
Single-model answers feel confident- until they miss the edge case that costs you. Agentic AI promises goal-directed automation, but without cross-verification and auditability, autonomous steps can amplify hallucinations and blind spots.
This guide defines agentic AI, lays out the architecture, shows real workflows, and provides a safe starter blueprint grounded in multi-LLM orchestration practices used for high-stakes knowledge work.
Agentic AI refers to systems that plan, act, and iterate autonomously to achieve defined goals. Unlike traditional chatbots that respond once and wait, agentic systems break tasks into steps, select tools, execute actions, and refine outputs through feedback loops.
- Plans multi-step workflows from high-level objectives
- Uses external tools like search engines, databases, and APIs
- Maintains memory across interactions to track progress
- Self-critiques outputs and retries when errors surface
- Operates with minimal human intervention once configured
Agentic AI excels at repetitive research, data synthesis, and workflow automation. It fails when tasks require nuanced judgment, ethical reasoning, or creative leaps that resist decomposition.
Core Architecture Components
Reliable agentic systems combine six layers: planner, executor, memory, reviewer, orchestration, and safety. Each plays a distinct role in turning goals into verifiable outcomes.
Planner
The planner decomposes high-level goals into discrete tasks. It routes subtasks to appropriate models or tools based on capability profiles. Weak planners generate brittle sequences that break when assumptions fail.
Executor
The executor carries out tool calls, API requests, and external actions. It translates planner instructions into concrete operations like querying databases, running calculations, or fetching documents.
Memory
Memory splits into short-term scratchpads for active tasks and long-term stores for context retrieval. Vector databases enable semantic search across past interactions, while structured logs track decision chains.
Reviewer
A reviewer agent self-critiques outputs before finalization. It checks for logical inconsistencies, missing citations, and constraint violations. Without review checkpoints, agents propagate errors downstream.
Orchestration Layer
The orchestrator sequences steps, manages dependencies, and coordinates multiple models. Multi-LLM orchestration platforms route tasks to specialized models and cross-verify outputs to reduce blind spots.
Safety and Observability
Guardrails constrain tool permissions, enforce budget limits, and block dangerous actions. Observability captures logs, traces, and artifacts at every step for auditability and debugging.
How Agentic AI Works Step-by-Step
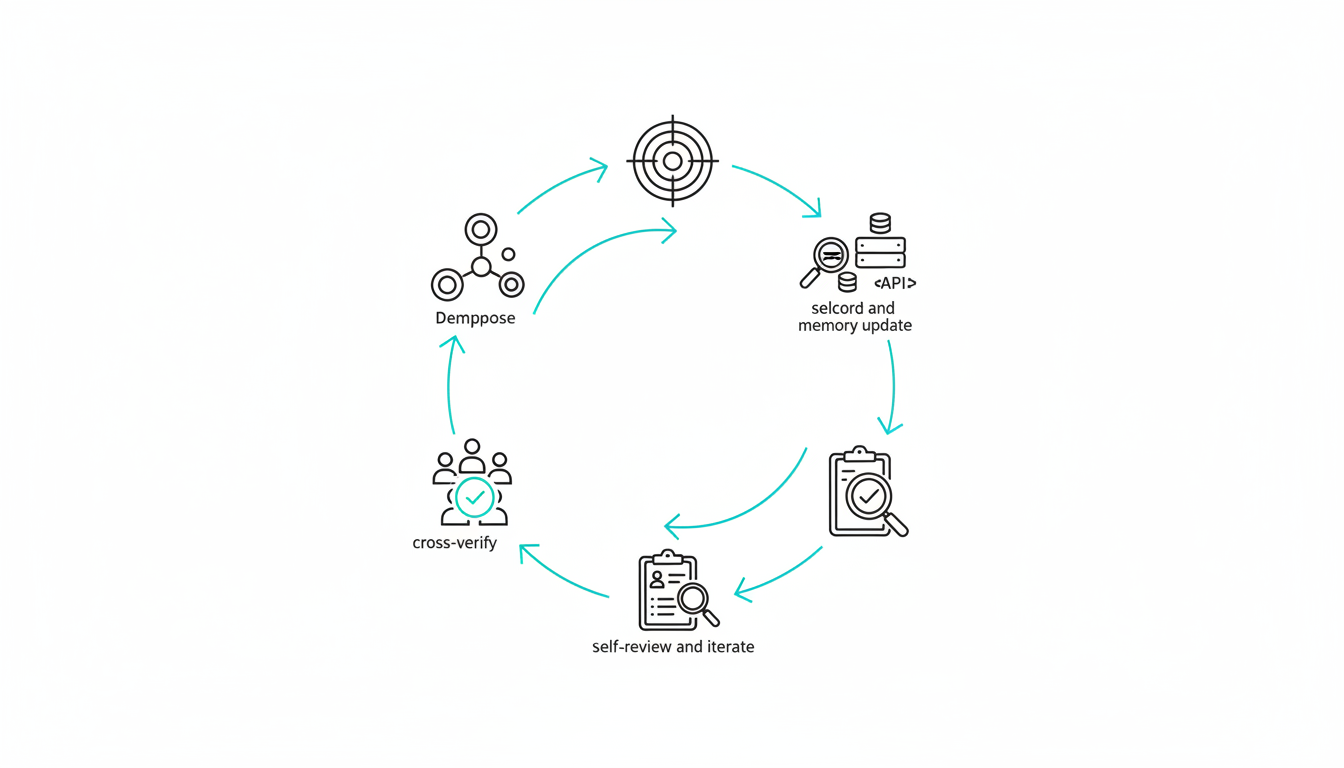
Agentic workflows follow a structured loop from goal definition through cross-verification. Each stage builds on prior outputs and exposes failure points for intervention.
