Executives don’t buy AI – they buy better decisions. The fastest AI transformations formalize how decisions are made, validated, and scaled. When you treat AI as a decision system rather than a tool roll-out, you create repeatable outcomes that stakeholders can trust.
Most programs stall in pilot purgatory. Scattered tools, one-off prompts, and no governance make results non-repeatable or risky. Stakeholders lose confidence when accuracy and auditability aren’t measurable. Teams run dozens of proofs of concept, but nothing moves to production because no one defined what “good enough” looks like.
A decision-centric operating model changes this dynamic. Multi-LLM orchestration and validation gates move teams from demos to dependable outcomes. You establish clear quality thresholds, document reasoning paths, and build audit trails that satisfy compliance teams. This approach draws on hands-on transformations across legal, investment, and research workflows, incorporating NIST AI RMF principles and multi-model practices proven to reduce bias and variance.
What AI Transformation Actually Means
AI transformation encompasses strategy, data readiness, model selection, governance, and change management. It’s not about deploying chatbots. You’re redesigning how knowledge work happens, automating judgment where appropriate, and augmenting human expertise where machines fall short.
Single-model approaches carry hidden risks. One model’s biases become your organization’s biases. One model’s blind spots become your blind spots. Multi-model orchestration mitigates these risks by stress-testing reasoning across different architectures and training sets.
- Reduce bias and variance by comparing outputs from multiple models
- Stress-test reasoning paths before committing to decisions
- Find consensus across different AI approaches and architectures
- Catch edge cases that single models miss
- Build confidence through transparent validation workflows
From Pilots to Production Systems
Moving beyond pilots requires three things: repeatable capabilities, documented artifacts, and clear handoffs between teams. You need evaluation sets that define quality, prompt templates that capture institutional knowledge, and MLOps workflows that handle model updates without breaking production systems.
The gap between demo and deployment is governance. Risk officers need audit trails. Compliance teams need to understand how decisions get made. Legal departments need to know what happens when models fail. Building these controls into your operating model from day one prevents the painful retrofits that kill momentum.
The AI Operating Model Canvas
Your operating model defines roles, decision rights, cadences, and artifacts. Without this structure, AI initiatives fragment across departments. With it, you create a repeatable system for identifying opportunities, validating approaches, and scaling what works.
Core Roles and Responsibilities
Four roles anchor the model. The AI Sponsor owns business outcomes and secures resources. The Product Owner translates business needs into use cases and maintains the backlog. The AI Lead designs validation workflows and manages model selection. The Risk Officer ensures governance, compliance, and audit readiness.
Decision rights matter as much as roles. Who approves new use cases? Who signs off on production deployments? Who decides when to kill a pilot? Clear RACI matrices prevent the endless meetings that slow transformations to a crawl.
- Sponsor approves budget and strategic direction
- Product Owner prioritizes use cases and defines success metrics
- AI Lead selects models and designs validation gates
- Risk Officer reviews governance and audit trails before production
- Cross-functional teams execute with clear escalation paths
Artifacts That Enable Scale
Documented artifacts turn tribal knowledge into institutional assets. Evaluation sets define what good looks like for each use case. Prompt templates capture effective approaches and prevent starting from scratch. Validation rubrics standardize quality checks across teams.
Context persistence separates professional AI systems from consumer chat tools. When you can reference previous analyses, link related decisions, and build on past reasoning, you create compound value. Context management becomes the foundation for knowledge work that scales.
Use Case Prioritization Framework
Not all use cases deliver equal value. An impact-feasibility matrix helps you focus on opportunities that combine business value with technical achievability. Weight each dimension by data readiness and risk exposure to avoid surprises mid-project.
Scoring Methodology
Score impact across three dimensions: revenue potential, cost reduction, and risk mitigation. Score feasibility based on data availability, technical complexity, and stakeholder alignment. Multiply the scores, then apply risk and data readiness weights to get a final priority ranking.
