
When outcomes carry risk-legal exposure, investment loss, or reputational damage-‘good enough’ AI isn’t good enough. A single model might draft a compelling brief, but can it catch the counterargument that unravels your case? Can it identify the data point that changes your investment thesis?
Single-model agents can be fast but fragile. They hallucinate citations, miss edge cases, and fail to justify decisions with the rigor your work demands. Without validation mechanisms and safety guardrails, autonomy amplifies small errors into costly outcomes.
The solution lies in multi-LLM orchestration-architecting systems where multiple AI models plan, execute, and cross-examine their own work with human-in-the-loop checkpoints. This guide distills practitioner patterns from professional use cases where reliability and auditability matter.
What Makes an AI Agent Autonomous
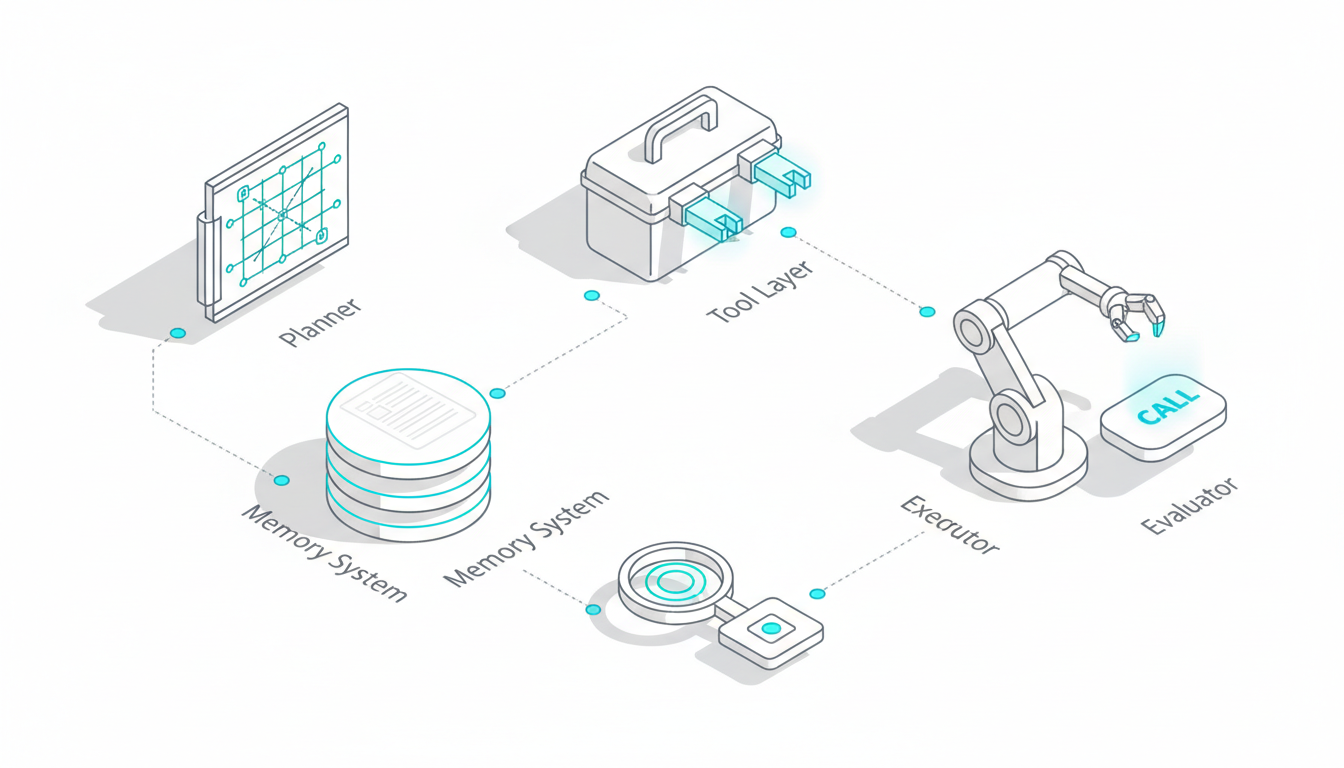
An autonomous AI agent goes beyond responding to prompts. It breaks down complex tasks, selects appropriate tools, maintains context across multiple steps, and evaluates its own outputs before presenting results.