- Define goal and constraints – specify objectives, success criteria, and boundaries
- Decompose into tasks and plan – break goal into executable subtasks with dependencies
- Select tools and execute – route tasks to appropriate models or APIs and run actions
- Record outcomes and update memory – log results, errors, and context for retrieval
- Self-review and iterate – critique output quality, retry failed steps, or escalate issues
- Cross-verify with multiple models – compare responses to surface disagreements and blind spots
- Finalize and log artifacts – package verified outputs with decision trails for audit
This loop repeats until success criteria are met or budget limits trigger termination. Human-in-the-loop thresholds pause execution when confidence drops below acceptable levels.
High-Stakes Workflows Where Agentic AI Adds Value
Agentic systems shine in knowledge work requiring multi-step research, source validation, and assumption testing. Four workflows illustrate practical applications.
Market and Strategy Research
Agents gather competitive intelligence, cross-check claims across sources, and flag contradictions. Source validation prevents hallucinated statistics from contaminating strategic memos.
Financial Analysis
Automated agents pull financial data, run scenario models, and challenge assumptions. Cross-verification with multiple reasoning models catches calculation errors and biased projections.
Legal Research Scoping
Agents map case law, extract relevant precedents, and verify citations. Audit logs document research paths for compliance and peer review.
R&D Literature Synthesis
Agents scan papers, extract findings, and synthesize insights across disciplines. Disagreement between models surfaces conflicting evidence and research gaps.
Risks and Failure Modes
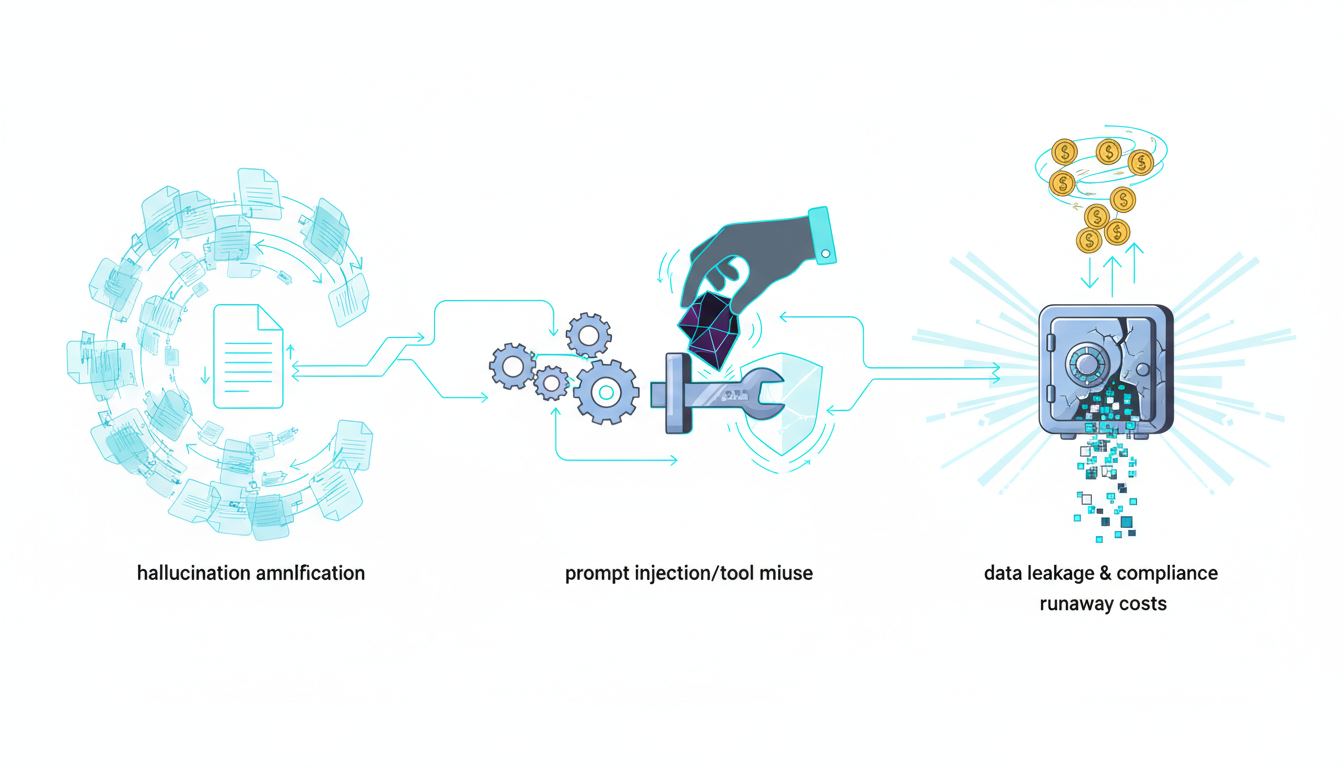
Autonomous loops amplify errors when safeguards fail. Five failure modes dominate production incidents.
