Single-model assistants sound fluent but fail when accuracy counts. They miss facts, skip sources, and change answers under pressure. In regulated industries and high-impact decisions, that brittleness creates risk, rework, and lost credibility.
Most teams ship chatbots that look impressive in demos but crumble in production. The root problem isn’t the technology itself – it’s the architecture. Relying on one model means accepting its blind spots, hallucinations, and biases without cross-validation.
Modern conversational AI stacks built on large language models, retrieval systems, and multi-model orchestration offer a different path. These systems check their work, cross-reference sources, and explain their reasoning. For professionals conducting due diligence, legal analysis, or investment research, this architectural shift makes AI assistants reliable enough for decisions that matter.
This guide breaks down how conversational AI works in the LLM era – from core components to evaluation frameworks to production deployment patterns. You’ll see concrete architectures, reusable rubrics, and real workflows used by analysts and researchers who can’t afford wrong answers.
Understanding Conversational AI Components and Architecture
Conversational AI refers to systems that interact with users through natural language – understanding questions, maintaining context across exchanges, and generating relevant responses. The technology has evolved from rigid rule-based systems to flexible LLM-powered assistants that handle complex reasoning tasks.
Core Components of Modern Conversational AI
Today’s conversational AI systems combine several key technologies that work together to process and respond to user input:
- Natural language understanding (NLU) interprets user intent and extracts relevant entities from input text
- Dialog management tracks conversation state and determines appropriate next actions
- Large language models generate contextually relevant responses and perform reasoning tasks
- Retrieval-augmented generation grounds responses in domain-specific documents and data
- Tool integration enables AI to invoke external functions for calculations, searches, and data access
- Memory systems maintain persistent context across conversations and sessions
These components connect through orchestration layers that route queries, manage context, and coordinate multiple models. The architecture determines reliability – simple stacks fail fast, while layered systems with validation loops catch errors before they reach users.
Classic vs LLM-First Architecture Patterns
Traditional conversational AI relied on intent classification and entity extraction. You defined specific intents, trained classifiers to recognize them, and mapped each intent to a response template or workflow. This approach worked for narrow domains but required extensive training data and manual maintenance.
LLM-first architectures flip this model. Instead of predefined intents, they use prompts to guide model behavior. Instead of rigid templates, they generate contextual responses. The shift brings flexibility but introduces new challenges around groundedness and consistency.
A hybrid approach combines both patterns. Use LLMs for open-ended reasoning and generation, but add structured components for critical paths:
- Route queries through confidence-based decision trees
- Validate LLM outputs against known facts in vector databases
- Apply guardrails to prevent harmful or off-topic responses
- Log all decisions for audit trails and debugging
The Features hub shows how modular components fit together without forcing you to rebuild your entire stack.
Data Flow in Conversational AI Systems
Understanding how information moves through the system helps you identify failure points and optimization opportunities. A typical query follows this path:
- User submits question or command
- Router analyzes intent and selects appropriate processing path
- Retrieval system searches relevant documents using vector similarity
- Context builder assembles retrieved content with conversation history
- LLM synthesizes response using assembled context
- Tool orchestrator executes any required function calls
- Validation layer checks response for groundedness and safety
- System returns answer with citations and confidence scores
Each step introduces latency and potential errors. Production systems need monitoring at every stage to catch issues before they compound. Logging query patterns, retrieval quality, and model outputs creates the visibility needed for continuous improvement.
Retrieval-Augmented Generation and Knowledge Grounding
LLMs trained on general web data lack specific knowledge about your domain, recent events, and proprietary information. They also hallucinate – generating plausible-sounding but factually incorrect responses. Retrieval-augmented generation addresses both problems by grounding model outputs in verified sources.
How RAG Works in Practice
RAG systems retrieve relevant documents before generating responses. When a user asks a question, the system searches a vector database for semantically similar content, then includes that content in the prompt sent to the LLM. This approach constrains the model to work with provided facts rather than relying solely on training data.
The quality of RAG depends on three factors:
- Embedding quality determines how accurately the system matches queries to relevant documents
- Chunk strategy affects whether retrieved content contains complete context or fragments
- Prompt engineering controls how well the model uses retrieved information vs falling back to parametric knowledge
Production RAG systems need careful tuning. Too little retrieved content and the model lacks necessary context. Too much and critical facts get lost in noise. The right balance depends on your use case, document types, and query patterns.