The core components that enable this autonomy include:
- Planner: Decomposes high-level goals into executable subtasks
- Tool Layer: Connects to APIs, databases, and document repositories
- Memory System: Maintains short-term scratchpad and long-term context
- Executor: Carries out planned actions and tool calls
- Evaluator: Critiques outputs and triggers refinement loops
Control Loops That Drive Agent Behavior
Agents operate through control loops that determine how they process information and make decisions. The ReAct pattern (Reasoning and Acting) alternates between thinking and doing- the model reasons about what to do next, executes an action, observes the result, and repeats.
More sophisticated patterns add verification steps. Chain-of-thought with verification generates intermediate reasoning steps and checks them before proceeding. Reflection loops prompt the model to critique its own outputs and identify improvements.
Self-consistency approaches generate multiple solution paths and select the most common answer. This reduces random errors but doesn’t address systematic bias-all paths might share the same blind spots.
The Autonomy Spectrum
Not all agents operate at the same level of independence. The spectrum ranges from:
- Tool-augmented assistance: Model suggests actions; human approves each step
- Task-level autonomy: Agent completes defined tasks with periodic checkpoints
- Workflow-level orchestration: Agent manages multi-step processes with final human review
High-stakes work typically requires task-level autonomy with frequent validation points. Full workflow autonomy remains rare outside narrow, well-defined domains.
Why Single-Model Agents Fall Short
A single large language model, no matter how capable, brings inherent limitations. It encodes the biases present in its training data. It generates plausible-sounding text that may not be factually accurate. It lacks mechanisms to challenge its own assumptions.
Common failure modes include:
- Hallucinated citations: Inventing case law, research papers, or data sources
- Confirmation bias: Finding evidence that supports initial conclusions while ignoring contradictions
- Tool misuse: Calling APIs incorrectly or misinterpreting results
- Context drift: Losing track of earlier decisions in long reasoning chains
- Reward hacking: Optimizing for surface-level metrics rather than true task completion
When a legal professional relies on a single model for case research, they risk building arguments on fabricated precedents. When an investment analyst uses one AI for due diligence, they miss the red flags a different model would catch.
Multi-LLM Orchestration: Architecture for Reliability
Multi-LLM orchestration addresses single-model limitations by coordinating multiple AI models with different strengths and training backgrounds. Instead of trusting one model’s judgment, you create a system where models challenge each other, aggregate diverse perspectives, and surface disagreements that warrant human attention.
The 5-Model AI Boardroom demonstrates this approach in practice. By running multiple models simultaneously on the same task, you get comprehensive analysis that reduces blind spots and catches errors before they become problems.
