Donde las apuestas son más altas, el acuerdo es más bajo.
Tasa de desacuerdo por dominio, clasificada de mayor a menor:
| Dominio | Turnos multimodelos | Turnos con desacuerdo |
| Financiero | 258 | 72.1% |
| Otros | 153 | 59.6% |
| Marketing y Ventas | 131 | 55.0% |
| Estrategia de Negocio | 257 | 54.9% |
| Análisis de Investigación | 74 | 52.7% |
| Técnico | 172 | 49.4% |
| Creativo | 38 | 42.1% |
| Legal | 135 | 41.5% |
| Médico | 56 | 33.9% |
| Educación | 49 | 28.6% |
Fuente: Índice de Divergencia Multimodelo de Suprmind, edición de abril de 2026 [61]
Las preguntas financieras producen desacuerdo entre modelos en casi tres de cada cuatro turnos. Las preguntas de educación lo producen en aproximadamente uno de cada cuatro. Los dominios de alto riesgo donde esta página documentó las peores consecuencias de la alucinación —financiero, legal, médico— son los mismos dominios donde ejecutar preguntas a través de más de un modelo saca a la luz la mayor divergencia. Específicamente en el Análisis de Investigación: el 52,2% de las contradicciones en ese dominio se clasificaron como de gravedad crítica (7 o más en una escala de 10 puntos), la mayor proporción crítica de cualquier dominio. Cuando los modelos discrepan sobre preguntas de investigación, tienden a discrepar sobre algo que importa. [61]
Lo que esto añade al caso multimodelos
La investigación académica estableció que los conjuntos superan a los modelos individuales. El DMI muestra que el mecanismo de detección se activa en el uso real de producción, no en puntos de referencia diseñados para ello, no en condiciones de laboratorio, sino en conversaciones en vivo con usuarios de pago sobre preguntas reales. El mecanismo que predice la investigación es el mecanismo que muestran los datos de producción.
La advertencia honesta restante de la sección anterior sigue siendo válida: la validación cruzada aumenta la probabilidad de detección, no garantiza la ausencia de alucinaciones. Dos hallazgos en este conjunto de datos refuerzan ese punto. Primero, los modelos ocasionalmente todavía están de acuerdo en la misma respuesta incorrecta; el DMI no detecta errores de datos de entrenamiento compartidos. Segundo, el DMI cuenta las contradicciones y correcciones, no sus resoluciones. Saber que dos modelos discreparon no es lo mismo que saber cuál tenía razón.
El desacuerdo es la señal; la verificación sigue siendo tarea del usuario.
Lo que la validación cruzada detecta (y lo que no)
Detecta bien:
- Citas y referencias fabricadas (diferentes modelos citan diferentes fuentes; las citas contradictorias señalan el problema)
- Estadísticas y puntos de datos inventados (es poco probable que el 47% fabricado de un modelo coincida con el 47% fabricado de otro modelo)
- Entidades, jurisprudencia, trabajos de investigación inventados (es difícil para cinco modelos inventar de forma independiente el mismo caso inexistente)
- Errores de razonamiento donde un modelo toma un atajo lógico que otro modelo cuestiona
Detecta menos bien:
- Errores presentes en datos de entrenamiento compartidos (todos los modelos entrenados con el mismo artículo incorrecto de Wikipedia reproducirán el mismo error)
- Conceptos erróneos ampliamente aceptados codificados en múltiples conjuntos de entrenamiento
- Sesgos sistemáticos compartidos entre familias de modelos (por ejemplo, narrativas históricas centradas en Occidente)
La validación multimodelos es una capa de detección, no una garantía. Aumenta la probabilidad de detectar alucinaciones. No las elimina. Las organizaciones que obtienen los mejores resultados combinan la validación cruzada multimodelos con la verificación específica del dominio, los puntos de control de revisión humana y la fundamentación habilitada por herramientas. [27]
La brecha de investigación
Todavía hay informes públicos estandarizados limitados que midan «la validación cruzada de cinco modelos reduce la alucinación en un X%» en todos los dominios bajo condiciones controladas. La mejora del 8% del marco UAF es el número único más sólido. Están surgiendo estudios de casos de producción de plataformas multimodelos, pero aún no se han publicado en revistas revisadas por pares.
La posición más segura basada en la evidencia: la orquestación multimodelos es una arquitectura de reducción de riesgos que aumenta la probabilidad de detección. No es una garantía de cero alucinaciones. Ningún enfoque logra esa garantía, como demuestran las pruebas matemáticas en la Sección 11.
Pruebe la verificación de hechos entre modelos con su propia pregunta.
Pregunte algo donde la precisión importe. Observe cómo responden cinco modelos de IA y vea dónde discrepan.
