If your decision would change a portfolio, a contract, or a clinical pathway, a single AI’s answer isn’t enough. One model’s output can be fast but brittle. It may carry blind spots, style biases, or overconfident hallucinations that slip past even careful reviewers.
Manually cross-checking across tools slows teams and still leaves gaps. You toggle between chat windows, copy-paste prompts, and reconcile conflicting answers without a clear audit trail. The friction compounds when stakes rise.
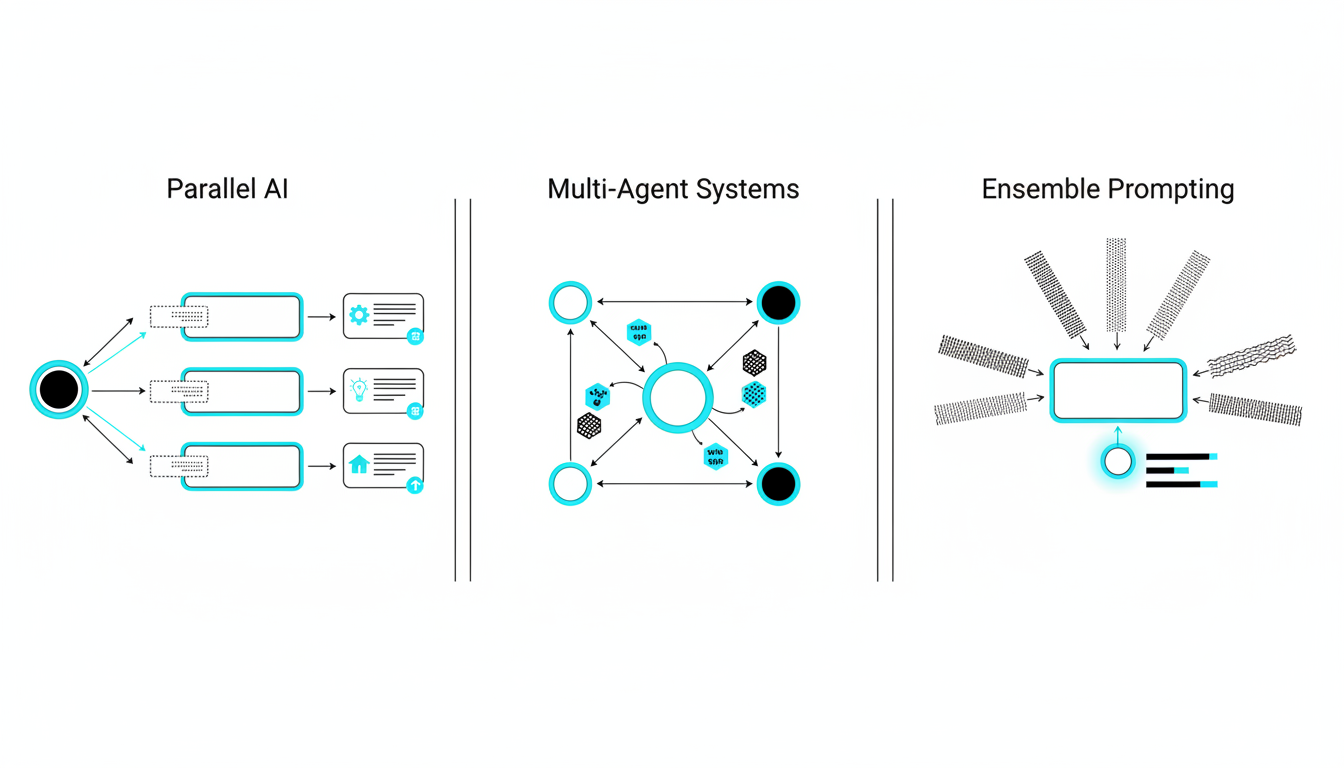
Parallel AI orchestrates multiple models to analyze the same problem, compare reasoning, and surface consensus or useful dissent with evidence. Instead of relying on a single perspective, you run several models simultaneously or sequentially and synthesize their outputs into a validated conclusion.
