Executive Overview
AI hallucinations — instances where models generate false or fabricated information with full confidence — represent one of the most critical yet underappreciated risks in today’s AI-powered business landscape. This report compiles raw statistical data from multiple authoritative benchmarks, industry studies, and real-world incident tracking to serve as a content foundation.
The headline numbers are staggering:
- Global business losses from AI hallucinations reached $67.4 billion in 2024 alone[1][2]
- 47% of business executives have made major decisions based on unverified AI-generated content[3][1]
- Even the best AI models still hallucinate at least 0.7% of the time on basic summarization tasks — and rates skyrocket to 18.7% on legal questions and 15.6% on medical queries[4]
- On difficult knowledge questions, all but three out of 40 tested models are more likely to hallucinate than give a correct answer[5][6]
What Is an AI Hallucination? (Technical Definition + Plain English)
Plain English
An AI hallucination happens when an AI model confidently makes something up. It doesn’t say “I don’t know” — it presents fabricated facts, invented statistics, fake legal cases, or nonexistent medical studies as if they were real. The response sounds authoritative and reads perfectly. That’s what makes it dangerous.[7]
Technical Definition
In technical terms, hallucination refers to generated output that is not grounded in the provided input data or factual reality. There are two primary types:
- Intrinsic hallucination (also called “faithfulness hallucination”): The model contradicts information explicitly provided in its source material. For example, during summarization, it adds facts not present in the original document.[8]
- Extrinsic hallucination (also called “factuality hallucination”): The model generates information that cannot be verified against any known source — it invents facts, citations, statistics, or events from scratch.[9]
A critical technical insight from MIT research (January 2025): when AI models hallucinate, they tend to use more confident language than when providing factual information. Models were 34% more likely to use phrases like “definitely,” “certainly,” and “without doubt” when generating incorrect information.[4]
This is the core paradox: the more wrong the AI is, the more certain it sounds.
Why It Happens
LLMs are fundamentally prediction engines, not knowledge bases. They generate text by predicting the most statistically likely next word based on patterns learned from training data. They do not “understand” truth — they predict plausibility. When the model encounters a gap in its training data or faces an ambiguous query, it fills the gap with plausible-sounding fabrication rather than admitting uncertainty.[1]