Herramientas de detección de alucinaciones de IA
El panorama de las herramientas
El mercado de detección de alucinaciones creció un 318% de 2023 a 2025, con 12.800 millones de dólares invertidos en soluciones dedicadas. Esta tasa de crecimiento refleja la seriedad con la que las empresas se toman el problema y lo inadecuadas que son las salvaguardas integradas en los modelos para el uso en producción. [35]
Principales herramientas de detección (2025-2026)
| Herramienta | Precisión de detección | Punto fuerte clave |
| W&B Weave | 91% | Razonamiento en cadena de pensamiento, integración de flujo de trabajo de producción |
| Arize Phoenix | 90% | Salidas basadas en etiquetas, puntuación de confianza, monitorización en tiempo real |
| Comet Opik | 72% | 100% de precisión (cero falsos positivos), enfoque conservador |
| Galileo | N/A | Puntuación del Índice de Alucinación, bloqueo en tiempo real, integración CI/CD |
| Verificación de citas GPTZero | 99%+ | Citas verificadas contra bases de datos web/académicas |
| AGI Futura | N/A | Detección de alucinaciones específicas de RAG, monitorización de experimentos |
| Pythia | N/A | Verificación de hechos basada en grafos de conocimiento, industrias reguladas |
Fuentes: Benchmark AIMultiple (2026) [46], Future AGI (2025) [47], GPTZero/Fortune [45]
Lo que significa la brecha de precisión
Las principales herramientas de detección detectan el 90-91% de las alucinaciones. Esto significa que aproximadamente 1 de cada 10 resultados alucinados aún pasa desapercibido a través de la mejor verificación automatizada disponible. Para aplicaciones donde una sola alucinación no detectada tiene consecuencias materiales —documentos legales, decisiones médicas, informes financieros—, la detección automatizada es una capa necesaria, pero no suficiente.
El enfoque de Comet Opik merece una mención aparte. Con una precisión de detección del 72%, detecta menos alucinaciones. Pero tiene una precisión del 100% —cero falsos positivos—. Nunca marca una afirmación correcta como alucinada. Para flujos de trabajo donde las falsas alarmas son costosas (interrumpir a un médico en medio de un diagnóstico, marcar una cita legal correcta para revisión), esta compensación puede ser preferible.
Progresión histórica
Cuatro años de mejora en tareas simples
| Año | Mejor tasa de alucinación | Contexto |
| 2021 | ~21,8% | Era temprana de GPT-3 |
| 2022 | ~15,0% | Mejoras de alineación RLHF |
| 2023 | ~8,0% | Lanzamiento de GPT-4 y presión competitiva |
| 2024 | ~3,0% | Rápida iteración en todos los proveedores |
| 2025 | 0.7% | Gemini-2.0-Flash en el conjunto de datos original de Vectara |
Fuentes: AllAboutAI [31]; Vectara HHEM [1]
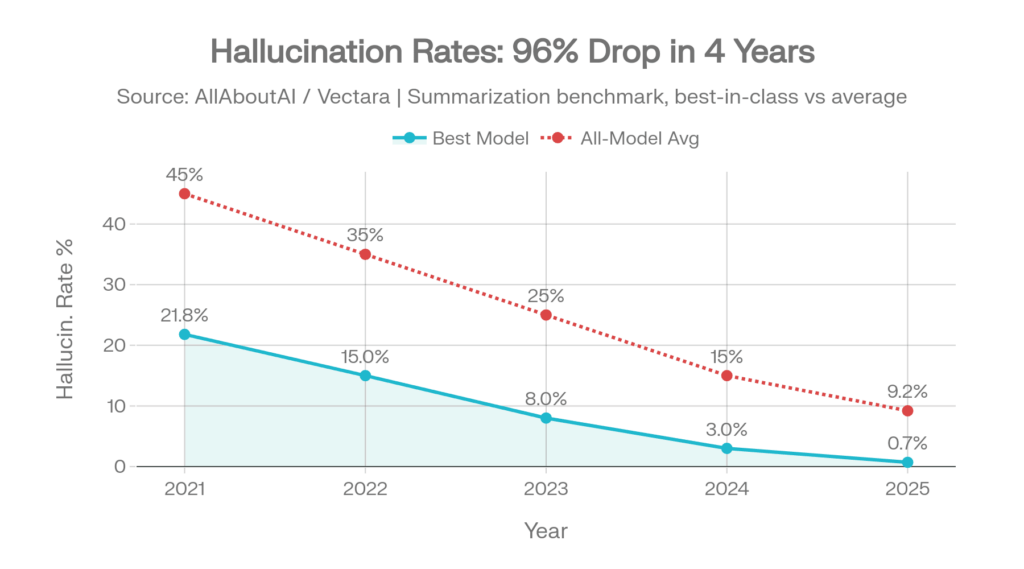
Cuatro años de mejora en la alucinación en tareas de resumen simples: 21,8% → 0,7%. Fuentes: Vectara [1], AllAboutAI [31]
Eso es una reducción del 96% en las tasas de alucinación del mejor modelo en cuatro años en el benchmark de resumen de Vectara. La tendencia es real y pronunciada.
