A multi-agent research tool orchestrates multiple AI models to work together on analysis tasks. Instead of relying on a single model that might hallucinate or miss critical counterarguments, these platforms coordinate several models to cross-check findings, surface contradictions, and converge on source-backed conclusions.
The core difference lies in ensemble architecture. Traditional AI chat interfaces route your query to one model. Multi-agent platforms split the work across specialized roles—one model might extract data, another challenges assumptions, a third synthesizes consensus. This division of labor mirrors how professional teams operate: different perspectives reduce blind spots.
Key components include:
- Agent roles – Each model receives specific instructions (analyst, skeptic, synthesizer)
- Coordination primitives – Rules governing how agents communicate and hand off tasks
- Context management – Shared memory so agents build on each other’s work
- Output synthesis – Mechanisms to merge or compare agent responses
Multi-agent systems shine when decision stakes are high and you need defensible audit trails. Investment analysts use them to stress-test theses before committing capital. Legal teams deploy them to cross-examine case precedents. Product strategists run them to validate market signals from scattered sources.
These tools are overkill for simple queries. If you need a quick fact or basic summarization, single-model chat suffices. Multi-agent orchestration makes sense when wrong answers carry consequences-when you need multiple viewpoints, reproducible reasoning, and citation integrity.
Core Orchestration Modes and When to Use Them
Orchestration modes define how agents collaborate. Each mode trades off speed, depth, and perspective diversity. Choosing the right mode depends on your research question and risk tolerance.
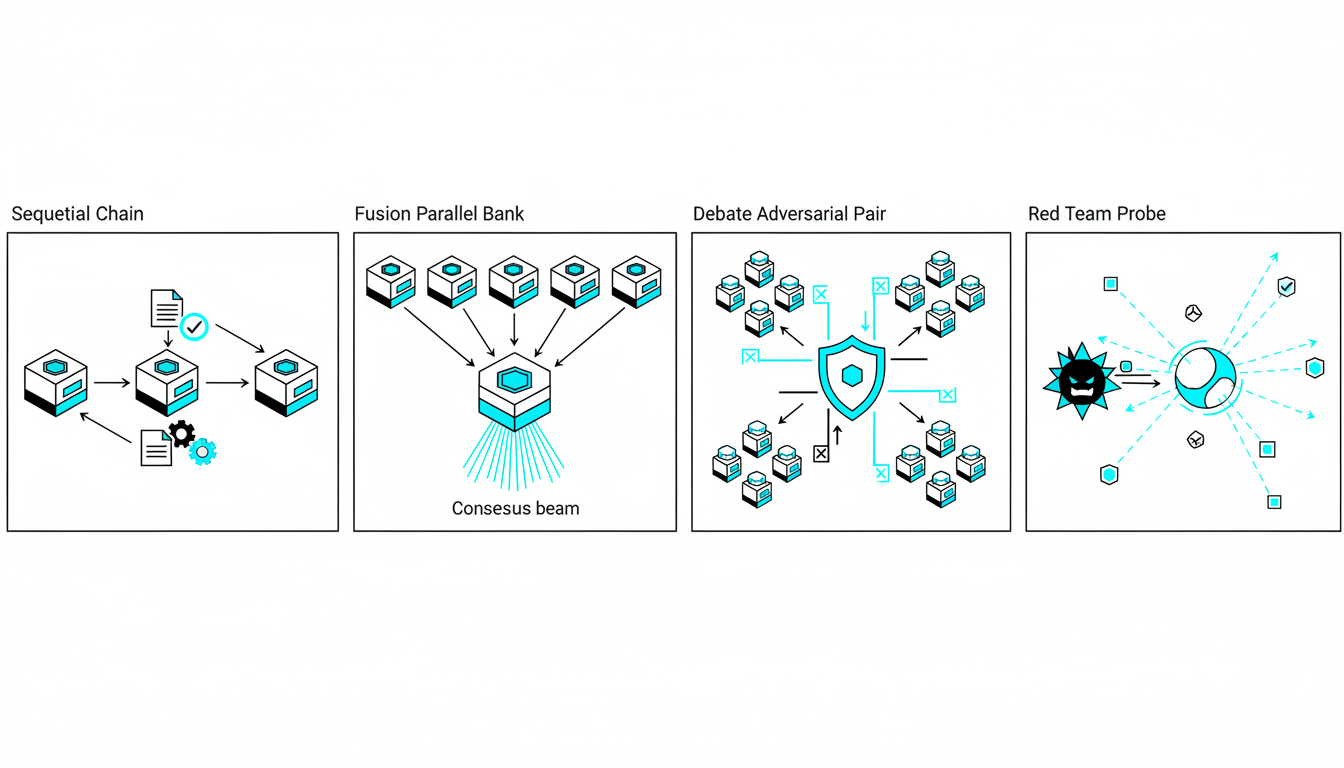
Sequential Mode: Stepwise Reasoning
Sequential orchestration chains agents in order. Agent A completes its task, passes results to Agent B, which feeds Agent C. This mimics assembly-line workflows where each step builds on the previous output.