This approach reduces single-model bias, broadens analytical coverage, and creates an auditable rationale. When implemented through multi-LLM orchestration platforms, parallel AI transforms high-stakes knowledge work from isolated chat sessions into structured decision validation workflows.
Parallel AI vs Multi-Agent Systems vs Ensemble Prompting
The term “parallel AI” often gets conflated with related concepts. Clarity on definitions helps you choose the right architecture for your workflow.
Parallel AI: Simultaneous Model Analysis
Parallel AI runs multiple large language models against the same prompt or problem set. Each model processes the input independently. You then compare their outputs, identify consensus, flag dissent, and synthesize a final answer grounded in evidence from all sources.
- Input: One prompt or document set sent to multiple models at once
- Process: Models analyze independently without inter-model communication
- Output: Multiple perspectives that you reconcile manually or through fusion logic
- Use case: Decision validation, bias reduction, coverage expansion
Multi-Agent Systems: Autonomous Task Delegation
Multi-agent frameworks assign specialized tasks to different AI agents. Agents communicate, delegate sub-tasks, and coordinate toward a shared goal. This approach suits complex workflows with distinct roles.
- Input: High-level objective decomposed into sub-tasks
- Process: Agents negotiate, share intermediate results, and iterate
- Output: Coordinated solution from distributed agents
- Use case: Research pipelines, code generation with testing loops, data pipelines
Ensemble Prompting: Aggregating Variations
Ensemble prompting runs variations of the same prompt (rephrased or role-adjusted) through one or more models and aggregates the results. It’s simpler than parallel AI but less robust for bias detection.
- Input: Multiple prompt variations for the same question
- Process: Collect outputs and vote or average responses
- Output: Consolidated answer from prompt diversity
- Use case: Quick consensus checks, exploratory research
Parallel AI sits between ensemble prompting and multi-agent systems. It offers more rigor than simple aggregation but less coordination overhead than full agent frameworks. For high-stakes analysis, parallel AI’s independent model runs and explicit dissent tracking deliver the right balance.
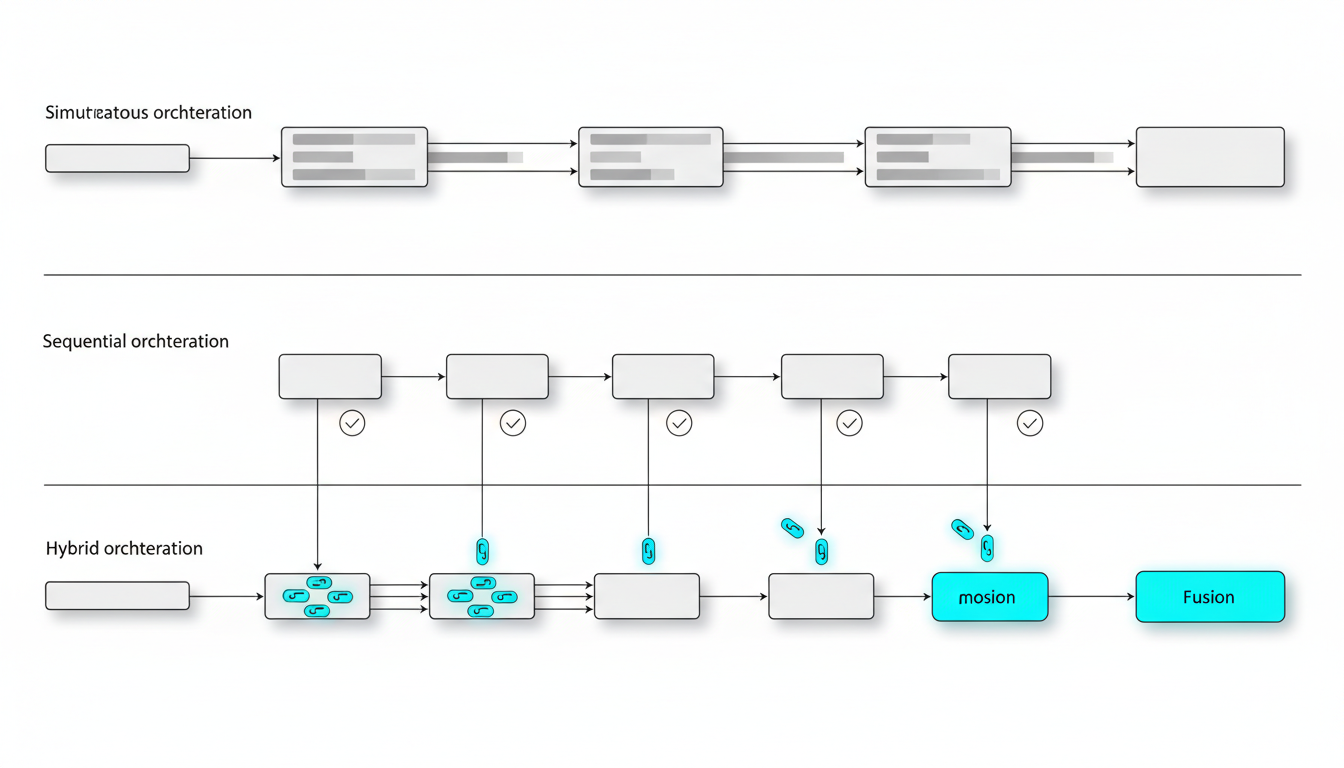
Architectural Patterns: Simultaneous, Sequential, and Hybrid Orchestration
How you orchestrate models determines speed, depth, and auditability. Three core patterns address different workflow needs.
Simultaneous Orchestration
Send the same prompt to all models at once. Collect outputs in parallel. This pattern maximizes speed and surfaces diverse perspectives quickly.
- Strengths: Fast turnaround, broad coverage, easy dissent detection