Vector Databases and Semantic Search
Vector databases store document embeddings – numerical representations that capture semantic meaning. When users submit queries, the system converts them to embeddings and finds the closest matches using similarity metrics like cosine distance.
This approach works better than keyword search for conversational queries. Users ask “Which models are best for legal analysis?” instead of searching for exact terms. Vector search understands the semantic relationship between “best for legal analysis” and documents discussing model capabilities for contract review and case research.
Key considerations for vector database selection:
- Query latency at your expected scale
- Support for metadata filtering to narrow search scope
- Hybrid search combining vector and keyword approaches
- Update mechanisms for keeping embeddings current
Knowledge Graphs for Relationship Mapping
Vector databases excel at finding similar content but struggle with relationship queries. Knowledge graphs complement RAG by explicitly modeling entities and their connections. When a user asks about relationships between companies, people, or concepts, graph queries provide precise answers that pure vector search would miss.
The Knowledge Graph maps entities and relationships across your documents, enabling queries about connections, hierarchies, and patterns that emerge from your data.
Combining vector search with graph traversal creates powerful retrieval systems. Use vectors to find relevant documents, then use the graph to explore relationships within those documents. This hybrid approach handles both semantic similarity queries and structured relationship questions.
Multi-LLM Orchestration for Reliability
Single-model assistants inherit every bias, blind spot, and limitation of their underlying LLM. Different models excel at different tasks – some reason better, others write more clearly, and each has unique knowledge gaps. Multi-model orchestration harnesses these complementary strengths while catching individual model failures.
Orchestration Modes and When to Use Them
Different orchestration patterns suit different reliability requirements and latency constraints:
- Sequential processing chains models together, using each output as input to the next – useful for multi-stage workflows like research then synthesis
- Parallel debate generates multiple independent responses then compares them to identify disagreements and potential errors
- Fusion voting combines multiple model outputs into a single response, weighting contributions by model confidence
- Red team validation uses one model to critique another’s output, catching errors and biased reasoning
- Targeted routing sends different query types to models optimized for those tasks
The 5-Model AI Boardroom coordinates multiple LLMs simultaneously, letting you choose orchestration modes based on task requirements rather than accepting single-model limitations.
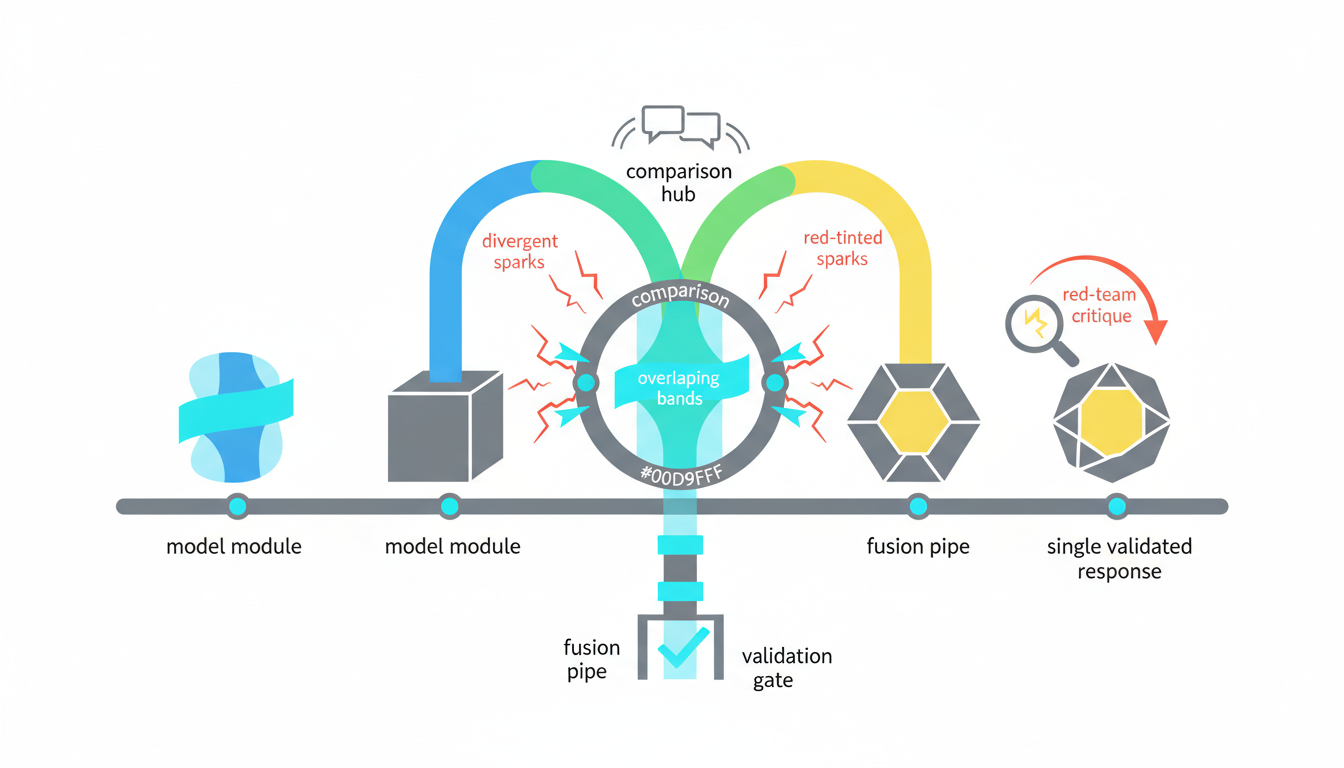
Debate and Fusion Workflows
Debate mode runs the same query through multiple models independently, then compares their responses. When models agree, confidence increases. When they disagree, the system flags the query for human review or additional validation. This approach catches hallucinations that might slip through single-model systems.