Use sequential mode when:
- Tasks have clear dependencies (extract data → analyze trends → draft recommendations)
- You want tight control over the reasoning path
- Budget or latency constraints limit parallel processing
Failure mode: Errors compound downstream. If Agent A misinterprets a filing, every subsequent agent inherits that mistake. Mitigation requires validation checkpoints between handoffs.
Fusion Mode: Parallel Consensus
Fusion runs multiple models simultaneously on the same prompt, then synthesizes their outputs. A 5-model AI Boardroom might send your investment question to GPT-4, Claude, Gemini, Llama, and Mistral at once. The platform compares responses, flags disagreements, and produces a consensus summary.
Use fusion mode when:
- You need to reduce single-model bias
- The question has no objectively correct answer (strategic decisions, creative work)
- Speed matters less than comprehensive coverage
Fusion excels at ensemble agreement metrics. If four models concur on a conclusion but one dissents, you know where to dig deeper. This mode surfaces blind spots that single-model interfaces hide.
Failure mode: Consensus doesn’t guarantee correctness. Five models can agree on a plausible-sounding hallucination. Always require source citations and validate against primary documents.
Debate Mode: Structured Argumentation
Debate mode assigns opposing roles to different agents. One argues for a thesis, another attacks it, a third adjudicates. This adversarial setup exposes weak reasoning and untested assumptions.
Use debate mode when:
- Testing an investment thesis or strategic hypothesis
- You suspect confirmation bias in initial analysis
- Stakeholders demand you consider counterarguments
Debate forces agents to steel-man opposing views. The defending agent must address the strongest version of counterarguments, not straw men. This produces more robust conclusions than echo-chamber analysis.
Failure mode: Agents might argue past each other if prompts lack structure. Define clear debate rules: number of rounds, evidence requirements, and adjudication criteria.
Red Team Mode: Adversarial Probing
Red team mode deploys one or more agents to attack your conclusions. Unlike debate, which seeks balanced perspectives, red teaming assumes your thesis is wrong and hunts for proof.
Use red team mode when:
- Validating high-stakes decisions before execution
- Stress-testing compliance or risk assessments
- Preparing for hostile questioning (board meetings, litigation)
Red team agents probe for hidden assumptions, data gaps, and logical fallacies. They ask: “What if this source is outdated?” or “How would this thesis fail in a recession?” This mode builds resilience into your research.
Failure mode: Overly aggressive red teaming can paralyze decision-making. Set boundaries-define which assumptions are off-limits and when to stop probing.
Targeted and Research Symphony Modes
Targeted mode assigns specific subtasks to specialized agents. You might route financial modeling to one agent, regulatory research to another, and competitive analysis to a third. Research Symphony coordinates large-scale reviews where dozens of agents tackle different document sets in parallel.
Use these modes when:
- Projects span multiple domains (legal + financial + technical)
- Document volume exceeds what one agent can process efficiently
- You need role-specific expertise (tax law, patent analysis, clinical trials)
Failure mode: Coordination overhead grows with agent count. Without clear handoff protocols, agents duplicate work or miss dependencies. Maintain a central orchestration log to track progress.
From Documents to Decisions: The Research Data Flow
Multi-agent research tools transform raw documents into actionable insights through a structured pipeline. Understanding this data flow helps you audit outputs and troubleshoot failures.
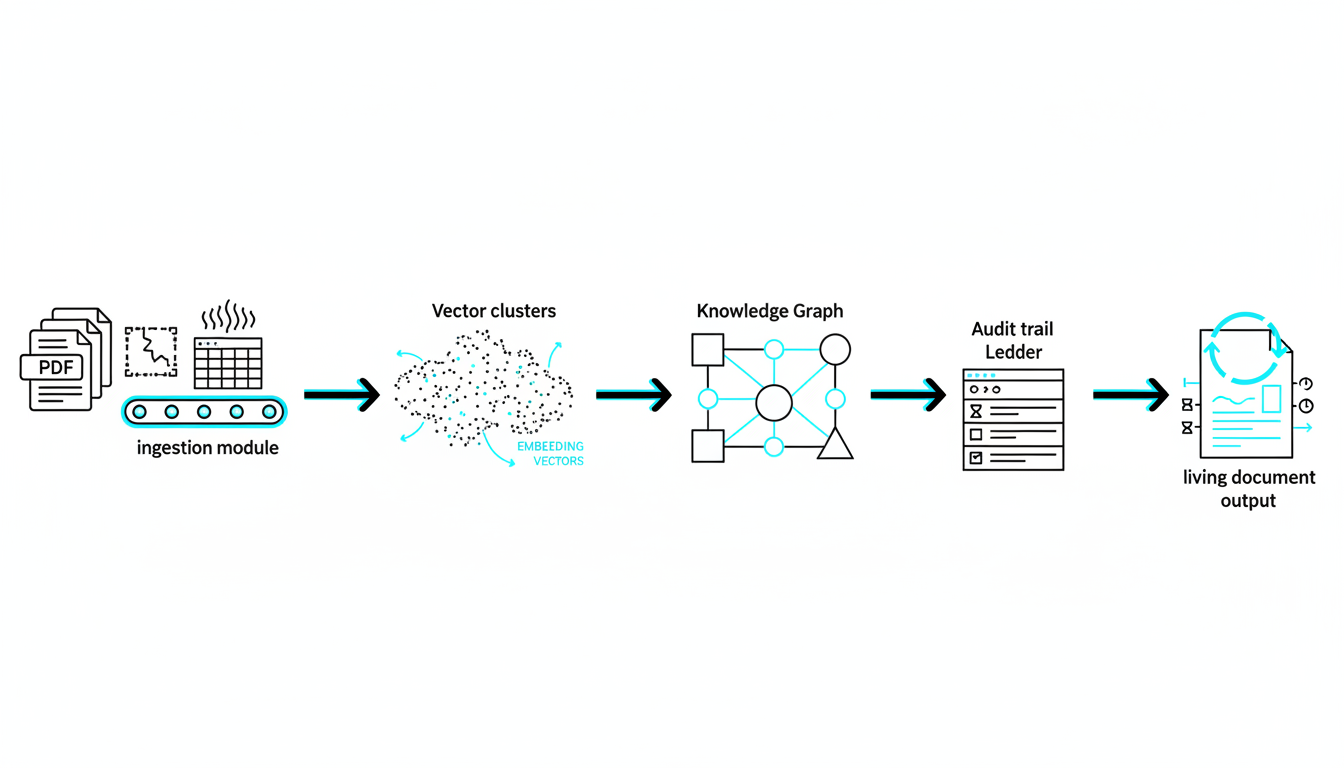
Ingestion: Loading Your Source Material