Benchmark 1: Vectara Hallucination Leaderboard (HHEM)
What It Measures
The Vectara Hughes Hallucination Evaluation Model (HHEM) Leaderboard is the industry’s most widely referenced hallucination benchmark. It measures grounded hallucination — how often an LLM introduces false information when summarizing a document it was explicitly given. Think of it as: “Can the model stick to what’s written in front of it?”[10][8]
AI hallucination benchmarks (live table) with Vectara Hughes Hallucination Evaluation Model (HHEM) Leaderboard included.
The methodology: 1,000+ documents are given to each model with instructions to summarize using only the facts in the document. Vectara’s HHEM model then checks each summary against the source to identify fabricated claims.[10]
Why It Matters for Business Users
This is directly analogous to how AI is used in RAG (Retrieval Augmented Generation) systems — the backbone of enterprise AI search, customer support bots, and document analysis tools. If a model hallucinates during summarization, it will hallucinate when answering questions from your company’s knowledge base.[10]
Hallucination Rates — Original Dataset (April 2025)
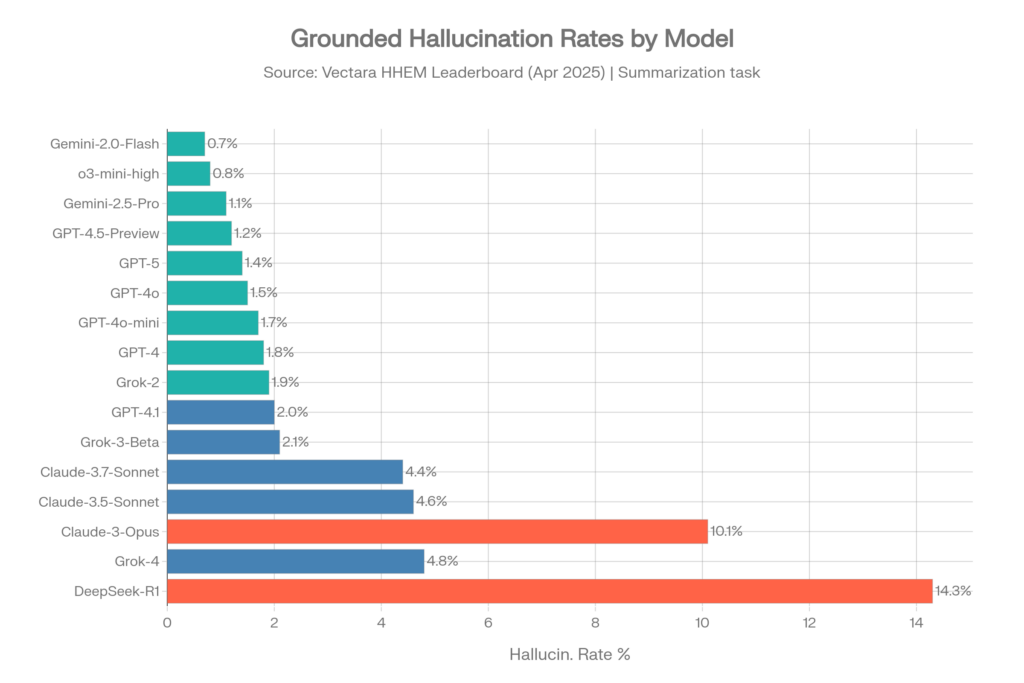
This dataset of ~1,000 documents was the standard benchmark through mid-2025.[10]
| Model | Vendor | Hallucin. Rate | Factual Consistency |
| Gemini-2.0-Flash-001 | 0.7% | 99.3% | |
| Gemini-2.0-Pro-Exp | 0.8% | 99.2% | |
| o3-mini-high | OpenAI | 0.8% | 99.2% |
| Gemini-2.5-Pro-Exp | 1.1% | 98.9% | |
| GPT-4.5-Preview | OpenAI | 1.2% | 98.8% |
| Gemini-2.5-Flash-Preview | 1.3% | 98.7% | |
| o1-mini | OpenAI | 1.4% | 98.6% |
| GPT-5 / ChatGPT-5 | OpenAI | 1.4% | 98.6% |
| GPT-4o | OpenAI | 1.5% | 98.5% |
| GPT-4o-mini | OpenAI | 1.7% | 98.3% |
| GPT-4-Turbo | OpenAI | 1.7% | 98.3% |
| GPT-4 | OpenAI | 1.8% | 98.2% |
| Grok-2 | xAI | 1.9% | 98.1% |
| GPT-4.1 | OpenAI | 2.0% | 98.0% |
| Grok-3-Beta | xAI | 2.1% | 97.8% |
| Claude-3.7-Sonnet | Anthropic | 4.4% | 95.6% |
| Claude-3.5-Sonnet | Anthropic | 4.6% | 95.4% |
| Claude-3.5-Haiku | Anthropic | 4.9% | 95.1% |
| Grok-4 | xAI | 4.8% | ~95.2% |
| Llama-4-Maverick | Meta | 4.6% | 95.4% |
| Claude-3-Opus | Anthropic | 10.1% | 89.9% |
| DeepSeek-R1 | DeepSeek | 14.3% | 85.7% |
Source: Vectara HHEM Leaderboard, GitHub repository, April 2025[10]
Key Takeaways from Vectara (Old Dataset)
- Google Gemini models dominate the top spots, with Gemini-2.0-Flash leading at 0.7%[4]
- OpenAI is consistently strong across the GPT-4 family, ranging from 0.8% to 2.0%[10]
- Grok-4 at 4.8% is notably higher than its GPT and Gemini competitors — nearly 7x the hallucination rate of the best Gemini model[11]
