
A large language model is a neural network trained on massive text datasets to predict and generate human-like language. These systems power everything from chatbots to code assistants, but they don’t “understand” text the way humans do. They learn statistical patterns across billions of words, enabling them to complete sentences, answer questions, summarize documents, and generate new content based on those learned patterns.
LLMs excel at language fluency and can handle tasks like classification, extraction, summarization, and reasoning. They can draft legal briefs, synthesize research papers, or analyze financial scenarios. The catch? They predict the most probable next word, not the most accurate one. This distinction matters when stakes are high.
Common misconceptions include treating LLM outputs as facts rather than predictions. A model might confidently cite a non-existent case or invent statistics that sound plausible. Learn how orchestrated, cross-verified AI works in practice to catch these blind spots before they become costly errors.
How LLMs Work: Transformer Architecture Basics
Modern LLMs rely on the transformer architecture, introduced in 2017. The process starts with tokenization, breaking text into smaller units (words or subwords) that the model can process. Each token gets converted into a numerical embedding that captures semantic meaning.
Self-Attention and Context Building
The core innovation is self-attention, which lets the model weigh the importance of every word relative to every other word in the input. When processing “The bank approved the loan,” self-attention helps the model distinguish between “bank” as a financial institution versus a river bank based on surrounding context.
Transformer blocks stack multiple attention layers with feed-forward networks. Each layer refines the representation, building deeper understanding of relationships between tokens. This architecture scales efficiently to billions of parameters.
Decoding Strategies and Context Windows
Once trained, LLMs generate text through decoding strategies that balance creativity and coherence:
- Greedy decoding picks the highest-probability token at each step (deterministic but repetitive)
- Top-k sampling randomly selects from the k most likely tokens (adds controlled randomness)
- Nucleus sampling chooses from the smallest set of tokens whose cumulative probability exceeds a threshold
- Temperature controls randomness – lower values produce focused outputs, higher values increase diversity
The context window defines how much text the model can consider at once. Early models handled 2,000 tokens; current systems process 100,000+ tokens. Longer windows enable richer context but increase computational cost and can dilute attention to critical details.
From Pretraining to Useful Systems
Building a useful LLM involves multiple training stages, each refining the model for specific applications.
Pretraining and Language Modeling Objectives
Pretraining exposes the model to massive text corpora (books, websites, code repositories). Two main approaches dominate:
- Masked language modeling hides random tokens and trains the model to predict them (used by BERT-style models)
- Causal language modeling predicts the next token given all previous tokens (used by GPT-style models)
Pretraining creates a foundation model with broad language capabilities but no task-specific skills.
Fine-Tuning and Alignment
Supervised fine-tuning trains the pretrained model on curated examples of desired behavior. Instruction tuning teaches the model to follow user prompts by training on instruction-response pairs.
Reinforcement learning from human feedback (RLHF) further refines outputs. Human raters rank model responses, and the model learns to maximize scores for helpful, harmless, honest outputs. This alignment process reduces harmful content and improves response quality.
Tool Use and Retrieval-Augmented Generation
Modern LLMs extend beyond text generation through function calling and retrieval-augmented generation (RAG). Function calling lets models invoke external APIs for calculations, database queries, or web searches. RAG retrieves relevant documents before generating responses, grounding outputs in verified sources.
These techniques address knowledge staleness and hallucinations by connecting models to current information. A legal assistant using RAG can cite specific case law rather than inventing precedents.
Strengths and Limitations in High-Stakes Work

LLMs deliver impressive capabilities but carry risks that compound in professional contexts where errors have consequences.
Core Strengths
- Language fluency produces grammatically correct, contextually appropriate text at scale
- Synthesis across domains connects concepts from diverse sources in seconds
- Few-shot generalization performs new tasks with minimal examples
- Rapid iteration generates multiple drafts, perspectives, or approaches instantly
Critical Limitations
Hallucinations remain the most dangerous limitation. Models generate plausible-sounding content with no grounding in reality. A medical literature review might cite studies that don’t exist. A financial analysis might reference non-existent regulations. The output looks authoritative until verified.
Models exhibit brittleness under distribution shift. Performance degrades when inputs differ from training data. A model trained on formal business writing struggles with technical jargon or colloquial language.
- Outdated knowledge – training data has a cutoff date, missing recent developments
- Reasoning traps – models fail at multi-step logic requiring symbolic manipulation
- Inconsistency – the same prompt can yield different outputs across runs
- Bias amplification – training data biases persist in generated content
In legal contexts, a hallucinated case citation can undermine an entire brief. In medical applications, incorrect drug interactions risk patient safety. In finance, flawed scenario analysis leads to poor capital allocation. See where verification matters most in high-stakes decisions to understand the full scope of risk.