The process starts with document ingestion. You upload PDFs, earnings transcripts, legal briefs, or research notes. The platform parses text, extracts metadata (dates, authors, document type), and chunks content into semantic units.
Advanced platforms store chunks in a vector database. Each chunk gets converted to an embedding-a numerical representation capturing semantic meaning. This enables similarity search: when an agent needs information about “revenue growth,” the system retrieves relevant chunks even if they use synonyms like “sales expansion.”
Key ingestion capabilities:
- OCR for scanned documents
- Table extraction from financial statements
- Citation parsing from legal filings
- Metadata tagging for version control
Context Management and Memory
Single-chat AI tools forget previous conversations unless you manually reference them. Multi-agent platforms need persistent context because agents build on each other’s work across sessions.
Context Fabric architecture maintains shared memory. When Agent A extracts key metrics from a 10-K filing, those metrics remain available to Agent B during debate mode three days later. This prevents redundant analysis and ensures consistency.
Context management includes:
- Conversation threading – Group related queries and responses
- Entity tracking – Remember companies, people, dates mentioned across sessions
- Decision history – Log which conclusions came from which agent interactions
- Source attribution – Link every claim back to originating documents
Without robust context management, multi-agent systems devolve into disconnected single-agent calls. You lose the compounding benefits of ensemble reasoning.
Knowledge Graph for Relationship Mapping
A Knowledge Graph captures entities and relationships extracted during analysis. When agents process documents, they identify key entities (companies, products, regulations) and map connections (subsidiary relationships, supply chain links, competitive dynamics).
This graph enables cross-document reasoning. If you ask “How does the merger affect our supplier contracts?” the system queries the graph to find relevant entities, then retrieves supporting document chunks. This beats keyword search because it understands conceptual relationships.
Knowledge graphs support:
- Impact analysis – Trace how changes propagate through connected entities
- Gap detection – Identify missing information in your research
- Contradiction flagging – Surface conflicting claims about the same entity
Audit Trails and Reproducibility
Professional research requires audit trails. You need to justify conclusions to stakeholders, regulators, or opposing counsel. Multi-agent platforms log every prompt, model response, and synthesis decision.
A complete audit trail includes:
- Original query and orchestration mode selected
- Which agents ran and in what sequence
- Source documents each agent accessed
- Individual agent outputs before synthesis
- Consensus logic or debate adjudication
- Final output with citation links
This logging enables reproducibility. Another analyst can rerun your research with identical inputs and verify they get equivalent outputs. This matters for compliance, peer review, and iterative refinement.
Living Documents and Citation Integrity
The best platforms generate living documents-outputs that update when underlying sources change. If a company files an amended 10-K, citations automatically refresh. This prevents stale research from informing current decisions.
Citation integrity checks verify that:
- Every claim links to a specific source passage
- Sources remain accessible (no broken links)
- Quotes match original text without distortion
- Publication dates are current and clearly marked
Multi-agent systems that skip citation rigor produce persuasive-sounding nonsense. Always validate that consensus outputs trace back to verifiable sources.
Reliability and Validation Metrics That Matter
Evaluating multi-agent tools requires measurable criteria. Vague claims about “better research” don’t help you choose platforms or justify costs. Use these metrics to compare tools and track performance.
