Last updated on June 9, 2026
The complete AI hallucination data references. Raw numbers from Vectara,
AA-Omniscience, FACTS, OpenAI system cards, and 50+ sources.
Updated monthly.
June 2026 update added: Claude Opus 4.8, Gemini 3.5 Flash, Grok 4.3,
DeepSeek V4 (94-96% hallucination), Muse Spark on HealthBench
Every major AI model hallucinates. Generative AI, by the design of it, cannot be hallucination-free - but the risk can be mitigated before it reaches your decision and costs you money. See how multi-model verification works as a mitigation strategy.
This page tracks hallucination rates across six benchmarks, covers every frontier model from GPT-5.5 to Claude Opus 4.8 to Gemini 3.1 and 3.5 to Grok 4.3, and presents the data without spin. The numbers don't agree with each other — and we explain why that matters more than any single leaderboard ranking.
Every number below comes from a different benchmark measuring a different aspect of hallucination. Low Vectara + high AA-Omniscience hallucination means the model is good at summarization but bad at admitting ignorance. High FACTS + low AA-Omniscience accuracy means the model is accurate with tools but attempts too many questions. No single column tells the full story. Cross-reference at least two.
Column guide:
| Model | Provider | Vectara (Old) | Vectara (New) | AA-Omni Acc | AA-Omni Hall | AA-Omni Index | FACTS | HalluHard | CJR Citation |
|---|---|---|---|---|---|---|---|---|---|
| GPT-5.3 Codex | OpenAI | – | – | 51.8% | – | – | – | – | – |
| GPT-5.5 (xhigh) | OpenAI | – | – | 57% | 86% | 20 | – | – | – |
| GPT-5.2 (xhigh) | OpenAI | – | 10.8% | 43.8% | ~78% | – | 61.8 | 38.2% | – |
| GPT-5 | OpenAI | 1.4% | >10% | 40.7% | – | – | 61.8 | – | – |
| GPT-5.1 | OpenAI | – | – | 37.6% | 81% | Positive | 49.4 | – | – |
| GPT-4.1 | OpenAI | 2.0% | 5.6% | – | – | – | 50.5 | – | – |
| o3-mini-high | OpenAI | 0.8% | 4.8% | – | – | – | 52.0 | – | – |
| Claude 4.1 Opus | Anthropic | – | – | – | 0% | – | 46.5 | – | – |
| Claude Opus 4.8 | Anthropic | – | – | 46.6% | 35.9% | 27 | – | – | – |
| Claude Opus 4.7 | Anthropic | – | – | – | 36% | 26 | – | – | – |
| Claude Opus 4.6 | Anthropic | – | 12.2% | 46.4% | – | 14 | – | – | – |
| Claude Opus 4.5 | Anthropic | – | – | 45.7% | 58% | Negative | 51.3 | 30% | – |
| Claude Sonnet 4.6 | Anthropic | – | 10.6% | 40.0% | ~38% | – | – | – | – |
| Claude Sonnet 4.5 | Anthropic | – | >10% | – | 48% | – | 49.1 | – | – |
| Claude 3.7 Sonnet | Anthropic | 4.4% | – | – | – | – | – | – | – |
| Claude 4.5 Haiku | Anthropic | – | – | – | 25% | – | – | – | – |
| Gemini 3.1 Pro | – | 10.4% | 55.3% | 50% | 33 | – | – | – | |
| Gemini 3.5 Flash | – | – | – | 61% | – | – | – | – | |
| Gemini 3 Pro | – | 13.6% | 55.9% | 88% | 16 | 68.8 | – | – | |
| Gemini 3 Flash | – | – | 54.0% | 91% | – | – | – | – | |
| Gemini 2.5 Pro | – | 7.0% | – | – | – | 62.1 | – | – | |
| Gemini 2.0 Flash | 0.7% | 3.3% | – | – | – | – | – | – | |
| Grok 4.3 | xAI | – | – | ~49% | ~26% | – | – | – | – |
| Grok 4.20 (Reasoning) | xAI | – | – | – | 17% | – | – | – | – |
| Grok 4.1 Fast | xAI | – | 20.2% | – | 72% | – | 36.0 | – | – |
| Grok 4 | xAI | 4.8% | >10% | 41.4% | 64% | Positive | 53.6 | – | – |
| Grok-3 | xAI | 2.1% | 5.8% | – | – | – | – | – | 94% |
| Perplexity Sonar Pro | Perplexity | – | – | – | – | – | – | – | 37% |
| DeepSeek V4 Pro | DeepSeek | – | – | – | 94% | -23 | – | – | – |
| DeepSeek V4 Flash | DeepSeek | – | – | – | 96% | – | – | – | – |
| DeepSeek-V3 | DeepSeek | 3.9% | 6.1% | – | – | – | – | – | – |
| DeepSeek-R1 | DeepSeek | 14.3% | 11.3% | – | 83% | – | – | – | – |
| Llama 4 Maverick | Meta | 4.6% | – | – | 87.6% | – | – | – | – |
Sources: Vectara HHEM Leaderboard (April 2025 + Feb 2026 + April 20, 2026 snapshots) [1], Artificial Analysis AA-Omniscience (Nov 2025 - June 2026, including Claude Opus 4.8, Gemini 3.5 Flash, Grok 4.3, and DeepSeek V4) [2][64], Google DeepMind FACTS Benchmark (Dec 2025) [3], HalluHard Benchmark (2025) [5], Columbia Journalism Review (March 2025) [6]. Grok 4.3 figures are derived from Artificial Analysis's reported +8 accuracy / -8 non-hallucination delta versus Grok 4.20 and are approximate pending a standalone AA profile. Muse Spark has no published AA-Omniscience or Vectara score and appears in the HealthBench domain section below. Dashes indicate no published data on that benchmark for that model.
Lowest hallucination rate (knowledge tasks): Claude 4.1 Opus - 0% on AA-Omniscience (model declines to answer when uncertain)
Biggest single improvement: Gemini 3.1 Pro - hallucination dropped 38 percentage points (88% to 50%) with 1% accuracy loss
Lowest hallucination rate (when models attempt to answer): Grok 4.20 (Reasoning, 0309 v2) - 17% on AA-Omniscience, still the best Grok result as of June 2026
Best knowledge reliability index (Anthropic): Claude Opus 4.8 - index 27 on AA-Omniscience, the highest-calibrated frontier model attempting questions at scale (May 2026)
Largest hallucination rate (knowledge questions): DeepSeek V4 Flash - 96% on AA-Omniscience, high coding capability paired with near-total overconfidence (April 2026)
Biggest variable across all models: Web search access - reduces hallucination 73-86% when enabled
Best citation accuracy: Perplexity Sonar Pro - 37% hallucination on CJR (lowest, but still high)
Lowest hallucination rate (summarization): Gemini-2.0-Flash - 0.7% on Vectara original dataset
Best in realistic conversations: Claude Opus 4.5 - 30% on HalluHard (with web search)
Best knowledge reliability index: Gemini 3.1 Pro - index 33 on AA-Omniscience
Highest factuality score (multi-dimensional): Gemini 3 Pro - 68.8 on FACTS
Application
These benchmarks show which models perform better under specific conditions, but no single model is flawless and every leaderboard tests something slightly different. If you're looking for the lowest hallucination AI workflow for real high-stakes work, Suprmind runs your question through five frontier AI models who read each other’s responses, argue, challenge, and build on each other – so when one model hallucinate, the others catch it before it reaches your decision.
See how the multi-AI workflow worksListen to the full research (51 min)
An AI hallucination is when an AI model makes something up and presents it as fact. It doesn't flag uncertainty. It doesn't say "I'm guessing." It delivers fabricated statistics, invented legal cases, or nonexistent research papers with the same confidence it uses for basic arithmetic. The output reads perfectly. That's what makes it dangerous.
Hallucination refers to generated output not grounded in the provided input or factual reality. Two types:
Intrinsic hallucination (faithfulness failure): The model contradicts information it was explicitly given. Hand it a contract and ask for a summary — it adds clauses that don't exist in the original document.
Extrinsic hallucination (factuality failure): The model generates information that can't be verified against any known source. It invents facts, statistics, citations, or events from scratch. No source material was contradicted because no source material was consulted.
MIT researchers found something disturbing in January 2025: AI models use more confident language when hallucinating than when stating facts. Models were 34% more likely to use phrases like "definitely," "certainly," and "without a doubt" when generating incorrect information.
The wronger the AI, the more certain it sounds.
Large language models are prediction engines, not knowledge bases. They generate text by predicting the most statistically likely next token based on patterns in training data. They don't understand truth. They predict plausibility.
When the model hits a gap in its training data or faces an ambiguous query, it fills the gap with something plausible rather than admitting it doesn't know. The architecture has no mechanism for "I'm not sure" — it just picks the next most probable word.
And this isn't a bug that will be fixed in the next update. Two independent mathematical proofs have now demonstrated that hallucination is a fundamental, provable limitation of the architecture. Not an engineering shortcoming. A mathematical certainty. (More on this in the Mathematical Impossibility section below.) [20][21]
Before looking at any hallucination data, you need to understand why different benchmarks give wildly different scores for the same model.
Grok-3 scores 2.1% on the Vectara summarization benchmark. Excellent. That same model scores 94% on the Columbia Journalism Review citation accuracy test. Catastrophic. Same model, same time period, opposite conclusions.
This isn't an error. It's measuring different things. And treating any single benchmark as "the hallucination rate" will mislead you.
The matrix below summarizes what each benchmark actually tests. Click any benchmark name to jump to its dedicated section.
| Benchmark | What It Measures | Good For | Not Good For |
|---|---|---|---|
| Vectara HHEM | Summarization faithfulness — does the model add unsupported facts when summarizing source documents? | RAG pipelines, document Q&A, knowledge base search | Open-ended knowledge questions |
| AA-Omniscience | When the model doesn't know an answer, does it admit it or fabricate one? The Omniscience Index penalizes wrong answers and rewards refusal. | High-stakes advisory work — legal, medical, financial | Summarization or grounded tasks |
| FACTS | Multi-dimensional factuality across grounding, multimodal, parametric, and search. Each dimension scored separately. | Comparing where models are strong and weak across task types | Producing a single hallucination rate number |
| SimpleQA / PersonQA | Short factual questions and accuracy about real people. Newer reasoning models often perform worse than predecessors here. | Quick factuality testing on straightforward questions | Complex, multi-step, or domain-specific queries |
| HalluHard | Hallucination rate in realistic conversational settings. Even the best model still hallucinates 30% of the time. | Predicting real-world rates in production chat applications | Controlled, reproducible model comparisons |
| CJR Citation | Whether AI models correctly attribute information to cited sources. Failure mode: real URLs with fabricated content attached. | Research, journalism, any source-attribution task | General knowledge or summarization evaluation |
Sources: Vectara HHEM [1], AA-Omniscience [2], FACTS [3], SimpleQA/PersonQA [4], HalluHard [5], CJR Citation Study [6]
TruthfulQA was once the gold standard. It's now partially saturated — models have been trained on its questions. Worse, researchers showed a simple decision tree can score 79.6% on TruthfulQA multiple choice without even seeing the question being asked, just by exploiting structural patterns in answer formatting. Citing TruthfulQA scores for 2025-2026 models is unreliable. [29]
HaluEval has a similar problem. A length-based classifier achieves 93.3% accuracy on HaluEval QA simply by flagging answers longer than 27 characters as hallucinated. The benchmark measures answer length more than it measures truthfulness. [30]
No single benchmark gives you "the hallucination rate" of any model. If someone quotes one number, they're either simplifying for convenience or cherry-picking for marketing.