La comprobación de la realidad
Estas mejoras miden la versión más fácil del problema: resumir documentos cortos sin añadir hechos sin fundamento. Cuando se pasa a evaluaciones más difíciles y realistas, la imagen cambia:
AA-Omniscience (preguntas de conocimiento difíciles): 36 de 40 modelos tienen más probabilidades de dar una respuesta incorrecta y segura que una correcta. Solo cuatro modelos lograron un Índice de Omnisciencia positivo. [2]
HalluHard (conversaciones realistas): Incluso el mejor modelo (Claude Opus 4.5 con búsqueda web) alucina el 30% de las veces. La mayoría de los modelos se encuentran en el rango del 50-70%. [5]
Nuevo conjunto de datos de Vectara (documentos de longitud empresarial): las tasas aumentan de 3 a 10 veces en comparación con el conjunto de datos original. La mejor puntuación es del 3,3%, no del 0,7%. [1]
Tareas específicas del dominio: la alucinación legal promedia el 18,7%. La médica promedia el 15,6%. Estas no han mostrado la misma trayectoria de mejora que el resumen general. [31]
La mejora es real. Pero extrapolar de puntos de referencia simples a la fiabilidad empresarial es un error que los datos no respaldan.
Metodología y cómo leer estos datos
Fuentes
Esta página se basa en las siguientes fuentes primarias:
Benchmarks: Vectara HHEM Leaderboard (tanto el conjunto de datos original de ~1.000 documentos como el conjunto de datos actualizado de 7.700 artículos), Artificial Analysis AA-Omniscience, Google DeepMind FACTS Benchmark, OpenAI SimpleQA y PersonQA, HalluHard (consorcio de investigación suizo-alemán) y el estudio de precisión de citas de Columbia Journalism Review.
Tarjetas de sistema e informes técnicos: tarjeta de sistema OpenAI GPT-5, actualización de implementación GPT-5.2, tarjeta de sistema o3/o4-mini, anuncios de modelos Anthropic para Claude Opus 4.5/4.6 y Sonnet 4.6, documento de metodología Google DeepMind FACTS.
Estudios de la industria y datos de incidentes: estudio de IA legal de Stanford RegLab/HAI, investigación de alucinaciones médicas de MedRxiv, Encuesta Global de IA de Deloitte, análisis de costes de IA empresarial de Forrester, compilación de estadísticas de alucinaciones de AllAboutAI, rastreador de sentencias judiciales de Business Insider, base de datos de alucinaciones de citas legales de Damien Charlotin y el análisis NeurIPS 2025 de GPTZero/Fortune.
Investigación académica: Xu et al. (2024) sobre la imposibilidad de eliminar las alucinaciones, Karpowicz (2025) sobre la imposibilidad matemática en tres marcos de prueba, marco de fusión consciente de la incertidumbre de Amazon/ACM WWW 2025, verificación en tiempo de entrenamiento VeriFY de ICML 2025, cadena de verificación de ACL 2024.
Adiciones de abril de 2026: Informe del Índice de IA de Stanford HAI 2026 (benchmark de adulación y base de datos de incidentes de IA), instantánea de Vectara HHEM del 20 de abril de 2026, estado de Artificial Analysis AA-Omniscience de abril de 2026 (Claude Opus 4.7, GPT-5.5, Grok 4.20), base de datos de Damien Charlotin (más de 1.200 casos legales), OpenAI HealthBench Professional y la edición de abril de 2026 del Índice de Divergencia Multimodelo de Suprmind.
Datos de producción de primera mano
Esta página ahora incluye datos del Índice de Divergencia Multimodelo (DMI) de Suprmind, una publicación trimestral que rastrea los patrones de desacuerdo y corrección entre modelos en el uso real de producción de la plataforma Suprmind. La edición de abril de 2026 cubre 1.324 turnos de conversación multimodelos de 299 usuarios en 10 dominios durante un período de 45 días (del 5 de marzo al 19 de abril de 2026). [61][62]
Lo que mide el DMI: con qué frecuencia los modelos de IA se contradicen, se corrigen y sacan a la luz ideas que otros modelos pasaron por alto cuando se ejecutan juntos en la misma pregunta.
Lo que el DMI no mide: la precisión fáctica frente a la verdad. El DMI registra que un modelo contradijo a otro. No juzga qué modelo era correcto. El desacuerdo se trata como una señal de detección, no como un veredicto sobre la precisión.