- Rate business impact on a 1-10 scale (revenue, cost, risk)
- Rate technical feasibility on a 1-10 scale (data, complexity, alignment)
- Multiply impact by feasibility to get base score
- Apply data readiness multiplier (0.5 for poor, 1.0 for good, 1.5 for excellent)
- Apply risk weight (0.7 for high-risk, 1.0 for medium, 1.3 for low-risk)
This scoring approach surfaces quick wins while flagging projects that need data preparation or risk controls before launch. You avoid the trap of chasing high-impact use cases that lack the data foundation to succeed.
Example Prioritization
An investment firm might score these use cases: due diligence memo validation (impact 8, feasibility 7, excellent data, medium risk = 78.4), portfolio screening (impact 9, feasibility 5, poor data, high risk = 15.75), and meeting summary generation (impact 4, feasibility 9, good data, low risk = 46.8). The numbers reveal that due diligence delivers the best risk-adjusted return, while portfolio screening needs data work before it’s viable.
For teams working on investment analysis workflows, this framework prevents over-investing in use cases that sound impressive but lack the supporting infrastructure to deliver reliable results.
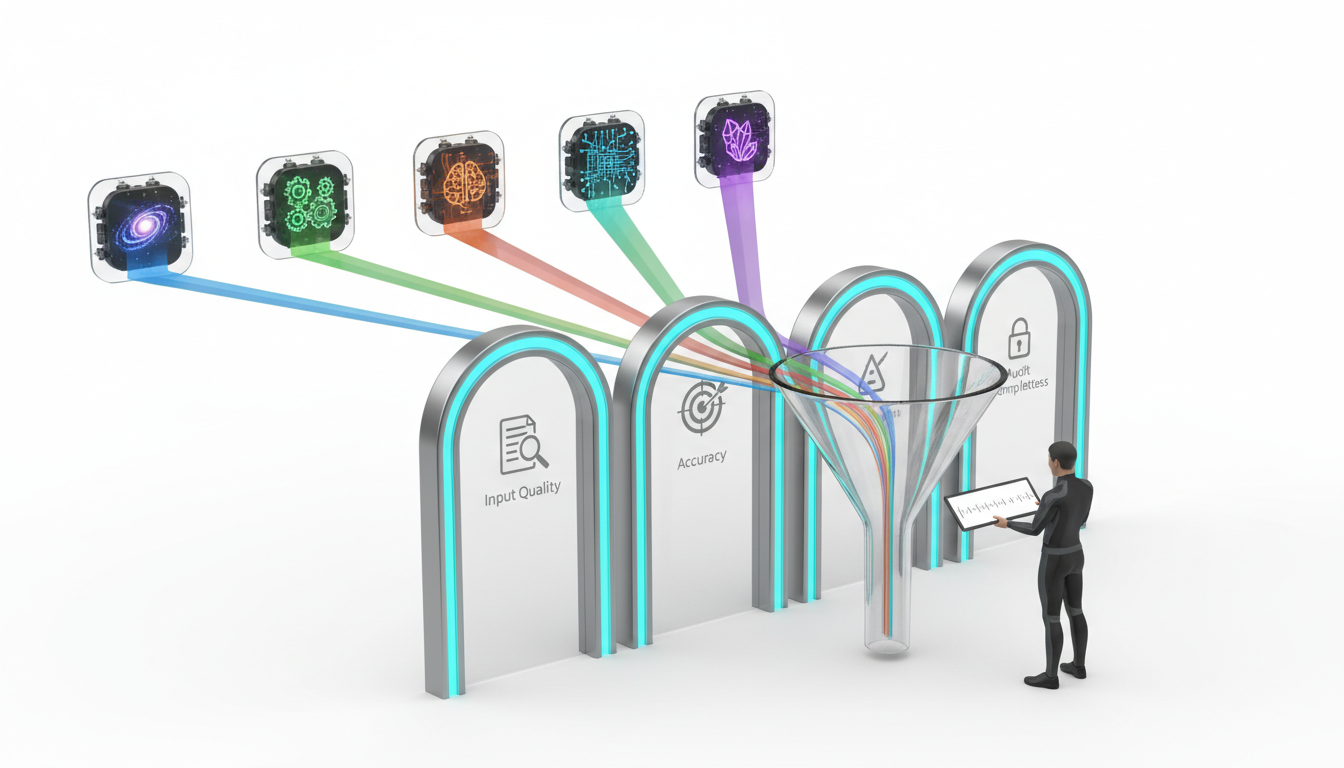
Decision Validation Gates
Validation gates transform AI from black box to trusted system. Each gate checks a different aspect of decision quality: input validity, reasoning soundness, output accuracy, and audit completeness. You define pass/fail criteria for each gate based on the stakes of the decision.