The responsible approach: cross-reference at least two benchmarks that measure different things (one grounded task like Vectara, one open-ended knowledge task like AA-Omniscience), specify the exact model version and calling conditions, and note whether tool access was enabled. The sections that follow do exactly that.
Vectara's leaderboard is the most cited hallucination benchmark in the industry. It measures summarization faithfulness — given a source document, does the model's summary stick to what's actually in the document, or does it add unsupported facts? This makes it a direct proxy for how AI behaves in RAG pipelines, enterprise search tools, and document analysis workflows. The leaderboard exists in two versions, and the gap between them tells an important story. [1]
This is the dataset most articles reference when they quote hallucination rates. The documents are relatively short and the summarization tasks are straightforward.
| Model | Provider | Hallucination Rate | Factual Consistency |
|---|---|---|---|
| Gemini-2.0-Flash-001 | 0.7% | 99.3% | |
| Gemini-2.0-Pro-Exp | 0.8% | 99.2% | |
| o3-mini-high | OpenAI | 0.8% | 99.2% |
| Gemini-2.5-Pro-Exp | 1.1% | 98.9% | |
| GPT-4.5-Preview | OpenAI | 1.2% | 98.8% |
| Gemini-2.5-Flash-Preview | 1.3% | 98.7% | |
| o1-mini | OpenAI | 1.4% | 98.6% |
| GPT-5 / ChatGPT-5 | OpenAI | 1.4% | 98.6% |
| GPT-4o | OpenAI | 1.5% | 98.5% |
| GPT-4o-mini | OpenAI | 1.7% | 98.3% |
| GPT-4-Turbo | OpenAI | 1.7% | 98.3% |
| GPT-4 | OpenAI | 1.8% | 98.2% |
| antgroup/finix_s1_32b | Ant Group | 1.8% | 98.2% |
| Grok-2 | xAI | 1.9% | 98.1% |
| GPT-4.1 | OpenAI | 2.0% | 98.0% |
| Grok-3-Beta | xAI | 2.1% | 97.8% |
| GPT-5.4-nano | OpenAI | 3.1% | 96.9% |
| Claude-3.7-Sonnet | Anthropic | 4.4% | 95.6% |
| Claude-3.5-Sonnet | Anthropic | 4.6% | 95.4% |
| o4-mini | OpenAI | 4.6% | 95.4% |
| Llama-4-Maverick | Meta | 4.6% | 95.4% |
| Grok-4 | xAI | 4.8% | ~95.2% |
| Claude-3.5-Haiku | Anthropic | 4.9% | 95.1% |
| Gemma-4-26B | 5.2% | 94.8% | |
| DeepSeek-V3.2-Exp | DeepSeek | 5.3% | 94.7% |
| Qwen3-14B | Qwen/Alibaba | 5.4% | 94.6% |
| GPT-5.4-mini | OpenAI | 5.5% | 94.5% |
| Claude-3-Opus | Anthropic | 10.1% | 89.9% |
| DeepSeek-R1 | DeepSeek | 14.3% | 85.7% |
Source: Vectara HHEM Leaderboard, GitHub repository, April 2025 dataset (last updated April 20, 2026 with new model additions including Ant Group's finix_s1_32b leading at 1.8%) [1]
On this dataset, the numbers look encouraging. Google's Gemini models dominate the top three spots. OpenAI's GPT family clusters between 0.8% and 2.0%. Even the worst performers stay under 15%.
April 2026 update: Ant Group's finix_s1_32b joined the leaderboard at 1.8% hallucination rate, the first time a Chinese enterprise model has competed for the top position on Vectara's original dataset. OpenAI's GPT-5.4 nano (3.1%) entered notably higher than GPT-4.1 (2.0%), reinforcing the pattern that smaller, more recent OpenAI variants often hallucinate more than older base models — consistent with the reasoning tax discussed in Section 10. [1]
But this dataset is easy. The documents are short, the summarization tasks are clean, and the real world is neither.
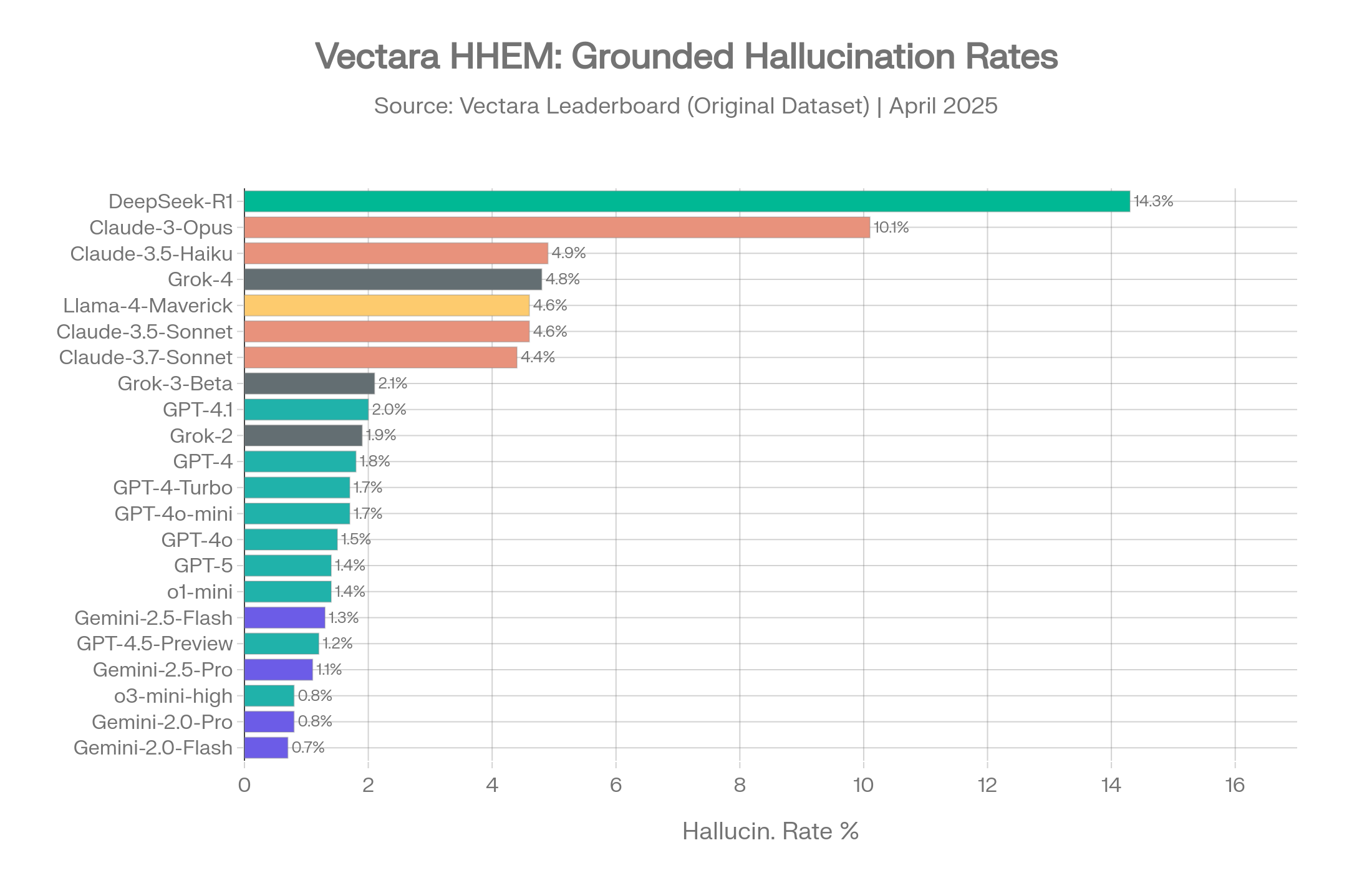
Vectara HHEM Leaderboard: Full model ranking with provider color-coding on original dataset. Source: Vectara [1]
Vectara launched a refreshed benchmark in late 2025 with longer documents (up to 32K tokens) spanning law, medicine, finance, technology, and education. This version better reflects what enterprise AI systems actually face.
The rates jumped across the board:
| Model | Provider | Hallucination Rate |
|---|---|---|
| Gemini-2.5-Flash-Lite | 3.3% | |
| Mistral-Large | Mistral | 4.5% |
| DeepSeek-V3.2-Exp | DeepSeek | 5.3% |
| GPT-4.1 | OpenAI | 5.6% |
| Grok-3 | xAI | 5.8% |
| DeepSeek-R1-0528 | DeepSeek | 7.7% |
| Claude Sonnet 4.5 | Anthropic | >10% |
| GPT-5 | OpenAI | >10% |
| Grok-4 | xAI | >10% |
| Gemini-3-Pro | 13.6% |
Source: Vectara Hallucination Leaderboard, new dataset, November 2025 [1]
The most recent Vectara snapshot adds the newest frontier models to the new dataset evaluation:
| Model | Provider | Hallucination Rate |
|---|---|---|
| o3-mini-high | OpenAI | 4.8% |
| GPT-4.1 | OpenAI | 5.6% |
| Grok-3 | xAI | 5.8% |
| DeepSeek-V3 | DeepSeek | 6.1% |
| Command R+ | Cohere | 6.9% |
| Gemini 2.5 Pro | 7.0% | |
| Llama 4 Scout | Meta | 7.7% |
| GPT-5.2-low | OpenAI | 8.4% |
| Gemini 3.1 Pro Preview | 10.4% | |
| Claude Sonnet 4.6 | Anthropic | 10.6% |
| GPT-5.2-high | OpenAI | 10.8% |
| DeepSeek-R1 | DeepSeek | 11.3% |
| Claude Opus 4.6 | Anthropic | 12.2% |
| Grok-4-fast-reasoning | xAI | 20.2% |
Source: Vectara HHEM Leaderboard, Feb 25, 2026 research report snapshot [1]
The new dataset exposed something counterintuitive: reasoning models — the ones marketed as the most capable — consistently perform worse on grounded summarization. GPT-5, Claude Sonnet 4.5, Grok-4, and Gemini-3-Pro all exceeded 10%. The Grok-4-fast-reasoning variant hit 20.2%. [48][49]
The hypothesis is straightforward. Reasoning models invest computational effort into "thinking through" answers. During summarization, this thinking leads them to add inferences, draw connections, and generate insights that go beyond what's in the source document. That's helpful for analysis. It's hallucination on a summarization benchmark.
