
For analysts and researchers, the question isn’t whether generative AI can draft – it’s whether you can trust its output when the cost of being wrong is real. A single-model chat can produce a polished memo in minutes, but without verification, that speed becomes a liability. When you’re validating investment theses or building legal arguments, you need more than clever text generation.
Generative AI refers to machine learning systems that create new content – text, images, code, audio – by learning patterns from training data. Unlike discriminative models that classify or predict, generative models synthesize. They produce outputs that didn’t exist in their training sets but follow learned statistical patterns. This distinction matters because synthesis introduces both power and risk.
The challenge: single-model outputs can hallucinate sources, miss contradictions, and produce inconsistent reasoning across similar queries. Without evaluation frameworks and governance, you’re building decisions on sand. This guide explains how generative AI works under the hood, where it fails, and how orchestration patterns convert demos into dependable workflows.
Core Model Families and Their Trade-Offs
Understanding what different model types do helps you pick the right tool for each task. Generative AI isn’t one technology – it’s several architectures solving different problems.
Large Language Models and Transformers
Large language models process and generate text using transformer architectures. Transformers use attention mechanisms to weigh relationships between words, letting models handle context across thousands of tokens. GPT-4, Claude, and Gemini all build on this foundation.
These models excel at:
- Drafting structured documents from prompts and examples
- Extracting information from unstructured text
- Reasoning through multi-step problems when prompted correctly
- Generating code and debugging existing implementations
- Translating between languages and technical levels
The limits show up in hallucinations – confidently stated false information – and citation failures where models invent sources or misattribute claims. Token limits restrict how much context fits in a single prompt, forcing you to chunk long documents and risk losing connections.
Diffusion Models for Visual Content
Diffusion models generate images by learning to reverse a noise process. Starting from random pixels, they iteratively denoise toward a target distribution learned from training data. DALL-E, Midjourney, and Stable Diffusion use variants of this approach.
Applications include:
- Concept visualization for strategy presentations
- Product mockups and design iteration
- Data visualization when combined with structured inputs
- Marketing asset generation at scale
Quality depends heavily on prompt specificity and training data coverage. These models struggle with precise layouts, consistent character generation across images, and text rendering within images.
Multimodal Systems
Multimodal AI processes multiple input types – text, images, audio, video – in a unified model. GPT-4V and Gemini Pro Vision can analyze charts, interpret diagrams, and answer questions about visual content. This capability matters for workflows that blend document analysis with visual evidence.
The 5-Model AI Boardroom approach lets you run different model families simultaneously, capturing diverse perspectives on the same input. When analyzing a pitch deck, you might use one model for financial projections, another for market sizing claims, and a third for competitive positioning – then synthesize their outputs.
How Training Shapes Model Behavior
Model capabilities come from training stages that progressively refine behavior. Understanding this pipeline helps you predict failure modes and set realistic expectations.
Pretraining and Foundation Models
Foundation models learn general patterns by predicting the next token in massive text corpora. This pretraining creates broad knowledge but no task-specific behavior. The model knows language structure and common facts but doesn’t follow instructions reliably.
Key characteristics of pretrained models:
- Broad knowledge across domains with uneven depth
- No inherent instruction-following without further training
- Sensitive to prompt phrasing and format
- Knowledge cutoff dates that create blind spots
Supervised Fine-Tuning
Fine-tuning trains models on task-specific datasets to specialize behavior. A legal research model might train on case law summaries, while a code generation model trains on repositories with tests and documentation. This stage teaches the model what good outputs look like for specific tasks.
Fine-tuned models show stronger performance on in-domain tasks but can lose general capabilities. The training data quality directly determines output reliability – garbage in, garbage out applies with force.
Reinforcement Learning from Human Feedback
RLHF aligns model outputs with human preferences by training on ranked responses. Human raters compare multiple outputs for the same prompt, teaching the model which responses are more helpful, accurate, or safe. This process reduces harmful outputs and improves instruction following.
The downside: RLHF can make models overly cautious, refusing valid requests that pattern-match to training examples of harmful content. It also bakes in the biases and preferences of the rating pool, which may not match your use case.
Failure Modes That Matter for High-Stakes Work
Knowing where models break helps you build defenses. These aren’t edge cases – they’re predictable failure patterns you’ll encounter regularly.
Hallucinations and Source Fabrication
Models generate plausible-sounding content without verifying truth. They’ll cite non-existent papers, invent statistics, and confidently misstate facts. This happens because language models optimize for coherence, not accuracy. The training objective is to predict likely next tokens, not to verify claims against ground truth.
Mitigation strategies:
- Require citations for factual claims and verify each source
- Use retrieval augmented generation to ground outputs in verified documents
- Run claims through multiple models and flag disagreements
- Maintain golden test sets of known-correct outputs for validation
- Implement automated fact-checking against trusted databases
Prompt Injection and Adversarial Inputs
Carefully crafted prompts can override instructions and extract training data or manipulate outputs. In professional contexts, this matters less for security and more for reliability – subtle phrasing changes can flip conclusions or introduce bias.