Input Quality Checks
Garbage in, garbage out remains true for AI systems. Input validation confirms that prompts contain necessary context, reference relevant documents, and specify output requirements clearly. You catch malformed requests before they waste compute resources or produce misleading results.
- Verify all required context is present and accessible
- Confirm source documents are current and authoritative
- Check that prompts specify format, length, and quality criteria
- Validate that constraints and guardrails are properly defined
- Ensure evaluation criteria are measurable and objective
Multi-Model Validation Workflows
Single models hallucinate, miss nuances, and carry biases. Multi-LLM orchestration reveals these issues by comparing reasoning paths across different architectures. When five models agree, confidence increases. When they disagree, you investigate before committing to action.
Different orchestration modes serve different validation needs. Debate mode surfaces conflicting interpretations. Fusion mode synthesizes complementary insights. Red Team mode stress-tests conclusions by attacking assumptions. Research Symphony mode coordinates specialized analysis across complex domains.
For legal research workflows, multi-model debate catches precedents that single models miss and reveals conflicting interpretations of case law before they become courtroom surprises.
Human-in-the-Loop Signoff
AI assists decisions but doesn’t make them. Human signoff gates ensure subject matter experts review outputs, validate reasoning, and take accountability for outcomes. You document who approved what, when, and based on which evidence.
The signoff process varies by risk level. Low-stakes decisions might need single-reviewer approval. High-stakes decisions require multi-level review with documented dissents. Critical decisions trigger executive sign-off with full audit trails.
Governance-by-Design Approach

Governance isn’t a phase that comes after deployment. You design it into workflows from the start. This approach aligns with NIST AI Risk Management Framework principles: map risks, measure controls, manage incidents, and govern throughout the lifecycle.
Model Risk Management
Model risk management borrows from financial services practices. You document model limitations, validate performance on holdout sets, monitor for drift, and maintain incident response procedures. When models fail, you know why and how to fix them.
- Document assumptions, limitations, and known failure modes
- Establish performance baselines and acceptable variance thresholds
- Monitor prediction accuracy and reasoning quality over time
- Define escalation triggers for drift or degraded performance
- Maintain model cards and technical documentation
Audit Trail Requirements
Regulators and auditors need to reconstruct decisions. Your audit trail captures inputs, model versions, reasoning paths, human reviews, and final outputs. You can answer “why did the system recommend this?” six months after the fact.
Audit trails serve internal purposes too. When decisions go wrong, you need to understand what happened. When decisions go right, you want to replicate the approach. Complete documentation enables both learning and accountability.
Privacy and Security Controls
AI systems process sensitive data. Your governance framework addresses data classification, access controls, encryption standards, and retention policies. You know what data goes where and who can access it.
Different use cases demand different controls. Financial analysis might require strict data residency. Legal work needs attorney-client privilege protections. Healthcare applications trigger HIPAA compliance. Your operating model accommodates these variations without creating governance chaos.
Data and Context Layer
AI quality depends on context quality. The data and context layer manages how information flows into AI systems, persists across conversations, and connects to institutional knowledge. Without this layer, every interaction starts from zero.
Context Persistence Strategy
Professional knowledge work builds on prior analyses. Context persistence lets you reference previous conversations, link related decisions, and evolve thinking over time. You avoid re-explaining background information and focus on new insights.
Persistent context requires deliberate architecture. You need to store conversation history, tag key decisions, link related threads, and surface relevant context automatically. The context management system becomes infrastructure that all use cases depend on.
Knowledge Graph Integration
Relationships matter as much as facts. Knowledge graphs map connections between entities, concepts, and decisions. When you ask about portfolio companies, the system surfaces related investments, key personnel, and relevant market trends automatically.
