For leaders who cannot afford guesswork, the fastest path to choosing the right AI is a reproducible evaluation. Knowing how to run AI-based evaluations across multiple LLMs at once proves ROI and reduces risk.
Testing models one by one creates inconsistent context and biased prompts. This sequential approach leads to unrepeatable results. High-stakes decisions require simultaneous runs, objective scoring, and auditable citations.
This guide walks you through a step-by-step workflow. You will learn to score outputs, fact-check claims, and document a decision-grade report. We base this on multi-AI orchestration best practices using a 5-Model AI Boardroom.
The Foundations of Multi-LLM Evaluation
Running a proper evaluation means moving beyond casual chatting. You must frame the task clearly and establish firm datasets.
- Task framing: Define exactly what the model must solve.
- Gold-standard datasets: Provide known good examples for baseline comparison.
- Scoring rubrics: Measure outcomes against strict business requirements.
Sequential testing introduces severe variance and context drift. Evaluating models side by side creates true comparability. It removes the risk of prompt leakage and inconsistent grounding.
Choosing the right models matters just as much as your prompts. You must decide between generalist models and specialist models for your exact tasks.
Step-by-Step Multi-LLM Evaluation Workflow
A structured process turns subjective opinions into objective data. Follow these steps to build a reliable testing system.
- Define your goals: Set clear targets for quality, speed, cost, and compliance.
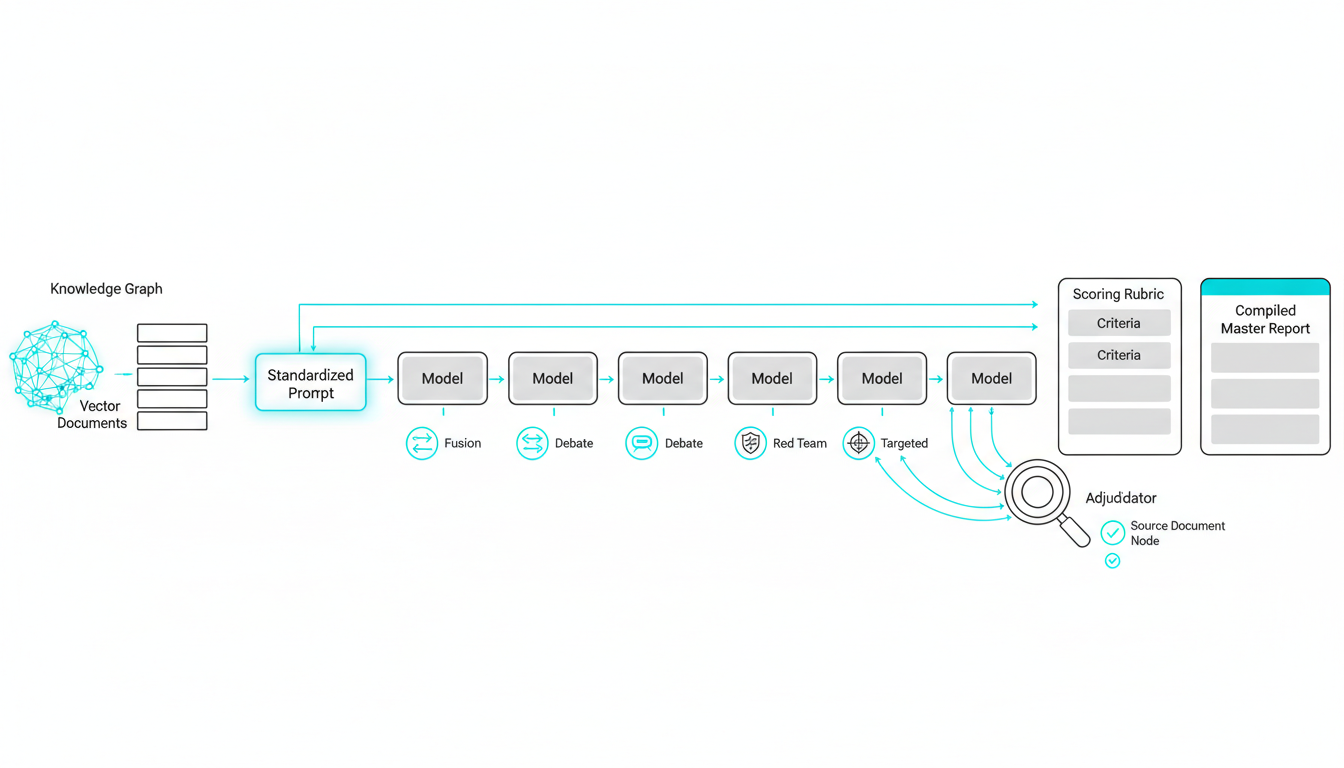
- Assemble your dataset: Configure grounding via a Knowledge Graph or Vector File Database.