- Hallucinations amplified by iteration – incorrect outputs feed into downstream tasks, compounding errors
- Tool misuse and prompt injection – agents execute unintended actions when inputs manipulate instructions
- Overconfidence without review – single-model agents miss blind spots and present flawed outputs as certain
- Data leakage and compliance violations – agents expose sensitive information through logs or external tool calls
- Runaway costs – unbounded loops consume API budgets without delivering value
Concrete Mitigations
Each risk maps to testable guardrails. Constrained tool permissions limit agent actions to approved operations. Mandatory review checkpoints pause execution for human validation.
Cross-model verification surfaces disagreements that signal uncertainty. Cost budgets and step limits prevent runaway loops. Audit logging and red-teaming expose vulnerabilities before production deployment.
Watch this video about agentic AI:
Evaluation and Reliability Standards
Agentic systems require continuous evaluation beyond traditional model benchmarks. Three practices establish reliability baselines.
Golden Task Suites
Regression tests with known correct outputs catch performance degradation. Tasks span common workflows and edge cases that previously triggered failures.
Offline vs. Online Evaluation
Offline testing validates changes in controlled environments. Online evaluation monitors live performance with real user tasks and escalation rates.
Human-in-the-Loop Thresholds
Confidence scores below defined thresholds trigger human review. Telemetry tracks success rates, error types, and divergence metrics across model combinations.
- Task completion rate and retry frequency
- Cross-verification disagreement patterns
- Tool call success and failure modes
- Cost per task and latency distributions
- Escalation triggers and resolution paths
Explore applied evaluation practices for orchestration in high-stakes contexts.
Implementation Blueprint for Safe Deployment
Start with narrow workflows and explicit guardrails. Five steps establish a foundation for iterative expansion.
- Choose orchestration pattern – single-LLM agents for simple tasks, multi-LLM sequential coordination for high-stakes work requiring cross-verification
- Define narrow workflow scope – pick one repeatable task with clear success criteria and known failure modes
- Instrument from day one – capture logs, traces, and artifacts at every step for debugging and compliance
- Design for disagreement – use multiple models to surface blind spots and validate reasoning chains
- Iterate with evaluation harness – run regression tests after each change and monitor live performance metrics
A starter configuration combines planner, executor, reviewer, memory, orchestration, and observability. Governance policies define tool permissions, budget limits, and escalation rules.
Tooling Landscape and Build vs. Buy
The agentic AI stack spans planning frameworks, tool-use libraries, vector stores, and observability platforms. Open-source options like LangChain and AutoGPT provide building blocks for custom agents.
Multi-LLM orchestration platforms coordinate specialized models and cross-verify outputs without custom integration. They suit high-stakes tasks where errors carry regulatory or financial consequences.
Build when workflows are unique and internal tooling exists. Buy when time-to-value, compliance requirements, or cross-verification needs outweigh development costs. Explore orchestration approaches that balance autonomy with auditability in the product overview and see pricing options.
Frequently Asked Questions
What distinguishes agentic AI from autonomous agents?
Agentic AI emphasizes goal-directed planning and tool use within defined constraints. Autonomous agents operate with broader decision-making authority and fewer human checkpoints. The terms overlap but agentic systems typically include stronger guardrails.
Can agentic systems operate safely in regulated contexts?
Yes, with proper guardrails. Audit logs document decision chains for compliance reviews. Constrained tool permissions prevent unauthorized actions. Human-in-the-loop thresholds pause execution when confidence drops. Cross-verification catches errors before finalization.
How do you control costs in agentic workflows?
Set budget limits per task and step counts per workflow. Monitor token usage and API call volumes in real time. Terminate loops that exceed thresholds. Use cheaper models for simple subtasks and reserve frontier models for complex reasoning.
How do you prevent hallucinated citations?
Cross-verify citations with multiple models. Use retrieval-augmented generation to ground outputs in source documents. Reviewer agents validate references against original texts. Audit logs trace claims back to source materials for manual spot-checks.
Key Takeaways for Implementing Agentic AI
Agentic AI delivers goal-directed automation through planning, tool use, memory, and self-critique. Reliability requires orchestration, guardrails, and observability at every step.
- Design for disagreement – cross-verification reduces risk by surfacing blind spots and conflicting evidence
- Start small with evaluation-first implementation – narrow workflows with regression tests establish reliability baselines
- Instrument logs and traces from day one – auditability and debugging depend on comprehensive observability
- Balance autonomy with human oversight – confidence thresholds and escalation rules prevent runaway errors
You now have a blueprint to implement agentic workflows without flying blind. Cross-verification, guardrails, and evaluation harnesses turn autonomous systems into reliable tools for high-stakes knowledge work.