The Context Fabric approach maintains conversation history and instruction sets separately, reducing the risk that user inputs override system prompts. This separation matters when building workflows that combine user queries with fixed evaluation criteria.
Distribution Shift and Training Data Limits
Models perform best on inputs similar to their training data. When you ask about recent events, niche domains, or proprietary information, performance degrades. Knowledge cutoff dates create hard boundaries where models have zero information.
Address this through:
- Retrieval augmented generation with current documents
- Fine-tuning on domain-specific corpora
- Explicit prompts that acknowledge knowledge limits
- Verification steps that catch anachronisms
Data Architecture for Reliable Outputs
How you structure and retrieve information determines whether models can access the right context. Token limits and retrieval strategies shape what’s possible.
Context Windows and Token Limits
Transformers process fixed-length sequences measured in tokens. GPT-4 handles 128K tokens, Claude extends to 200K, but longer contexts increase latency and cost. When analyzing multi-document research, you’ll hit these limits fast.
Strategies for long contexts:
- Chunk documents and process sequentially with summary chaining
- Use hierarchical summarization to compress before detailed analysis
- Extract key sections based on relevance scoring
- Maintain persistent context across conversations rather than reloading full documents
Retrieval Augmented Generation
RAG systems retrieve relevant documents from a knowledge base and inject them into prompts. This grounds model outputs in verified sources and extends knowledge beyond training data. The quality of your retrieval determines the quality of your outputs.
Effective RAG requires:
- Vector databases that embed documents for semantic search
- Chunking strategies that preserve context within retrieved segments
- Ranking algorithms that surface the most relevant passages
- Metadata filters that constrain retrieval to trusted sources
- Citation tracking that links generated claims to source documents
Knowledge Graphs for Traceability
Knowledge graphs represent entities and relationships explicitly, enabling structured reasoning and source tracking. When analyzing investment opportunities, a Knowledge Graph can map companies to executives, funding rounds, competitors, and regulatory filings – making it easy to verify claims and explore connections.
Graphs complement vector search by providing:
- Explicit relationship traversal for multi-hop reasoning
- Provenance tracking from claims to original sources
- Consistency checking across related entities
- Temporal reasoning about events and sequences
Multi-LLM Orchestration to Reduce Bias
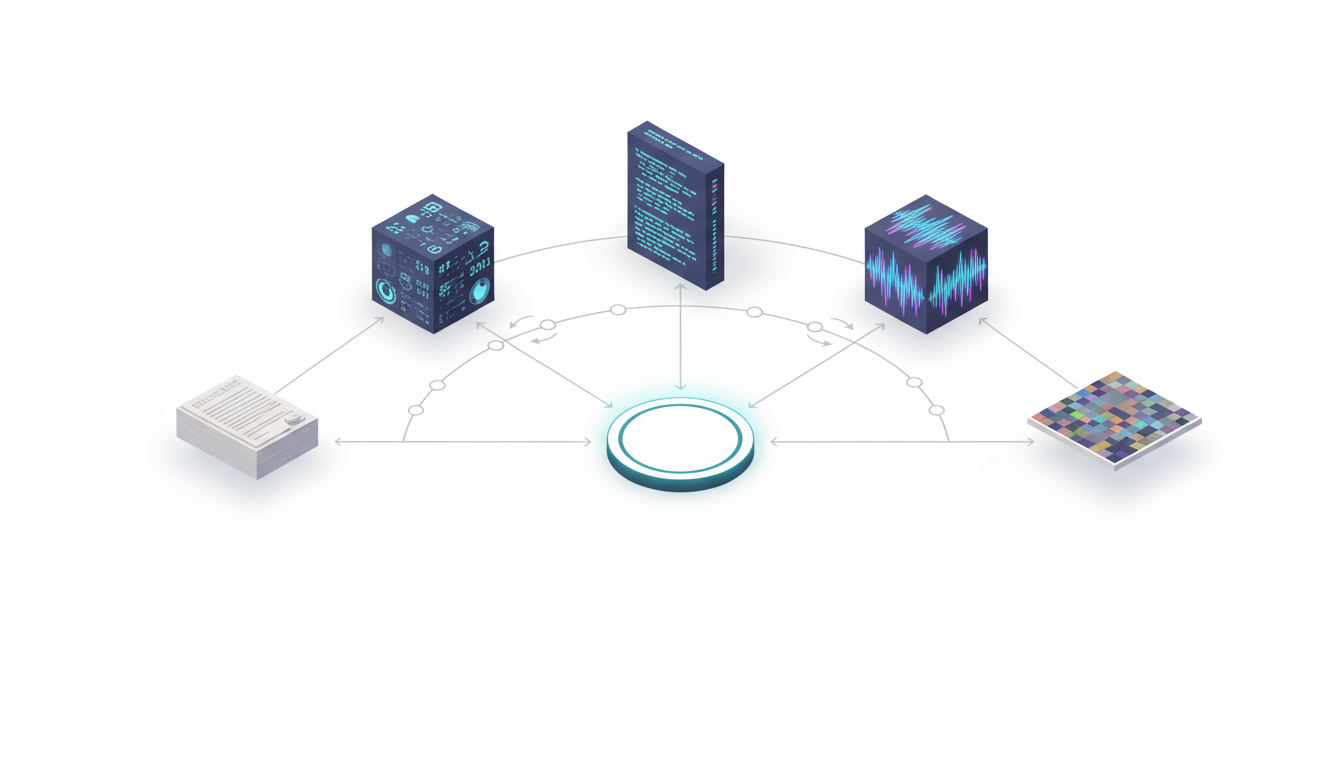
Single models have blind spots, biases, and inconsistent reasoning. Running multiple models in coordination surfaces disagreements and improves decision confidence. This isn’t about redundancy – it’s about structured disagreement that reveals assumptions.