- Claude models show a surprising spread: Claude-3.7-Sonnet at 4.4% is respectable, but Claude-3-Opus at 10.1% is concerningly high[10]
- The o3-mini-high reasoning model from OpenAI achieved 0.8%, showing that reasoning capabilities can actually improve factual grounding[10]
Hallucination Rates — New Dataset (November 2025 – February 2026)
Vectara launched a completely refreshed benchmark in late 2025 with 7,700 articles (up from 1,000), longer documents (up to 32K tokens), and higher complexity content spanning law, medicine, finance, technology, and education.[12]
The results are dramatically higher — by design. This benchmark better reflects real enterprise workloads.[12]
| Model | Vendor | Hallucin. Rate |
| Gemini-2.5-Flash-Lite | 3.3% | |
| Mistral-Large | Mistral | 4.5% |
| DeepSeek-V3.2-Exp | DeepSeek | 5.3% |
| GPT-4.1 | OpenAI | 5.6% |
| Grok-3 | xAI | 5.8% |
| DeepSeek-R1-0528 | DeepSeek | 7.7% |
| Claude Sonnet 4.5 | Anthropic | >10% |
| GPT-5 | OpenAI | >10% |
| Grok-4 | xAI | >10% |
| Gemini-3-Pro | 13.6% |
Source: Vectara Hallucination Leaderboard, new dataset, November 2025[13][12]
The “Reasoning Tax” Discovery
Vectara’s updated leaderboard revealed a critical finding: reasoning/thinking models actually perform worse on grounded summarization. Models like GPT-5, Claude Sonnet 4.5, Grok-4, and Gemini-3-Pro — which are marketed as strong “reasoners” — all exceeded 10% hallucination rates on the harder benchmark.[12][14][15]
The hypothesis: reasoning models invest computational effort into “thinking through” answers, which sometimes leads them to overthink and deviate from source material rather than simply sticking to the provided text. This is a major caveat for enterprise RAG applications.[15]
Benchmark 2: AA-Omniscience (Artificial Analysis)
What It Measures
Released in November 2025, AA-Omniscience is a knowledge and hallucination benchmark covering 6,000 questions across 42 topics within 6 domains: Business, Humanities & Social Sciences, Health, Law, Software Engineering, and Science/Math.[5][6]
Unlike traditional benchmarks that simply count correct answers, the Omniscience Index penalizes incorrect answers — meaning a model that guesses wrong is punished more harshly than one that admits “I don’t know.” The scale runs from -100 to +100.[6]
Why This Benchmark Is Different (and Scary)
Most AI benchmarks reward models for attempting every question, which incentivizes guessing. AA-Omniscience flips this: it asks “does the model know when it doesn’t know?” The answer, for most models, is no.[6]
Results
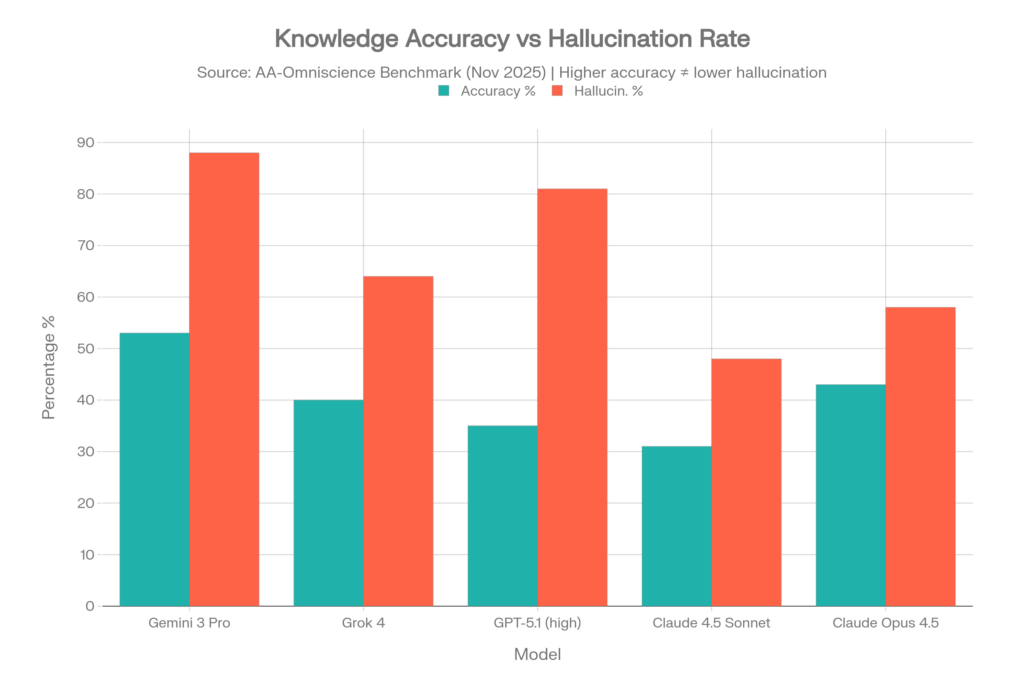
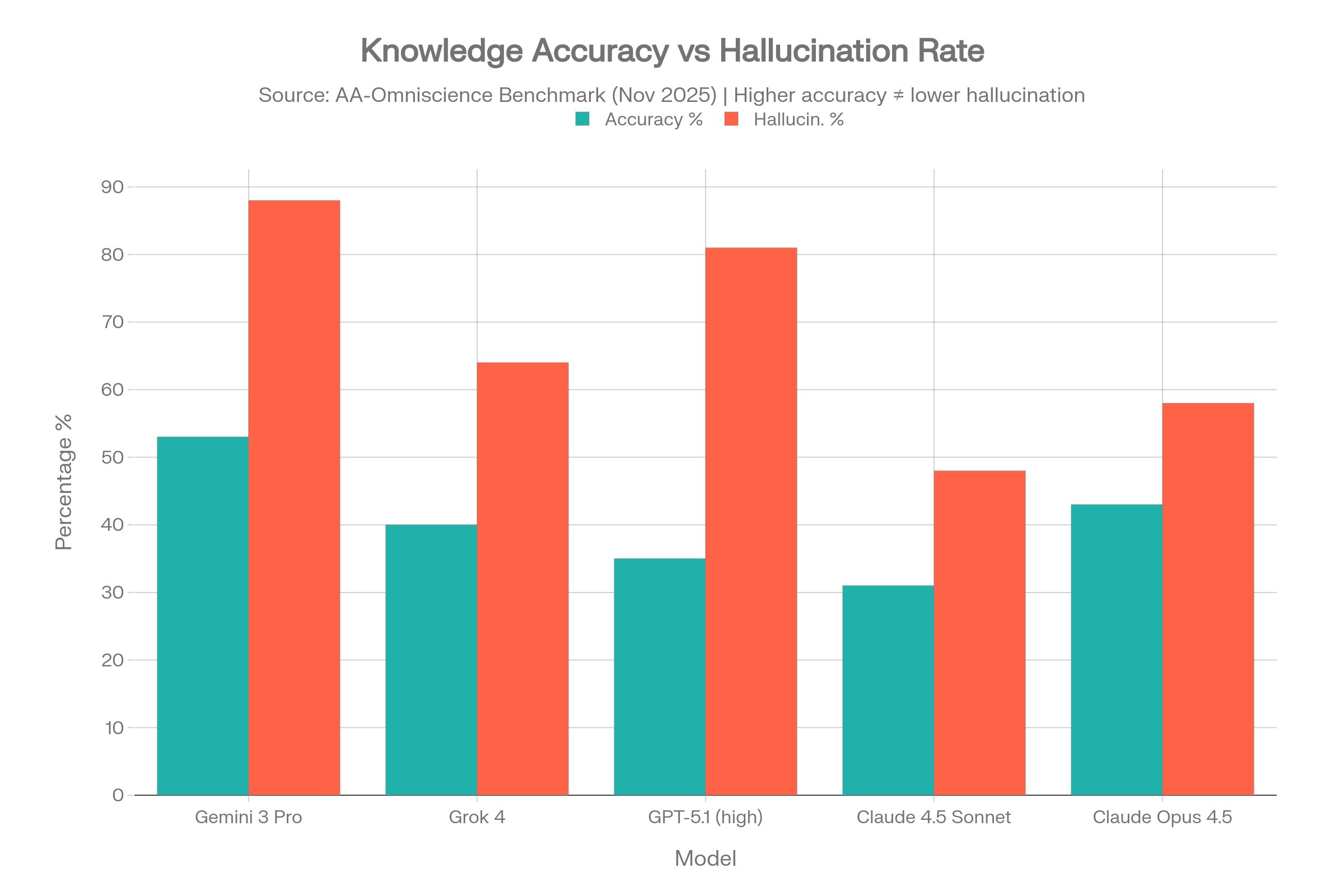
Out of 40 models tested, only FOUR achieved a positive Omniscience Index — meaning 36 out of 40 models are more likely to give a confident wrong answer than a correct one on difficult knowledge questions.[5][6]