Tratamos los datos del DMI y los benchmarks de precisión como complementarios, no intercambiables. Vectara, AA-Omniscience, FACTS y los otros benchmarks de esta página miden con qué frecuencia los modelos se equivocan de forma aislada. El DMI mide con qué frecuencia los modelos se detectan entre sí en producción. Ambas preguntas importan. No son la misma pregunta.
El conjunto de datos DMI, la metodología y los doce archivos CSV subyacentes están disponibles públicamente en la página enlazada en las referencias. Los datos de cuentas internas están excluidos; el conjunto de datos publicado es solo para usuarios externos.
Frecuencia de actualización: trimestral. Próxima edición: julio de 2026.
Lo que excluimos
TruthfulQA — parcialmente saturado. Incluido en los datos de entrenamiento del modelo, contiene algunas respuestas doradas incorrectas y puede ser manipulado para lograr un 79,6% de precisión mediante un árbol de decisión que nunca ve la pregunta.
HaluEval — resoluble por longitud de respuesta. Un clasificador que marca las respuestas de más de 27 caracteres como alucinadas logra un 93,3% de precisión, lo que socava la validez del benchmark para la comparación de modelos.
Benchmarks comunitarios no verificados — se excluyeron las publicaciones de Reddit, las afirmaciones de Twitter y los artículos de blog que citaban números de benchmark sin documentación de metodología o información de reproducibilidad, a menos que pudieran ser cotejados con fuentes primarias.
Afirmaciones de marketing de proveedores — cuando un proveedor afirma una tasa de alucinación específica, pero los benchmarks independientes muestran números diferentes, ambos se presentan con la discrepancia señalada. Esto se aplica particularmente a los benchmarks internos de Grok de xAI frente a los resultados de AA-Omniscience.
Fechas y versiones de los benchmarks
Las instantáneas de Vectara están fechadas. El conjunto de datos original se evaluó hasta abril de 2025. El conjunto de datos actualizado cubre de noviembre de 2025 a febrero de 2026, con la instantánea más reciente fechada el 25 de febrero de 2026. AA-Omniscience se lanzó en noviembre de 2025 y se ha actualizado a medida que se lanzan nuevos modelos. FACTS se publicó en diciembre de 2025. Las tarjetas de sistema de OpenAI están fechadas según la versión.
Cuando dos benchmarks muestran números diferentes para el mismo modelo, esto generalmente refleja diferentes fechas de evaluación, diferentes versiones del conjunto de datos o diferentes aspectos de la factualidad que se están midiendo. Señalamos estas discrepancias en lugar de promediarlas.
Lagunas de datos conocidas
Los modelos Perplexity Sonar no figuran en AA-Omniscience ni en Vectara. Perplexity utiliza modelos subyacentes (incluidas variantes de GPT y DeepSeek) lo que hace que la atribución de alucinaciones sea compleja. Sus resultados de SimpleQA y Search Arena se incluyen cuando están disponibles.
Claude Opus 4.6 y Sonnet 4.6 se lanzaron en febrero de 2026. Los datos de AA-Omniscience están apareciendo, pero son tempranos. Las puntuaciones del nuevo conjunto de datos de Vectara aún no están disponibles para la generación 4.6.
GPT-5.3 tiene datos de AA-Omniscience (51,8% de precisión para la variante Codex), pero una cobertura limitada en otros benchmarks a partir de este escrito.
Los desgloses específicos del dominio para la mayoría de los benchmarks prueban el conocimiento general. Los datos de alucinación específicos de la industria (financiera, médica, legal) provienen principalmente de estudios especializados en lugar de los principales leaderboards.
Las cifras de costes empresariales provienen de encuestas y estimaciones en lugar de bases de datos de incidentes verificadas. La cifra de 67.400 millones de dólares, los costes de verificación por empleado y los rangos por incidente deben tratarse como indicativos en lugar de precisos.
Frecuencia de actualización
Mensual: instantáneas del leaderboard de Vectara, nuevas adiciones de modelos de AA-Omniscience, actualizaciones de tarjetas de sistema de OpenAI, nuevos datos de lanzamiento de modelos.
Trimestral: cambios en el leaderboard de FACTS, introducción de nuevos benchmarks, hallazgos de artículos académicos, desarrollos regulatorios (particularmente la aplicación de la Ley de IA de la UE relacionada con los requisitos de precisión).
Según sea necesario: lanzamientos importantes de modelos, informes de incidentes significativos, hitos de sentencias judiciales y cambios en la metodología de los benchmarks.
Preguntas frecuentes
Preguntas frecuentes sobre las alucinaciones de IA
¿Qué es una tasa de alucinación de IA?