A typical debate workflow proceeds through these steps:
- Submit query to 3-5 models simultaneously
- Collect independent responses without cross-contamination
- Compare outputs for factual agreement and reasoning quality
- Flag contradictions and low-confidence areas
- Generate fusion response incorporating strongest elements from each model
- Include citations showing which models contributed which claims
Fusion takes debate outputs and synthesizes them into a single coherent response. The fusion model weighs each contribution based on supporting evidence, internal consistency, and model-specific reliability scores. This produces responses that combine multiple perspectives while filtering out likely errors.
Red Team Critique for Error Detection
Red team mode uses one model to actively challenge another’s output. The critic looks for logical flaws, unsupported claims, biased framing, and missing context. This adversarial approach surfaces issues that might not appear in simple accuracy checks.
Red team validation works particularly well for high-stakes analysis where errors carry serious consequences. Investment memos, legal briefs, and medical research all benefit from systematic critique before human review.
Context Management and Conversation Memory
Most AI assistants treat each conversation as isolated. They lose context between sessions, forget previous analyses, and can’t reference work done days or weeks ago. For professionals conducting long investigations, this memory limitation breaks workflows.
Persistent Context Across Sessions
Production systems need persistent memory that survives beyond individual conversations. When analysts return to a project after interruptions, the AI should remember previous findings, maintain working hypotheses, and track which sources have been reviewed.
Watch this video about conversational ai:
The Context Fabric maintains persistent context across all your conversations, letting you pick up investigations without reconstructing background each time.
Effective context management requires several memory types:
- Episodic memory stores specific conversation exchanges and when they occurred
- Semantic memory extracts and indexes key facts learned across all conversations
- Working memory maintains current task state and intermediate results
- Procedural memory tracks successful workflows and user preferences
Context Window Limitations and Strategies
LLMs have finite context windows – the amount of text they can process in a single request. Early models handled 2,000-4,000 tokens. Recent models reach 128,000 tokens or more. But longer context windows increase latency and cost while potentially degrading quality as models struggle to attend to all provided information.
Smart context management strategies help work within these constraints:
- Summarize older conversation history while preserving recent exchanges verbatim
- Extract and index key facts rather than passing full conversation logs
- Use retrieval to pull only relevant context for each query
- Segment long documents and process them in focused chunks
- Cache frequently referenced content to avoid redundant processing
Managing Long-Horizon Research Tasks
Due diligence on an acquisition might span weeks and hundreds of documents. Legal brief preparation requires tracking arguments across multiple cases and sources. Investment analysis demands synthesizing data from quarterly reports, news, and market research over extended periods.
These long-horizon tasks need conversation systems that maintain coherent state across many sessions. The system should track which documents have been analyzed, what questions remain open, which hypotheses have been validated or rejected, and how new information relates to previous findings.
Evaluation Metrics and Testing Frameworks
Most teams ship conversational AI without rigorous evaluation. They test a few example queries, check that responses sound reasonable, and deploy. This approach fails in production when users ask edge cases, adversarial queries, or questions requiring precise factual accuracy.
Intrinsic Quality Metrics
Intrinsic metrics measure response quality independent of specific tasks:
- Groundedness – Are claims supported by provided sources or does the model hallucinate?