Building knowledge graphs takes time but pays compound returns. Each new connection makes the system smarter. Each tagged relationship improves future queries. Over months, you create an institutional memory that captures how your organization thinks.
Teams can explore how relationship mapping enhances decision quality by surfacing non-obvious connections and ensuring consistent reasoning across related analyses.
Watch this video about ai transformation:
Prompt Templates as Versioned Assets
Effective prompts capture institutional expertise. Treating them as versioned assets means tracking what works, documenting improvements, and preventing regression. You build a library of proven approaches rather than reinventing prompts for each use case.
Version control enables A/B testing and performance tracking. When you update a prompt template, you compare results against the baseline. If quality improves, you promote the change. If it degrades, you roll back. This discipline prevents the prompt drift that undermines consistency.
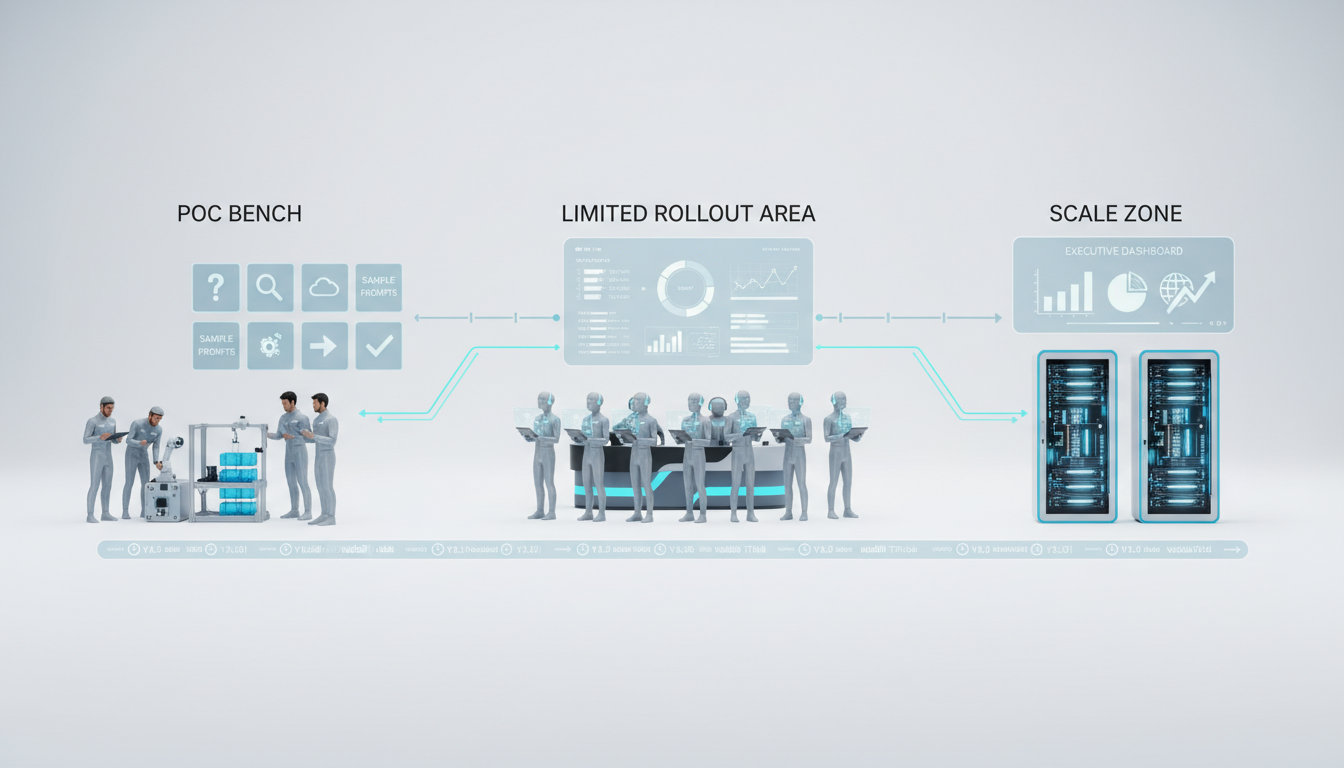
Pilot-to-Production Pathway
The journey from proof of concept to production system follows three stages: PoC, limited rollout, and scale. Each stage has entry criteria, success metrics, and kill/scale decision rules. You avoid the pilot purgatory trap by defining what success looks like before you start.