Una tasa de alucinación de IA mide con qué frecuencia un modelo genera información falsa o fabricada presentada como un hecho. La tasa varía según el benchmark porque diferentes pruebas miden diferentes modos de fallo. Vectara mide con qué frecuencia un modelo añade hechos inventados al resumir un documento. AA-Omniscience mide con qué frecuencia un modelo da una respuesta incorrecta y segura en lugar de admitir que no sabe. FACTS mide la factualidad en cuatro dimensiones: fundamentación, multimodal, conocimiento paramétrico y búsqueda. Un modelo puede obtener un 0,7% en Vectara y un 88% en AA-Omniscience simultáneamente porque las pruebas miden cosas completamente diferentes.
¿Qué modelo de IA tiene la tasa de alucinación más baja en 2026?
No hay una respuesta única, depende completamente de la tarea. En preguntas de conocimiento donde el modelo debe admitir ignorancia: Claude 4.1 Opus logró un 0% de alucinación en AA-Omniscience al negarse a responder en lugar de adivinar. En resumen de documentos: Gemini-2.0-Flash lidera el conjunto de datos original de Vectara con una tasa de alucinación del 0,7%. En factualidad multidimensional: Gemini 3 Pro obtuvo 68,8 en el benchmark FACTS. En tareas conversacionales realistas: Claude Opus 4.5 logró un 30% en HalluHard con la búsqueda web habilitada. Ningún modelo único lidera en todos los benchmarks.
¿Cuál es la tasa de alucinación de Claude en 2026?
La tasa de alucinación de Claude varía significativamente según la versión del modelo y el benchmark. Claude 4.1 Opus: 0% de alucinación en AA-Omniscience (se niega a responder en lugar de adivinar), puntuación FACTS 46,5. Claude Opus 4.6: 12,2% en el nuevo conjunto de datos de Vectara, 46,4% de precisión en AA-Omniscience, Índice de Omnisciencia 14. Claude Opus 4.5: 45,7% de precisión en AA-Omniscience con una tasa de alucinación del 58%, puntuación FACTS 51,3, 30% en HalluHard. Claude Sonnet 4.6: 10,6% en el nuevo conjunto de datos de Vectara, aproximadamente 38% de tasa de alucinación en AA-Omniscience. Claude 4.5 Haiku: 25% de tasa de alucinación en AA-Omniscience, la tercera más baja de cualquier modelo probado. En el conjunto de datos más difícil de Vectara, los modelos Claude superan consistentemente el 10%.
¿Cuál es la tasa de alucinación de GPT-5?
GPT-5.3 Codex: 51,8% de precisión en AA-Omniscience, aún sin datos de Vectara. GPT-5.2 (xhigh): 10,8% en el nuevo conjunto de datos de Vectara, 43,8% de precisión en AA-Omniscience con aproximadamente un 78% de tasa de alucinación, puntuación FACTS 61,8, HalluHard 38,2%. GPT-5: 1,4% en el Vectara original, más del 10% en el nuevo conjunto de datos, 40,7% de precisión en AA-Omniscience. GPT-4.1: 2,0% en el Vectara original, 5,6% en el nuevo, puntuación FACTS 50,5. GPT-5.2 obtiene la puntuación más alta entre los modelos de OpenAI en FACTS (61,8), pero alucina aproximadamente un 78% en las preguntas de conocimiento difíciles de AA-Omniscience.
¿Cuál es la tasa de alucinación de Grok en 2026?
Grok 4: 4,8% en el Vectara original, más del 10% en el nuevo conjunto de datos, 41,4% de precisión en AA-Omniscience con una tasa de alucinación del 64%, puntuación FACTS 53,6. Grok 4.1 Fast Reasoning: 20,2% en el nuevo conjunto de datos de Vectara (el más alto de cualquier modelo de vanguardia probado), 72% de tasa de alucinación en AA-Omniscience, puntuación FACTS 36,0. Grok-3: 2,1% en el Vectara original, 5,8% en el nuevo, 94% de alucinación de citas en CJR. La variante Grok 4.1 Fast Reasoning funciona notablemente peor que la base Grok 4, lo que sugiere que el modo de razonamiento añade inferencias que se convierten en alucinaciones en tareas fácticas.
¿Cuál es la tasa de alucinación de Gemini en 2026?
Gemini 3.1 Pro: 10,4% en el nuevo conjunto de datos de Vectara, 55,3% de precisión en AA-Omniscience (la más alta de cualquier modelo) con una tasa de alucinación del 50%, Índice de Omnisciencia 33 (el más alto en general). Gemini 3 Pro: 13,6% en el nuevo Vectara, 55,9% de precisión, pero 88% de alucinación en AA-Omniscience, puntuación FACTS 68,8 (la más alta en general). Gemini 2.0 Flash: 0,7% en el Vectara original (el más bajo de cualquier modelo), 3,3% en el nuevo conjunto de datos. La actualización 3.1 Pro fue significativa: la alucinación se redujo del 88% al 50% con solo un 1% de pérdida de precisión. Los modelos Gemini son los que más saben, pero fabrican de forma más agresiva cuando no están seguros.