Orchestration Modes for Different Tasks
Different orchestration patterns solve different problems. Sequential processing chains outputs, fusion combines perspectives, debate surfaces contradictions, and red team attacks conclusions.
Sequential mode passes outputs from one model to the next, refining iteratively. Use this for tasks with clear stages – research, draft, critique, revise. Each model specializes in one step.
Fusion mode runs models in parallel and synthesizes their outputs. When analyzing a contract, you might have one model focus on financial terms, another on liability clauses, and a third on termination conditions. Fusion consolidates their findings into a unified assessment.
Debate mode assigns models opposing positions and has them argue. This surfaces weak points in reasoning and tests claims against counter-arguments. For investment decision support, debate mode can pit bull and bear cases against each other, forcing explicit reasoning about risks.
Red team mode dedicates models to attacking conclusions. One model generates analysis, others try to break it. This adversarial approach catches assumptions, missing evidence, and logical gaps before they reach stakeholders.
Consensus and Dissent Capture
When models disagree, the disagreement contains information. Forcing consensus too early loses valuable signals about uncertainty and alternative interpretations.
Effective orchestration captures:
- Points of agreement across all models as high-confidence claims
- Points of disagreement with reasoning from each perspective
- Confidence levels for contested conclusions
- Missing information that would resolve disagreements
- Assumptions each model makes explicitly or implicitly
When performing due diligence workflows, dissent capture helps you identify which claims need additional verification and which risks different stakeholders might weigh differently.
Task Routing and Model Selection
Not every model excels at every task. Routing queries to specialized models improves both quality and cost efficiency. Financial analysis might route to models trained on market data, while legal research routes to models with stronger citation capabilities.
Routing strategies include:
- Rule-based routing by query type or domain
- Classifier-based routing that predicts optimal model from query content
- Adaptive routing that learns from feedback on output quality
- Cost-based routing that balances performance and expense
Evaluation Frameworks for Defensible Outputs
Without measurement, you can’t improve or defend your work. Evaluation converts subjective quality into trackable metrics and reproducible standards.
Defining Quality Criteria
Start by defining what “good” means for your specific task. Investment memos need accurate financial data, complete risk assessment, and clear recommendations. Legal briefs need valid citations, sound arguments, and coverage of relevant precedents. Generic quality metrics miss these task-specific requirements.
Quality dimensions to measure:
Watch this video about generative ai:
- Accuracy – factual correctness of claims and data
- Completeness – coverage of required topics and perspectives
- Citation validity – verifiable sources that support claims
- Logical consistency – arguments that don’t contradict themselves
- Relevance – focus on the specific question asked
- Clarity – understandable to the target audience
Building Test Sets and Rubrics
Golden test sets contain known-correct examples that models should handle well. For legal analysis with orchestration, a golden set might include landmark cases with verified summaries, key holdings, and citation chains. New outputs get compared against these benchmarks.
Evaluation rubrics translate quality dimensions into scorable criteria:
| Criterion | Weight | Pass Threshold | Measurement Method |
|---|---|---|---|
| Citation accuracy | 30% | 95% | Automated verification against source database |
| Claim completeness | 25% | 90% | Checklist of required elements |
| Logical consistency | 20% | No contradictions | Automated contradiction detection |
| Risk coverage | 15% | All major categories | Domain-specific taxonomy match |
| Clarity score | 10% | 8/10 | Readability metrics plus human review |
Automated Scoring and Human Review
Some quality dimensions automate cleanly – citation verification, consistency checking, coverage of required topics. Others need human judgment – argument strength, strategic insight, tone appropriateness. The goal is to automate what you can and focus human review on high-value assessment.
Hybrid evaluation workflow:
- Automated checks catch obvious failures fast
- Scoring algorithms rank outputs by rubric criteria
- Human reviewers focus on borderline cases and strategic judgment
- Feedback loops update rubrics and improve automated checks
- Track drift in model performance over time
Guardrails and Governance for Professional Use
AI governance isn’t bureaucracy – it’s the difference between experimental tools and systems you can defend to stakeholders. Clear policies, logging, and incident response turn pilots into production workflows.
Content Filtering and Safety Checks
Guardrails prevent harmful outputs and catch policy violations before they reach users. In professional contexts, this includes detecting potential IP leakage, PII exposure, and regulatory compliance issues.