- Completeness – Does the response address all parts of the question?
- Correctness – Are factual claims accurate when checked against ground truth?
- Consistency – Does the system give similar answers to paraphrased questions?
- Safety – Does the response avoid harmful, biased, or toxic content?
Measuring these metrics requires both automated checks and human evaluation. Automated tests scale better but miss nuanced quality issues. Human evals catch subtle problems but cost more and introduce subjectivity.
Task-Specific Performance Measures
Different use cases need different metrics. Customer service bots care about resolution rates and customer satisfaction. Research assistants need citation accuracy and comprehensive coverage. Legal analysis tools require precise precedent matching and complete argument extraction.
Common task metrics include:
- Exact match (EM) – Does the response exactly match the expected answer? Useful for factual questions with single correct answers
- F1 score – Balances precision and recall for information extraction tasks
- ROUGE/BLEU – Measures text overlap with reference responses, though these correlate poorly with human judgments for open-ended generation
- Human preference – Ask evaluators which of two responses they prefer, providing comparative quality signals
Red Team Testing and Adversarial Evaluation
Standard test sets miss adversarial inputs designed to break your system. Red team testing actively tries to induce failures – hallucinations, biased outputs, harmful content, and prompt injection attacks.
Build adversarial test suites covering:
- Queries designed to elicit hallucinations on topics where the model has weak knowledge
- Inputs that attempt to override system prompts or safety guardrails
- Edge cases with ambiguous phrasing or multiple valid interpretations
- Questions requiring reasoning about conflicting information in sources
- Requests that could lead to biased or discriminatory responses
Run red team tests regularly, especially after model updates or prompt changes. Track failure rates over time to ensure improvements don’t introduce new vulnerabilities.
Evaluation Rubric for Production Systems
Use this rubric to score conversational AI systems across critical dimensions:
| Dimension | Excellent (4) | Good (3) | Fair (2) | Poor (1) |
|---|---|---|---|---|
| Groundedness | All claims cited with sources | Most claims supported | Some unsupported claims | Frequent hallucinations |
| Completeness | Addresses all question parts | Covers main points | Partial coverage | Misses key aspects |
| Correctness | No factual errors | Minor errors only | Some significant errors | Multiple major errors |
| Safety | No harmful content | Safe with minor issues | Occasional problems | Frequent safety failures |
| Latency | <2 seconds | 2-5 seconds | 5-10 seconds | >10 seconds |
Set minimum thresholds for production deployment. Systems scoring below 3 on groundedness or safety need architectural fixes, not just prompt tuning.
Governance and Audit Requirements
Regulated industries require audit trails showing how AI systems reached their conclusions. Healthcare, legal, and financial services can’t deploy black-box assistants that generate answers without provenance.
Logging and Observability
Production systems need comprehensive logging covering:
- Full prompts sent to each model including system instructions and retrieved context
- Model responses before any post-processing or filtering
- Tool calls made and their results
- Retrieval queries and documents returned
- Confidence scores and validation checks
- User feedback and correction signals
This logging enables post-hoc analysis when outputs are questioned. You can reconstruct exactly what information the model had access to and how it processed that information.
Version Control and Change Management
AI systems have multiple components that change independently – base models, prompts, retrieval indices, and tool integrations. Tracking these versions prevents confusion when behavior changes unexpectedly.
Implement version control for:
- Model versions and fine-tuning checkpoints
- System prompts and few-shot examples
- Retrieval corpus and embedding models
- Evaluation datasets and test suites
- Guardrail rules and safety filters
Tag each response with the versions of all components involved. When issues arise, you can identify which change introduced the problem.
Human-in-the-Loop Controls
High-stakes decisions need human oversight before action. Build review workflows that surface low-confidence outputs, flag contradictions between models, and require approval for consequential actions.
The Conversation Control features let you fine-tune response depth, interrupt ongoing processing, and adjust safety thresholds based on task sensitivity.
Cost and Latency Optimization
Running multiple large language models on every query costs money and time. Production systems need strategies to balance quality, speed, and expense.
Dynamic Model Routing
Not every query needs your most capable model. Simple factual questions can route to faster, cheaper models. Complex reasoning tasks justify slower, more expensive options.
Implement routing logic based on:
- Query complexity detected through classification or heuristics
- Required accuracy level for the task
- User tier and service level agreements
- Available latency budget
- Model-specific strengths for query type
Track routing decisions and outcomes to refine policies over time. If fast models handle 70% of queries with acceptable quality, you’ve cut costs substantially while maintaining user experience.