¿Cuál es la tasa de alucinación de Perplexity?
Perplexity Sonar Pro obtuvo un 37% de alucinación de citas en el benchmark de Columbia Journalism Review, la más baja de cualquier modelo probado, pero aún así significa que más de una de cada tres fuentes citadas contenía afirmaciones fabricadas. ChatGPT alcanzó el 67% en la misma prueba. Gemini alcanzó el 76%. Grok-3 llegó al 94%. El modo de fallo de Perplexity es singularmente peligroso: las URL que cita son reales, pero la información que atribuye a esas fuentes a veces es fabricada. No existen datos de benchmark de Vectara o AA-Omniscience para los modelos Perplexity Sonar.
¿Por qué diferentes benchmarks dan diferentes tasas de alucinación para el mismo modelo de IA?
Diferentes benchmarks miden modos de fallo fundamentalmente distintos. Vectara prueba la fidelidad del resumen. AA-Omniscience prueba la calibración del conocimiento. FACTS prueba la factualidad multidimensional en tareas de fundamentación, multimodalidad, conocimiento paramétrico y búsqueda. CJR prueba la precisión de las citas. Un modelo como Grok-3 obtiene un 2,1% en Vectara (se adhiere bien a los documentos fuente) pero un 94% en CJR (fabrica casi todas las citas). Ambos números son precisos. Miden diferentes habilidades. El enfoque responsable: cotejar al menos dos benchmarks que midan cosas diferentes, especificar la versión exacta del modelo y la configuración, y señalar si la búsqueda web o el modo de razonamiento estaban habilitados.
¿Se pueden eliminar por completo las alucinaciones de la IA?
No. Dos pruebas matemáticas independientes han demostrado que la alucinación es una limitación fundamental de la arquitectura del modelo de lenguaje. No es un problema de ingeniería que espere una solución. Las mejores tasas de alucinación han disminuido del 21,8% al 0,7% en cuatro años en tareas de resumen simples. Pero en tareas más difíciles —preguntas legales (18,7% de media), consultas médicas (15,6%), preguntas de conocimiento que requieren que el modelo se base en sus propios datos de entrenamiento— las tasas siguen siendo altas en todos los modelos. La comunidad de investigación ha pasado de eliminar las alucinaciones a gestionar el riesgo de alucinación mediante la detección, el marcado, la contención y la validación cruzada. El acceso a la búsqueda web es el mayor reductor, disminuyendo las tasas de alucinación entre un 73% y un 86% cuando está habilitado.
¿Cuánto cuestan las alucinaciones de la IA a las empresas?
Las pérdidas empresariales globales por alucinaciones de IA alcanzaron un estimado de 67.400 millones de dólares en 2024. El 47% de los ejecutivos empresariales informaron haber tomado decisiones importantes basándose en contenido generado por IA no verificado. El 66% de los usuarios confían en la salida de la IA sin evaluar su precisión. Hay más de 944 casos legales documentados que involucran información falsa generada por IA. Los costes específicos del dominio oscilan entre 18.000 dólares por incidente de servicio al cliente y 2,4 millones de dólares en casos de negligencia médica. La FDA ha autorizado más de 1.350 dispositivos médicos mejorados con IA, con 60 dispositivos involucrados en 182 retiradas del mercado.
¿El uso de múltiples modelos de IA reduce la alucinación?
La investigación apoya cada vez más esto. Diferentes modelos de IA rara vez alucinan la misma información falsa porque tienen diferentes datos de entrenamiento, diferentes arquitecturas y diferentes puntos ciegos. Un estudio del marco UAF midió una mejora del 8% en la precisión a través de enfoques de conjunto multimodelos. El desacuerdo entre modelos detecta fabricaciones específicamente porque los modos de fallo no se superponen. Cuando tres modelos analizan la misma pregunta y dos discrepan con el tercero, el desacuerdo en sí mismo es una señal de que una afirmación necesita revisión humana. Este es el principio detrás de las plataformas de orquestación multi-IA que dirigen las preguntas a múltiples modelos de vanguardia simultáneamente. Vea cómo Suprmind utiliza este enfoque →
Referencias y fuentes
Benchmarks y Leaderboards
- Vectara. «Hallucination Leaderboard (HHEM-2.3)». Repositorio de GitHub. Última actualización: 25 de febrero de 2026. github.com/vectara/hallucination-leaderboard
- Artificial Analysis. «AA-Omniscience: Knowledge and Hallucination Benchmark». Noviembre de 2025. artificialanalysis.ai/evaluations/omniscience
- Google DeepMind. «FACTS Grounding: Evaluating and Improving Factuality in Large Language Models». FACTS Benchmark Suite, diciembre de 2025.
- OpenAI. «SimpleQA: Measuring Short-form Factuality». OpenAI Research, 2024.