Essential guardrails:
- Input validation that blocks adversarial prompts
- Output filtering for harmful content and policy violations
- PII detection and redaction before logging or sharing
- Regulatory compliance checks for industry-specific rules
- Rate limiting to prevent abuse and manage costs
Logging and Audit Trails
Every query, output, and decision needs a paper trail. When regulators or opposing counsel ask how you reached a conclusion, logs provide evidence. Track prompts, model versions, orchestration modes, evaluation scores, and human interventions.
Audit requirements:
- Immutable logs of all inputs and outputs
- Version tracking for models, prompts, and evaluation rubrics
- Attribution of decisions to specific model runs
- Change logs when humans override or edit outputs
- Retention policies that balance compliance and storage costs
Mapping to Standards and Frameworks
The NIST AI Risk Management Framework provides a structure for identifying, measuring, and mitigating AI risks. ISO/IEC 23894 covers risk management for AI systems. These frameworks help you demonstrate due diligence to stakeholders and regulators.
NIST AI RMF functions to implement:
- Govern – establish policies, roles, and accountability
- Map – identify AI risks in your specific context
- Measure – quantify risks and track metrics
- Manage – implement controls and response plans
Start small: define acceptable use, require human review for high-stakes outputs, log everything, and establish an incident response process. Expand governance as you scale usage.
Context Management for Long-Horizon Research
Professional research spans days or weeks, accumulating evidence and evolving understanding. Models need to maintain context across sessions without forcing you to reload entire conversation histories.
Persistent Memory Strategies
Persistent context keeps relevant information accessible across conversations. When you return to an investment analysis after reviewing new data, the system should remember previous findings, open questions, and working hypotheses.
The Context Fabric maintains conversation state, user preferences, and domain knowledge separately. This lets you pause research, explore tangents, and return to the main thread without losing progress. Context persists across sessions and scales beyond token limits.
Retrieval Patterns for Complex Research
As research progresses, you build a corpus of analyzed documents, extracted facts, and working conclusions. Effective retrieval surfaces the right information at the right time without overwhelming the context window.
Retrieval strategies that scale:
- Semantic search over conversation history to find relevant prior discussions
- Temporal ordering that prioritizes recent context
- Topic clustering that groups related research threads
- Importance scoring that surfaces key findings over supporting details
- User-directed retrieval that lets you explicitly reference past work
Linking Claims to Sources
Every claim in a decision memo needs a source. Knowledge graphs make this explicit by linking generated statements to the documents, data points, or model runs that produced them. When stakeholders question a conclusion, you can trace it back to evidence.
Traceability requirements:
- Every factual claim links to a source document or data point
- Source metadata includes retrieval timestamp and version
- Confidence scores attach to claims based on source quality
- Conflicting sources get flagged for human review
- Citation chains show reasoning from evidence to conclusion
Conversation Control for Professional Workflows
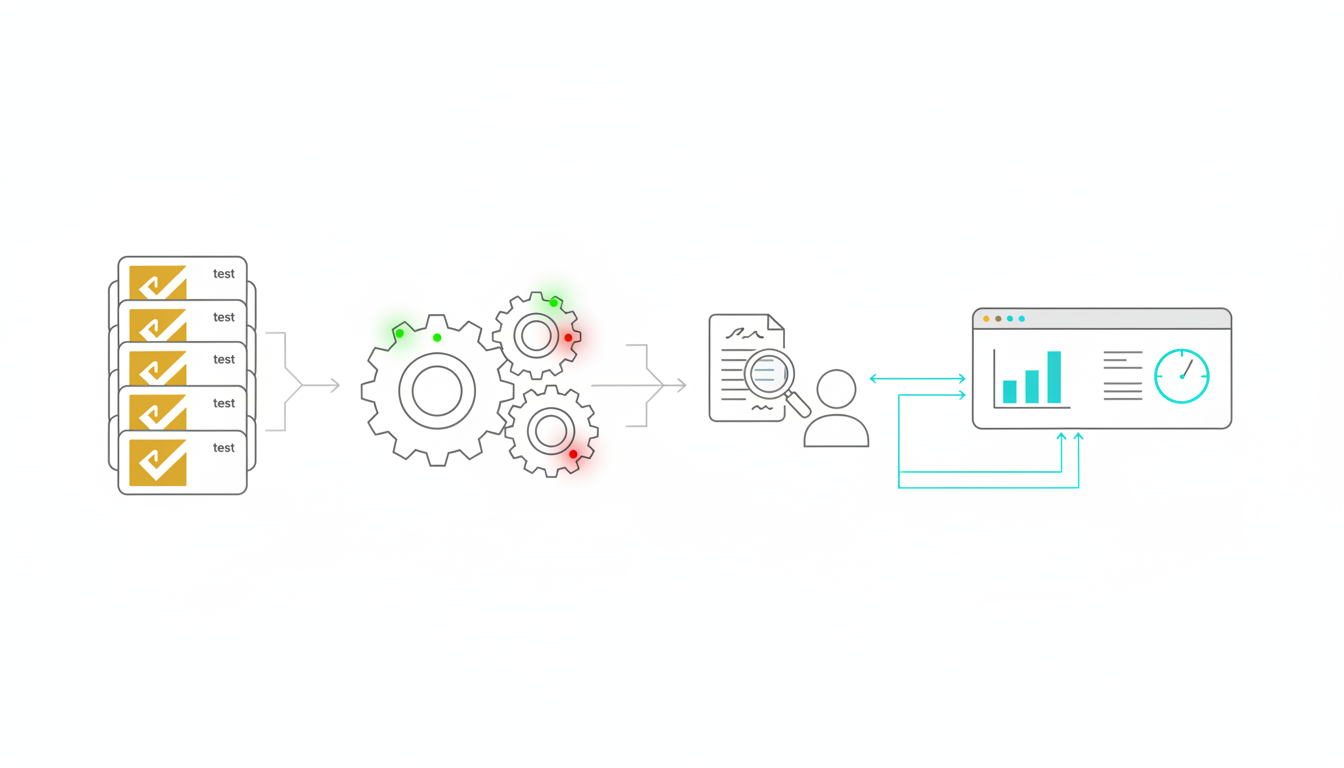
Real work isn’t linear. You need to interrupt, redirect, adjust detail levels, and target questions to specific models. Conversation control features turn chat interfaces into professional tools.