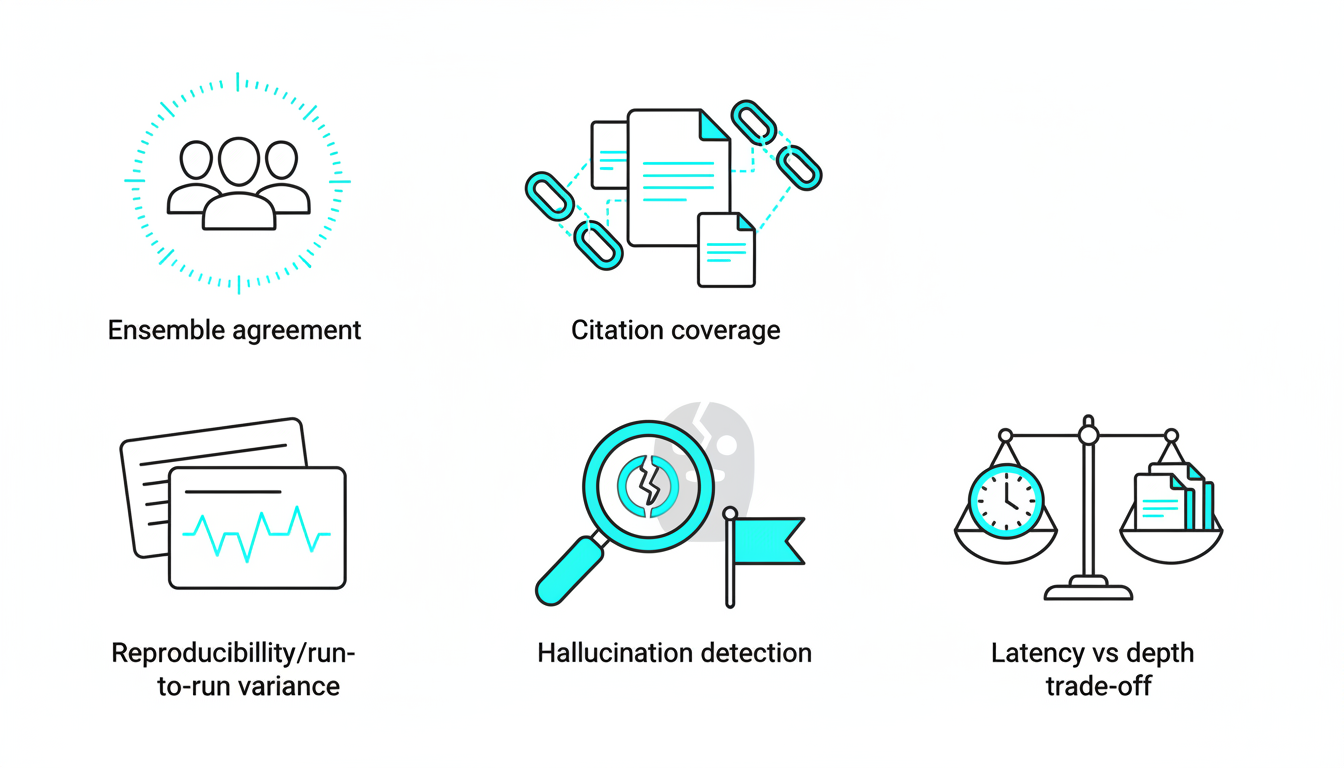
Ensemble Agreement Rate
Ensemble agreement measures how often models concur on answers. If five models run fusion mode and four give identical responses, your agreement rate is 80%. Higher rates suggest robust conclusions; lower rates flag areas needing human review.
Track agreement across question types:
- Factual extraction (dates, numbers) – Expect 90%+ agreement
- Interpretation (trend analysis, risk assessment) – 60-80% is typical
- Creative tasks (drafting, brainstorming) – Agreement below 50% is normal
Use disagreement as a research signal. When models split 3-2, investigate why. Often one model caught a nuance others missed, or vice versa.
Source-Backed Citation Coverage
Count what percentage of claims include citations to primary sources. Aim for 100% citation coverage on factual assertions. Opinions and recommendations can be uncited if clearly labeled as synthesis.
Evaluate citation quality:
- Specificity – Citations link to exact paragraphs, not entire documents
- Recency – Sources are dated and sorted by relevance
- Diversity – Multiple independent sources support key claims
- Accessibility – Links work and documents are retrievable
Platforms that generate citations after the fact (post-hoc attribution) produce weaker audit trails than systems that require citations during generation.
Watch this video about multi-agent research tool:
Hallucination Detection via Cross-Check
Multi-agent systems reduce but don’t eliminate hallucinations. Implement cross-check protocols:
- Red team mode challenges every major claim
- Source verification agents validate citations against original documents
- Contradiction flags highlight when agents give incompatible answers
Measure hallucination rate by sampling outputs and manually verifying claims. A good platform keeps hallucinations below 5% on factual queries. Track this metric monthly as models evolve.
Run-to-Run Variance and Reproducibility
Run the same query multiple times with identical settings. Low variance indicates stable, reproducible outputs. High variance suggests the platform relies too heavily on stochastic model behavior.
Acceptable variance thresholds:
- Factual queries – Near-zero variance (same answer every time)
- Analytical queries – 10-15% variance in phrasing, identical conclusions
- Creative queries – Higher variance expected, but core ideas should recur
Platforms with poor context management or weak orchestration logic produce erratic outputs. Reproducibility builds trust with stakeholders.