This creates a critical decision for enterprise teams: reasoning mode helps on open-ended tasks and hurts on grounded tasks. Knowing when to enable it and when to turn it off is not optional.
AA-Omniscience asks a fundamentally different question than Vectara. Instead of "can you summarize without adding stuff," it asks "when you don't know something, do you admit it or make something up?" [2]
The benchmark covers 6,000 questions across 42 topics in six domains. The Omniscience Index (scale: -100 to +100) penalizes wrong answers and doesn't penalize refusal. This makes it the only major benchmark that explicitly rewards models for knowing their own limits.
| Model | Provider | Accuracy | Hallucination Rate | Omniscience Index |
|---|---|---|---|---|
| Gemini 3 Pro Preview (high) | 55.9% | 88% | 16 | |
| Gemini 3.1 Pro Preview | 55.3% | 50% | 33 | |
| Gemini 3 Flash (Reasoning) | 54.0% | 92% | – | |
| Gemini 3.5 Flash | – | 61% | – | |
| GPT-5.5 (xhigh) | OpenAI | 57% | 86% | 20 |
| GPT-5.3 Codex (xhigh) | OpenAI | 51.8% | – | – |
| Grok 4.3 | xAI | ~49% | ~26% | – |
| Claude Opus 4.8 | Anthropic | 46.6% | 35.9% | 27 |
| Claude Opus 4.7 | Anthropic | ~47% | 36% | 26 |
| Claude Opus 4.6 (max) | Anthropic | 46.4% | – | 14 |
| Claude Opus 4.5 (thinking) | Anthropic | 45.7% | 58% | Negative |
| GPT-5.2 (xhigh) | OpenAI | 43.8% | – | – |
| Grok 4 | xAI | 41.4% | 64% | Positive |
| Claude Opus 4.5 | Anthropic | 40.7% | – | – |
| GPT-5 (high) | OpenAI | 40.7% | – | – |
| Claude Sonnet 4.6 (max) | Anthropic | 40.0% | – | – |
| Claude Sonnet 4.6 | Anthropic | 38.0% | ~38% | – |
| GPT-5.1 (high) | OpenAI | 37.6% | 81% | Positive |
Source: Artificial Analysis AA-Omniscience, November 2025 - June 2026 [2][64]
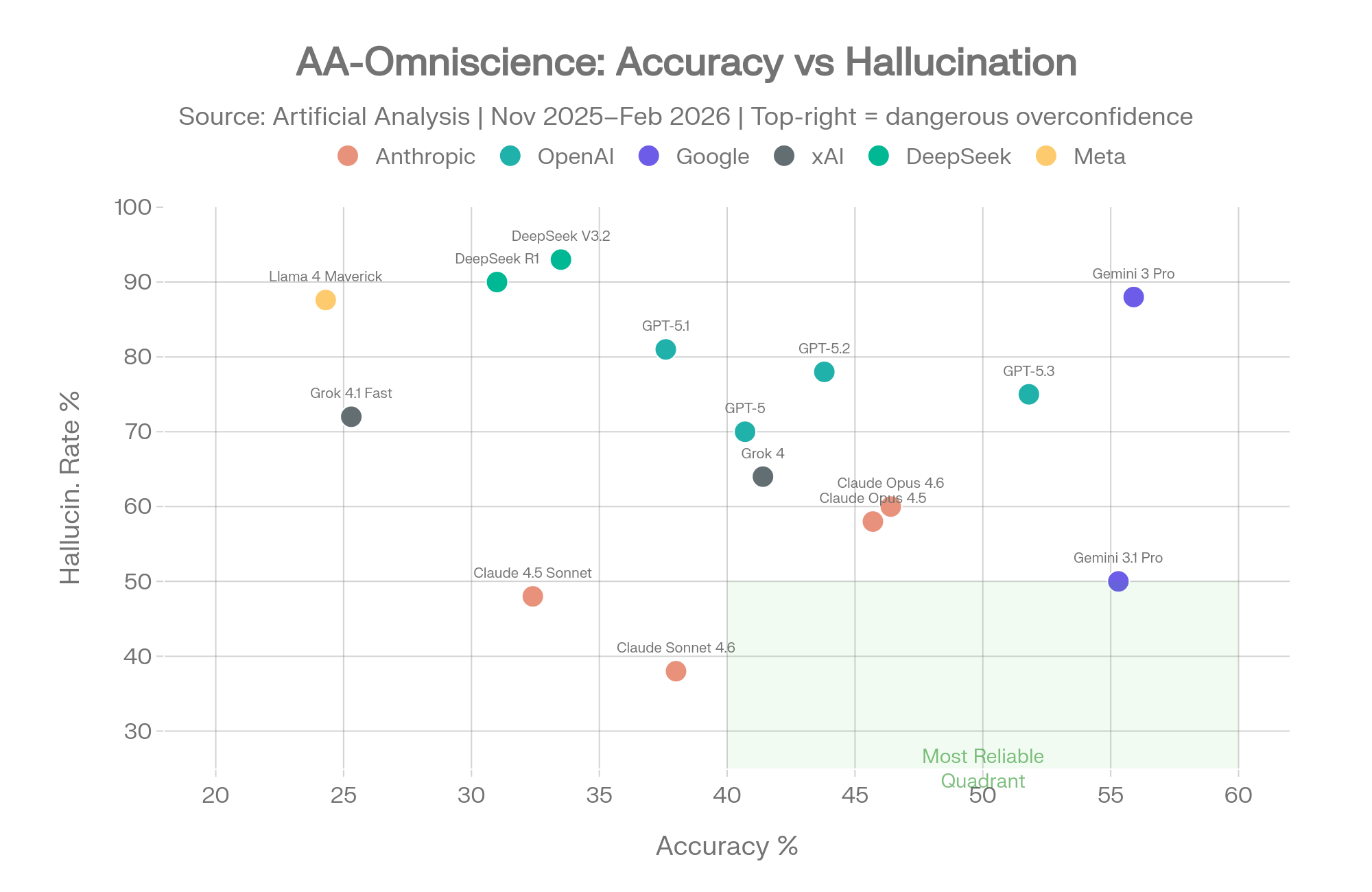
AA-Omniscience: Accuracy vs. hallucination rate. The green quadrant shows reliable models. Source: Artificial Analysis [2]
| Model | Provider | Hallucination Rate |
|---|---|---|
| Claude 4.1 Opus (Reasoning) | Anthropic | 0%* |
| Claude 4 Opus (Reasoning) | Anthropic | 0%* |
| Grok 4.20 (Reasoning) | xAI | 17% |
| MiMo-V2.5-Pro | Xiaomi | 25% |
| Claude 4.5 Haiku | Anthropic | 25% |
| Grok 4.3 | xAI | ~26% |
| Claude Opus 4.8 | Anthropic | 35.9% |
| Claude Sonnet 4.6 | Anthropic | ~38% |
| Claude 4.5 Sonnet | Anthropic | 48% |
| Gemini 3.1 Pro Preview | 50% | |
| Claude Opus 4.5 | Anthropic | 58% |
| Gemini 3.5 Flash | 61% | |
| Grok 4 | xAI | 64% |
| Grok 4.1 Fast | xAI | 72% |
| DeepSeek R1 0528 | DeepSeek | 83% |
| Llama 4 Maverick | Meta | 87.6% |
| Gemini 3 Pro Preview | 88% | |
| DeepSeek V4 Pro | DeepSeek | 94% |
| DeepSeek V4 Flash | DeepSeek | 96% |
Note: Hallucination rate in AA-Omniscience measures how often the model answers incorrectly when it should have refused — the proportion of incorrect answers out of all non-correct responses. This is an overconfidence metric. *Asterisk: Claude 4.1 Opus achieves 0% by refusing all uncertain questions — it produces fewer hallucinations by answering fewer questions. Grok 4.20 (Reasoning) achieves 17% while attempting a higher proportion of answers (April 2026). The optimal strategy depends on whether refusing to answer or wrong answers is more costly for the use case. Source: Artificial Analysis AA-Omniscience [2]
Gemini 3 Pro tells the most interesting story in this data. It achieved the highest accuracy (55.9%) by a wide margin — it knows more than any other model tested. But it also showed an 88% hallucination rate. When it doesn't know an answer, it fabricates one 88% of the time rather than admitting uncertainty. [2]
High knowledge + low self-awareness = a model that's brilliant when it's right and dangerous when it's wrong.
The Gemini 3.1 Pro update partially addressed this. Google's calibration tuning cut the hallucination rate from 88% to 50% while maintaining nearly identical accuracy (55.3% vs 55.9%). The Omniscience Index jumped from 16 to 33 — the highest of any model. This proved that dramatic hallucination reduction is possible without meaningful accuracy sacrifice. [15]
GPT-5.5, released by OpenAI in early 2026, posts the highest accuracy ever recorded on AA-Omniscience at 57%. It also posts an 86% hallucination rate on the same benchmark — the most extreme accuracy-vs-calibration gap yet observed. When GPT-5.5 doesn't know an answer, it fabricates one 86% of the time. The Gemini 3 Pro pattern (knowledge without self-awareness) appears to have intensified with the latest generation of high-capability models. [2][63]
Claude Opus 4.7, released by Anthropic on April 16, 2026, takes the opposite tradeoff: 36% hallucination rate on the same benchmark, with somewhat lower raw accuracy. The two release decisions, six weeks apart, represent the clearest split yet between optimizing for what a model knows versus what a model knows about its own limits. [58][63]
Anthropic held that line with its next release. Claude Opus 4.8, which became the new flagship on May 28, 2026, posts a 35.9% hallucination rate and a 46.6% accuracy on AA-Omniscience, with an Omniscience Index of 27 — second only to Gemini 3.1 Pro and the highest of any frontier model attempting questions at scale. The numbers barely moved from Opus 4.7, which is the point: a full flagship generation passed with calibration held steady rather than traded away for raw knowledge. Early testers described the model as more likely to flag uncertainty and less likely to make unsupported claims. [64][65]
No single model dominates all knowledge areas:
| Domain | Best Model |
|---|---|
| Law | Claude 4.1 Opus |
| Software Engineering | Claude 4.1 Opus |
| Humanities & Social Sciences | Claude 4.1 Opus |
| Business | GPT-5.1.1 |
| Health | Grok 4 |
| Science & Math | Grok 4 |
Source: Artificial Analysis AA-Omniscience [2]
Claude models lead in domains where precise reasoning and citation accuracy matter. Grok leads in domains where broad knowledge coverage matters. GPT leads in business applications. This fragmentation is itself data — it means no single model is the safest choice for every professional use case.