Stop, Interrupt, and Message Queuing
When a model heads in the wrong direction, you need to stop it without losing progress. Interrupt capabilities let you halt generation, adjust instructions, and resume. Message queuing lets you stack requests and process them in order without waiting for each response.
Control features that matter:
- Stop generation mid-response when output quality drops
- Queue multiple queries to different models simultaneously
- Adjust response length and detail level on the fly
- Branch conversations to explore alternatives without losing the main thread
- Merge branches when alternative paths converge on the same conclusion
Response Detail Controls
Different questions need different depths. When validating a calculation, you want full working. When checking a definition, a brief answer suffices. Detail controls let you specify verbosity without rephrasing prompts.
Levels to implement:
- Brief – direct answer with minimal explanation
- Standard – answer with key reasoning steps
- Detailed – comprehensive explanation with examples
- Expert – full technical depth with citations and caveats
Role Targeting in Specialized Teams
When you build a specialized AI team, different models take different roles – analyst, critic, domain expert, editor. Targeting lets you direct questions to specific team members rather than broadcasting to all models.
Use targeted queries to:
- Ask the financial analyst to verify calculations
- Request the legal expert to check citation format
- Have the critic review argument structure
- Direct the editor to improve clarity without changing substance
Implementation: Building an Evaluation-First Workflow
Theory means nothing without execution. Here’s a step-by-step approach to implement evaluation-driven AI workflows in high-stakes contexts.
Step 1: Define Task and Success Criteria
Start with a specific task and concrete success metrics. “Analyze this investment” is too vague. “Produce a 3-page memo covering market size, competitive position, team quality, and key risks, with verified financial data and at least 5 primary sources” gives you something to measure.
Document:
- Exact deliverable format and structure
- Required information elements
- Quality thresholds for accuracy, completeness, and clarity
- Source requirements and citation standards
- Review and approval process
Step 2: Select Models and Orchestration Mode
Choose models based on task requirements. Financial analysis might use models strong in numerical reasoning. Legal research needs strong citation capabilities. Complex strategic questions benefit from debate mode to surface multiple perspectives.
Selection criteria:
- Domain expertise and training data coverage
- Context window size for long documents
- Citation and source linking capabilities
- Cost and latency constraints
- Orchestration mode that matches task structure
Step 3: Build Evaluation Rubrics and Golden Sets
Create rubrics that operationalize your success criteria. Build golden test sets with known-correct outputs. Start small – 10-20 examples that cover common cases and edge cases. Expand as you learn which failure modes matter most.
Rubric components:
- Weighted criteria matching your quality dimensions
- Pass/fail thresholds for each criterion
- Measurement methods (automated checks, human review, hybrid)
- Reviewer guidance for subjective criteria
- Escalation rules for borderline cases
Step 4: Run Orchestration and Capture Outputs
Execute your orchestration mode and collect all outputs – individual model responses, synthesis, and metadata. Log prompts, model versions, timestamps, and any errors or warnings. This creates the audit trail you’ll need later.
Capture:
- Raw outputs from each model in the ensemble
- Orchestration mode and configuration used
- Consensus points and disagreements
- Confidence scores and uncertainty flags
- Source documents and retrieval results
Step 5: Score Against Rubrics and Flag Issues
Run automated checks first – citation verification, consistency analysis, coverage checks. Score outputs against your rubric. Flag items that fail thresholds or show high disagreement across models. Route flagged items to human review.
Automated checks to implement:
- Citation validity against source databases
- Numerical accuracy for calculations and data points
- Completeness checks against required elements
- Contradiction detection within and across outputs
- Format compliance with templates and standards
Step 6: Human Review and Consolidation
Human reviewers focus on what automation can’t catch – strategic insight, argument strength, tone, and edge cases. They also resolve disagreements between models and make final calls on borderline quality issues.
Review workflow:
- Reviewer sees automated scores and flagged issues
- Reviews flagged sections in context
- Validates or overrides automated scores
- Consolidates multi-model outputs into final deliverable
- Documents decisions and reasoning for audit trail
Step 7: Verify Citations and Sources
Never ship without verifying every citation. Check that sources exist, are correctly attributed, and actually support the claims made. This step catches hallucinated references and misattributions.