- Standardize prompts: Create clear prompt variants and register your seeds for reproducibility.
- Select your orchestration mode: Choose between Sequential, Fusion, Debate, Red Team, or Targeted modes.
- Run simultaneous evaluations: Queue messages across 5 models and capture outputs.
- Score the outputs: Apply a rubric for clarity, factuality, style, and compliance.
- Adjudicate claims: Fact-check citations and mitigate hallucinations.
- Compare trade-offs: Weigh quality against cost and time to recommend an ensemble.
- Export findings: Generate a Master Document with your final metrics and next steps.
Managing this process manually takes too much time. You can use a Multi-AI Orchestrator for Professionals to automate these steps. This platform allows you to run simultaneous tests in a single interface.
Validating claims is a critical part of this workflow. You need Adjudicator fact-checking to reduce AI hallucinations during your scoring phase.
Templates and Checklists for Immediate Execution
You need the right tools to execute your testing system. Standardized templates keep your team aligned and your data clean.
- Evaluation rubric: A downloadable spreadsheet with criteria, weights, and pass/fail thresholds.
- Prompt pack: Standardized role instructions with built-in safety checks.
- Mode selection matrix: A guide showing when to use different testing modes.
- Update runbook: A checklist for re-testing after models release new versions.
- Cost dashboard: A tracking sheet for per-run budgeting and time analysis.
Your documentation must survive scrutiny from leadership. Using a Scribe Living Document for reproducible logs guarantees your results remain auditable. You can also implement Context Fabric for consistent, grounded runs across all sessions.
Real-World Application: Product Marketing Evaluation
A product marketing team needed to compare three models for positioning statements. They required highly exact outcomes for their upcoming campaign launch.
Watch this video about How to run AI-based evaluations across multiple LLMs at once:
- Factual accuracy: The team needed verifiable claims for public materials.
- Brand compliance: The outputs had to match strict tone guidelines.
- Review speed: The process needed to save time for busy reviewers.
The team ran simultaneous tests and applied strict scoring rubrics. They used proven techniques to reduce AI hallucinations during the review phase.
The results transformed their workflow completely. They cut review time by 40 percent while drastically improving factual accuracy. They also deployed Red Team Mode for adversarial evaluation to stress-test their final messaging.
Frequently Asked Questions
How large should my evaluation dataset be?
Start with 50 to 100 high-quality examples. This size provides enough statistical significance without overwhelming your testing budget.
How do I prevent prompt leakage and guarantee fairness?
Run your models simultaneously in isolated environments. Use identical system instructions and apply the exact same grounding documents for every test.
What metrics should I track beyond subjective scoring?
Track cost per run, time to first token, and total generation time. You should also measure citation accuracy and format compliance.
How often should I re-run these multi-LLM tests?
Test your prompts again whenever a provider announces a major version update. You should also schedule quarterly reviews to catch silent model degradation.
When is an ensemble better than a single model?
Ensembles excel at complex tasks requiring multiple perspectives. Use them when accuracy and risk mitigation outweigh the need for low latency.
Transform AI Selection Into Evidence-Based Decisions
You now have a repeatable system that replaces guesswork with hard data. Following this workflow helps your organization choose the right tools for high-stakes tasks.
- Run standardized tasks across multiple models simultaneously.
- Score outputs with a predefined rubric and validate claims.
- Ground your tests with persistent context to reduce hallucinations.
- Track quality metrics alongside cost and time to inform business decisions.
- Publish a decision-grade report with fully reproducible logs.
See how a 5-Model AI Boardroom simplifies this orchestration while preserving rigorous standards. Start a free trial to run your first multi-LLM evaluation today.