Proof of Concept Phase
PoC validates technical feasibility and business value. You select a narrow use case, define success criteria, build evaluation sets, and run controlled tests. The goal is learning, not perfection. You want to understand what works, what breaks, and what resources you need to scale.
- Define specific use case with clear boundaries and constraints
- Build evaluation set with 20-50 representative examples
- Establish baseline performance metrics and target improvements
- Run validation tests with multiple models and orchestration modes
- Document findings, failure modes, and resource requirements
Kill rules prevent throwing good money after bad. If accuracy falls below thresholds, if data quality blocks progress, or if stakeholder engagement collapses, you stop. Failed pilots teach valuable lessons when you document what went wrong and why.
Limited Rollout Stage
Limited rollout expands to 10-20 users while you refine workflows and build operational muscle. You establish support processes, monitor performance closely, and iterate based on user feedback. The focus shifts from “does it work?” to “can we support it?”
This stage reveals operational gaps that pilots miss. You discover that users need training. Documentation needs work. Edge cases require special handling. Integration with existing systems creates friction. Addressing these issues before full deployment prevents the chaos that kills adoption.
Scale and Optimize
Production deployment means the system handles real work without constant intervention. You’ve automated monitoring, established SLAs, trained support teams, and integrated with enterprise systems. Users trust the system because it delivers consistent quality.
Scaling isn’t just technical. You need change management that helps users adopt new workflows, communication that builds confidence, and metrics that demonstrate value. Executive dashboards show business impact. User feedback loops drive continuous improvement. Incident response procedures handle failures gracefully.
Operating Rhythms and Governance Cadences
Sustainable AI operations require regular rhythms. Weekly model reviews catch performance drift early. Monthly governance check-ins ensure compliance. Quarterly roadmap updates align AI investments with business priorities.
Weekly Model Performance Reviews
Weekly reviews examine accuracy metrics, user feedback, and failure patterns. You identify degrading performance before it impacts decisions. The AI Lead presents findings, the Risk Officer flags compliance issues, and the Product Owner prioritizes fixes.
- Review accuracy metrics and compare against baseline thresholds
- Analyze user feedback and support tickets for patterns
- Examine failure cases and root cause analysis
- Update evaluation sets with new edge cases
- Prioritize model updates and prompt refinements
Incident Postmortems
When things go wrong, postmortems document what happened, why it happened, and how to prevent recurrence. You create a learning culture where failures improve the system rather than triggering blame cycles.
Effective postmortems follow a structured format: timeline of events, root cause analysis, contributing factors, immediate fixes, and long-term preventive measures. You share findings across teams so everyone learns from incidents.
Evaluation Set Maintenance
Evaluation sets decay over time. New edge cases emerge. Business requirements evolve. User expectations shift. Quarterly evaluation set reviews keep quality standards current and prevent the drift that undermines trust.
You add examples that models failed on, remove outdated scenarios, and adjust scoring rubrics to reflect new priorities. This maintenance work ensures that your quality gates remain relevant as the business changes.
90-Day Acceleration Plan
The first 90 days establish your foundation. You stand up governance, select priority use cases, build evaluation sets, and deploy your first validation workflow. The goal is momentum, not perfection. You want early wins that build confidence and reveal what needs work.
Days 1-30: Foundation and Governance
Month one focuses on structure. You formalize the operating model, assign roles, establish decision rights, and create the governance framework. The AI Sponsor secures resources. The Risk Officer drafts policies. The AI Lead evaluates platform options.
- Finalize operating model canvas with roles and RACI matrix
- Draft governance policies aligned to NIST AI RMF
- Select and configure AI orchestration platform
- Establish audit trail and documentation standards
- Create communication plan for stakeholder engagement
Days 31-60: Use Case Selection and Validation Design
Month two identifies quick wins. You score use cases using the prioritization framework, select the top three, and design validation workflows for each. The Product Owner builds evaluation sets. The AI Lead configures orchestration modes.