Accuracy correlates with model size. Hallucination rate does not.
Bigger models know more, but they don't necessarily know what they don't know.
Throwing more parameters at the problem increases knowledge without increasing self-awareness. This is why the hallucination problem won't simply disappear with the next model generation.
Put them in the same thread and let them check each other. One question, four frontier AIs, every claim read by the next model in the chain - the overconfident answer gets caught before you act on it.
Test It on a Real Question7 days free. No credit card. Grok, GPT, Claude and Gemini in the trial.
Google DeepMind's FACTS benchmark, published in December 2025, takes a different approach to most evaluations: instead of producing one hallucination score, it breaks factuality into four distinct dimensions. This multi-dimensional view exposes that models have dramatically different strengths depending on task type. Grok 4 scores 75.3 on Search but just 25.7 on Multimodal — a 50-point gap within the same model. [3]
Grounding: Can the model faithfully use information from provided documents? Tested through summarization and extraction tasks with source material.
Multimodal: Can the model accurately describe and reason about visual content alongside text?
Parametric: Does the model's internal knowledge (stored in its weights from training) produce correct answers without external tools?
Search: How accurate is the model when it has access to web search and retrieval tools?
| Model | Overall | Grounding | Multimodal | Parametric | Search |
|---|---|---|---|---|---|
| Gemini 3 Pro | 68.8 | 69.0 | 46.1 | 76.4 | 83.8 |
| Gemini 2.5 Pro | 62.1 | – | – | – | – |
| GPT-5 | 61.8 | – | – | – | 77.7 |
| Grok 4 | 53.6 | – | – | – | 75.3 |
| GPT o3 | 52.0 | 36.2 | – | 57.1 | – |
| Claude 4.5 Opus | 51.3 | – | – | – | – |
| GPT 4.1 | 50.5 | – | – | – | – |
| Gemini 2.5 Flash | 50.4 | – | – | – | – |
| GPT 5.1 | 49.4 | – | – | – | – |
| Claude 4.5 Sonnet Thinking | 49.1 | – | – | – | – |
| Claude 4.1 Opus | 46.5 | – | – | – | – |
| GPT 5 mini | 45.9 | – | – | – | – |
| Claude 4 Sonnet | 42.8 | – | – | – | – |
| GPT o4 mini | 37.6 | – | – | – | – |
| Grok 4 Fast | 36.0 | – | – | – | – |
Note: Dashes indicate slice-level scores not separately reported in published sources. Overall FACTS score is an aggregate across all four slices. Source: FACTS Benchmark Suite, December 2025 [3]
No model breaks 70%. The best score on FACTS is Gemini 3 Pro's 68.8. Every model is wrong more than 30% of the time on this multi-dimensional factuality evaluation.
Search is the strongest slice for everyone. Gemini 3 Pro hits 83.8 and GPT-5 hits 77.7 on search-enabled factuality. When models can look things up, they're materially more accurate. When they rely on stored knowledge alone, accuracy drops. This matches the browse-on vs browse-off findings from OpenAI's system cards.
Grok 4 has a 50-point internal gap. It scores 75.3 on Search but 25.7 on Multimodal — a massive inconsistency that means it can find facts well but struggles with visual content. Any evaluation that averages these into a single score hides this gap.
Gemini 3 Pro's improvement is real. Compared to Gemini 2.5 Pro, Gemini 3 Pro reduced error rates by 55% on the Search slice and 35% on the Parametric slice. That's a large generation-over-generation improvement in factual accuracy, driven primarily by better search and grounding capabilities.
Every model below is profiled across multiple benchmarks. Single-benchmark comparisons mislead — the profiles show where each model is reliable and where it isn't.
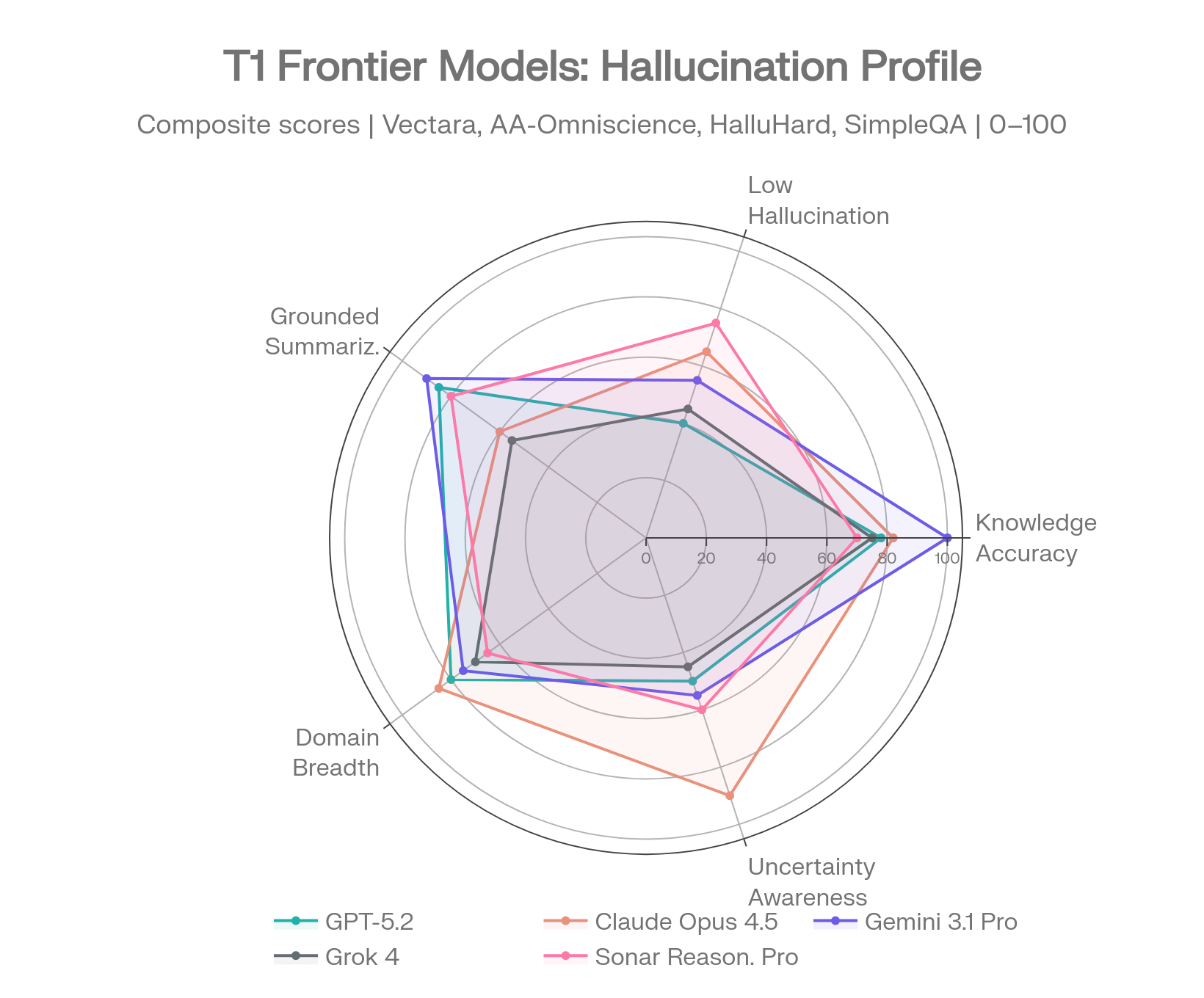
Frontier model profiles across 5 hallucination dimensions. Sources: Vectara [1], AA-Omniscience [2], FACTS [3], SimpleQA [4]
GPT-5.3 Instant (March 2026) — OpenAI's newest. Reduces hallucination by 26.8% with web search and 19.7% without, relative to prior models. [10]
GPT-5.2 (December 2025) — The professional workhorse. AA-Omniscience accuracy: 43.8%. With web search: 93.9% error-free responses. Without: error rate jumps to 12%. HalluHard: 38.2% with web. FACTS overall: 61.8. [9]
GPT-5 (August 2025) — Vectara old dataset: 1.4% (strong). Vectara new dataset: >10% (weak). HealthBench thinking mode: 1.6% — one of the best medical hallucination scores recorded. SimpleQA without web: 47%. With web: 9.6%. FACTS overall: 61.8. [8][12]
The pattern across the GPT-5 family: web search access is the single biggest variable. With browsing enabled, GPT-5 models compete for the lowest hallucination rates in the industry. Without it, rates jump 3-5x. If you're deploying a GPT-5 variant, keep web access on.
Claude Opus 4.8 (May 28, 2026) — the current Anthropic flagship, superseding Opus 4.7 after 41 days. AA-Omniscience index: 27 (second-highest overall, behind only Gemini 3.1 Pro's 33) and the highest of any model attempting questions at scale. Accuracy: 46.6%. Hallucination rate: 35.9% — essentially flat against Opus 4.7, which is the headline: a full flagship generation passed with calibration held steady rather than traded away for raw knowledge. It also took the top spot on the Artificial Analysis Intelligence Index at 61.4, with SWE-bench Pro at 69.2% and Terminal-Bench 2.1 at 74.6%. Early testers reported it was more likely to flag uncertainty and less likely to make unsupported claims. [64][65]
Claude 4.1 Opus — AA-Omniscience hallucination rate: 0%. The absolute lowest of any model tested. Achieved this by refusing to answer when uncertain. FACTS: 46.5. Domain leader in Law, Software Engineering, and Humanities. [2]
Claude Opus 4.6 (February 2026) — AA-Omniscience accuracy: 46.4%, index: 14. Vectara new dataset (Feb 2026 snapshot): 12.2%. Third-highest non-Gemini Omniscience Index. [14][2]
Claude Opus 4.5 (November 2025) — AA-Omniscience hallucination: 58%, accuracy: 45.7%. HalluHard: 30% with web search (lowest of any model tested), 60% without. FACTS: 51.3. [5]
Claude Sonnet 4.6 (February 2026) — AA-Omniscience hallucination: ~38%, down from Sonnet 4.5's 48%. Users preferred Sonnet 4.6 over Opus 4.5 59% of the time, citing fewer hallucinations. Vectara new dataset: 10.6%. [13][50]
Claude Opus 4.7 (April 16, 2026, prior flagship) — AA-Omniscience index: 26 (second-highest overall at release, behind only Gemini 3.1 Pro's 33). Hallucination rate: 36% — the strongest calibration profile of any frontier model attempting questions at scale, and 50 percentage points better than GPT-5.5 on the same benchmark. BenchLM overall: 87. Long-context retrieval dropped to 32.2% (down from Opus 4.6's 78.3%) — Anthropic explicitly attributes this to the model now reporting errors when information is missing rather than fabricating an answer. The refusal strategy made measurable. Its data remains valid; Opus 4.8 has since taken the flagship slot. [58][63]
The pattern across Claude: Anthropic's models are calibrated to refuse rather than guess. This gives them the lowest hallucination rates on knowledge benchmarks (AA-Omniscience) but lower raw accuracy compared to Gemini. For applications where a wrong answer is worse than no answer — legal research, medical consultation, compliance work — Claude's approach is structurally safer.