Verification process:
- Extract all citations from final output
- Verify each source exists and is accessible
- Check that quoted text matches source exactly
- Confirm claims are supported by cited sources
- Flag missing citations for required claims
Role-Based Implementation Examples
Abstract workflows mean little without concrete examples. Here’s how evaluation-first orchestration applies to specific professional contexts.
Investment Analysis Cross-Check
An investment analyst needs to validate a target company’s market size claims and growth projections. Single-model analysis might miss contradictory data or fail to surface downside scenarios.
Orchestration approach:
- Load company materials, market reports, and competitive data into context
- Run fusion mode with three models analyzing different aspects – market sizing methodology, growth assumptions, competitive dynamics
- Use debate mode to pit bull and bear cases against each other
- Capture consensus on facts and disagreement on projections
- Verify all market size data against primary sources
- Produce memo with confidence levels and alternative scenarios
Evaluation rubric focuses on data accuracy, assumption transparency, scenario coverage, and source quality. Golden set includes past analyses with known outcomes.
Case Law Citation Audit
A legal researcher needs to verify that a brief’s citations are valid, correctly applied, and support the arguments made. Citation hallucinations can destroy credibility.
Orchestration approach:
- Extract all citations from the brief
- Use specialized legal models to verify case existence and holdings
- Check that quoted language matches source exactly
- Validate that cases support the propositions cited for
- Flag any citations that don’t verify
- Cross-check against opposing precedents
Automated checks handle citation format and case existence. Human review validates legal reasoning and precedent application. The Knowledge Graph tracks relationships between cases, statutes, and arguments.
Product Strategy Counter-Argument Matrix
A product strategist needs to test a go-to-market plan against objections and alternative approaches. Confirmation bias in single-model analysis can miss critical flaws.
Orchestration approach:
- Present strategy document to multiple models in red team mode
- Each model attacks from a different angle – market timing, competitive response, resource constraints, technical feasibility
- Capture all objections and counter-arguments
- Use fusion mode to synthesize a strengthened strategy
- Document assumptions and risks explicitly
- Create decision matrix with weighted criteria
Evaluation focuses on objection coverage, assumption testing, and risk mitigation completeness. The output includes both the refined strategy and a record of challenges considered.
Prompts That Travel: Reusable Instruction Patterns
Effective prompts combine clear instructions, relevant context, format specifications, and examples. These patterns work across models and tasks with minimal modification.
Watch this video about what is generative ai:
Instruction Structure
Start with role definition, then task, then constraints and format. This structure helps models understand context and expectations.
Template:
- Role: “You are a financial analyst reviewing market sizing claims.”
- Task: “Verify the total addressable market calculation in the attached document.”
- Constraints: “Check all data sources. Flag any assumptions. Identify gaps.”
- Format: “Provide: 1) Data verification results, 2) Assumption list, 3) Confidence score, 4) Missing information.”
Few-Shot Examples
Include 2-3 examples of good outputs that match your rubric. This calibrates models to your quality standards and format preferences.
Example structure:
- Input case with typical characteristics
- Expected output that would score highly on your rubric
- Brief explanation of why this output is good
- Second example covering a different case type
Chain-of-Thought Prompting
Request explicit reasoning steps before conclusions. This improves accuracy on complex tasks and makes outputs auditable.