- Weaknesses: No inter-model learning, requires manual synthesis
- Best for: Rapid validation, initial scans, broad risk assessments
Platforms that support persistent context management with Context Fabric can maintain each model’s rationale across sessions, making simultaneous runs auditable over time.
Sequential Orchestration
Run models one after another. Each model’s output informs the next prompt. This pattern enables refinement and follow-up questions based on earlier findings.
- Model A generates initial analysis
- Model B critiques or expands on Model A’s output
- Model C synthesizes both and proposes next steps
- Repeat until convergence or resource limits
Sequential flows work well for complex research where you need to map relationships in a Knowledge Graph and link evidence across rounds. The trade-off is longer cycle time.
Hybrid Orchestration
Combine simultaneous and sequential patterns. Run an initial parallel scan, then feed high-priority findings into sequential refinement rounds. This approach balances speed and depth.
- Phase 1: Simultaneous scan of 5 models for broad coverage
- Phase 2: Sequential deep-dive on flagged risks or gaps
- Phase 3: Fusion synthesis with dissent matrix
Hybrid orchestration suits due diligence workflows where you need both breadth and targeted depth.
Where Parallelization Helps and Where It Doesn’t
Parallel AI reduces certain risks but cannot fix all failure modes. Understanding its boundaries prevents misapplication.
Where Parallel AI Excels
- Bias reduction: Different models have different training data and alignment targets. Running multiple models surfaces perspective diversity.
- Coverage expansion: One model may miss edge cases another catches. Parallel runs increase the chance of identifying outliers.
- Dissent handling: When models disagree, you gain visibility into uncertainty rather than false confidence from a single answer.
- Hallucination detection: Contradictions across models flag potential fabrications for manual review.
Where Parallel AI Falls Short
- Data errors: If your input documents contain mistakes, all models will propagate the error. Parallelization doesn’t validate source data.
- Lack of grounding: Models without retrieval augmentation can hallucinate in parallel. You need vector databases or knowledge graphs to anchor outputs.
- Consensus collapse: If all models converge on the same wrong answer, you lose the benefit of diversity. Red-team prompts mitigate this.
- Expertise gaps: Models trained on general corpora may lack domain-specific knowledge. Parallelization won’t substitute for subject-matter expertise.
Effective parallel AI pairs orchestration with vector-grounded prompts and explicit dissent tracking. Governance basics like evidence linking and rationale capture turn raw outputs into trustworthy decisions.