Verification and Governance in Practice
Deploying LLMs responsibly requires systematic verification and governance controls. These aren’t optional safeguards – they’re operational requirements.
Verification Checklist
- Cite sources – require models to reference specific documents, cases, or data points
- Cross-check facts – verify claims against authoritative sources before accepting them
- Constrain outputs – use structured formats (JSON, forms, templates) to reduce hallucination surface area
- Human review gates – insert mandatory human checkpoints before final decisions
- Confidence scoring – flag low-confidence outputs for additional scrutiny
Governance Framework
Effective governance balances capability with control:
- Prompt logging captures all inputs and outputs for audit trails
- Role-based access restricts sensitive model capabilities to authorized users
- Data privacy controls prevent leakage of confidential information into training or prompts
- Monitoring dashboards track usage patterns, error rates, and anomalies
- Incident response plans define procedures when models produce harmful or incorrect outputs
Evaluation and Benchmarks
Evaluation depends on task type. Classification tasks use exact match accuracy or F1 scores. Summarization tasks historically used BLEU or ROUGE metrics, but these correlate poorly with human judgment – prefer human evaluation or factuality checks.
For generation tasks, combine multiple approaches:
- Benchmark suites like MMLU (general knowledge), Big-Bench (diverse reasoning), and HELM (holistic evaluation)
- Domain-specific test sets reflecting actual use cases
- Human evaluation on coherence, factuality, and usefulness
- Adversarial testing to expose edge cases and failure modes
Map your task to appropriate metrics. Legal document analysis requires factuality checks and citation verification. Creative writing prioritizes coherence and engagement. Financial forecasting demands numerical accuracy and assumption transparency.
Single-Model vs. Orchestrated Multi-Model Workflows
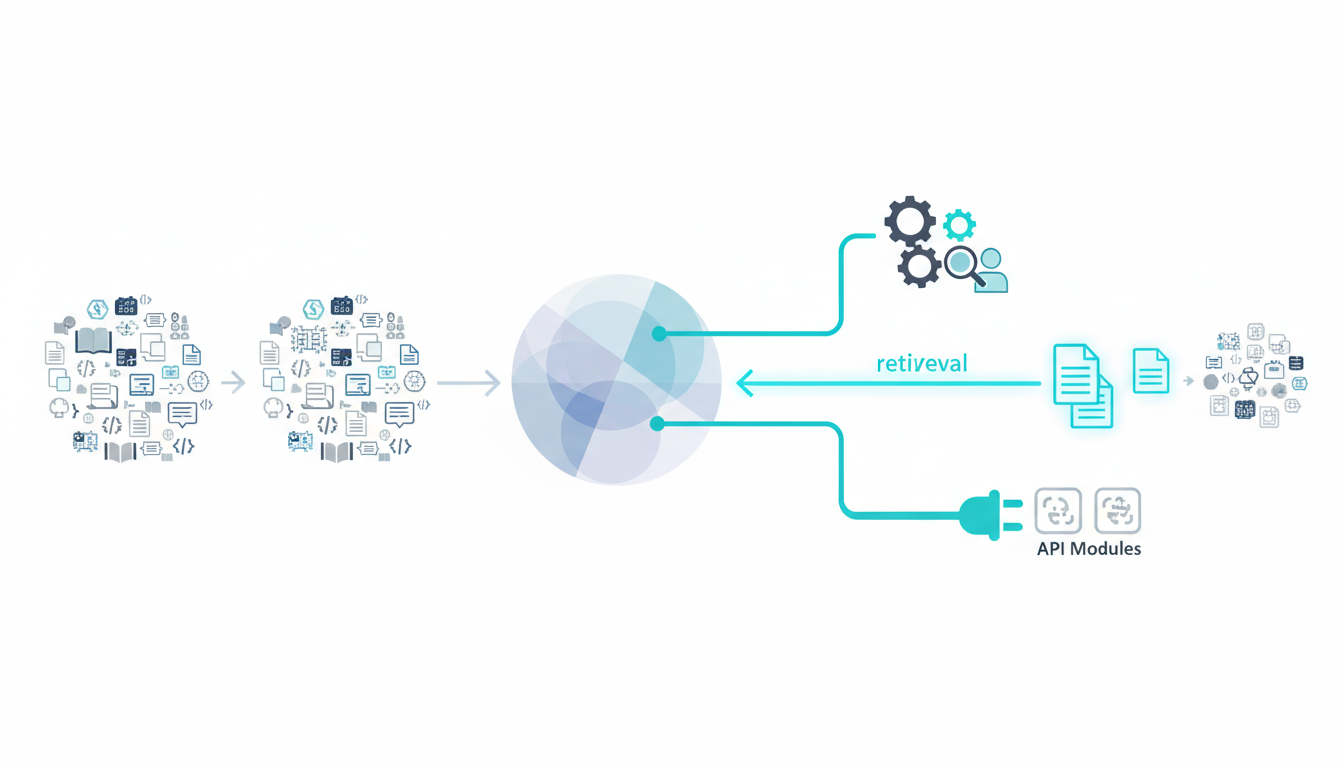
Most LLM deployments use a single model. This works for straightforward tasks with clear success criteria and low error tolerance. When stakes rise or complexity increases, orchestrated workflows offer meaningful advantages.