Prompt addition: “Before providing your final answer, show your reasoning step-by-step. Explain your logic, cite sources for factual claims, and note any assumptions you’re making.”
Governance Quick-Start Guide
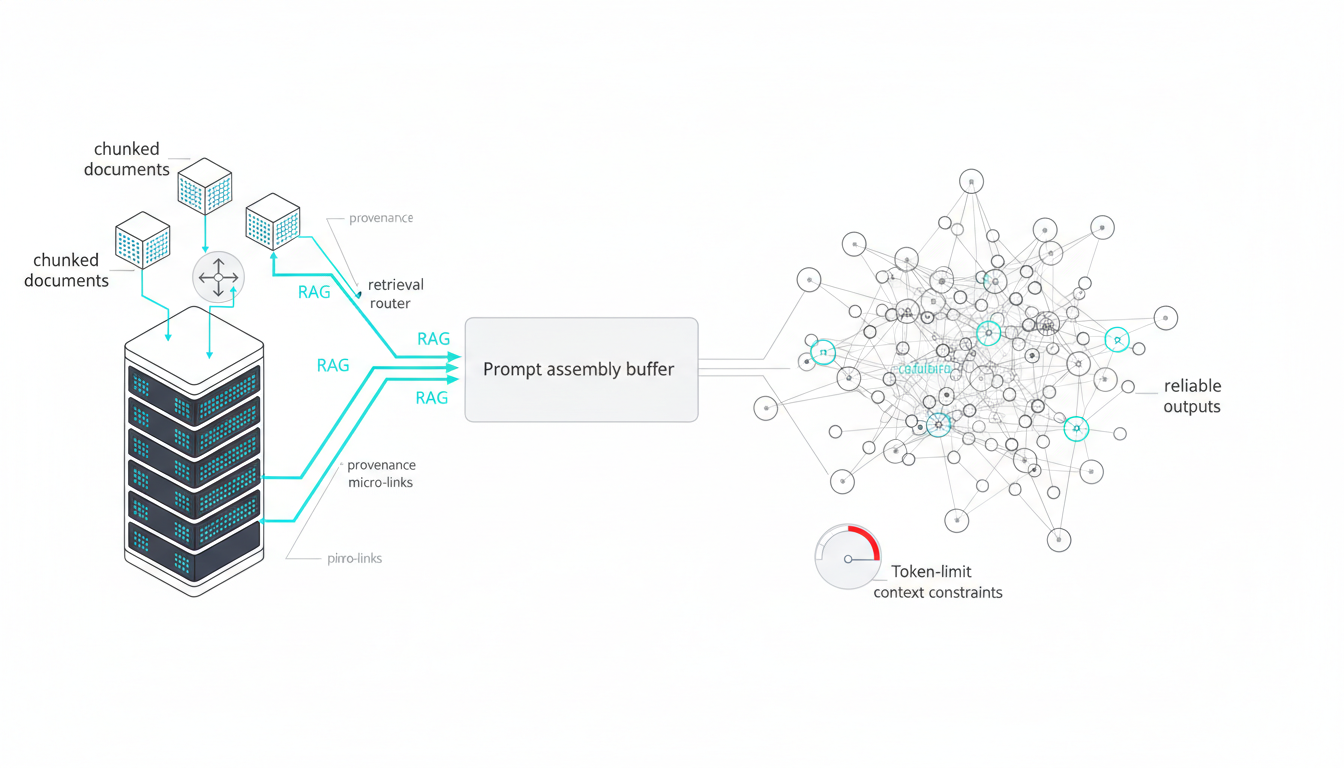
You don’t need a 50-page policy document to start. Begin with essential controls and expand as usage scales.
Week 1: Essential Policies
Define acceptable use, prohibited use cases, and approval requirements. Document who can access which models and for what purposes.
Minimum viable policy:
- Approved use cases and models
- Prohibited inputs (PII, trade secrets, privileged information)
- Required human review for high-stakes outputs
- Incident reporting process
- Data retention and deletion rules
Week 2: Logging and Monitoring
Implement basic logging for all queries and outputs. Track usage by user, model, and task type. Set up alerts for unusual patterns or policy violations.
Logging requirements:
- Timestamp, user, model, and query text
- Full output and any edits made
- Evaluation scores and human review decisions
- Errors, warnings, and guardrail triggers
- Cost and latency metrics
Week 3: Evaluation and Feedback
Deploy rubrics and golden test sets. Start collecting feedback on output quality. Track which tasks and models perform well and which need improvement.
Metrics to track:
- Rubric scores by task type and model
- Human override rate and reasons
- Citation accuracy and hallucination frequency
- Time saved vs. manual completion
- User satisfaction and adoption rate
Week 4: Incident Response
Create a simple incident response plan. Define what constitutes an incident, who investigates, and how you prevent recurrence.
Incident categories:
- Data leakage or PII exposure
- Harmful or policy-violating outputs
- Systematic quality failures
- Security or access control breaches
- Regulatory compliance issues
Mapping to NIST AI RMF
The NIST framework organizes AI risk management into four functions. Map your controls to these functions to demonstrate systematic risk management.
| NIST Function | Your Implementation | Evidence |
|---|---|---|
| Govern | Acceptable use policy, approval workflows | Policy documents, access logs |
| Map | Task inventory, risk assessment by use case | Risk register, task classification |
| Measure | Evaluation rubrics, quality metrics, incident tracking | Dashboards, test results, logs |
| Manage | Guardrails, human review, incident response | Control documentation, response records |
Key Performance Indicators for AI Workflows
Track metrics that matter for your business outcomes. Generic AI metrics miss the point – measure impact on decisions and work quality.
Quality Metrics
These measure whether outputs meet your standards and support good decisions.
- Accuracy uplift: Improvement in factual correctness vs. baseline
- Citation validity rate: Percentage of citations that verify correctly
- Completeness score: Coverage of required information elements
- Consistency rate: Agreement across multi-model runs
- Human override frequency: How often reviewers reject or heavily edit outputs
Efficiency Metrics
These measure whether AI actually saves time and effort.
- Time to first draft: Speed to usable initial output
- Revision cycles: Number of edits needed before final version
- Research velocity: Documents analyzed per hour
- Cost per analysis: Total spend divided by deliverables produced
Confidence Metrics
These measure how much you can trust outputs without extensive verification.
- Model agreement rate: Consensus frequency in multi-LLM runs
- Disagreement resolution time: Effort to resolve conflicting outputs
- Downstream error rate: Mistakes that make it to stakeholders
- Audit success rate: Percentage of outputs that survive scrutiny
Governance Metrics
These demonstrate that you’re managing AI responsibly.
- Policy compliance rate
- Incident frequency and severity
- Time to incident resolution
- Audit trail completeness
- Training completion for users
Glossary of Core Terms
Precise definitions prevent miscommunication and help you evaluate vendor claims accurately.