Orchestration Modes: Patterns for Different Tasks
Different orchestration modes fit distinct analytical needs. Each mode has inputs, steps, expected outputs, and failure modes to watch.
Fusion Mode for Consensus Summaries
Fusion mode runs models in parallel, collects their rationales, and synthesizes a unified summary. It’s ideal for creating executive briefs or consolidated recommendations.
- Inputs: Research question, source documents, constraints (length, tone, focus)
- Steps: Run models in parallel → collect per-model rationales → synthesize fusion output → validate against sources
- Expected output: Consensus summary with minority positions noted
- Failure modes: Consensus collapse (all models agree on weak answer), lost minority signal (dissent gets buried)
- Mitigations: Use dissent matrix to track minority positions, enforce evidence-linked citations
When parallelizing across 5 models, an AI Boardroom interface can surface per-model rationales and a consolidated synthesis. This visibility prevents premature consensus and preserves valuable dissent.
Debate Mode for Risk-Sensitive Decisions
Debate mode assigns pro and con roles to different models. Each argues a position, forcing adversarial scrutiny of assumptions and evidence.
- Define thesis and counter-thesis prompts
- Assign pro/con roles to specific models
- Time-box debate rounds (e.g., 3 rounds of claim-counterclaim)
- Force evidence citations in each round
- Synthesize final recommendation with risk register
Failure modes: Performative debate where models echo each other, shallow adversarial attempts that miss real risks.
Mitigations: Use role specialization to enforce distinct perspectives. Inject red-team prompts to stress-test weak points. Fine-tune response depth with Conversation Control to prevent verbose but shallow exchanges.
Red Team Mode for Stress Testing
Red team mode generates attacks, edge cases, and failure scenarios against a draft output. It’s critical for validating investment theses, legal arguments, or product positioning.
- Inputs: Draft output, risk register, adversarial prompts
- Steps: Generate attacks and edge cases → score risks by likelihood and impact → propose fixes or mitigations
- Expected output: Annotated draft with risk flags and remediation options
- Failure modes: Shallow adversarial attempts that miss sophisticated attacks
- Mitigations: Use risk taxonomy prompts, @Mention model specialization for domain-specific attacks
Context Fabric maintains risk registers across sessions, so you can track how vulnerabilities evolve as you refine your analysis.
Sequential Orchestration for Complex Research
Sequential orchestration chains model outputs for multi-step research. Each model’s analysis informs the next prompt, building depth over rounds.
- Retrieve relevant documents from vector database
- Run per-model analysis on document set
- Synthesize findings in fusion round
- Identify gaps or contradictions
- Generate follow-up questions and iterate
Failure modes: Drift (later rounds lose focus), missing citations (models fabricate sources).
Mitigations: Use Knowledge Graph linking to anchor each claim, enforce vector-grounded prompts to prevent hallucination. Ground analyses in a Vector File Database and persist insights in a Living Document for auditability.
Targeted Specialist Teams
Targeted mode maps sub-tasks to models based on their strengths. You assign specific models to specific roles and arbitrate conflicts.
- Inputs: Task taxonomy, model strength profiles (e.g., Model A for code, Model B for legal reasoning)
- Steps: Map sub-tasks to models → enforce scope boundaries → collect outputs → arbitrate conflicts
- Expected output: Role-specific deliverables with clear ownership
- Failure modes: Overlapping scopes, unclear arbitration rules
- Mitigations: Define clear @Mention rules, establish arbitration rubric before starting
You can build a specialized model team by assigning models to roles like analyst, critic, synthesizer, and fact-checker. This pattern works well for investment memos, legal briefs, and market research reports.
Watch this video about parallel ai:
Implementation Quick-Start: Standing Up a Parallel AI Workflow
Moving from concept to operational workflow requires clear objectives, prompt templates, and governance guardrails. This checklist accelerates setup.
Pre-Flight Checklist
- Define objectives: What decision are you validating? What constitutes success?
- Identify sources: Which documents, datasets, or knowledge bases will ground your analysis?