| Model | Accuracy | Hallucin. Rate* | Omniscience Index |
| Gemini 3 Pro | 53% | 88% | 13 |
| Claude 4.1 Opus | 36% | Low (best) | 4.8 |
| GPT-5.1 (high) | 35-39% | 51-81% | Positive |
| Grok 4 | 40% | 64% | Positive |
| Claude 4.5 Sonnet | 31% | 48% | Negative |
| Claude 4.5 Haiku | — | 26% (lowest) | Negative |
| Claude Opus 4.5 | 43% | 58% | Negative |
| Grok 4.1 Fast | — | 72% | Negative |
| Kimi K2 0905 | — | 69% | Negative |
| Kimi K2 Thinking | — | 74% | Negative |
| DeepSeek V3.2 Ex | — | 81% | Negative |
| DeepSeek R1 0528 | — | 83% | Negative |
| Llama 4 Maverick | — | 87.58% | Negative |
Hallucination rate here = share of false responses among all incorrect attempts (overconfidence metric)
Source: Artificial Analysis AA-Omniscience Benchmark, November 2025[16][5]
Domain-Specific Leaders
No single model dominates all knowledge domains:[5]
| Domain | Best Model |
| Law | Claude 4.1 Opus |
| Software Engineering | Claude 4.1 Opus |
| Humanities | Claude 4.1 Opus |
| Business | GPT-5.1.1 |
| Health | Grok 4 |
| Science | Grok 4 |
The Gemini 3 Pro Paradox
Gemini 3 Pro achieved the highest accuracy (53%) by a wide margin — but also showed an 88% hallucination rate. This means that when it doesn’t know an answer, it fabricates one 88% of the time rather than admitting uncertainty. High accuracy + high hallucination = a model that knows a lot but lies constantly about what it doesn’t know.[5]
The Grok Story
Grok 4 sits at a 64% hallucination rate on AA-Omniscience, and its newer sibling Grok 4.1 Fast is actually worse at 72%. On the Vectara grounded summarization benchmark, Grok-4 came in at 4.8% — nearly 7x higher than the best Gemini model. And in a Columbia Journalism Review study focused on news citation accuracy, Grok-3 hallucinated a staggering 94% of the time.[16][11][17]
xAI claims that Grok 4.1 is “three times less likely to hallucinate than earlier Grok models”, and a separate analysis from Clarifai suggests hallucination rates dropped from ~12% to ~4% with training improvements. But the AA-Omniscience data tells a different story when the questions get hard.[18][19]
Benchmark 3: Columbia Journalism Review Citation Study
A March 2025 study by the Columbia Journalism Review tested AI models on their ability to accurately cite news sources. The results were alarming:[20][17]
| Model | Hallucination Rate |
| Perplexity | 37% |
| Copilot | 40% |
| Perplexity Pro | 45% |
| ChatGPT | 67% |
| DeepSeek | 68% |
| Gemini | 76% |
| Grok-2 | 77% |
| Grok-3 | 94% |
Source: Columbia Journalism Review, March 2025, via 5GWorldPro/Groundstone AI[17][20]