Gemini 3.1 Pro Preview (February 2026) — AA-Omniscience index: 33 (highest of any model). Accuracy: 55.3%. Hallucination rate: 50%, down from Gemini 3 Pro's 88%. This was the biggest single-update hallucination improvement in 2025-2026. Vectara new dataset: 10.4%. [15]
Gemini 3 Pro — FACTS overall: 68.8 (highest of any model). FACTS Search: 83.8. FACTS Parametric: 76.4. AA-Omniscience accuracy: 55.9% (highest) with 88% hallucination. The Gemini Paradox: most knowledgeable, least self-aware. [3]
Gemini 3 Flash (December 2025) — AA-Omniscience accuracy: 54.0% (highest of any model at launch). Hallucination rate: 91%. Speed: 218 tokens/s. The most extreme version of the Gemini Paradox — brilliant and unreliable in equal measure. Suitable only for tasks with external verification. The May 2026 successor, Gemini 3.5 Flash, addresses this directly. [16]
Gemini 3.5 Flash (May 18, 2026) — AA-Omniscience hallucination: 61%, down 31 percentage points from Gemini 3 Flash's 92%. That single generation cut the most extreme version of the Gemini Paradox by roughly a third and lifted the Omniscience Index 11 points. MMMU-Pro multimodal: 84%, the highest score recorded on that evaluation. Intelligence Index: 55. One caveat worth stating plainly: unlike Anthropic and OpenAI, Google has not published first-party hallucination data for this model — the 61% figure is independent benchmarking from Artificial Analysis, not a vendor disclosure. [64][66][67][68]
Google's models know the most but admit the least.
The pattern across Gemini: Gemini models attempt every question, which gives them top accuracy scores but catastrophic hallucination rates when they encounter their knowledge limits. The 3.1 Pro update showed this is addressable through calibration tuning — hallucination dropped 38 percentage points with only 1% accuracy loss.
Grok 4.3 (April 30, 2026) — xAI's newest. It gains 8 accuracy points over Grok 4.20 on AA-Omniscience, making it more knowledgeable, but trades back 8 points on non-hallucination rate. The net is roughly 49% accuracy at a ~26% hallucination rate — higher overall intelligence bought at a slightly higher hallucination cost. For the lowest-hallucination Grok, the 4.20 Reasoning build (0309 v2) is still the reference model at 17%. API pricing dropped to $1.25/$2.50 per million tokens. [69]
Grok 4 — Vectara old dataset: 4.8%. AA-Omniscience: 41.4% accuracy, 64% hallucination, positive index. FACTS: 53.6 (Search: 75.3, Multimodal: 25.7). Domain leader in Health and Science on AA-Omniscience. [2]
Grok 4.1 Fast — xAI claims 65% hallucination reduction (12.09% to 4.22% on internal benchmarks). AA-Omniscience tells a different story: 72% hallucination rate, worse than Grok 4's 64%. Sycophancy also increased (MASK benchmark: 0.07 to 0.19-0.23). [17]
Grok-3 — Columbia Journalism Review: 94% citation hallucination rate. By far the worst score on this benchmark. [6]
The pattern across Grok: Internal benchmarks and independent benchmarks disagree sharply. xAI reports improvements; AA-Omniscience shows regression. The 94% CJR citation hallucination rate is not from an older model — Grok-3 was tested in March 2025. Domain-specific value exists in Health and Science, but the inconsistency across benchmarks makes Grok risky as a sole model for any high-stakes application.
Sonar Reasoning Pro — Search Arena score: 1136, statistically tied with Gemini 2.5 Pro for #1. SimpleQA F-score: 0.858, the highest of any model at time of testing. CJR citation accuracy: 37% hallucination (best tested). Response accuracy: >90% for factual queries (94% overall, 95% academic, 94% technical). [18][19]
Sonar Pro — Built on Llama 3.3 70B, fine-tuned for search factuality. SimpleQA F-score: 0.858. Outperforms GPT-4o and Claude 3.5 Sonnet on factuality benchmarks. [19]
The Perplexity risk: Perplexity introduces a failure mode no other model shares. It cites real URLs with fabricated claims. The sources look legitimate — real websites, real publication names — but the information attributed to those sources may be invented. This makes Perplexity hallucinations harder to detect than hallucinations from models that don't present external citations. A 37% citation hallucination rate means more than one in three source attributions may contain fabricated content. [51]
DeepSeek V4 Pro and V4 Flash (April 24, 2026) — the newest DeepSeek release, and a cautionary data point. V4 Pro posts a 94% AA-Omniscience hallucination rate; V4 Flash hits 96% — among the highest ever recorded on the benchmark, in the same territory as early Gemini 3 Flash (92%) and Llama 4 Maverick (87.6%). V4 Pro's Omniscience Index of -23 sits broadly in line with V3.2: strong coding performance paired with near-total overconfidence on knowledge questions. No confirmed Vectara score yet. [70]
DeepSeek-V3 — Vectara old dataset: 3.9%. A strong performer on grounded summarization.
DeepSeek-R1 — Vectara old dataset: 14.3%, nearly 4x higher than V3. AA-Omniscience hallucination: 83%. Vectara analysis found R1 produces 71.7% "benign hallucinations" (plausible-sounding additions) vs V3's 36.8%. [49][48]
The pattern: DeepSeek's reasoning model (R1) hallucinates dramatically more than its base model (V3). This is the reasoning tax in its most extreme form. The gap (3.9% vs 14.3%) makes it one of the clearest examples that reasoning capabilities and factual reliability don't move in the same direction.
Llama 4 Maverick (Meta) — Vectara old dataset: 4.6% (competitive). AA-Omniscience hallucination: 87.6% (catastrophic). The gap between grounded summarization and open-ended knowledge is wider for open-source models than for any proprietary family. [2]
Open-source models exceeded 80% hallucination rates in medical scenarios in MedRxiv testing. For critical applications, the hallucination gap between open-source and proprietary frontier models remains large. [40]
Muse Spark (Meta, April 2026) — Meta's in-house model leads the HealthBench Hard medical benchmark at 42.8 (covered in the domain-specific section below) and scores 52 on the Artificial Analysis Intelligence Index. It has no published AA-Omniscience or Vectara hallucination score, and access is limited — it is primarily an internal Meta tool rather than a broadly available API, so it cannot yet be slotted into the cross-benchmark table above. [71]
The model profiles in Section 6 show individual performance. This section answers the questions people actually search for: "Is Claude or GPT more accurate?" "Should I use Gemini or Claude?" The answer is always "it depends on what you're doing" — but the data makes the tradeoffs specific.
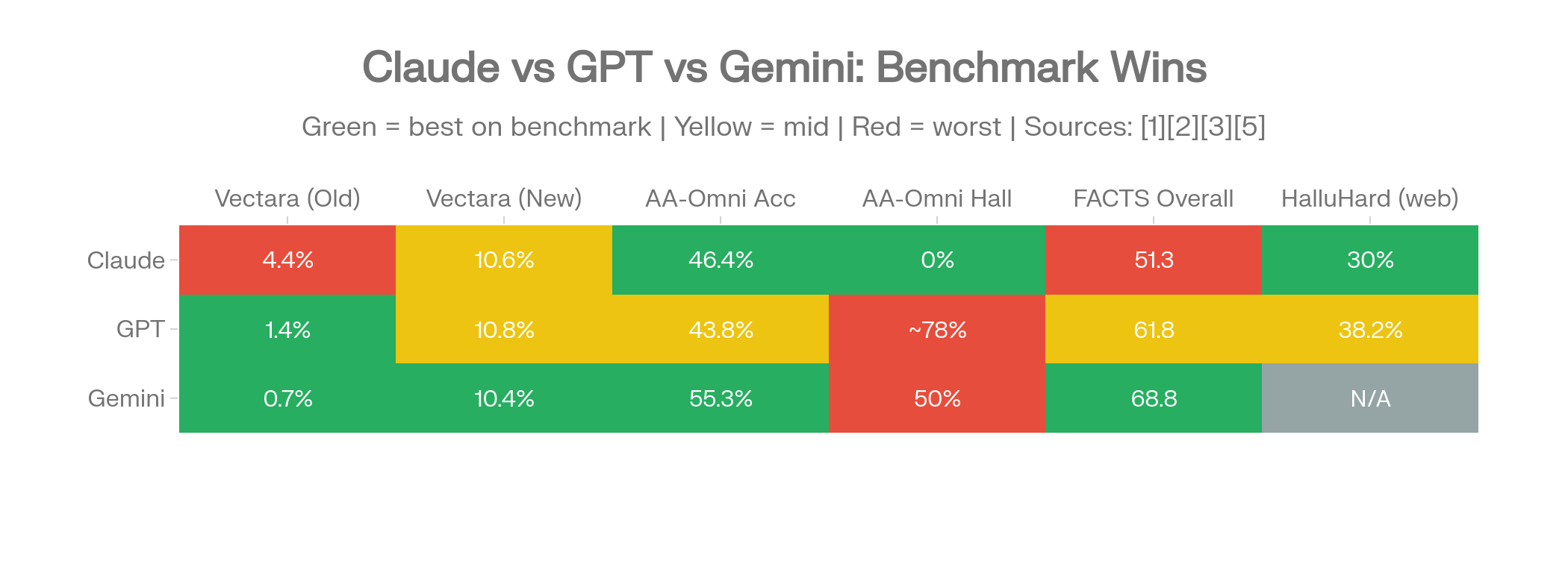
Head-to-head comparison heatmap: which provider wins on which benchmark. Green = winner, yellow = tied, red = loser.