- Set risk thresholds: What level of dissent triggers manual review? What confidence score is acceptable?
- Establish success criteria: How will you measure output quality? Speed? Auditability?
- Choose orchestration mode: Fusion, Debate, Red Team, Sequential, or Targeted based on task type
Prompt Templates for Each Mode
Standardized prompts reduce setup friction and improve consistency across runs.
Fusion Mode Template:
- “Analyze [document set] and synthesize a [length] summary focused on [topic]. Cite evidence for each claim. Flag any contradictions across sources.”
Debate Mode Template:
- “Pro: Argue that [thesis]. Cite evidence. Con: Argue that [counter-thesis]. Cite evidence. Synthesize: Evaluate both positions and recommend a decision with risk register.”
Red Team Template:
- “Review [draft output]. Generate 5 adversarial scenarios that could invalidate the conclusion. Score each by likelihood and impact. Propose mitigations.”
Sequential Template:
- “Round 1: Extract key findings from [documents]. Round 2: Critique findings for gaps and contradictions. Round 3: Synthesize validated insights and generate follow-up questions.”
Targeted Template:
- “Model A: Perform quantitative analysis. Model B: Assess qualitative risks. Model C: Synthesize both into executive summary. Arbitrate conflicts using [rubric].”
Dissent and Consensus Matrix
Track minority positions with evidence to prevent consensus collapse. Use this table structure:
- Model: Which model produced the claim?
- Claim: What is the assertion?
- Evidence: Which sources support it?
- Confidence: Model’s self-reported confidence (if available)
- Impact: How much does this claim affect the final decision?
- Resolution: Accept, reject, or flag for manual review
This matrix makes dissent visible and auditable. It prevents valuable minority perspectives from disappearing into a blended consensus.
Auditability: Logging Rationales, Citations, and Decisions
High-stakes decisions require audit trails. Capture these elements for every run:
- Inputs: Prompt, documents, model versions, timestamp
- Per-model outputs: Full text, citations, confidence scores
- Synthesis logic: How you combined outputs (voting, weighted average, manual arbitration)
- Dissent log: Minority positions and resolution notes
- Final decision: Conclusion, supporting evidence, risk register
Platforms with persistent context management maintain these logs across sessions. You can revisit past decisions, trace rationale evolution, and comply with regulatory or internal review requirements.
Security Considerations for Sensitive Documents
Parallel AI often processes confidential data. Apply these safeguards:
- Data residency: Ensure models run in compliant regions (e.g., EU data stays in EU)
- Access controls: Restrict who can view prompts, outputs, and audit logs
- Encryption: Encrypt data at rest and in transit
- Anonymization: Redact personally identifiable information before sending to models
- Model selection: Use models with acceptable data retention policies (some providers offer zero-retention options)
For legal or financial workflows, verify that your orchestration platform supports compliance with GDPR, HIPAA, or other relevant frameworks.
Role-Specific Playbooks: Parallel AI in Action
Different professionals face different analytical challenges. These playbooks show how to apply parallel AI to real workflows.
Investment Analyst: Multi-Model Due Diligence
Investment decisions hinge on accurate valuation and risk assessment. A single model’s thesis can miss downside scenarios or overweight recent trends.
Workflow:
- Ingest 10-Ks, earnings calls, and analyst reports via vector database
- Run parallel valuation theses across 5 models (DCF, comps, precedent transactions)
- Debate assumptions (growth rates, discount rates, exit multiples) in adversarial rounds
- Red-team for downside scenarios (regulatory risk, competitive threats, macro shocks)
- Synthesize fusion memo with evidence links and dissent matrix
Outcome: Investment memo with multi-model consensus, flagged risks, and audit trail. Decision-makers see where models agree and where they diverge, enabling informed capital allocation.
For deeper guidance on investment workflows, explore how teams structure their analytical processes.
Legal Professional: Clause Risk Analysis and Remediation
Contract review demands precision. Missing a risky clause can trigger costly disputes. Parallel AI helps identify enforceability issues and propose remediation.