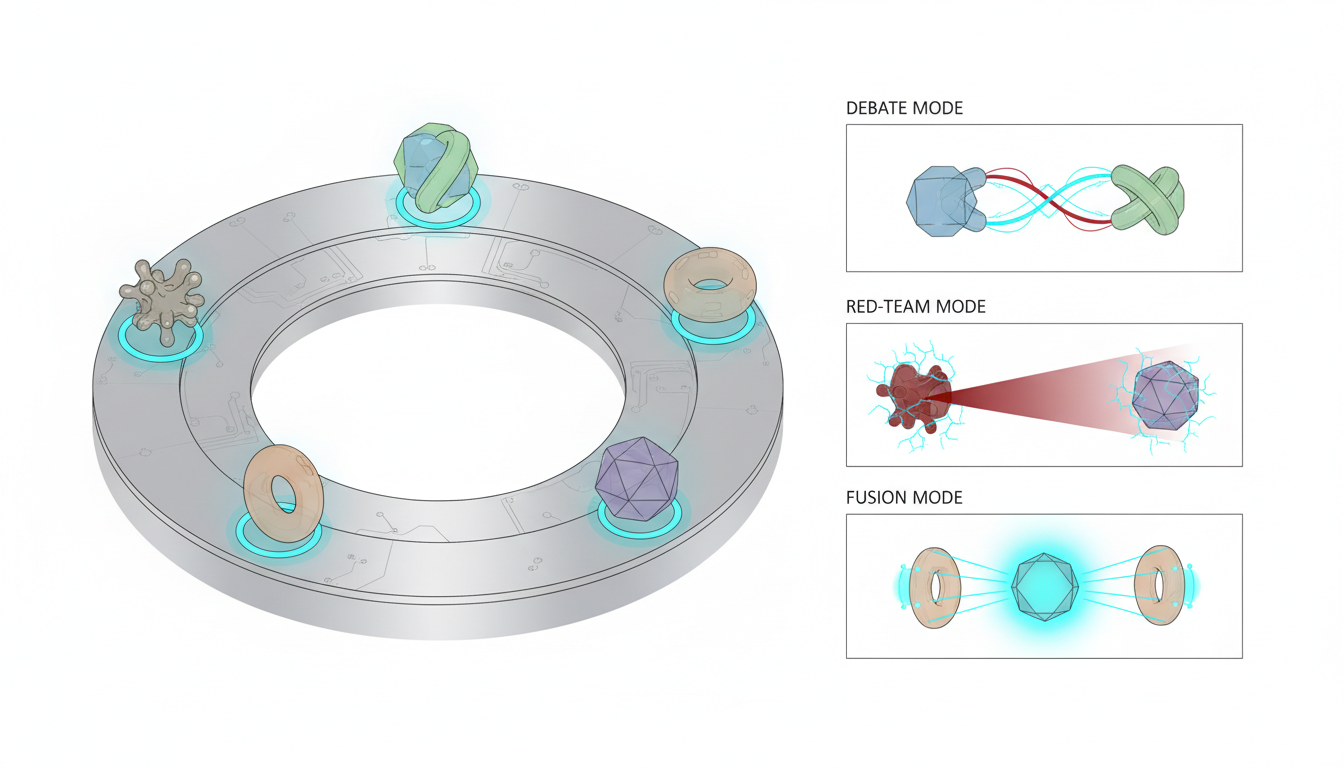
Debate and Red Team Modes
In debate mode, two or more models take opposing positions on a question. One model argues for a conclusion while another challenges it. This adversarial process surfaces assumptions, identifies weak evidence, and forces more rigorous reasoning.
A legal team analyzing a contract might use debate mode to test different interpretations of ambiguous clauses. One model advocates for the client’s preferred reading while another acts as opposing counsel. The resulting analysis reveals vulnerabilities before they emerge in negotiation.
Red team mode takes this further by assigning one or more models to actively attack a proposed solution. If you’re evaluating an investment thesis, the red team looks for downside scenarios, contradictory data, and flawed assumptions. This reveals risks that a single supportive analysis would miss.
Fusion and Ensemble Approaches
Fusion mode aggregates outputs from multiple models running in parallel. Each model brings different capabilities-one excels at mathematical reasoning, another at language understanding, a third at creative problem-solving.
The system collects all responses and applies aggregation rules:
- Majority voting for classification tasks
- Weighted averaging based on model confidence scores
- Expert routing that assigns subtasks to specialized models
- Evaluator models that judge quality and select the best response
When models disagree significantly, the system flags the discrepancy for human review. This catches cases where the task is genuinely ambiguous or where models are operating near the edge of their capabilities.
Sequential Research Workflows
Complex research tasks benefit from sequential orchestration. The first model formulates search queries and retrieves relevant documents. The second extracts key claims and evidence. The third checks for contradictions and missing information. The fourth synthesizes findings into a coherent summary.
This staged approach maintains focus at each step. The retrieval specialist doesn’t get distracted by synthesis. The contradiction checker doesn’t skip documents because it’s eager to write the summary. Context Fabric preserves information across stages, so later models have access to earlier reasoning and sources.
Targeted Expertise Assignment
Different models have different strengths. Some excel at code generation. Others handle medical terminology better. Still others are optimized for mathematical reasoning or multilingual tasks.
Targeted mode lets you assign specific subtasks to appropriate models. When analyzing a complex document, you might route technical sections to a model trained on scientific literature, legal language to a model with strong reasoning capabilities, and financial tables to a model optimized for numerical analysis.
This specialization improves accuracy while controlling costs. You use expensive, capable models only where they add value, routing simpler tasks to faster, cheaper alternatives.
Building Reliable Agent Systems
Deploying autonomous AI agents in professional settings requires careful planning and systematic evaluation. You need to define acceptable risk levels, establish validation mechanisms, and create runbooks for handling failures.