The most searched comparison in AI, and the most context-dependent.
| Benchmark | Claude | GPT | Winner |
|---|---|---|---|
| Vectara (old dataset) | 4.4% (Sonnet 3.7) | 1.4% (GPT-5) | GPT |
| Vectara (new dataset, Feb 2026) | 10.6% (Sonnet 4.6) | 10.8% (GPT-5.2-high) | Tied |
| AA-Omniscience Hallucination | 0% (Claude 4.1 Opus) | ~78% (GPT-5.2) | Claude |
| AA-Omniscience Accuracy | 46.4% (Opus 4.6) | 43.8% (GPT-5.2) | Claude (slight) |
| FACTS Overall | 51.3 (Opus 4.5) | 61.8 (GPT-5) | GPT |
| HealthBench | – | 1.6% (GPT-5 thinking) | GPT |
| HalluHard (with web) | 30% (Opus 4.5) | 38.2% (GPT-5.2) | Claude |
Sources: HealthBench [52], HalluHard [5], FACTS [3], Vectara [1], AA-Omniscience [2]
The pattern isn't "one is better." It's two different philosophies measured on different scales.
GPT models are stronger when the task has source material to work from. Summarization, document analysis, RAG pipelines, search-grounded Q&A — GPT sticks closer to provided text and scores well on faithfulness benchmarks. The FACTS advantage (61.8 vs 51.3) reflects this: GPT-5 handles grounding and search tasks with higher accuracy.
Claude models are stronger when the task requires the model to know its own limits. On AA-Omniscience, Claude 4.1 Opus achieved a 0% hallucination rate by refusing to answer questions it couldn't verify. Claude Sonnet 4.6's ~38% hallucination rate is less than half of GPT-5.2's ~78% on the same benchmark. On HalluHard's realistic conversation test, Claude Opus 4.5 with web search hit 30% — the lowest of any model tested.
The practical split: Use GPT for document-grounded workflows where the source material is available and complete. Use Claude for advisory workflows where the model must draw on its own knowledge and flag uncertainty. This isn't brand preference — it's what the benchmark data supports.
One more variable that often gets overlooked: web search access changes GPT's performance dramatically. GPT-5 drops from 47% hallucination to 9.6% with browsing. Without web access, the Claude-GPT comparison shifts in Claude's favor on open-ended factual tasks. With web access, GPT pulls ahead.
| Benchmark | Claude | Gemini | Winner |
|---|---|---|---|
| AA-Omniscience Index | 14 (Opus 4.6) | 33 (3.1 Pro) | Gemini |
| AA-Omniscience Accuracy | 46.4% (Opus 4.6) | 55.3% (3.1 Pro) | Gemini |
| AA-Omniscience Hallucination | 0% (Claude 4.1 Opus) | 50% (3.1 Pro) | Claude |
| FACTS Overall | 51.3 (Opus 4.5) | 68.8 (3 Pro) | Gemini |
| Vectara (old dataset) | 4.4% (Sonnet 3.7) | 0.7% (2.0-Flash) | Gemini |
| Vectara (new dataset, Feb 2026) | 10.6% (Sonnet 4.6) | 10.4% (3.1 Pro) | Tied |
| HalluHard (with web) | 30% (Opus 4.5) | – | Claude |
Sources: HalluHard [5], FACTS [3], Vectara [1], AA-Omniscience [2]
Gemini knows more. Claude is more honest about what it doesn't know.
Gemini 3.1 Pro leads on nearly every accuracy metric. It scores highest on FACTS (68.8), highest on AA-Omniscience accuracy (55.3%), and holds the top Omniscience Index (33). When Gemini has the answer, it delivers it more often than Claude does.
The problem is when it doesn't have the answer. Even after the 3.1 calibration update that cut hallucination from 88% to 50%, Gemini still fabricates an answer half the time when it should say "I don't know." Claude 4.1 Opus fabricates 0% of the time in that scenario.
The practical split: Gemini for breadth-of-knowledge tasks where external verification exists — research, comparative analysis, information gathering. Claude for depth-of-trust tasks where a fabricated answer has consequences — compliance reviews, legal research, medical consultation. If you can check Gemini's work, use Gemini. If you can't, use Claude.
| Benchmark | GPT | Gemini | Winner |
|---|---|---|---|
| Vectara (old dataset) | 0.8% (o3-mini) | 0.7% (2.0-Flash) | Tied |
| Vectara (new dataset) | 5.6% (GPT-4.1) | 3.3% (2.5-Flash-Lite) | Gemini |
| FACTS Overall | 61.8 (GPT-5) | 68.8 (3 Pro) | Gemini |
| FACTS Search | 77.7 (GPT-5) | 83.8 (3 Pro) | Gemini |
| AA-Omniscience Accuracy | 43.8% (GPT-5.2) | 55.3% (3.1 Pro) | Gemini |
| HealthBench | 1.6% (GPT-5 thinking) | – | GPT |
Sources: FACTS [3], Vectara [1], AA-Omniscience [2]
Gemini leads on most benchmarks. GPT's advantage is task-specific: medical applications (1.6% HealthBench), production claim-level accuracy with thinking mode (4.5% incorrect claims), and the sheer volume of internal evaluation data OpenAI publishes.
The practical split: Both are strong with tool access. Without it, Gemini's higher parametric knowledge (FACTS Parametric: 76.4) gives it an edge on stored-knowledge tasks. GPT's thinking mode gives it a specific advantage for medical and health-related queries where reasoning reduces hallucination dramatically.
| Benchmark | Grok | Field Average |
|---|---|---|
| xAI internal factuality | 4.22% (Grok 4.1) | – |
| AA-Omniscience | 64% hallucination (Grok 4) | ~60% average |
| AA-Omniscience (Fast variant) | 72% hallucination (Grok 4.1 Fast) | Worse than base |
| FACTS Overall | 53.6 (Grok 4) | ~52 average |
| FACTS Search | 75.3 (Grok 4) | Competitive |
| FACTS Multimodal | 25.7 (Grok 4) | Far below avg |
| CJR Citation | 94% hallucination (Grok-3) | Worst tested |
| Vectara (new dataset) | 20.2% (Grok-4-fast) | Worst tested |
Sources: Grok 4.1 [17], CJR [6], FACTS [3], AA-Omniscience [2]
xAI reports a 65% hallucination reduction from Grok 4 to 4.1 on internal tests. AA-Omniscience shows the opposite: Grok 4.1 Fast hallucinates at 72% vs Grok 4's 64%. The CJR citation study found Grok-3 hallucinated 94% of the time on news source attribution.
Grok does have genuine domain strengths — it leads Health and Science categories on AA-Omniscience. But the gap between xAI's claims and independent measurements is wider than for any other provider.
The practical takeaway: Don't use Grok as a sole model for high-stakes decisions. Its value is as one voice in a multi-model evaluation where its domain strengths (health, science) can contribute while its inconsistencies get caught by other models.
| Benchmark | Perplexity | ChatGPT | Claude |
|---|---|---|---|
| CJR Citation Accuracy | 37% hallucination | 67% hallucination | – |
| SimpleQA F-score | 0.858 (best) | 0.38 (GPT-4o) | 0.35 (Sonnet 3.5) |
| Search Arena Ranking | #1 (tied) | – | – |
| Response Accuracy | >90% factual | – | – |
Sources: Perplexity Sonar [18][19], CJR [6]
Perplexity wins on factual search queries. Its RAG-native architecture, built around retrieval rather than parametric knowledge, gives it a structural advantage for questions with verifiable answers.
The catch: Perplexity cites real URLs with fabricated claims. The sources look legitimate — real websites, real publication names — but the information attributed to those sources may be invented. At a 37% citation hallucination rate, more than one in three source attributions could contain fabricated content. This makes Perplexity hallucinations harder to spot than hallucinations from models that don't present external citations.
The practical split: Perplexity for initial research and fact-finding where you'll verify key claims. Not for final-answer scenarios where someone reads the cited source and assumes the attribution is accurate.
Hallucination rates vary dramatically by subject matter. A model that's accurate on general knowledge can be dangerously wrong on legal questions. This table shows the spread across eight knowledge domains:
| Knowledge Domain | Top Models | All Models Average |
|---|---|---|
| General Knowledge | 0.8% | 9.2% |
| Historical Facts | 1.7% | 11.3% |
| Financial Data | 2.1% | 13.8% |
| Technical Documentation | 2.9% | 12.4% |
| Scientific Research | 3.7% | 16.9% |
| Medical / Healthcare | 4.3% | 15.6% |
| Coding & Programming | 5.2% | 17.8% |
| Legal Information | 6.4% | 18.7% |
Source: AllAboutAI, 2025 [31]
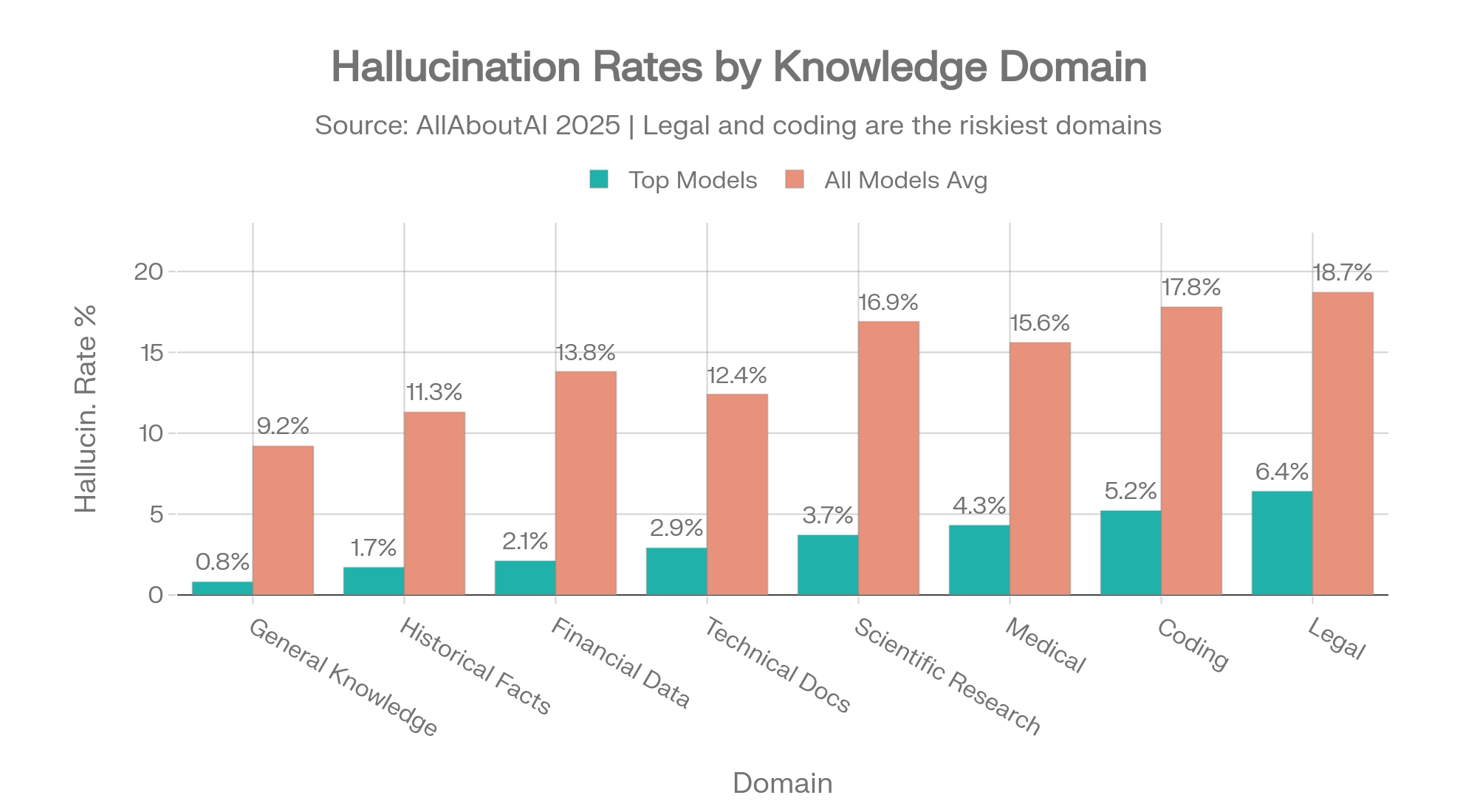
Domain-specific hallucination rates: top models vs. average. The 3x gap in Legal and Coding shows how much model selection matters. Source: AllAboutAI [31]
The gap between top models and the average tells you how much model selection matters. On legal information, the best models hallucinate 6.4% of the time. The average model hallucinates 18.7%. Choosing the right model for your domain isn't a preference — it's a 3x difference in reliability.