Workflow:
- Extract clauses from contract using structured prompts
- Run parallel risk scoring across models (enforceability, ambiguity, precedent alignment)
- Generate adversarial tests for edge cases (jurisdiction conflicts, force majeure triggers)
- Synthesize consensus on high-risk clauses
- Produce annotated contract notes with remediation options
Outcome: Risk-flagged contract with model-backed recommendations. Legal teams gain confidence that no single model’s blind spot compromised the review.
Professionals handling legal clause risk checks can adapt this playbook to their specific contract types and jurisdictions.
Research Lead: Literature Synthesis and Gap Analysis
Research projects require synthesizing large document sets and identifying knowledge gaps. Parallel AI accelerates extraction and validation.
Workflow:
- Retrieve literature from vector database (papers, reports, datasets)
- Run per-model finding extraction (methodologies, results, limitations)
- Link findings in knowledge graph to map relationships and contradictions
- Synthesize validated insights in fusion round
- Identify gaps and generate follow-up research questions
Outcome: Comprehensive literature review with evidence-linked claims, dissent tracking for conflicting studies, and a roadmap for next-stage research.
Research teams can ground their analyses in vector databases and persist insights across sessions for long-term projects.
Governance: Making Parallel AI Outputs Trustworthy
Orchestration without governance produces noise. Trustworthy parallel AI requires evidence linking, dissent tracking, and auditability.
Evidence Linking and Citation Hygiene
Every claim must trace back to a source. Enforce citation rules in prompts:
- “Cite the source document and page number for each assertion.”
- “If no source supports a claim, label it as inference and flag for review.”
- “Prefer direct quotes over paraphrases when accuracy is critical.”
Models that hallucinate citations fail audit. Validate links programmatically where possible (e.g., check that cited page numbers exist).
Dissent Tracking and Minority Position Preservation
Consensus can hide valuable warnings. Track dissent explicitly:
- Log which models disagreed and why
- Assign confidence scores to minority positions
- Escalate high-impact dissent for manual review
- Document resolution (accepted, rejected, or deferred pending more data)
This practice prevents groupthink and surfaces edge cases that deserve attention.
Rationale Capture and Decision Versioning
Decisions evolve. Capture rationale at each step so you can reconstruct how conclusions changed:
- Version 1: Initial parallel scan with raw outputs
- Version 2: Post-debate synthesis with updated risk scores
- Version 3: Final decision after red-team stress test
Versioning supports iterative refinement and regulatory compliance. Auditors can trace how new information shifted recommendations.
Access Controls and Audit Logs
Restrict who can view, edit, or approve parallel AI outputs. Maintain logs of:
- Who ran the analysis
- Which models were used
- What prompts were sent
- When the analysis occurred
- Who reviewed and approved the final output
These logs satisfy internal controls and external audits.
Watch this video about multi-LLM orchestration:
Performance Trade-Offs: Speed, Cost, and Quality
Parallel AI introduces trade-offs between turnaround time, compute cost, and output quality. Understanding these helps you calibrate workflows.
Speed
Simultaneous orchestration is fastest. Sequential orchestration takes longer but enables refinement. Hybrid approaches balance both.
- Simultaneous: 5 models in parallel complete in ~same time as 1 model
- Sequential: 5 rounds take 5x the time of a single run
- Hybrid: Initial parallel scan + targeted sequential deep-dive
For urgent decisions, prioritize simultaneous runs. For complex research, invest in sequential depth.
Cost
Running multiple models multiplies API costs. Optimize by:
- Using smaller models for initial scans, larger models for synthesis
- Caching common prompts to avoid redundant calls
- Batching requests where latency permits
- Setting budget caps per workflow to prevent runaway costs
Cost-per-decision varies by task complexity. A simple fusion run may cost a few dollars. A multi-round debate with large context windows can reach tens of dollars.
Quality
More models generally improve coverage and bias reduction. Diminishing returns set in after 5-7 models. Beyond that, you gain marginal insight at high cost.