This phase requires close collaboration with business users. You need their expertise to define what good looks like, identify edge cases, and establish realistic quality thresholds. Their buy-in determines whether pilots succeed or stall.
Days 61-90: Pilot Deployment and Learning
Month three runs controlled pilots. You deploy validation workflows, monitor performance closely, gather user feedback, and iterate rapidly. The focus is learning what works in your specific context with your specific data and users.
By day 90, you have concrete results. You know which use cases deliver value, which need more work, and which should be killed. You’ve validated your governance approach, refined your workflows, and built credibility with stakeholders. You’re ready to scale.
12-Month Scale Roadmap
The 12-month roadmap expands from three pilot use cases to 10-15 production deployments. You formalize the AI center of excellence, integrate telemetry systems, and automate evaluation pipelines. The operating model shifts from startup mode to sustainable operations.
Quarters 2-3: Expand and Standardize
You roll out successful pilots to broader user groups while adding new use cases. Standardization becomes critical. You document best practices, create reusable components, and establish templates that accelerate new deployments.
- Scale three successful pilots to full production
- Launch 4-6 new use cases based on prioritization framework
- Formalize AI center of excellence with dedicated resources
- Implement automated monitoring and alerting systems
- Build prompt template library and evaluation set repository
Quarter 4: Optimize and Institutionalize
By quarter four, AI becomes part of how work gets done. You’ve integrated with enterprise systems, automated routine operations, and built self-service capabilities that let business users deploy new use cases with minimal IT support.
Institutionalization means governance becomes routine, not heroic. Risk reviews happen on schedule. Model updates follow standard procedures. Incident response works smoothly. You’ve created sustainable operations that don’t depend on a few key people.
Role-Specific Implementation Examples
Abstract frameworks need concrete examples. Here’s how different roles apply the operating model to real work.
Investment Research: Due Diligence Validation
An investment team uses multi-model debate to validate due diligence memos. Five models analyze the same target company, each focusing on different risk factors. Debate mode surfaces conflicting interpretations of financial data, market positioning, and management quality.
The validation workflow includes input checks (confirm data completeness), multi-model analysis (run debate mode on key investment theses), red team review (stress-test assumptions with adversarial prompts), and analyst signoff (human expert reviews and approves). The audit trail documents which models flagged which risks and how the analyst resolved disagreements.
Teams working on due diligence processes can adapt this workflow to their specific investment criteria and risk frameworks.
Legal Research: Precedent Synthesis
A legal team uses research symphony mode to synthesize case law across multiple jurisdictions. Each model specializes in a different jurisdiction or legal domain. The orchestration system coordinates their analysis and identifies precedents that individual models miss.
Validation gates include source verification (confirm cases are properly cited and current), cross-jurisdiction analysis (identify conflicts between jurisdictions), reasoning quality checks (verify legal logic is sound), and attorney review (licensed professional signs off on conclusions).
Product Marketing: Narrative Testing
A marketing team uses fusion mode to test product narratives across customer segments. Multiple models analyze messaging effectiveness, each representing a different customer persona. Fusion mode synthesizes insights into unified recommendations.
The workflow includes audience definition (specify target segments and pain points), multi-persona analysis (run fusion across segment models), A/B testing design (create variants based on model recommendations), and campaign lead approval (marketing director signs off on final messaging).
KPIs and Performance Dashboards
You can’t manage what you don’t measure. AI transformation dashboards track accuracy, variance, cycle time, rework rate, compliance exceptions, and ROI. Metrics drive improvement and demonstrate value to stakeholders.
Core Performance Metrics
Accuracy measures how often AI outputs meet quality standards. You track this per use case and per model. Declining accuracy triggers investigation and remediation.