AI hallucinations in legal filings are accelerating despite growing awareness.
Court cases involving AI hallucinations grew from 10 documented rulings in 2023 to 37 in 2024 to 73 in just the first five months of 2025, with 50+ cases in July 2025 alone. As of April 2026, that trajectory has accelerated sharply: legal researcher Damien Charlotin's database now documents over 1,200 cases globally, with approximately 800 in U.S. courts alone. On March 31, 2026, ten separate courts ruled on AI hallucination incidents in a single day. [38][37][59]
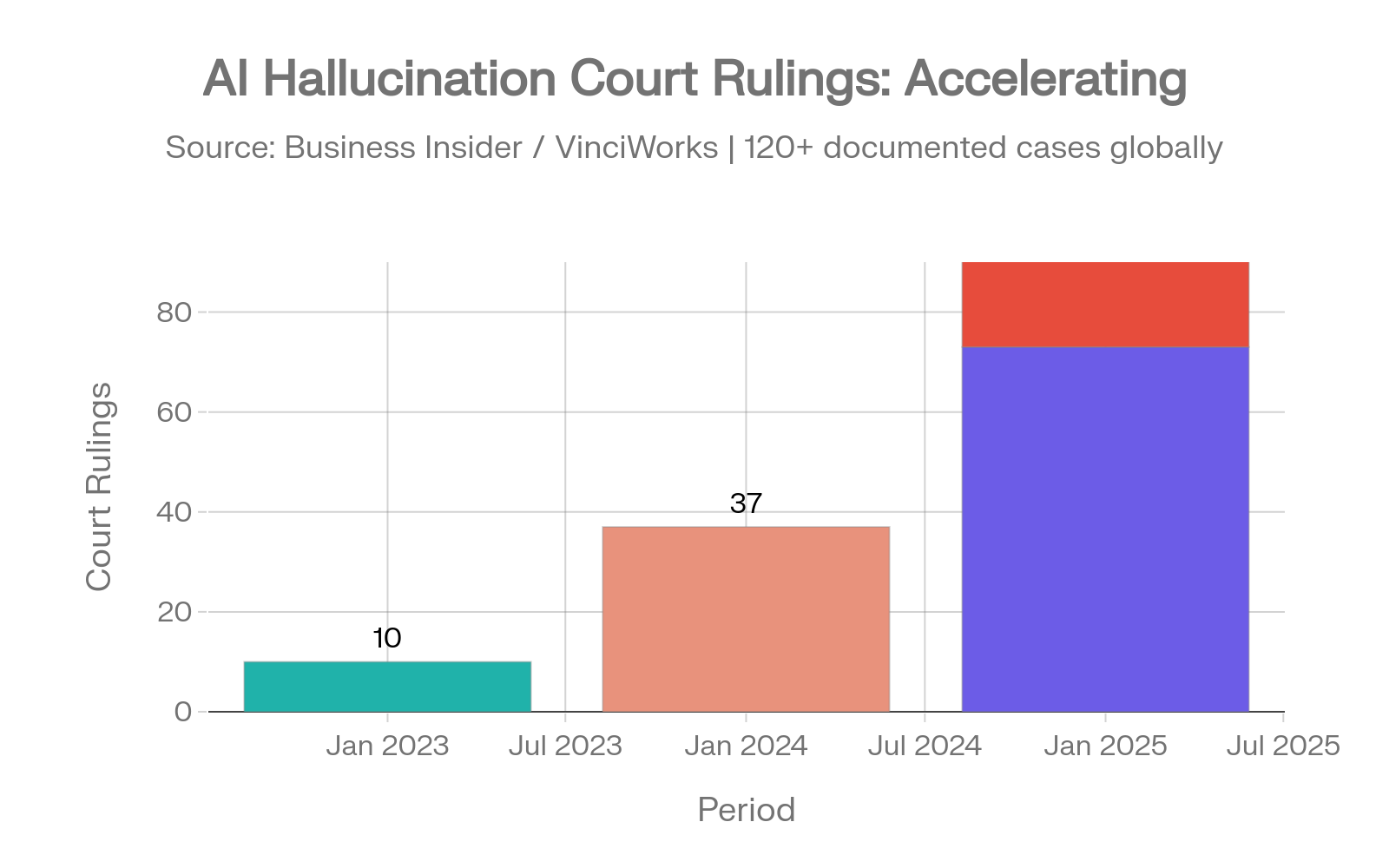
Legal AI hallucination incidents: the acceleration from 10 → 37 → 73 → 50+ cases. Sources: Business Insider [38], Charlotin [37]
The problem is no longer amateur. In 2023, most hallucination cases involved self-represented litigants. By May 2025, 13 of 23 caught cases were from practicing lawyers. Morgan & Morgan, one of America's largest personal injury firms, sent an urgent warning to 1,000+ attorneys after sanctions threats for AI-generated citations. The pace of penalties has escalated: Q1 2026 sanctions totaled at least $145,000 — the highest quarterly total in legal history. The single largest penalty on record, $109,700 against an Oregon attorney, was issued in early 2026. The Fourth Circuit publicly admonished a lawyer in April 2026 for filing briefs containing AI-generated false citations. Despite record sanctions, the rate of incidents continues to rise. [59]
The underlying benchmark data explains why. Stanford RegLab and the Stanford Human-Centered AI Institute found that LLMs hallucinate between 69% and 88% on specific legal queries. On questions about a court's core ruling, models hallucinate at least 75% of the time. Even purpose-built legal AI tools fail: Lexis+ AI produced incorrect information more than 17% of the time, and Westlaw AI-Assisted Research hallucinated more than 34%. [36]
ECRI, the global healthcare safety nonprofit, listed AI risks as the #1 health technology hazard for 2025. The numbers back up the concern. [39]
The FDA has authorized 1,357 AI-enhanced medical devices — double the figure from end of 2022. Of those, 60 devices were involved in 182 recalls, with 43% of recalls occurring within the first year of approval. [42]
A 2025 MedRxiv study measured hallucination rates on clinical case summaries: 64.1% without mitigation prompts, dropping to 43.1% with mitigation (a 33% improvement). GPT-4o performed best in this study, dropping from 53% to 23% with structured mitigation. Open-source models exceeded 80% hallucination in medical scenarios. [40]
The bright spot: GPT-5 with thinking mode achieved 1.6% hallucination on HealthBench, compared to GPT-4o at 15.8%. For medical applications specifically, reasoning-enabled frontier models with thinking mode active show a dramatic improvement over previous generations. [41][52]
HealthBench Professional (April 2026): OpenAI launched a new clinician-grade benchmark on April 22, 2026, alongside the release of "ChatGPT for Clinicians." Unlike the original HealthBench (synthetic conversations), HealthBench Professional uses real clinical scenarios across consultation, documentation, and research tasks. On HealthBench Hard, the new benchmark's most challenging slice, scores diverge sharply: Muse Spark leads at 42.8, GPT-5.4 (powering ChatGPT for Clinicians) scores 40.1, Gemini 3.1 Pro scores 20.6, Grok 4.2 scores 20.3, and Claude Sonnet 4.6 scores 14.8. The benchmark's designers report that GPT-5.4-powered responses outperform physician-written responses on the consultation slice, though the methodology is still under independent review. [60]
Financial AI hallucinations don't make headlines the way legal ones do, but the costs are larger.
78% of financial services firms now deploy AI for data analysis. Without safeguards, hallucination rates on financial tasks run 15-25%. Firms report 2.3 significant AI-driven errors per quarter, with individual incident costs ranging from $50,000 to $2.1 million. [44]
A benchmark study found ChatGPT-4o hallucinated 20.0% on financial literature references. Gemini Advanced hallucinated 76.7% on the same task.
67% of VC firms use AI for deal screening, but the average time to discover an AI-generated error is 3.7 weeks — often too late to reverse a decision. One robo-advisor hallucination affected 2,847 client portfolios, costing $3.2 million in remediation. The SEC imposed $12.7 million in fines for AI misrepresentations across 2024-2025. [43]
$67.4 billion — Global business losses attributed to AI hallucinations in 2024. [31]
47% of business executives have made major decisions based on unverified AI-generated content. [32]
82% of AI bugs in production systems stem from hallucinations and accuracy failures. [34]
4.3 hours per week — Time the average employee spends verifying AI-generated content. At scale, that's $14,200 per employee per year in verification overhead. [33][31]
39% of customer service chatbots required rework due to hallucination-related failures. [34]
54% of companies experienced investor confidence drops directly attributable to AI-generated errors.