- 2-3 models: Basic diversity, limited dissent visibility
- 5 models: Strong coverage, clear consensus/dissent patterns
- 7+ models: Marginal gains, higher cost and synthesis complexity
For most high-stakes workflows, 5 models hit the quality-cost sweet spot.
Common Failure Modes and How to Mitigate Them
Even well-designed parallel AI workflows can fail. Recognizing failure modes early prevents wasted effort.
Consensus Collapse
All models converge on the same weak answer. This happens when prompts are too leading or when models share similar training biases.
Mitigation: Inject red-team prompts that force adversarial perspectives. Use debate mode to surface dissent. Rotate model selection to avoid clustering around similar architectures.
Lost Minority Signal
Valuable dissent gets buried in fusion synthesis. A single model flags a critical risk, but the majority vote drowns it out.
Mitigation: Use dissent matrix to preserve minority positions. Escalate high-impact dissent for manual review regardless of vote count.
Hallucinated Citations
Models fabricate sources to support claims. This undermines trust and creates audit risk.
Mitigation: Enforce vector-grounded prompts. Validate citations programmatically. Flag unsupported claims for human verification.
Drift in Sequential Rounds
Later rounds lose focus as models chase tangents. The final output no longer addresses the original question.
Mitigation: Anchor each round with a summary of the original objective. Use knowledge graph linking to maintain thematic coherence. Set round limits to prevent unbounded exploration.
Overlapping Model Scopes
In targeted orchestration, models duplicate work or contradict each other due to unclear role boundaries.
Mitigation: Define explicit @Mention rules. Assign non-overlapping sub-tasks. Establish arbitration rubric before starting.
Frequently Asked Questions
How many models should I run in parallel?
Five models provide strong coverage and clear consensus/dissent patterns without excessive cost. Two to three models offer basic diversity. Seven or more models deliver marginal gains at higher complexity and expense.
Can I use the same model multiple times with different prompts?
Yes, but this is ensemble prompting rather than true parallel AI. Running one model with varied prompts reduces diversity compared to running distinct models. For bias reduction, use different model architectures.
How do I handle contradictory outputs?
Log contradictions in a dissent matrix. Assign confidence scores. Escalate high-impact conflicts for manual review. Use debate or red-team modes to probe the disagreement and identify which position has stronger evidence.
What if all models agree on a wrong answer?
Consensus collapse is a known failure mode. Mitigate by injecting red-team prompts, using adversarial debate, and grounding outputs in verified source documents. No orchestration method eliminates the need for human oversight on critical decisions.
How do I maintain audit trails across sessions?
Use platforms with persistent context management. Log inputs, per-model outputs, synthesis logic, dissent records, and final decisions. Version each iteration so you can reconstruct how conclusions evolved.
Is parallel AI suitable for real-time decisions?
Simultaneous orchestration can approach real-time if models run in parallel and synthesis is automated. Sequential or hybrid modes take longer. For time-critical decisions, pre-configure prompts and use cached results where possible.
Key Takeaways: Operationalizing Parallel AI for Decision Validation
Parallel AI transforms high-stakes analysis from isolated chat sessions into structured, auditable workflows. You now have the patterns, prompts, and safeguards to implement it.
- Parallel AI reduces single-model bias by orchestrating multiple models to analyze the same problem and surfacing consensus or dissent with evidence.
- Different orchestration modes fit distinct tasks: Fusion for summaries, Debate for risk-sensitive decisions, Red Team for stress testing, Sequential for complex research, and Targeted for specialist teams.
- Governance makes outputs trustworthy: Evidence linking, dissent tracking, rationale capture, and audit logs turn raw model outputs into defensible decisions.
- Role-specific playbooks accelerate adoption: Investment analysts, legal professionals, and research leads can adapt proven workflows to their contexts without starting from scratch.
- Performance trade-offs matter: Balance speed, cost, and quality by choosing the right orchestration pattern and model count for each task.
Start with a single high-stakes decision. Choose the orchestration mode that fits your risk profile. Run the workflow. Review the dissent matrix. Refine your prompts based on what you learn.
Explore how simultaneous multi-LLM analysis is implemented to compare rationales and synthesize decisions with auditability and precision.