Latency vs. Depth Trade-Offs
Multi-agent orchestration takes longer than single-model queries. Measure end-to-end latency: time from query submission to final output delivery. Compare this to the depth and quality of analysis.
Typical latency ranges:
- Sequential mode – 30-90 seconds for 3-agent chains
- Fusion mode – 60-120 seconds for 5-model parallel runs
- Debate mode – 2-5 minutes for multi-round exchanges
- Research Symphony – 10-30 minutes for large document sets
Evaluate whether added depth justifies the wait. For time-sensitive decisions, sequential or targeted modes offer better speed-quality balance than full-scale debate.
Scoring Rubric for Quick Comparisons
Rate platforms on a 0-5 scale across five dimensions:
| Dimension | Score 0-1 | Score 2-3 | Score 4-5 |
|---|---|---|---|
| Reliability | Frequent hallucinations, poor citation | Occasional errors, partial citations | Consistent accuracy, full source attribution |
| Reproducibility | High run-to-run variance | Moderate variance, unclear audit trail | Low variance, complete logs |
| Context Management | No memory across sessions | Basic threading, limited entity tracking | Persistent context, knowledge graph |
| Explainability | Black-box outputs | Some reasoning shown, weak citations | Full reasoning chains, verifiable sources |
| Governance | No access controls or audit logs | Basic permissions, manual exports | Role-based access, automated compliance |
Sum scores to get a total out of 25. Platforms scoring below 15 need significant improvement. Scores above 20 indicate production-ready tools.
Evaluation Framework: How to Choose a Multi-Agent Research Tool
Selecting the right platform requires matching capabilities to your workflow. Use this framework to assess fit before committing.
Define Your Problem and Role Design
Start by mapping your research tasks. What questions do you ask repeatedly? What decisions depend on this research? Which failure modes cost the most?
Design agent roles around your workflow:
- Data extraction agents – Pull metrics from financial statements
- Analyst agents – Interpret trends and compare scenarios
- Skeptic agents – Challenge assumptions and probe weaknesses
- Synthesizer agents – Merge outputs into coherent recommendations
Platforms with fixed roles limit customization. Look for systems that let you define custom agents with specific instructions and knowledge bases. For a practical guide, see how to build a specialized AI team.
Mode Coverage and Configurability
Verify the platform supports orchestration modes you need. Not all tools offer debate or red team modes. Some lock you into sequential-only workflows.
Test configurability:
- Can you adjust the number of agents per mode?
- Can you set custom debate rules or red team intensity?
- Can you mix modes (sequential handoff to debate, then fusion synthesis)?
- Can you save mode configurations as templates?
Rigid platforms force you to adapt your workflow to their constraints. Flexible systems adapt to your needs.
Context Persistence and Cross-Document Reasoning
Test how platforms handle multi-session projects. Upload a set of related documents, run several queries, then return a week later. Does the system remember previous analysis? Can agents reference earlier findings without you re-uploading everything?
Evaluate cross-document capabilities:
- Can agents synthesize insights from 10+ documents simultaneously?
- Does the knowledge graph connect entities across sources?
- Can you query relationships (“Which contracts mention both Company A and Product B?”)
- Do living documents update when you add new sources?
Weak context management turns multi-agent tools into glorified chatbots. You want systems that build institutional knowledge over time.
Governance: Permissions, Data Handling, and Compliance
Professional use demands governance controls. Check whether the platform supports:
- Role-based access – Restrict who can view sensitive research
- Audit logging – Track who ran which queries and when
- Data residency – Keep documents in specific geographic regions
- PII handling – Redact or encrypt personal information automatically
- Export controls – Download research for external review or archiving
Platforms built for consumer use often lack these features. Enterprise-grade tools include compliance certifications (SOC 2, GDPR, HIPAA) and detailed data processing agreements.
Integration: Files, APIs, and Export Options
Research doesn’t happen in isolation. You need to pull data from existing systems and push outputs to downstream tools.
Assess integration capabilities:
- File upload – PDF, Word, Excel, PowerPoint, HTML
- API access – Programmatic query submission and result retrieval
- Webhook triggers – Notify other systems when research completes
- Export formats – Markdown, JSON, CSV for reports and dashboards
- Third-party connectors – Slack, Teams, CRM, project management tools
Closed ecosystems create bottlenecks. Open platforms with robust APIs fit into existing workflows without forcing migration.
Cost-Performance Modeling on Your Workload
Multi-agent orchestration costs more than single-model queries because you run multiple models per request. Estimate your monthly spend based on actual usage patterns.
Calculate costs:
- Average queries per user per day
- Typical orchestration mode (fusion costs 5x sequential)
- Document volume and storage fees
- Number of users and access tiers
Compare total cost to value delivered. If multi-agent research prevents one bad investment per quarter, the ROI is clear. If it saves analysts 10 hours per week, calculate that time savings against subscription fees.
Some platforms charge per query, others per user, others per compute unit. Match pricing model to your usage profile. High-volume users benefit from flat-rate plans; sporadic users prefer pay-as-you-go.