Watch this video about autonomous ai agents:
Design Phase: Defining Stakes and Metrics
Start by mapping the decision stakes. What happens if the agent gets it wrong? A research summary with minor errors might cost time to correct. A legal brief with fabricated citations could result in sanctions or malpractice claims.
Define evaluation metrics that match these stakes:
- Accuracy: Percentage of correct outputs on validation sets
- Completeness: Coverage of relevant information and edge cases
- Traceability: Can you verify every claim to a source document?
- Latency: Time from query to validated result
- Cost: Tokens consumed per successful task completion
High-stakes applications prioritize accuracy and traceability over speed. Lower-stakes workflows can trade some precision for faster results.
Tool Integration and API Connections
Agents need access to your knowledge base, document repositories, and specialized tools. This requires careful integration work:
- Document stores with proper indexing and search capabilities
- Vector databases for semantic retrieval
- API connectors to internal systems and external data sources
- Permission systems that enforce access controls
- Rate limiting and error handling for external services
Start with read-only access to reduce risk. Agents can retrieve and analyze information without modifying critical systems. Add write capabilities only after thorough testing and with appropriate approval workflows.
Memory Strategy: Balancing Context and Cost
Agents need memory to maintain coherence across multi-step tasks. Short-term memory acts as a scratchpad for the current task-storing intermediate results, tool outputs, and reasoning steps.
Long-term memory persists information across sessions. This includes user preferences, domain knowledge, and patterns learned from previous interactions. Context Fabric maintains this persistent context without requiring you to manually track conversation history.
The challenge is managing context window limits. Each model has a maximum token capacity. As conversations grow longer, you need strategies to prioritize relevant information:
- Summarize older conversation segments while preserving key decisions
- Extract and store structured information (entities, relationships, conclusions)
- Retrieve relevant context dynamically based on current task
- Prune low-value information while maintaining audit trails
Safety Guardrails and Human Oversight
Autonomous doesn’t mean unsupervised. Professional workflows require multiple layers of safety controls.
Human-in-the-loop checkpoints pause execution at critical decision points. Before the agent files a document, sends a communication, or commits a transaction, a human reviews and approves. This catches errors before they cause real-world consequences.
Guardrail prompts constrain agent behavior. Instructions like “never generate legal advice without citing sources” or “flag any recommendation that exceeds the approved budget” create boundaries that reduce risk.
Policy filters screen outputs for prohibited content-personally identifiable information, confidential data, offensive language, or compliance violations. These filters run automatically before results reach users.
Conversation Control provides additional safety mechanisms. You can stop or interrupt agent execution if it’s heading in the wrong direction. Response depth controls limit how far the agent can explore without human input. Message queuing lets you review and approve actions before they execute.
Evaluation Framework: Measuring What Matters
Reliable agents require systematic evaluation. You need both intrinsic measures (how well does the agent perform specific capabilities?) and extrinsic measures (does it actually help users accomplish their goals?).
Intrinsic Evaluation Methods
Test individual components in isolation:
- Factuality checks: Verify claims against ground truth databases
- Citation traceability: Confirm every reference links to an actual source
- Tool use accuracy: Check that API calls use correct parameters and interpret results properly
- Reasoning coherence: Ensure logical consistency across multi-step chains
Create unit tests for common scenarios. If the agent should retrieve case law, test it on known cases. If it should calculate financial ratios, verify the math against spreadsheet results.
Extrinsic Evaluation: Task Success Metrics
Measure performance on real user tasks:
- Task completion rate: Percentage of queries that produce usable results
- Decision confidence delta: How much more confident are users after agent analysis?
- Review time saved: Hours reduced compared to manual research
- Error detection rate: How often does the agent catch mistakes humans would miss?
Track these metrics across different orchestration modes. Does debate mode improve accuracy for legal analysis? Does fusion mode reduce errors in financial modeling? Use data to refine your approach.
Cost-Latency Tradeoffs
More thorough analysis costs more and takes longer. You need to balance quality against practical constraints.
Calculate tokens per correct decision as your efficiency metric. If debate mode uses 3x more tokens but catches 5x more errors, it’s worth the cost for high-stakes work. If fusion mode uses 2x tokens but only improves accuracy by 10%, single-model might suffice for routine tasks.
Set concurrency budgets that match your infrastructure. Running five models simultaneously requires more compute than sequential execution. For urgent queries, parallel processing delivers faster results. For batch analysis, sequential processing conserves resources.