- Müller, R. et al. «HalluHard: A Challenging Hallucination Benchmark for Realistic Conversations». 2025. the-decoder.com
- Columbia Journalism Review. «AI Citation Accuracy Study». Marzo de 2025.
- OpenAI. «HALOGEN: Evaluating Hallucination of Generative Foundation Models». arXiv, 2024. arxiv.org/abs/2404.00730
Tarjetas de sistema de modelos y anuncios de proveedores
- OpenAI. «GPT-5 System Card». Agosto de 2025. Resumen de W&B
- OpenAI. «Introducing GPT-5.2». Diciembre de 2025. openai.com
- OpenAI. «GPT-5.3 Instant: Conversaciones cotidianas más fluidas y útiles». Marzo de 2026. openai.com
- OpenAI. «o3 and o4-mini System Card». 2025. openai.com (PDF)
- OpenAI. «GPT-5 hallucinates less». Mashable, agosto de 2025. mashable.com
- Anthropic. «Introducing Claude Sonnet 4.6». Febrero de 2026. anthropic.com
- Anthropic. «Claude Opus 4.5 Benchmarks and Analysis». Artificial Analysis, noviembre de 2025. artificialanalysis.ai
- Artificial Analysis. «Gemini 3.1 Pro Preview: The new leader in AI». Febrero de 2026. artificialanalysis.ai
- Artificial Analysis. «Gemini 3 Flash — Everything you need to know». Diciembre de 2025. artificialanalysis.ai
- Digital Applied. «Grok 4.1: xAI Emotional AI Complete Guide». 2026. digitalapplied.com
- Perplexity AI. «Perplexity Sonar Dominates New Search Arena Evaluation». perplexity.ai
- Perplexity AI. «Introducing the Sonar Pro API». perplexity.ai
Investigación académica — Teoría e imposibilidad de las alucinaciones
- Xu, Z. et al. «Hallucination is Inevitable: An Innate Limitation of Large Language Models». arXiv, 2024. arxiv.org/abs/2401.11817
- Karpowicz, M. «On the Fundamental Impossibility of Hallucination Control in Large Language Models». arXiv, 2025. arxiv.org/abs/2506.06382v3
- OpenAI / Computerworld. «OpenAI admite que las alucinaciones de IA son matemáticamente inevitables». computerworld.com
Investigación académica — Técnicas de reducción de alucinaciones
- Dhuliawala, S. et al. «Chain-of-Verification Reduces Hallucination in Large Language Models». ACL 2024 Findings. aclanthology.org
- Luo, Y. et al. «Uncertainty-Aware Super Mind: An Ensemble Framework for Mitigating Hallucinations in Large Language Models». Amazon / ACM WWW 2025. arxiv.org/abs/2503.05757
- Zhou, Y. et al. «Do I Really Know? Learning Factual Self-Verification for LLMs (VeriFY)». ICML 2025. arxiv.org
- Singh, A. et al. «Combining CoT, RAG, Self-Consistency, and Self-Verification». arXiv, 2025. arxiv.org/abs/2505.09031
- Li, J. et al. «Mitigating Hallucination in Large Language Models (LLMs): Survey». arXiv, 2025. arxiv.org
Investigación académica — Enfoques de conjunto y multimodelo
- Schoenegger, P. et al. «Wisdom of the silicon crowd: LLM ensemble prediction capabilities rival the human crowd». PNAS / PMC, 2025. pmc.ncbi.nlm.nih.gov
Críticas a la metodología de los bancos de pruebas
- Hilgard, S. «Gaming TruthfulQA: Simple Heuristics Exposed Dataset Weaknesses». turntrout.com
- Li, J. et al. «HaluEval: A Large-Scale Hallucination Evaluation Benchmark». arXiv. Crítica referenciada: solucionable mediante heurística de longitud de respuesta.
Estudios e informes del sector
- AllAboutAI. «Estadísticas de alucinaciones de IA e informe de investigación 2025-2026». Fuente de compilación principal para tasas específicas del dominio, cifras de impacto empresarial y datos de progresión histórica.
- Deloitte. «Global AI Survey 2025». Fuente de estadísticas sobre la toma de decisiones ejecutivas (el 47 % tomó decisiones basadas en contenido de IA no verificado).
- Forrester. «Enterprise AI Cost Analysis 2025». Fuente de datos sobre el coste de verificación por empleado (14.200 $/año, 4,3 horas/semana).
- Testlio. «AI Testing and Quality Report 2025». Fuente de estadísticas sobre errores de IA en producción (el 82 % provienen de alucinaciones, tasa de retrabajo de chatbots del 39 %).
- Gartner. «Hallucination Detection Tools Market Report 2025». Fuente de la cifra de crecimiento del mercado del 318 % y de la inversión total de 12.800 millones de dólares.