Applied Scenarios: Multi-Agent Research in Action
Abstract capabilities matter less than concrete workflows. These scenarios show how professionals deploy multi-agent tools to solve real problems.
Investment Memo Validation with Debate and Fusion
An analyst drafts an investment memo recommending a tech stock. Before circulating to the investment committee, they run the thesis through multi-agent validation.
Workflow:
- Upload sources – 10-K filing, earnings transcripts, competitor filings, industry reports
- Fusion mode – Five models extract key metrics (revenue growth, margins, R&D spend)
- Debate mode – One agent argues the bull case, another presents bear arguments, a third adjudicates
- Red team mode – Adversarial agent probes weakest assumptions (“What if customer concentration risk materializes?”)
- Synthesis – Final memo includes ensemble agreement scores and addresses top counterarguments
Result: The investment committee sees a thesis that survived hostile questioning. They trust the recommendation because the analyst surfaced and addressed objections proactively. For domain-specific examples, see investment decisions with Suprmind.
Legal Precedent Synthesis and Risk Surfacing
A law firm researches case precedents for a patent dispute. They need to identify relevant rulings, extract legal principles, and assess litigation risk.
Workflow:
- Ingest case law – 50+ court opinions from federal circuit and district courts
- Targeted mode – Specialized agents extract holdings, procedural posture, and key facts from each case
- Knowledge graph – Map relationships between cases (citing, distinguishing, overruling)
- Sequential mode – Chain agents to analyze fact patterns, apply precedents, draft risk assessment
- Citation integrity check – Verify every legal claim links to specific case passages
Result: Partners receive a synthesis showing which precedents favor their client, which cut against them, and confidence scores for each argument. The knowledge graph visualizes how courts have treated similar issues over time. Explore legal analysis with Suprmind.
Product-Market Signal Mapping with Knowledge Graph
A product team evaluates whether to build a new feature. They need to synthesize signals from customer reviews, support tickets, sales calls, and competitor launches.
Workflow:
- Aggregate sources – App store reviews, Zendesk tickets, Gong call transcripts, competitor blog posts
- Research Symphony – Deploy 20 agents to process different document sets in parallel
- Knowledge graph – Extract entities (features, pain points, competitors) and map co-occurrence patterns
- Fusion mode – Models vote on whether demand signal is strong enough to justify development
- Living document – Output updates as new reviews and tickets arrive
Result: Product managers see a demand map showing which features customers request most, how often competitors mention similar capabilities, and which pain points remain unaddressed. The living document tracks signal strength over time.
Scientific Literature Review with Citation Integrity Checks
A pharmaceutical researcher reviews clinical trial literature for a drug repurposing proposal. They need to identify relevant studies, assess methodology quality, and flag conflicting results.
Workflow:
- Upload papers – 100+ PubMed articles, FDA submissions, clinical trial registries
- Sequential mode – Extract study design, patient populations, endpoints, and results
- Debate mode – Agents argue whether evidence supports repurposing hypothesis
- Citation integrity – Verify every efficacy claim links to peer-reviewed sources
- Contradiction flagging – Surface studies with conflicting endpoints or safety signals
Result: The researcher submits a literature review showing consensus findings, areas of uncertainty, and which studies need closer examination. Stakeholders trust the analysis because every claim is verifiable and contradictions are explicitly acknowledged.
Workflow Patterns and Templates
Repeatable workflows accelerate research and reduce errors. These templates provide starting points you can customize.
Research Kickoff Checklist
Before launching multi-agent research, complete this checklist:
- Define the decision this research will inform
- List all available source documents and their formats
- Identify which questions must be answered with high confidence
- Choose orchestration modes based on question type (factual = fusion, strategic = debate)
- Set agreement thresholds (when does disagreement trigger human review?)
- Assign roles if using targeted or symphony modes
- Configure audit logging and access permissions
- Schedule checkpoints to review intermediate outputs
Orchestration Decision Tree
Use this decision tree to select modes:
- Is the question purely factual? → Fusion mode for ensemble agreement
- Does it require multi-step reasoning? → Sequential mode with validation checkpoints
- Is there a clear thesis to test? → Debate mode to surface counterarguments
- Do you need to stress-test conclusions? → Red team mode for adversarial probing
- Does it span multiple domains? → Targeted mode with specialized agents
- Is document volume high? → Research Symphony for parallel processing
You can chain modes: start with fusion for data extraction, hand off to debate for interpretation, finish with red team for validation.
Agreement Logging Template
Track ensemble agreement across research projects:
| Query | Mode | Agreement % | Dissenting Agent | Resolution |
|---|---|---|---|---|
| Revenue growth rate | Fusion | 100% | None | High confidence |
| Market share trend | Fusion | 60% | Claude | Manual review – Claude cited newer data |
| Strategic risk assessment | Debate | 40% | Multiple | Escalated to senior analyst |
Log disagreements to identify patterns. If one model consistently dissents, investigate whether it accesses different training data or interprets prompts differently.