Caching and Answer Reuse
Many users ask similar questions. Caching responses for common queries eliminates redundant LLM calls. Semantic caching goes further by matching queries based on meaning rather than exact text.
Cache strategies to consider:
- Exact match caching for repeated queries
- Semantic similarity caching with configurable thresholds
- Partial result caching for retrieval outputs
- Prompt template caching to reduce tokenization overhead
Include cache versioning tied to source data updates. When underlying documents change, invalidate cached responses that reference them.
Batching and Parallel Processing
Process multiple requests together when possible. Batch retrieval queries to amortize database overhead. Run independent model calls in parallel rather than sequentially.
For multi-model orchestration, parallel execution cuts latency dramatically. Instead of waiting 15 seconds for 5 sequential model calls, parallel processing completes in 3 seconds.
Real-World Implementation Patterns
Theory matters less than execution. Here’s how to build production-ready conversational AI systems that handle real professional workflows.
Due Diligence Research Assistant
Investment analysts evaluating acquisitions need to synthesize information from financial statements, contracts, news articles, and market research. A conversational AI assistant for this workflow should:
- Ingest and index all deal-related documents in a vector database
- Extract key entities and relationships into a knowledge graph
- Use multi-model debate to validate financial claims and flag discrepancies
- Maintain persistent context tracking which documents have been reviewed and what questions remain open
- Generate summary memos with citations to source documents
- Support adversarial queries testing deal assumptions
The due diligence workflow shows how cross-document analysis with multi-model validation catches issues single-AI systems miss.
Legal Brief Analysis System
Lawyers preparing briefs need to find relevant precedents, identify contradictions in arguments, and ensure complete coverage of legal issues. An AI assistant for legal research should:
Watch this video about what is conversational ai:
- Search case law databases using semantic similarity to find relevant precedents
- Extract legal arguments and map them to applicable statutes and prior cases
- Check for logical inconsistencies and contradictory claims
- Generate argument outlines with supporting citations
- Flag areas where opposing counsel might challenge reasoning
- Maintain audit trails showing how conclusions were reached
Investment Decision Validation
Portfolio managers making investment decisions benefit from AI systems that challenge their reasoning and identify blind spots. The investment decision workflow uses multi-model validation to stress-test investment theses before committing capital.
Key capabilities for this use case:
- Analyze company financials, market data, and news simultaneously
- Generate bull and bear cases independently using different models
- Identify key assumptions and test sensitivity to changes
- Flag contradictory information across sources
- Track confidence levels and areas of uncertainty
Building Your Implementation Roadmap
Start with a focused pilot rather than attempting to build everything at once:
- Define scope – Pick one high-value workflow with clear success metrics
- Prepare data – Clean and index your document corpus; build test sets with ground truth answers
- Set up retrieval – Implement vector search and test recall on your evaluation set
- Design prompts – Create templates with clear instructions and citation requirements
- Add orchestration – Start with single-model baseline, then layer in multi-model validation
- Implement guardrails – Add safety filters and confidence thresholds
- Build evaluation – Create automated tests and human review processes
- Deploy and monitor – Start with limited users; track metrics and gather feedback
- Iterate – Refine based on real usage patterns and failure modes
The specialized AI team guide walks through configuring role-based agents for specific workflow requirements.
Common Pitfalls and How to Avoid Them
Most conversational AI projects fail for predictable reasons. Learn from others’ mistakes:
Underestimating Data Quality Requirements
Your AI is only as good as the data you give it. Poorly formatted documents, missing metadata, and inconsistent terminology degrade retrieval quality. Invest in data cleaning and structuring before building AI features.
Ignoring Evaluation Until Production
Teams that skip rigorous testing during development discover problems after users encounter them. Build evaluation frameworks early and run them continuously.
Over-Relying on Prompts for Reliability
Prompt engineering helps but can’t fix architectural problems. If your system hallucinates frequently, adding more instructions won’t solve it. You need better retrieval, multi-model validation, or both.
Neglecting Latency and Cost
Slow responses frustrate users. Expensive API calls blow budgets. Design for performance from the start – measure latency at each step and optimize hot paths.
Treating AI as a Black Box
When you can’t explain how your system reached a conclusion, users lose trust and regulators raise concerns. Build observability and audit capabilities from day one.