Domain-Specific Implementation Patterns
Different professional domains have distinct requirements and workflows. Here are proven patterns for three high-stakes use cases.
Legal Research and Analysis
Legal professionals need reliable citations, comprehensive argument coverage, and systematic consideration of counterarguments. A typical legal analysis workflow includes:
- Brief triage: Classify the legal question and identify relevant practice areas
- Argument mapping: Extract claims, supporting evidence, and logical structure
- Case law retrieval: Search for relevant precedents and statutory authority
- Counterargument generation: Use red team mode to challenge each claim
- Citation verification: Confirm every case reference exists and supports the stated proposition
Key performance indicators include:
- Percentage of verified citations (target: 100%)
- Argument diversity score (number of distinct legal theories explored)
- Time from query to draft brief (target: 60-80% reduction vs. manual research)
Use debate mode for contested interpretations. When a contract clause could support multiple readings, have models argue each position. The resulting analysis prepares you for opposing counsel’s arguments.
Investment Analysis and Due Diligence
Investment decisions require comprehensive risk assessment and systematic evaluation of downside scenarios. A robust due diligence process includes:
- Thesis framing: Articulate the investment hypothesis and key assumptions
- Data gathering: Retrieve financial statements, market data, and competitive intelligence
- Risk mapping: Identify operational, market, regulatory, and execution risks
- Red-team challenge: Attack the thesis with contradictory evidence and alternative scenarios
- Scenario analysis: Model outcomes under different market conditions
Track these metrics:
- Downside scenarios covered (target: identify 10+ material risks)
- Source quality scores (percentage of claims backed by primary sources)
- Memo completeness (coverage of standard due diligence checklist items)
Red team mode excels here. Assign one model to advocate for the investment while another actively looks for reasons to pass. The resulting tension surfaces risks that a single supportive analysis would miss.
Research Literature Synthesis
Academic and technical research requires systematic literature review, claim extraction, and contradiction identification. An effective research workflow includes:
- Query expansion: Generate related search terms and concepts
- Literature retrieval: Find relevant papers, reports, and datasets
- Claim extraction: Identify key findings and supporting evidence from each source
- Contradiction hunting: Use debate mode to find conflicting results across papers
- Synthesis summary: Aggregate findings while noting areas of disagreement
Measure research quality through:
Watch this video about ai agents:
- Contradiction detection rate (how often does the system flag conflicting claims?)
- Reference coverage (percentage of relevant literature identified)
- Summary faithfulness (do synthesis statements accurately represent source papers?)
Sequential research mode works well for this workflow. Each stage focuses on a specific task-retrieval, extraction, verification, synthesis-without getting distracted by downstream concerns. Knowledge Graph maps relationships between concepts, authors, and findings, making it easier to identify patterns and gaps.
Operational Runbooks and Failure Recovery
Even well-designed systems encounter problems. You need documented procedures for handling common failures and edge cases.
Common Failure Modes and Responses
When agents produce unexpected results, follow this diagnostic process:
- Hallucination detected: Stop execution, flag the output, review prompt engineering and retrieval quality
- Tool call failure: Check API connectivity, verify parameters, implement retry logic with exponential backoff
- Context overflow: Summarize older segments, extract key decisions to structured storage, restart with compressed context
- Model disagreement: Escalate to human review, document the conflict, gather additional information to resolve
- Performance degradation: Monitor token costs and latency, scale compute resources, optimize prompts for efficiency
Logging and Observability
Maintain detailed audit trails that capture:
- Input queries and user context
- All tool calls and API interactions
- Intermediate reasoning steps and model outputs
- Sources consulted and citations generated
- Final results and human approval decisions
This logging enables retrospective analysis. When users report problems, you can replay the exact sequence of steps and identify where things went wrong. Over time, these logs become training data for improving prompts and refining orchestration logic.
Version Control and Rollback Procedures
Treat agent configurations as code. Store prompts, orchestration rules, and tool definitions in version control. When you make changes, deploy to a staging environment first. Run regression tests against known good examples.
If a new configuration causes problems in production, roll back to the previous stable version immediately. Investigate the issue in staging before attempting another deployment.