Datos sobre alucinaciones legales
- Stanford RegLab / Stanford Human-Centered AI Institute (HAI). «Legal AI Hallucination Study». hai.stanford.edu
- Charlotin, D. «AI Hallucination Cases Database». Sciences Po / HEC Paris. Más de 1.200 casos globales documentados (abril de 2026), aproximadamente 800 en tribunales de EE. UU. damiencharlotin.com/hallucinations
- Business Insider. Rastreador de fallos judiciales: 10 casos (2023), 37 (2024), 73 (primeros 5 meses de 2025), más de 50 (solo en julio de 2025).
Datos sobre alucinaciones en el sector sanitario
- ECRI. «Top 10 Health Technology Hazards for 2025». Los riesgos de la IA ocupan el puesto n.º 1.
- MedRxiv. «Medical Case Hallucination Study 2025». 64,1 % sin mitigación, 43,1 % con mitigación, GPT-4o del 53 % al 23 %.
- NIH / PMC. «Marked reduction in hallucination rates with GPT-5». pmc.ncbi.nlm.nih.gov
- FDA. Datos de dispositivos médicos mejorados con IA: 1.357 autorizados, 60 implicados en 182 retiradas, 43 % en el primer año.
Datos sobre alucinaciones financieras
- Datos de cumplimiento de la SEC: 12,7 millones de dólares en multas por declaraciones falsas de IA, 2024-2025.
- Informes del sector (agregados): el 78 % de las empresas financieras despliegan IA; 15-25 % de alucinaciones sin salvaguardas; entre 50.000 $ y 2,1 millones de $ por incidente.
Integridad académica
- GPTZero / Fortune. «NeurIPS research papers contained 100+ AI-hallucinated citations that survived peer review». Enero de 2026. fortune.com
Herramientas de detección
- AIMultiple. «AI Hallucination Detection Tools Benchmark 2026». W&B Weave 91 %, Arize Phoenix 90 %, Comet Opik 72 %. research.aimultiple.com
- Future AGI. «Top 5 AI Hallucination Detection Tools in 2025». futureagi.com
Estudios detallados de Vectara
- Vectara. «DeepSeek-R1 hallucinates more than DeepSeek-V3». vectara.com
- Vectara. «Why does Deepseek-R1 hallucinate so much?». vectara.com
Datos específicos del modelo (adicional)
- Datos de la comunidad Reddit / AA-Omniscience. «Sonnet 4.6 significantly decreases hallucinations compared to Opus». reddit.com
- Incremys. «Perplexity AI statistics: 2025-2026 trends and SEO impact». incremys.com
- Vellum. «GPT-5 Benchmarks». Análisis profundo de HealthBench. vellum.ai
- Tech Transformation. «OpenAI’s o3 and o4-mini Reasoning Models Exhibit Increased Hallucination». tech-transformation.com
- Blockchain.news. «PersonQA Benchmark Reveals Increasing Hallucination Rates in OpenAI Models». blockchain.news
- Voronoi App. «Leading AI Models Show Persistent Hallucinations Despite Accuracy Gains». voronoiapp.com
Referencias regulatorias
- Ley de IA de la UE, Artículo 15. «Los sistemas de IA de alto riesgo deben alcanzar un nivel adecuado de precisión y funcionar de forma coherente durante todo su ciclo de vida». EUR-Lex.
- NIST. «AI Risk Management Framework (AI RMF 1.0)». Incluyendo el perfil complementario AI 600-1, aprobado en julio de 2024.
Adiciones de abril de 2026
- Stanford HAI. «2026 AI Index Report — Responsible AI Chapter». Stanford Human-Centered AI Institute, publicado el 13 de abril de 2026. hai.stanford.edu/ai-index/2026-ai-index-report
- The Ethics Reporter. «The Plague Spreads: How 1,200 AI Hallucination Cases Prove the Failed Register». 12 de abril de 2026. theethicsreporter.com
- OpenAI. «HealthBench Professional — Clinician-Grade Health AI Benchmark». Publicado el 22 de abril de 2026. openai.com (PDF)
- Suprmind. «Multi-Model Divergence Index — April 2026 Edition». Publicado en abril de 2026. suprmind.ai/hub/multi-model-ai-divergence-index
- Suprmind. «DMI April 2026 Edition — Public CSV Bundle (12 archivos: contradicciones, correcciones, perspectivas, gravedad, desgloses por dominio)». suprmind.ai/hub/multi-model-ai-divergence-index/#downloads
- Kingy AI. «GPT-5.5 vs. Claude Opus 4.7: A Benchmark-by-Benchmark Field Guide to the New Frontier». 22 de abril de 2026. kingy.ai
Deje de confiar en una sola IA para las decisiones importantes.
Cinco modelos Frontier. Una conversación. Cada respuesta es verificada. Descubra por qué los profesionales que no pueden permitirse errores se están pasando a la validación multimodelo.