Audit-Ready Living Document Outline
Structure outputs for maximum transparency:
- Executive Summary – Key findings with ensemble agreement scores
- Methodology – Which modes ran, which models participated, how consensus was determined
- Source Inventory – List of documents analyzed with upload dates
- Findings by Question – Each research question answered with citations
- Disagreement Log – Where models diverged and how conflicts were resolved
- Limitations – Data gaps, outdated sources, areas needing human judgment
- Recommendations – Next steps with confidence levels
- Appendix – Full agent outputs, prompt logs, version history
This structure satisfies audit requirements while remaining readable. Stakeholders can drill into details when needed without wading through raw logs.
Risks, Limitations, and Ethical Considerations
Multi-agent systems amplify both capabilities and risks. Understand limitations to use these tools responsibly.
Model Drift and Recency
AI models evolve. Providers update training data, fine-tune on new tasks, and deprecate old versions. Model drift means outputs change over time even with identical inputs.
Mitigate drift by:
Watch this video about multi-agent research platform:
- Pinning specific model versions in production workflows
- Re-running critical analyses when models update
- Monitoring agreement rates for sudden shifts
- Maintaining human review for high-stakes decisions
Recency matters too. Models trained on data through 2023 won’t know about 2024 events. Verify that source documents, not model knowledge, drive conclusions.
Data Privacy and Compliance
Uploading sensitive documents to cloud-based AI platforms creates data exposure risk. Understand how providers handle your information:
- Do they train models on your data?
- Where are documents stored geographically?
- Who can access your research sessions?
- How long do they retain data after deletion?
- What happens if the provider suffers a breach?
For regulated industries (finance, healthcare, legal), choose platforms with compliance certifications (SOC 2, GDPR) and data processing agreements. Consider on-premise deployments for the most sensitive work.
Over-Reliance on Consensus
Ensemble agreement feels reassuring but doesn’t guarantee truth. Five models can confidently agree on a hallucination if they share the same training biases.
Prevent over-reliance by:
- Requiring source citations for every factual claim
- Red teaming high-confidence conclusions
- Maintaining human domain expertise in the loop
- Validating a sample of outputs against ground truth
Use multi-agent systems to augment judgment, not replace it. The goal is better-informed decisions, not automated decision-making.
Human-in-the-Loop Design
The most effective multi-agent workflows include human checkpoints. Agents flag uncertainty, humans investigate. Agents generate options, humans choose.
Design intervention points:
- Pre-research – Humans define questions and select modes
- Mid-research – Humans review intermediate outputs and adjust agent instructions
- Post-research – Humans validate conclusions and add context machines miss
Fully automated research pipelines are brittle. They fail silently when assumptions break. Human oversight catches edge cases and adapts to changing circumstances.
Bias Amplification
Multi-agent systems can amplify biases present in training data. If all models learned from similar sources, ensemble agreement might reflect shared blind spots rather than objective truth.
Counter bias by:
- Including models trained on diverse data sets
- Explicitly prompting agents to consider underrepresented perspectives
- Red teaming for demographic, geographic, or ideological bias
- Auditing outputs for fairness and representation
Bias detection is an active research area. Stay current with emerging techniques and incorporate them into your validation workflows.
Where Multi-Agent Research Is Headed
The field evolves rapidly. These trends will shape the next generation of multi-agent tools.
Toolformer-Style APIs and Function Calling
Current agents operate mostly in text. Future systems will call external tools-calculators, databases, APIs-to ground reasoning in real-time data.
Imagine an agent that:
- Queries a financial database for current stock prices
- Runs a Monte Carlo simulation to model risk
- Calls a legal research API to check case status
- Pulls live market data to validate assumptions
This “toolformer” approach reduces hallucinations by anchoring outputs in verifiable external sources. Multi-agent orchestration becomes a coordination layer over diverse information systems.
Long-Context Synthesis and Retrieval Advances
Models with million-token context windows will handle entire document sets in one pass. This eliminates chunking and retrieval steps, simplifying data flow.
Long-context models enable:
- Whole-document reasoning without semantic search
- Cross-reference checking across hundreds of pages
- Reduced latency by skipping retrieval steps
Still, long context doesn’t solve all problems. Retrieval remains valuable for massive corpora where even million-token windows are insufficient. Hybrid approaches will combine long-context models with targeted retrieval.
Open Evaluation Benchmarks for Agent Reliability
The field lacks standardized benchmarks for multi-agent performance. Vendors make claims about accuracy and reliability without reproducible tests.
Emerging benchmarks will measure:
- Factual accuracy – Percentage of verifiable claims that are correct
- Citation precision – How often citations support the claims they’re attached to
- Ensemble calibration – Whether high-agreement predictions are actually more accurate
- Adversarial robustness – How well systems resist prompt injection and jailbreaks
Open benchmarks will enable apples-to-apples comparisons and drive competition on metrics that matter to professionals.
Specialized Domain Models
General-purpose models will be supplemented by domain-specific agents fine-tuned on legal, financial, medical, or scientific corpora. These specialists will outperform general models on narrow tasks.
Multi-agent platforms will orchestrate mixed teams:
- A general model handles broad reasoning
- A financial model interprets SEC filings
- A legal model analyzes case law
- A medical model reviews clinical trials
This specialization improves accuracy while maintaining flexibility for cross-domain research.