When Single Models Suffice
A single model handles routine tasks efficiently:
Watch this video about large language model:
- Email drafting with standard templates
- Data extraction from structured documents
- Classification with well-defined categories
- Simple summarization of short texts
Why Add Cross-Verification
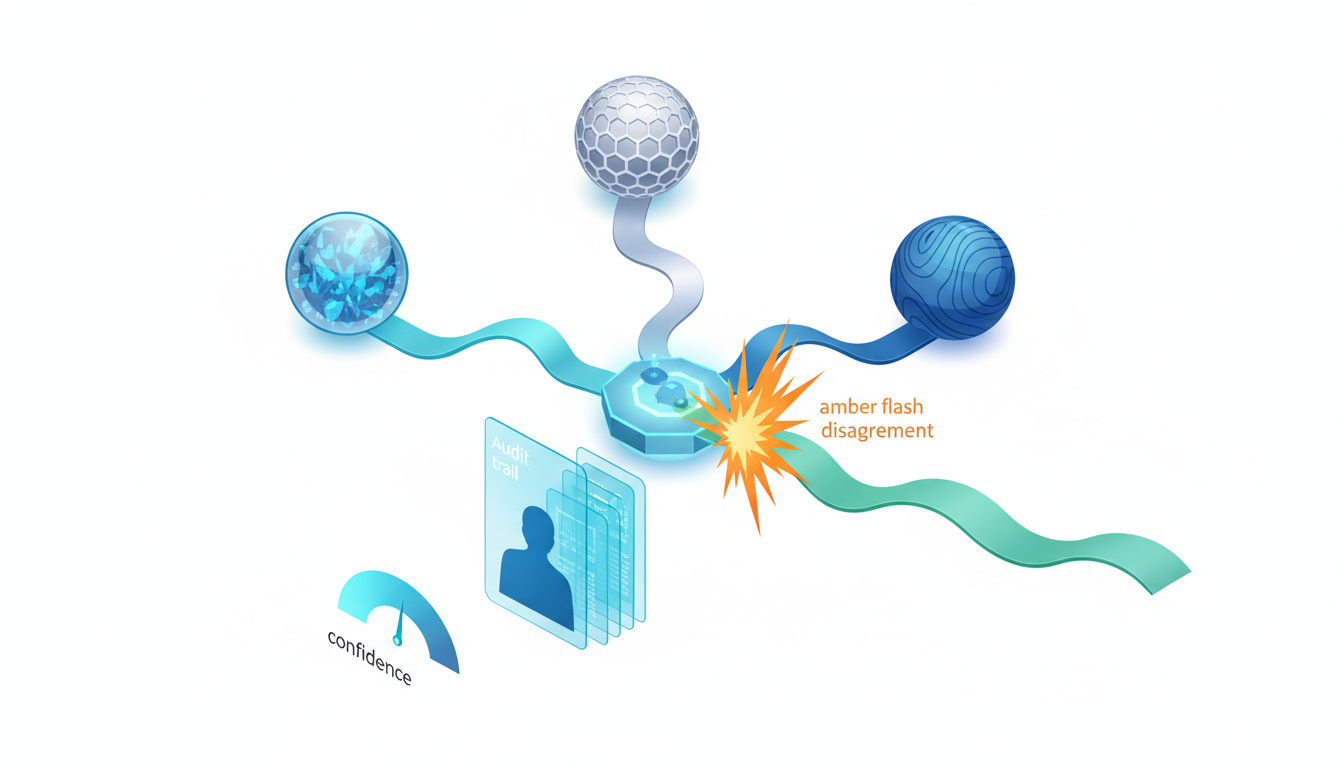
Model diversity exposes blind spots. Different models have different training data, architectures, and failure modes. When multiple models agree, confidence increases. When they disagree, the friction reveals assumptions worth examining.