- Accuracy rate: percentage of outputs that pass validation gates
- Variance: consistency of outputs across multiple runs
- Cycle time: end-to-end duration from request to approved output
- Rework rate: percentage of outputs requiring human correction
- Compliance exceptions: incidents requiring risk officer review
Business Impact Metrics
Technical metrics matter, but executives care about business outcomes. You track time saved, cost avoided, revenue enabled, and risk reduced. These metrics connect AI investments to bottom-line results.
ROI calculations need to account for total cost of ownership: platform costs, integration work, training, support, and ongoing maintenance. You compare these costs against quantified benefits: labor hours saved, error reduction, faster time-to-market, and improved decision quality.
Dashboard Design Principles
Effective dashboards serve different audiences. Executives need high-level trends and business impact. Operational teams need detailed performance data and alert notifications. Risk officers need compliance metrics and incident reports.
You design role-specific views that surface relevant information without overwhelming users. Color coding highlights issues requiring attention. Trend lines show whether performance is improving or degrading. Drill-down capabilities let users investigate anomalies.
Watch this video about AI transformation roadmap:
Tools and Templates
Practical implementation requires concrete tools. These templates accelerate your transformation by providing starting points you can customize to your context.
Use Case Scoring Sheet
The scoring sheet captures impact ratings (revenue, cost, risk), feasibility ratings (data, complexity, alignment), risk weights, and data readiness multipliers. You calculate priority scores and rank use cases objectively.
Customize the weights based on your organization’s priorities. A cost-conscious firm might weight cost reduction higher. A risk-averse firm might apply stricter risk penalties. The framework adapts to your strategic context.
Validation Rubric Template
The validation rubric defines pass/fail criteria for each quality dimension. You specify what constitutes acceptable accuracy, completeness, relevance, and reasoning quality. Scoring becomes consistent across reviewers and use cases.
Each rubric includes examples of excellent, acceptable, and unacceptable outputs. These examples calibrate reviewers and reduce subjective interpretation. You update examples as you encounter new edge cases.
Risk Heatmap
The risk heatmap visualizes probability and impact for different failure modes. You identify which risks need mitigation, which need monitoring, and which you can accept. The visual format makes risk discussions concrete and actionable.
Update the heatmap quarterly as you learn more about actual failure modes and their consequences. Some risks that seemed severe prove manageable. Others that seemed minor reveal hidden impacts. The heatmap evolves with your experience.
Building Your Specialized AI Team
Different challenges require different expertise. Your AI team composition should match the problem you’re solving. Financial analysis needs models strong in quantitative reasoning. Legal work needs models trained on case law. Creative work needs models that generate novel ideas.
The process of assembling specialized teams involves understanding model strengths, defining team roles, and selecting orchestration modes that leverage complementary capabilities.
Team composition isn’t static. You adjust based on the task, the data, and the quality requirements. High-stakes decisions might use five models with debate mode. Routine analysis might use two models with fusion mode. You match resources to requirements.
Common Implementation Challenges
Even well-designed transformations hit obstacles. Anticipating common challenges helps you navigate them successfully.
Data Quality and Readiness
Poor data quality undermines AI performance. Missing fields, inconsistent formats, and outdated information produce unreliable outputs. You need data cleanup, standardization, and governance before AI delivers value.
Address data issues early. Include data readiness in your use case scoring. Build data quality checks into validation gates. Invest in data platforms that make clean data accessible. The AI work can’t succeed if the data foundation is weak.
Change Management Resistance
People resist changes that threaten their expertise or job security. Address fears directly. Show how AI augments rather than replaces human judgment. Involve users in design decisions. Celebrate early wins that demonstrate value.
Training matters more than you expect. Users need hands-on practice with new workflows. They need time to build confidence. They need support when things go wrong. Skimping on change management dooms technically sound implementations.
Governance Overhead
Governance can become bureaucracy that slows everything down. Balance control with agility. Automate compliance checks where possible. Create fast-track approvals for low-risk use cases. Reserve heavyweight governance for high-stakes decisions.
The goal is governance that enables rather than blocks. Risk officers should help teams move faster by clarifying requirements and streamlining approvals. When governance becomes a bottleneck, you lose momentum and credibility.
Measuring Success and Iterating
AI transformation is a journey, not a destination. You measure progress, learn from results, and adjust your approach. Success looks different at different stages.