Continuous Learning from User Feedback
Current systems don’t learn from corrections. If you fix a hallucination, the next user encounters the same error. Future platforms will implement feedback loops:
- Users flag incorrect outputs
- System logs corrections and retrains agents
- Improved models deploy automatically
- Collective intelligence grows over time
This requires careful design to prevent malicious feedback from degrading performance. Privacy-preserving federated learning may enable cross-organization improvement without sharing sensitive data.
Frequently Asked Questions
What makes a research tool “multi-agent” compared to regular AI chat?
A multi-agent research tool coordinates multiple AI models working together on the same problem. Regular AI chat sends your query to one model. Multi-agent systems split work across specialized roles, compare outputs, and synthesize consensus. This reduces single-model bias and surfaces contradictions that one model might miss.
How do I know when to use debate mode versus fusion mode?
Use fusion mode when you want multiple perspectives on the same question without structured disagreement. Fusion runs models in parallel and compares their answers. Use debate mode when you need to test a specific thesis or hypothesis. Debate assigns opposing roles-one agent defends a position, another attacks it. Debate works best for strategic decisions where you need to surface counterarguments.
Can these systems replace human analysts?
No. Multi-agent tools augment human judgment but don’t replace domain expertise. They excel at processing large document sets, surfacing contradictions, and generating initial drafts. Humans remain essential for interpreting nuance, applying industry context, and making final decisions. The best workflows combine machine speed with human insight.
How do I prevent hallucinations in multi-agent outputs?
Require source citations for every factual claim. Use red team mode to challenge high-confidence conclusions. Validate a sample of outputs against original documents. Track ensemble agreement-low agreement flags areas needing human review. Remember that consensus doesn’t guarantee correctness; always verify claims against primary sources.
What’s the difference between a knowledge graph and a vector database?
A vector database stores document chunks as numerical embeddings for similarity search. When you query “revenue growth,” it retrieves semantically related passages. A knowledge graph extracts entities and relationships from those passages-companies, people, dates, connections. The graph enables reasoning about relationships (“Which companies supply to both A and B?”) that pure similarity search can’t answer.
How much does multi-agent research cost compared to single-model chat?
Multi-agent orchestration costs more because you run multiple models per query. Fusion mode with five models costs roughly five times a single-model query. Debate and red team modes add rounds of interaction, multiplying costs further. Even so, the value often justifies the expense-preventing one bad decision can save far more than subscription fees.
What happens to my data when I upload documents to these platforms?
This depends on the provider. Some train models on customer data; others keep it isolated. Check the data processing agreement. For sensitive work, choose platforms with compliance certifications (SOC 2, GDPR) and clear data retention policies. Consider on-premise deployments for the most confidential research.
How long does it take to get results from multi-agent research?
Sequential mode typically takes 30-90 seconds for three-agent chains. Fusion mode with five models runs 60-120 seconds. Debate mode needs 2-5 minutes for multi-round exchanges. Research Symphony handling large document sets can take 10-30 minutes. Latency depends on document volume, model selection, and orchestration complexity.
Can I customize which models participate in each research session?
Advanced platforms let you select specific models for each agent role. You might choose GPT-4 for strategic reasoning, Claude for document analysis, and Gemini for data extraction. Some systems lock you into fixed model sets. Test configurability during evaluation-rigid platforms limit your ability to optimize for specific tasks.
How do I measure whether multi-agent research is working?
Track ensemble agreement rates, citation coverage, hallucination frequency, and run-to-run variance. Compare time spent on research before and after adoption. Survey users about confidence in conclusions. Measure downstream decision quality-did multi-agent research lead to better outcomes? Use the scoring rubric in this article to benchmark performance quarterly.
Getting Started with Multi-Agent Research
Multi-agent orchestration transforms how professionals validate high-stakes decisions. By coordinating multiple models through sequential, fusion, debate, and red team modes, you surface contradictions, reduce bias, and build defensible audit trails.
Key takeaways:
- Choose orchestration modes based on question type and risk tolerance
- Measure reliability through ensemble agreement, citation coverage, and reproducibility
- Implement governance controls from day one-permissions, audit logs, data handling
- Select platforms with mode flexibility, persistent context, and integration capabilities
- Maintain human oversight at critical decision points
The best multi-agent tools don’t just answer questions faster. They help you ask better questions, test assumptions you didn’t know you held, and converge on conclusions you can defend to stakeholders.
Start by mapping your current research workflow. Identify bottlenecks, failure modes, and decisions that carry the highest stakes. Pilot multi-agent orchestration on a contained project where you can compare outputs to traditional methods. Measure time savings, agreement rates, and decision quality.
As you gain confidence, expand to more complex scenarios. Build templates for recurring research patterns. Train your team on when to use each orchestration mode. Develop governance policies that balance speed with audit requirements.
Multi-agent research isn’t about replacing human judgment. It’s about giving professionals the tools to make better-informed decisions faster, with audit trails that withstand scrutiny. When the stakes are high and the margin for error is thin, orchestrating multiple perspectives becomes a competitive advantage. Learn more about living documents and explore the full feature set to fit your workflow.