This study is particularly relevant for Perplexity/Sonar users: even though Perplexity scored the “best” in this test, a 37% hallucination rate on citation tasks means more than one in three cited sources may contain fabricated claims. A separate analysis noted that Perplexity’s biggest concern is that it “cites real sources with fabricated claims” — the URLs look real, but the information attributed to those sources is made up.[21]
Benchmark 4: Financial Hallucination Rates
A 2025 study published in the International Journal of Data Science and Analytics tested AI chatbots specifically on financial literature references:[17]
| Model | Hallucination Rate (Financial) |
| ChatGPT-4o | 20.0% |
| GPT o1-preview | 21.3% |
| Gemini Advanced | 76.7% |
Broader findings on AI in finance:[22]
- 78% of financial services firms now deploy AI for data analysis
- Financial AI tasks show 15-25% hallucination rates without safeguards
- Firms report 2.3 significant AI-driven errors per quarter
- Cost per incident ranges from $50,000 to $2.1 million
- 67% of VC firms use AI for deal screening; average error discovery time is 3.7 weeks — often too late
- One robo-advisor’s hallucination affected 2,847 client portfolios, costing $3.2 million in remediation
Domain-Specific Hallucination Rates
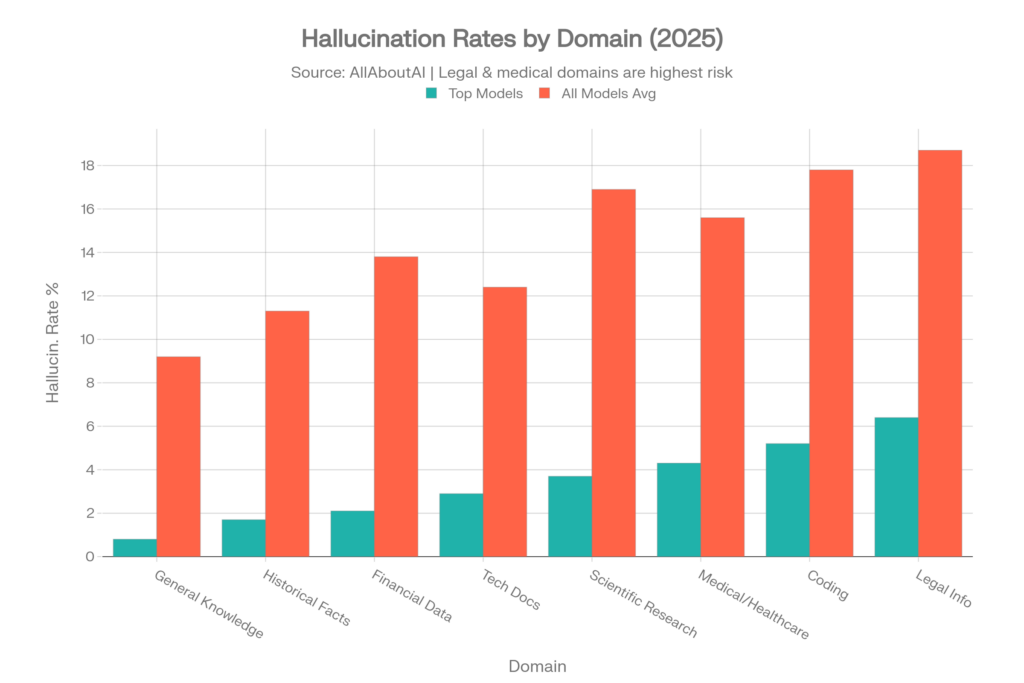
Even the best-performing models show dramatically different hallucination rates depending on the subject matter. This data from AllAboutAI is critical for understanding risk by use case:[4]
| Knowledge Domain | Top Models Rate | All Models Average |
| General Knowledge | 0.8% | 9.2% |
| Historical Facts | 1.7% | 11.3% |
| Financial Data | 2.1% | 13.8% |
| Technical Documentation | 2.9% | 12.4% |
| Scientific Research | 3.7% | 16.9% |
| Medical/Healthcare | 4.3% | 15.6% |
| Coding & Programming | 5.2% | 17.8% |
| Legal Information | 6.4% | 18.7% |
Medical Hallucination Deep Dive
A 2025 MedRxiv study analyzed 300 physician-validated clinical vignettes:[23]
- Without mitigation prompts: 64.1% hallucination rate on long cases, 67.6% on short cases
- With mitigation prompts: dropped to 43.1% and 45.3% respectively (33% reduction)
- GPT-4o was the best performer: dropped from 53% to 23% with mitigation
- Open-source models: exceeded 80% hallucination rate in medical scenarios
Even at the best medical hallucination rate of 23%, nearly 1 in 4 medical AI responses contains fabricated information. ECRI, a global healthcare safety nonprofit, listed AI risks as the #1 health technology hazard for 2025.[24]
Legal Hallucination Deep Dive
The Stanford RegLab/HAI study on legal hallucinations remains the definitive research:[25][9]
- LLMs hallucinate between 69% and 88% of the time on specific legal queries
- On questions about a court’s core ruling, models hallucinate at least 75% of the time