Early Success Indicators
In the first 90 days, success means establishing foundations and learning quickly. You want stakeholder engagement, clear governance, validated use cases, and early wins that build confidence.
- Operating model documented and roles assigned
- Governance framework approved and communicated
- Three use cases selected and prioritized with data
- Validation workflows designed and tested
- First pilot deployed with measurable results
Mid-Term Success Indicators
By month six, success means scaling what works and killing what doesn’t. You have multiple use cases in production, standardized processes, and demonstrated business value. Users adopt AI tools without constant hand-holding.
Long-Term Success Indicators
After 12 months, success means sustainable operations and continuous improvement. AI is integrated into how work gets done. Governance runs smoothly. New use cases deploy faster. The organization treats AI as infrastructure, not a special project.
You’ve built institutional capabilities that outlast individual champions. Documentation captures knowledge. Templates accelerate new deployments. The AI center of excellence operates independently. You’ve created lasting organizational change.
Frequently Asked Questions
How long does it take to see ROI from this approach?
Early wins appear within 90 days as pilot use cases demonstrate time savings and quality improvements. Measurable ROI typically emerges at 6-9 months when multiple use cases reach production and you can quantify labor savings, error reduction, and faster cycle times. Full transformation value accrues over 12-18 months as the operating model matures and you scale to 10-15 production use cases.
What makes multi-model orchestration better than using a single AI?
Single models carry individual biases, blind spots, and failure modes. Multi-model orchestration reveals these issues by comparing reasoning across different architectures. When models agree, you gain confidence. When they disagree, you investigate before committing to action. This approach reduces bias, catches errors, and improves decision quality, particularly for high-stakes work where mistakes are costly.
Do we need a dedicated AI team or can existing staff handle this?
Start with a small core team (Sponsor, Product Owner, AI Lead, Risk Officer) and expand as you scale. Existing staff can handle many responsibilities if they have capacity and training. The AI Lead role requires technical expertise in model selection and validation design. The Risk Officer needs governance and compliance background. Other roles can be part-time initially and grow into full-time positions as the program matures.
How do we handle compliance and audit requirements?
Build audit trails into workflows from day one. Capture inputs, model versions, reasoning paths, human reviews, and final outputs for every decision. Align your governance framework with NIST AI RMF principles. Document model limitations and validation procedures. Establish clear signoff requirements for different risk levels. Regular governance reviews ensure compliance standards remain current as regulations evolve.
What if our data isn’t ready for AI?
Data readiness is part of use case scoring. Start with use cases where data is cleanest and most accessible. Use early successes to justify investment in data cleanup and governance. Build data quality checks into validation gates so you catch issues before they impact decisions. Treat data readiness as a parallel workstream that improves over time, not a blocker that prevents starting.
How do we prevent pilot purgatory?
Define kill/scale rules before starting pilots. Establish clear success criteria, timelines, and decision gates. If a pilot doesn’t meet thresholds by the deadline, kill it and document lessons learned. If it succeeds, move immediately to limited rollout with defined expansion criteria. The discipline of making explicit go/no-go decisions prevents the drift that traps programs in endless pilot mode.
Moving Forward With Your Transformation
AI transformation succeeds when you treat it as a decision system with clear validation gates, not a technology deployment. Multi-LLM orchestration reduces bias and increases reliability. Governance built into workflows from day one prevents painful retrofits. Roadmaps tied to measurable KPIs and kill/scale rules keep programs focused on outcomes.
You now have a practical operating model, validation framework, and roadmap to move from pilots to dependable outcomes. The templates and examples provide starting points you can customize to your context. The governance blueprint ensures compliance without sacrificing agility.
Start with the 90-day acceleration plan. Stand up your operating model, select three priority use cases, build evaluation sets, and deploy your first validation workflow. Learn what works in your specific context with your specific data and users. Use those lessons to refine your approach as you scale.
Explore the platform capabilities that enable multi-model decision validation and see how different orchestration approaches fit different use cases. The combination of structured operating models and powerful orchestration tools creates the foundation for sustainable AI transformation that delivers measurable business value.