Orchestrated workflows shine in high-stakes scenarios:
- Legal research – multiple models analyze case law, surface conflicting interpretations, flag ambiguities
- Clinical literature synthesis – cross-verification catches misread studies or overlooked contraindications
- Strategic analysis – diverse perspectives challenge groupthink and identify unconsidered risks
Trade-Off Comparison
| Dimension | Single Model | Orchestrated Multi-Model |
|---|---|---|
| Quality | Good for routine tasks | Higher for complex reasoning |
| Risk | Unchecked hallucinations | Cross-verification reduces errors |
| Cost | Lower per query | Higher but justified for critical work |
| Latency | Faster responses | Sequential processing adds time |
| Governance | Simpler audit trail | Richer disagreement logs |
Orchestrated debate surfaces disagreements that single models hide. When models conflict, you get a signal to investigate further rather than accepting the first plausible answer. Explore multi-AI orchestration concepts and examples to see how sequential context-building compounds intelligence.
Implementing LLMs Safely: Step-by-Step
Successful LLM deployment follows a structured approach that prioritizes verification from the start.
Step 1: Define Tasks and Success Metrics
Specify exactly what the model should do and how you’ll measure success. Vague goals like “improve productivity” fail. Concrete metrics like “reduce contract review time by 40% while maintaining 99% accuracy” succeed.
Step 2: Choose Model(s) and Context Strategy
Select models based on task requirements. Consider parameter count, context window size, and specialization. Decide between RAG (retrieval-augmented generation) for dynamic knowledge and long context windows for processing large documents.
Step 3: Design Prompt Patterns and Constraints
Prompt engineering shapes model behavior. Effective patterns include:
- Role specification – “You are a legal analyst reviewing contracts for risk”
- Output constraints – “List exactly three risks with supporting citations”
- Chain-of-thought – “Explain your reasoning step-by-step before concluding”
- Few-shot examples – show desired input-output pairs
Step 4: Build Verification Gates and Human-in-the-Loop
Insert checkpoints where humans review model outputs before they influence decisions. For high-stakes work, require dual verification: automated fact-checking plus human expert review.
Step 5: Monitor, Collect Feedback, and Re-evaluate
Track performance metrics continuously. Collect user feedback on output quality. Run periodic re-evaluations as models update or use cases evolve. Maintain a feedback loop that identifies failure patterns and refines prompts.
Real-World Application Patterns
Legal Research with Citation Verification
A law firm uses LLMs to draft research memos. The system retrieves relevant case law through RAG, generates analysis, and requires citation verification before human review. When multiple models disagree on case interpretation, the disagreement flags ambiguity for attorney review. The audit trail logs all sources and reasoning steps.
Clinical Literature Synthesis
Medical researchers synthesize hundreds of papers on treatment efficacy. An orchestrated workflow has multiple models extract key findings, identify methodology issues, and flag contradictions. Disagreements between models surface edge cases – studies with conflicting results or methodological concerns that a single model might miss.
Strategic Planning with Multi-Perspective Analysis
A strategy team evaluates market entry options. Different models analyze competitive landscape, regulatory risks, and financial projections. The orchestrated debate reveals assumptions each model makes, helping the team understand which risks matter most. The final memo includes dissenting perspectives alongside consensus recommendations.
Frequently Asked Questions
Are more parameters always better?
Not necessarily. Larger models have more capacity but require more compute and can be slower. A 7-billion parameter model fine-tuned for your domain often outperforms a generic 100-billion parameter model. Match model size to task complexity and resource constraints.
How do context windows affect quality?
Longer context windows let models process more information but can dilute attention to critical details. A 100,000-token window enables analyzing entire documents but may miss subtle patterns that shorter, focused contexts catch. Use the smallest window that captures necessary context.
What benchmarks matter for my use case?
Match benchmarks to your task type. MMLU tests general knowledge. Big-Bench evaluates diverse reasoning. For specialized domains, create custom test sets reflecting actual use cases. Generic benchmarks indicate general capability but don’t guarantee performance on your specific task.
How do I reduce hallucinations?
Combine multiple techniques: use RAG to ground outputs in verified sources, constrain output formats to reduce free-form generation, require citation of specific sources, implement cross-verification with multiple models, and insert human review gates before final decisions.
When should I consider multiple models?
When errors carry significant consequences, when tasks require nuanced judgment, or when single-model outputs lack confidence. Legal analysis, medical decisions, financial planning, and strategic planning all benefit from cross-verification. For routine tasks with low error tolerance, single models suffice.
Moving Forward with Verification-First Practices
Large language models deliver powerful capabilities for language tasks, but reliability depends on verification, evaluation, and governance. Single models provide speed and simplicity. Orchestrated workflows surface disagreements that reduce risk in high-stakes decisions.
Adopt LLMs stepwise: define clear tasks and metrics, choose appropriate models and context strategies, design constrained prompts, build verification gates into workflow, and monitor performance continuously. The goal isn’t eliminating all errors – it’s catching them before they become costly.
Disagreement between models isn’t a bug. It’s a feature that reveals blind spots and untested assumptions. When stakes are high, you need more than one confident answer. You need verification built into the process from the start.