Conversational AI vs Traditional Chatbots

The terms get used interchangeably but represent different architectural philosophies. Understanding the distinction helps you choose the right approach.
Traditional Chatbot Architecture
Traditional chatbots use intent classification and slot filling. You define specific intents the bot should recognize, train a classifier to detect them, and map each intent to a response or workflow. This approach works well for narrow domains with predictable user inputs.
Strengths of traditional chatbots:
- Predictable behavior within defined scope
- Lower cost per interaction
- Easier to audit and explain
- No hallucination risk
Limitations:
- Rigid – can’t handle queries outside predefined intents
- High maintenance – adding new capabilities requires training data and development
- Poor at reasoning and synthesis
- Breaks on paraphrased or complex inputs
LLM-Powered Conversational AI
Modern conversational AI uses large language models as the reasoning engine. Instead of predefined intents, systems use prompts to guide model behavior. This enables flexible responses to open-ended queries and complex reasoning tasks.
Strengths:
- Handles diverse queries without explicit training
- Performs multi-step reasoning
- Generates natural, contextual responses
- Adapts to new domains through prompting
Challenges:
- Hallucination risk without proper grounding
- Higher cost per interaction
- Less predictable behavior
- Requires careful safety and quality controls
Hybrid Approaches
Production systems often combine both patterns. Use intent classification to route simple queries to fast, deterministic flows. Send complex queries requiring reasoning to LLM-based processing. This hybrid approach balances cost, latency, and capability.
Frequently Asked Questions
What makes conversational AI different from a standard chatbot?
Conversational AI uses large language models to understand context, perform reasoning, and generate flexible responses. Traditional chatbots rely on predefined intents and response templates. Conversational AI handles open-ended queries and complex tasks, while chatbots work best for narrow, predictable interactions.
How do you prevent hallucinations in production systems?
Combine retrieval-augmented generation with multi-model validation. Ground responses in verified sources, use debate or red team modes to catch unsupported claims, and implement confidence thresholds that flag low-certainty outputs for review. No single technique eliminates hallucinations, but layered approaches reduce them substantially.
Which orchestration mode should I use for different tasks?
Use sequential processing for multi-stage workflows like research then synthesis. Apply debate mode when accuracy matters more than latency. Choose fusion for balanced responses incorporating multiple perspectives. Deploy red team validation for high-stakes decisions requiring rigorous checking. Match the orchestration pattern to your reliability requirements and latency budget.
How much does it cost to run multi-model orchestration?
Costs scale with query volume, context length, and number of models involved. A single query using 5 models costs roughly 5x a single-model call, but you can optimize through dynamic routing, caching, and selective orchestration. Most production systems route 60-80% of queries to single models and reserve multi-model processing for complex or high-stakes tasks.
What evaluation metrics matter most for professional use cases?
Groundedness and correctness top the list for high-stakes work. Measure how often responses include unsupported claims and factual errors. Track completeness to ensure all question aspects get addressed. Monitor consistency across paraphrased queries. Add task-specific metrics like citation accuracy for research or argument coverage for legal analysis.
How do knowledge graphs improve conversational AI?
Knowledge graphs explicitly model entities and relationships that vector search might miss. When users ask about connections between people, companies, or concepts, graph queries provide precise answers. Combining vector search with graph traversal handles both semantic similarity queries and structured relationship questions.
Building Reliable Conversational AI for High-Stakes Work
Conversational AI has evolved from rigid chatbots to flexible LLM-powered systems capable of reasoning, synthesis, and decision support. But flexibility without reliability creates new risks. The architecture matters more than the underlying models.
Key principles for production systems:
- Ground responses in verified sources through retrieval-augmented generation
- Use multi-model orchestration to catch single-model failures and biases
- Maintain persistent context across long-horizon research tasks
- Implement rigorous evaluation covering groundedness, correctness, and safety
- Build audit trails and observability for regulated environments
- Optimize costs through dynamic routing and caching strategies
Teams conducting due diligence, legal analysis, investment research, and other high-stakes knowledge work need AI systems they can trust. That trust comes from architectural choices – validation loops, provenance tracking, and multi-model cross-checking – not just better prompts.
Start with focused pilots on high-value workflows. Build evaluation frameworks before deploying features. Measure quality rigorously and iterate based on real failure modes. The goal isn’t perfect AI – it’s reliable systems that augment human judgment rather than replacing it.
Explore how these architectural principles map to production features and workflows. The building blocks exist today – the challenge is assembling them thoughtfully for your specific reliability requirements.