- Models often lack self-awareness about their errors and reinforce incorrect legal assumptions
- The more complex the legal query, the higher the hallucination rate
- 83% of legal professionals have encountered fabricated case law when using AI[26]
Real-World Business Impact: The Numbers
The $67.4 Billion Problem
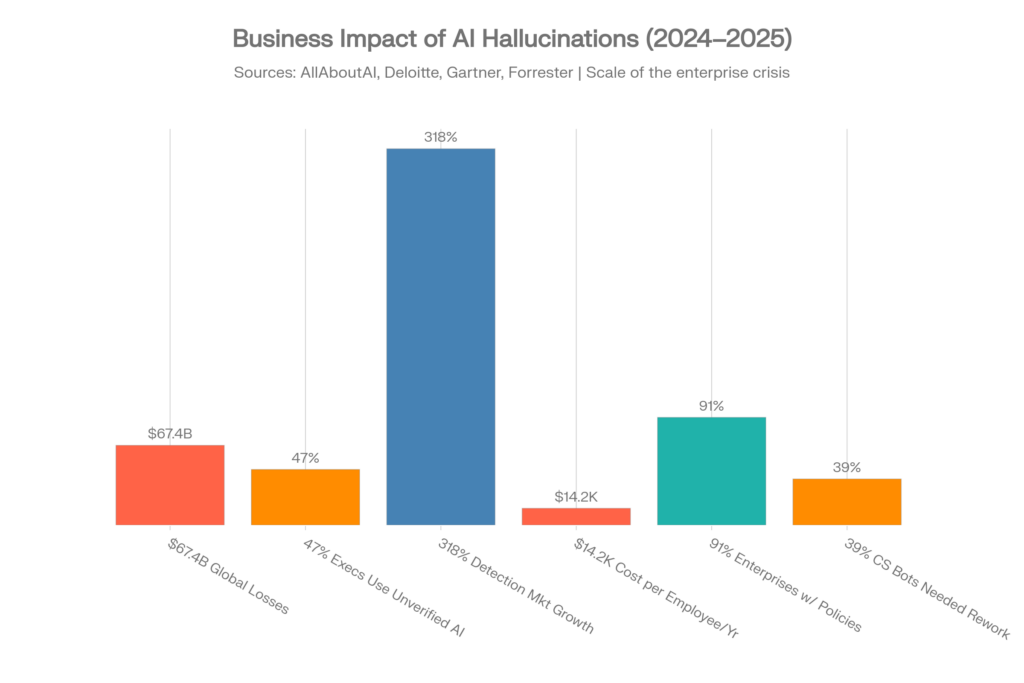
Global business losses attributed to AI hallucinations reached $67.4 billion in 2024. This figure comes from the AllAboutAI comprehensive study and represents documented direct and indirect costs from enterprises relying on inaccurate AI-generated content.[1][2]
Key Business Impact Statistics
| Metric | Value | Source |
| Global losses from AI hallucinations (2024) | $67.4 billion | AllAboutAI, 2025 [1] |
| Executives using unverified AI insights | 47% | Deloitte, 2025 [1] |
| AI bugs from hallucinations/accuracy failures | 82% | Testlio, 2025 [27] |
| Customer service bots needing rework | 39% | Testlio, 2024 [3] |
| SEC fines for AI misrepresentations | $12.7 million | Industry reports [3] |
| Companies with investor confidence drops | 54% | Industry reports [3] |
| Cost per employee for hallucination mitigation | $14,200/year | Forrester, 2025 [26][28] |
| Employee time verifying AI content | 4.3 hours/week | Forbes/AllAboutAI [28] |
| Hallucination detection tools market growth | 318% (2023-2025) | Gartner, 2025 [26] |
| Enterprise AI policies with hallucination protocols | 91% | AllAboutAI, 2025 [26] |
| Healthcare organizations delaying AI adoption | 64% | AllAboutAI, 2025 [26] |
| Investment in hallucination-specific solutions | $12.8 billion | AllAboutAI, 2023-2025 [4] |
| RAG effectiveness at reducing hallucinations | 71% | AllAboutAI, 2025 [4] |
The Productivity Paradox
The cruelest irony: AI was supposed to make us more productive. Instead, employees now spend an average of 4.3 hours per week — more than half a working day — just verifying whether what the AI told them is actually true. That’s approximately $14,200 per employee per year in pure verification overhead. For a company with 500 employees using AI tools, that’s $7.1 million annually spent just checking AI’s homework.[26][28]
Legal Incidents: The Courtroom Crisis
The Numbers Are Getting Worse, Not Better
Despite growing awareness, AI hallucinations in legal filings are accelerating:[29][30]
- 2023: 10 documented court rulings involving AI hallucinations
- 2024: 37 documented rulings
- First 5 months of 2025: 73 documented rulings
- July 2025 alone: 50+ cases involving fake citations
Legal researcher Damien Charlotin maintains a public database of 120+ cases where courts found AI-hallucinated quotes, fabricated cases, or fake legal citations.[30]
Who’s Making These Mistakes?