Getting Started: Pilot to Production
Don’t try to automate everything at once. Start with a narrow, high-value workflow where you can measure results clearly.
Pilot Selection Criteria
Choose an initial use case that is:
- High-frequency: Performed often enough to generate meaningful data quickly
- Well-defined: Clear success criteria and evaluation metrics
- Moderate-stakes: Important enough to matter, not so critical that failures cause major problems
- Representative: Similar to other workflows you’ll automate later
A legal team might start with initial case assessment rather than trial preparation. An investment firm might pilot with preliminary screening before full due diligence. A research group might automate literature search before synthesis.
Pre-Launch Checklist
Before going live, verify:
- Red-team scenarios tested: Attempted to break the system with adversarial inputs
- Cost budgets established: Set token limits and cost alerts
- Latency targets defined: Know acceptable response times for your use case
- Bias audits completed: Tested for systematic errors across demographics or edge cases
- Rollback procedures documented: Team knows how to disable the system if needed
- User training delivered: People understand how to interpret agent outputs and when to override
Scaling from Pilot to Production
After a successful pilot, expand gradually. Add related workflows one at a time. Monitor quality metrics at each stage. Collect user feedback and iterate on prompts and orchestration logic.
As you scale, invest in infrastructure:
- Automated testing pipelines that catch regressions
- Monitoring dashboards that surface performance trends
- User feedback mechanisms that capture edge cases
- Documentation that helps new team members understand the system
Build a library of reusable components. When you solve prompt engineering challenges or create effective tool integrations, package them for use across multiple workflows. This accelerates future development and maintains consistency.
Frequently Asked Questions
How do I know when to use multiple models instead of one?
Use multi-model orchestration when decision stakes are high and errors are costly. Legal analysis, investment decisions, medical research, and compliance reviews benefit from multiple perspectives. Routine queries, content drafting, and low-stakes summarization often work fine with a single model.
What’s the cost difference between single-model and multi-model approaches?
Multi-model orchestration typically costs 2-5x more in tokens, depending on the mode. Debate and red team modes use the most tokens because models generate multiple rounds of argument. Fusion mode costs less because models run in parallel without extended back-and-forth. Calculate cost per correct decision rather than cost per query-higher token usage is worthwhile if it prevents expensive errors.
Can I mix different model providers in one orchestration?
Yes, and this often improves results. Different providers have different training data, architectures, and strengths. Combining models from multiple sources reduces the risk of shared blind spots. You might use one provider’s model for reasoning tasks, another’s for code generation, and a third for multilingual work.
How do I handle disagreements between models?
Disagreements are valuable signals. When models reach different conclusions, it usually means the task is genuinely ambiguous or requires domain expertise. Flag these cases for human review rather than forcing a consensus. Document the disagreement and the reasoning behind each position. Over time, you’ll identify patterns that help refine your orchestration logic.
What’s the minimum team size needed to deploy these systems?
A single technical professional can pilot agent workflows using existing platforms. Scaling to production typically requires 2-3 people: someone who understands the domain (legal, investment, research), someone who handles technical integration, and someone who manages prompts and orchestration logic. Larger deployments add specialists for security, compliance, and user training.
How long does it take to see ROI from agent deployment?
Pilots typically show measurable time savings within 2-4 weeks. Full ROI depends on workflow complexity and adoption rates. Teams that start with narrow, high-frequency tasks often achieve positive ROI within 2-3 months. More complex implementations take 6-12 months to optimize and scale.
Building Reliable AI Systems
Autonomous agents represent a shift from AI as a tool to AI as a collaborator. Done right, they elevate expert decision-making by surfacing insights, challenging assumptions, and handling routine analysis. Done wrong, they amplify errors and create new risks.
The key differentiators are:
- Rigorous control loops that verify outputs before presenting results
- Multi-model orchestration that reduces single-model blind spots
- Systematic evaluation with clear metrics and audit trails
- Human oversight at critical decision points
- Operational discipline with runbooks, monitoring, and rollback procedures
Start with a narrow workflow where you can measure results clearly. Use specialized AI teams to match models to tasks. Implement safety guardrails from day one. Scale gradually as you build confidence in the system’s reliability.
With the right architecture and evaluation practices, agents become force multipliers for high-stakes knowledge work. They don’t replace human judgment-they make it more informed, more thorough, and more defensible.