Transformers
Neural network architecture using attention mechanisms to process sequential data. Transformers can weigh the importance of different input elements regardless of position, enabling them to handle long-range dependencies in text. The foundation of modern large language models.
Diffusion Models
Generative models that create images by learning to reverse a gradual noising process. Starting from random noise, they iteratively denoise toward a target distribution learned from training data. Used in DALL-E, Stable Diffusion, and similar image generators.
RLHF (Reinforcement Learning from Human Feedback)
Training technique that aligns model outputs with human preferences. Human raters compare multiple model responses to the same prompt, creating a reward signal that guides the model toward more helpful, accurate, or safe outputs. Reduces harmful content but can introduce rater biases.
Retrieval Augmented Generation
Pattern that retrieves relevant documents from a knowledge base and includes them in prompts to ground model outputs. Extends model knowledge beyond training data and enables citation of sources. Quality depends on retrieval accuracy and document chunking strategy.
Model Hallucinations
Confidently stated false information generated by language models. Occurs because models optimize for plausible text, not truth. Includes invented citations, fabricated statistics, and misattributed claims. Mitigated through verification, multi-model validation, and retrieval grounding.
Evaluation Metrics
Quantitative measures of model output quality. Task-specific and should align with business requirements. Examples: citation accuracy, completeness score, logical consistency, factual correctness. Enable systematic comparison and improvement tracking.
Guardrails
Controls that prevent harmful or policy-violating outputs. Include input validation, output filtering, PII detection, and content safety checks. Essential for production deployments where outputs reach users or inform decisions.
Model Ensemble
Running multiple models on the same task and combining their outputs. Reduces single-model bias, surfaces disagreements, and improves reliability. Orchestration modes determine how outputs combine – sequential, parallel fusion, debate, or adversarial testing.
Vector Databases
Databases optimized for storing and searching high-dimensional embeddings. Enable semantic search where queries find conceptually similar documents rather than exact keyword matches. Critical infrastructure for retrieval augmented generation.
Knowledge Graphs
Structured representations of entities and their relationships. Enable explicit reasoning about connections, support multi-hop queries, and provide provenance tracking. Complement vector search by adding structured knowledge to semantic retrieval.
Frequently Asked Questions
How do I know when outputs are accurate enough to use?
Define task-specific accuracy thresholds before you start. Use golden test sets to calibrate what “good enough” means for your context. Require human verification for high-stakes claims. Track downstream errors to validate that your thresholds work in practice. When models disagree significantly, that signals uncertainty that needs human judgment.
What’s the cost difference between single-model and multi-model approaches?
Multi-model orchestration costs more per query but often reduces total cost per decision. You pay for multiple API calls but save on revision cycles, error correction, and risk from bad outputs. Start by measuring cost per final deliverable, not cost per API call. For high-stakes work, the insurance value of validation often justifies the expense.
How do I prevent models from leaking sensitive information?
Use input filtering to block PII and confidential data before it reaches models. Deploy on-premise or in private cloud environments for sensitive work. Implement output scanning to catch inadvertent disclosures. Log all queries for audit. Review vendor data retention and training policies. For highly sensitive contexts, consider fine-tuned models on controlled data rather than general-purpose APIs.
Can I trust citations that models provide?
Never trust citations without verification. Models frequently hallucinate sources or misattribute claims. Implement automated citation checking against trusted databases. Require human review of all citations before publishing. Use retrieval augmented generation to ground outputs in verified documents. Track citation accuracy as a key quality metric.
How long does it take to set up evaluation workflows?
Start with a simple rubric and 10 golden examples in a few hours. Expand iteratively as you learn which quality dimensions matter most. Automated checks take longer to build but pay off quickly. Budget a week for initial setup, then continuous refinement based on failure patterns you discover. The goal is progress, not perfection.
What happens when models disagree on important conclusions?
Disagreement is valuable information about uncertainty. Capture the reasoning from each perspective. Identify what evidence would resolve the disagreement. Route to human experts for final judgment. Document the decision and rationale. Over time, patterns in disagreements reveal which tasks need better prompts, more context, or different models.
Moving from Demos to Dependable Workflows
Generative AI delivers real value when you treat it as a tool that needs verification, not magic that works unsupervised. Single models are fast but fragile. Multi-model orchestration with evaluation frameworks converts speed into reliability.
The key principles:
- Define quality standards before generating content
- Use multiple models to surface bias and disagreement
- Verify citations and factual claims systematically
- Maintain audit trails for all decisions
- Track metrics that matter for your outcomes
You now have the mental models to understand how generative AI works, where it fails, and how orchestration patterns reduce risk. The evaluation templates and governance frameworks give you starting points for implementation. The role-specific examples show what this looks like in practice.
The difference between experimental AI and production workflows is systematic evaluation and governance. Start with one high-value task, build rubrics that operationalize quality, and expand as you learn what works. To explore how orchestration features work in practice, see how the patterns described here map to specific platform capabilities. For a deeper tour of orchestration approaches, visit the orchestration modes overview, and for workflow controls see Conversation Control.