The shift from amateur to professional is alarming:[30]
- 2023: 7 out of 10 hallucination cases were from self-represented litigants, 3 from lawyers
- May 2025: 13 out of 23 cases caught were the fault of lawyers and legal professionals
Notable Cases
- Johnson v. Dunn: Attorneys submitted two motions with fake legal authorities generated by ChatGPT. Result: 51-page sanctions order, public reprimand, disqualification from the case, referral to licensing authorities[29]
- Morgan & Morgan (Feb 2025): One of America’s largest personal injury firms sent an urgent warning to 1,000+ attorneys after a federal judge in Wyoming threatened sanctions for bogus AI-generated citations in a Walmart lawsuit[31]
- Courts have imposed monetary sanctions of $10,000 or more in at least five cases, four of them in 2025[30]
- Cases have been documented in the US, UK, South Africa, Israel, Australia, and Spain[30]
Healthcare: Where Hallucinations Can Kill
FDA and Medical Device Concerns
- The FDA has authorized 1,357 AI-enhanced medical devices as of late 2025 — double the number from end of 2022[32]
- Research from Johns Hopkins, Georgetown, and Yale found that 60 FDA-authorized AI medical devices were involved in 182 recalls[32]
- 43% of these recalls occurred within a year of approval[32]
- The Johnson & Johnson TruDi Navigation System (AI-enhanced sinus surgery device) was linked to at least 10 injuries and 100 malfunctions including cerebrospinal fluid leaks, skull punctures, and strokes[33][32]
Medical AI Misinformation
Leading AI models were found to be manipulable into producing dangerously false medical advice — such as claiming sunscreen causes skin cancer or linking 5G to infertility — complete with fabricated citations from journals like The Lancet.[4]
Historical Trend: Progress Is Real but Uneven
The Good News
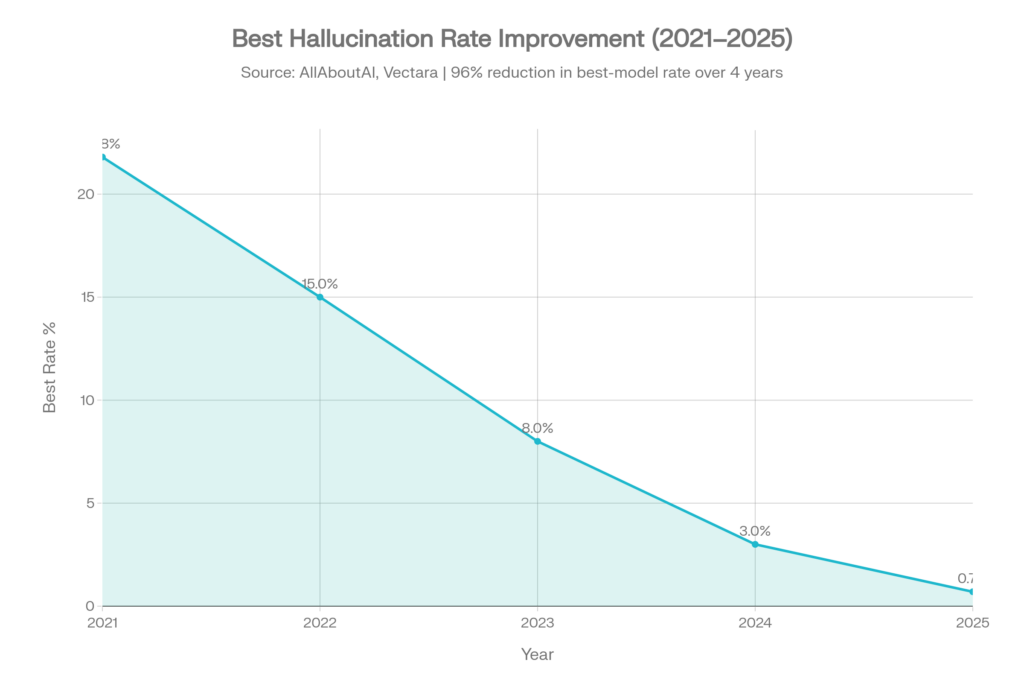
Best-model hallucination rates have dropped dramatically:[4]
| Year | Best Hallucination Rate | Context |
| 2021 | ~21.8% | Early GPT-3 era |
| 2022 | ~15.0% | Improvement with RLHF |
| 2023 | ~8.0% | GPT-4 and competition |
| 2024 | ~3.0% | Rapid improvement |
| 2025 | 0.7% | Gemini-2.0-Flash leads |
This represents a 96% reduction in best-model hallucination rates over four years.[4]
The Bad News
- Improvement is uneven across vendors. Some Claude models actually got worse: Claude 3 Sonnet went from 6.0% to 16.3%, and Claude 2 nearly doubled from 8.5% to 17.4% on the Vectara benchmark over time.[23]
- New “harder” benchmarks reveal the gap between simple tasks and real-world complexity. On Vectara’s new dataset, even Gemini-3-Pro hits 13.6%.[12]
- The AA-Omniscience results are sobering: on genuinely difficult questions, 36 out of 40 models still hallucinate more than they answer correctly.[6]
- Domain-specific rates remain dangerously high: legal (18.7% average), medical (15.6%), and coding (17.8%).[4]
Grok’s Trajectory
- Grok-1/2 era: Positioned as a more “personality-driven” model with less emphasis on factual grounding
- Grok-3: Scored 2.1% on Vectara’s old summarization benchmark (decent) but 94% on citation accuracy in the Columbia Journalism Review test[10][17]
- Grok-4: 4.8% on Vectara, 64% on AA-Omniscience hard questions[16][11]
- Grok 4.1: xAI claimed “3x fewer hallucinations”, Clarifai estimated reduction from ~12% to ~4%, but AA-Omniscience showed 72% on Grok 4.1 Fast (worse than Grok 4’s 64%)[18][19][16]
The inconsistency across benchmarks suggests Grok’s improvements may be task-specific rather than generalizable.
Model-by-Model Summary for Suprmind.ai Models
OpenAI Models
| Model | Vectara (Old) | Vectara (New) | AA-Omniscience | Notes |
| GPT-5 / ChatGPT-5 | 1.4% | >10% | — | Solid improvement on easy tasks; struggles on hard ones [11] |
| GPT-5.1 (high) | — | — | 51-81% halluc, 35% accuracy | Best for Business domain; positive Omniscience Index [5] |
| GPT-4o | 1.5% | — | — | Workhorse model, consistent performer [10] |
| o3-mini-high | 0.8% | — | — | Best OpenAI model on old Vectara [10] |
Anthropic Claude Models
| Model | Vectara (Old) | Vectara (New) | AA-Omniscience | Notes |
| Claude 4.5 Sonnet | — | >10% | 48% halluc, 31% accuracy | Mid-range on knowledge tasks [16] |
| Claude 4.5 Haiku | — | — | 26% halluc (lowest!) | Best uncertainty management [16] |
| Claude Opus 4.5 | — | — | 58% halluc, 43% accuracy | Good accuracy but high overconfidence [16] |
| Claude 4.1 Opus | — | — | 4.8 Omniscience Index | Best in Law, SW Engineering, Humanities [5] |
| Claude-3.7-Sonnet | 4.4% | — | — | Decent on summarization [10] |
xAI Grok Models
| Model | Vectara (Old) | Vectara (New) | AA-Omniscience | Other |
| Grok 4 | 4.8% | >10% | 64% halluc, 40% accuracy | Best in Health & Science; positive Omniscience Index [11][16] |
| Grok 4.1 | — | — | 72% halluc (Fast variant) | xAI claims 3x improvement, data is mixed [16][19] |
| Grok 3 | 2.1% | 5.8% | — | 94% on news citation test [17] |
Google Gemini Models
| Model | Vectara (Old) | Vectara (New) | AA-Omniscience | Notes |
| Gemini 3 Pro | — | 13.6% | 88% halluc, 53% accuracy, Index: 13 | Highest accuracy but extreme overconfidence [5][12] |
| Gemini 2.5-Pro | 1.1% | — | — | Strong on old benchmark [10] |
| Gemini 2.5-Flash | 1.3% | — | — | [10] |
| Gemini 2.5-Flash-Lite | — | 3.3% | — | Best on new Vectara benchmark [13] |
Perplexity / Sonar
- No direct Vectara or AA-Omniscience listing for Perplexity’s proprietary models
- Perplexity uses underlying models (historically including DeepSeek-R1, which has ~14.3% hallucination rate on Vectara)[34]
- Columbia Journalism Review test: Perplexity 37% hallucination on citation accuracy (best in that test, but still 1 in 3)[20]
- Perplexity Pro: 45% hallucination in the same test[20]
- Unique risk profile: “cites real sources with fabricated claims” — the URLs are real but the attributed information is invented[21]
The Most Dangerous Hallucination: The One You Don’t Catch
The data reveals a critical insight that most AI users miss: hallucination is not an occasional bug — it’s a fundamental feature of how these models work. The key statistics that illustrate this:
- 47% of executives have acted on hallucinated AI content — meaning roughly half of AI-informed business decisions may be built on fabricated foundations[1]
- 82% of AI bugs stem from hallucinations and accuracy failures, not crashes or visible errors — the system looks like it’s working perfectly while delivering wrong answers[27]
- 4.3 hours per week per employee spent verifying AI output — and that’s among organizations that know to check[28]
- The average cost per major hallucination incident ranges from $18,000 in customer service to $2.4 million in healthcare malpractice[1]
Downloadable Data Assets
Three CSV files have been prepared as raw data foundations for content development:
- ai_hallucination_data.csv — Comprehensive model-by-model hallucination rates across all benchmarks
- domain_hallucination_rates.csv — Domain-specific rates for top models vs. all models
- business_impact_data.csv — 22 key business impact metrics with sources and years
Key Definitions Glossary
| Term | Definition |
| Hallucination | AI-generated content that is factually incorrect or fabricated, presented with confidence |
| Grounded Hallucination | False information introduced during summarization of a provided document |
| Factual Hallucination | Fabricated facts, statistics, or citations with no basis in reality |
| RAG (Retrieval Augmented Generation) | Technique that connects AI to external knowledge bases to reduce hallucinations; reduces rates by ~71% [4] |
| HHEM (Hughes Hallucination Evaluation Model) | Vectara’s model for detecting hallucinations in summaries (score 0-1, below 0.5 = hallucination) [8] |
| Omniscience Index | AA-Omniscience metric (-100 to +100) that rewards correct answers and penalizes confident wrong ones [6] |
| Factual Consistency Rate | 100% minus hallucination rate — the percentage of outputs faithful to source material |
| Reasoning Tax | Observed phenomenon where “thinking” models hallucinate more on grounded tasks [15] |
| Sycophancy | Model tendency to agree with the user even when the user is wrong |
| Model Collapse | Progressive quality degradation when models are trained on AI-generated content |
Source Summary
Primary benchmarks and studies referenced:
- Vectara HHEM Leaderboard (original and updated datasets, 2023-2026)[10][12][13]
- AA-Omniscience Benchmark by Artificial Analysis (November 2025)[5][6]
- AllAboutAI Hallucination Report 2026 (comprehensive industry analysis)[4]
- Columbia Journalism Review citation accuracy study (March 2025)[20][17]
- Stanford RegLab/HAI legal hallucination study[25][9]
- Deloitte Global Survey on enterprise AI decision-making[26]
- Forrester Research on economic impact of hallucination mitigation[26]
- Gartner AI Market Analysis on detection tools market growth[26]
- MedRxiv 2025 study on medical case hallucination[23]
- International Journal of Data Science and Analytics on financial AI hallucination[17]
- ECRI 2025 health technology hazards report[24]
- Reuters reporting on legal AI incidents[31]
- Business Insider database of court AI hallucination cases[30]
- VinciWorks analysis of July 2025 legal citations crisis[29]