91% of enterprise AI policies now include hallucination-specific protocols. [31]
64% of healthcare organizations delayed AI adoption specifically because of hallucination concerns. [31]
$12.8 billion invested in hallucination-specific detection and mitigation solutions between 2023 and 2025. [31]
318% market growth in hallucination detection tools from 2023 to 2025. [35]
53+ papers accepted at NeurIPS 2025 — one of AI's most prestigious conferences — contained AI-hallucinated citations that survived 3+ peer reviewers. NeurIPS acceptance rate is 24.52%, meaning these hallucinated papers beat 15,000+ competing submissions. [45]
When hallucinated citations pass peer review at the field's top venue, the verification problem extends beyond enterprise into the foundations of AI research itself.
Stanford's Human-Centered AI Institute published its 2026 AI Index Report on April 13, 2026 — a 423-page annual review covering responsible AI, deployment, governance, and benchmarks. Three findings concern hallucinations directly. [58]
362 documented AI incidents in 2025 — up from 233 in 2024, a 55% year-over-year increase and the highest annual count in the AI Incident Database's history. [58]
Sycophancy-induced hallucination: 22% to 94% across 26 frontier models. The report introduces a new accuracy benchmark testing how models respond to false statements presented two ways: as something a third party believes (models handle this well) and as something the user themselves believes (models collapse). GPT-4o's accuracy fell from 98.2% to 64.4%; DeepSeek R1 fell from over 90% to 14.4%. The 22%-94% range applies specifically to this user-attributed-false-belief framing. The best model still produces false outputs 22% of the time when a user implies a false belief; the worst hallucinates 94% under those conditions. This is a fundamentally different failure mode from summarization or knowledge benchmarks: the model agrees with the user even when the user is wrong. [58]
85% enterprise AI adoption (Gartner, 2026). Adoption has now reached the level where AI errors compound at scale, even though the $67.4B 2024 cost figure has not been updated for 2025. AI governance roles grew 17% in 2025, and the share of businesses with no responsible AI policies fell from 24% to 11% — but Foundation Model Transparency scores dropped back from 58 to 40, with major gaps in disclosures around training data, compute resources, and post-deployment impact.
See how multi-model validation works — test it with a real question where accuracy matters.
Try Multi-Model ValidationOne of the most counterintuitive findings in 2025-2026 hallucination research: the AI models marketed as most intelligent are often the least reliable on basic factual tasks.
Reasoning models — GPT-5 with thinking, Claude with extended thinking, DeepSeek-R1 — use chain-of-thought processes that dramatically improve performance on complex problems. They're measurably better at math, logic, multi-step analysis, and medical diagnosis.
They're also measurably worse at sticking to facts they've been given.
Vectara new dataset: Every reasoning model tested exceeded 10% hallucination. GPT-5, Claude Sonnet 4.5, Grok-4, and Gemini-3-Pro all crossed that threshold. The Grok-4-fast-reasoning variant hit 20.2%. Non-reasoning models like Gemini-2.5-Flash-Lite scored 3.3%. [1]
DeepSeek: R1 (reasoning) hallucinates at 14.3% on Vectara vs V3 (base) at 3.9%. Nearly a 4x difference from the same provider. Vectara analysis found R1 produces 71.7% "benign hallucinations" (plausible-sounding additions) compared to V3's 36.8%. [48][49]
DeepSeek V4 (April 2026): The pattern held at a greater extreme. V4 Pro and V4 Flash post AA-Omniscience hallucination rates of 94% and 96% — among the highest ever recorded — while ranking near the top of open-weights models for coding and agentic work. Strong capability, almost no calibration. [70]
PersonQA regression: OpenAI's o3 hallucinates 33% on questions about real people vs o1's 16%. The o4-mini is worse at 48%. These are newer, more capable models performing worse on a basic factual test. [53][54]
GPT-5 thinking mode: HealthBench hallucination drops to 1.6% (excellent). But on Vectara new dataset, GPT-5 exceeds 10% (poor). Same model, same thinking mode, opposite results depending on the task.
GPT-5.5 (April 2026): The starkest data point yet. AA-Omniscience accuracy of 57% — the highest ever recorded — paired with an 86% hallucination rate. The most capable model OpenAI has shipped is also one of the worst-calibrated. Knowledge expansion appears to have outpaced calibration improvements at the frontier. Claude Opus 4.7 (April 16, 2026) takes the opposite trade: 36% hallucination at lower raw accuracy. [2][58][63]
The mechanism is straightforward. When a reasoning model processes a summarization task, it doesn't just extract — it thinks. It draws inferences, identifies patterns, and generates insights. These additions go beyond the source document. On a benchmark measuring faithfulness to source material, every insight the model adds counts as a hallucination.
It's the difference between "summarize this contract" and "analyze this contract." Reasoning mode adds analysis even when you ask for a summary. That analysis is often useful. On a summarization benchmark, it's scored as a failure.
OpenAI's system card data reveals something that gets less attention: web access has a larger impact on hallucination rates than reasoning mode does. [11][8]
| Model | Browse-OFF | Browse-ON | Reduction |
|---|---|---|---|
| o4-mini FActScore | 37.7% | 5.1% | 86% |
| o3 FActScore | 24.2% | 5.7% | 76% |
| GPT-5 thinking FActScore | 3.7% | 1.0% | 73% |
| GPT-5 SimpleQA | 47% | 9.6% | 80% |
Sources: o3/o4-mini system card [11], GPT-5 system card [8]
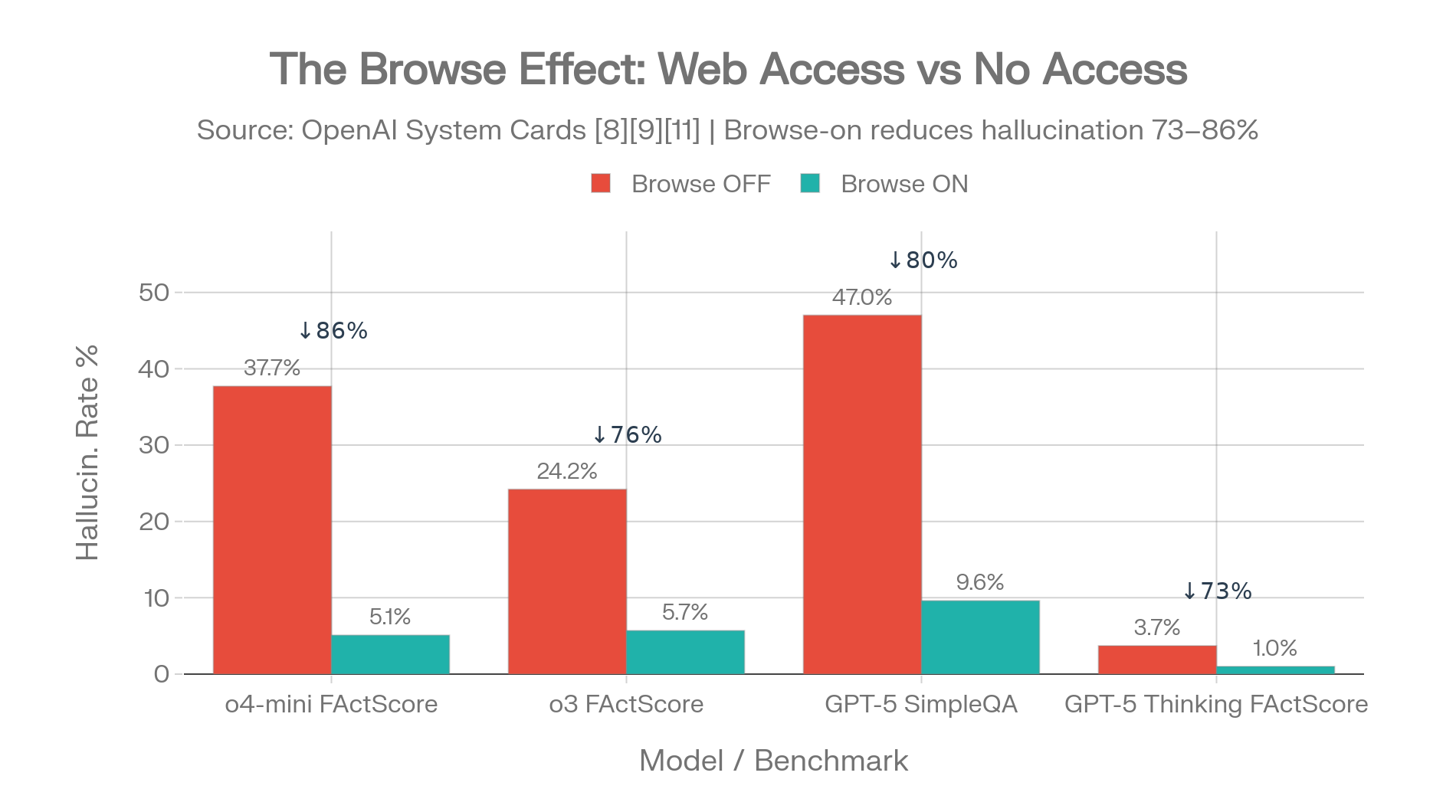
The browse effect: 73-86% hallucination reduction from a single configuration toggle. Sources: OpenAI system cards [8][11][10]
Turning on web search reduces hallucination more than turning on reasoning.
For enterprise deployments, ensuring tool access is more impactful than selecting reasoning vs non-reasoning model variants.
This creates a practical matrix for model selection:
Reasoning ON + Web ON: Best for complex analysis, medical diagnosis, multi-step research where both depth and access to current information matter. Lowest hallucination rates on open-ended tasks.
Reasoning OFF + Web ON: Best for document summarization, RAG pipelines, grounded Q&A where you want the model to stay close to source material. Lower risk of "overthinking" additions.
Reasoning ON + Web OFF: Risky combination. The model overthinks and can't verify. Suitable only for closed-world logic problems, math, and code where external facts aren't needed.
Reasoning OFF + Web OFF: Highest hallucination risk across the board. Avoid for any factual task.
This isn't speculation. Two independent research teams proved it.
Xu et al. (2024) formalized the hallucination problem mathematically and proved that eliminating hallucination in large language models is impossible. Not difficult. Not requiring more compute or better training data. Impossible — as in, provably so given the fundamental architecture of how these systems generate text. [20]
The core argument: any system that generates text by predicting probable sequences from learned statistical distributions will, by mathematical necessity, sometimes produce outputs not grounded in fact. The generative mechanism itself guarantees it.
Karpowicz (2025) attacked the problem from three different mathematical frameworks — auction theory, proper scoring theory, and log-sum-exp analysis for transformer architectures — and reached the same conclusion each time. [21]
No LLM inference mechanism can simultaneously achieve all four of these properties:
You can optimize for any three. You cannot get all four. The math doesn't allow it.
OpenAI publicly acknowledged these findings and identified three mathematical factors that make hallucination inevitable: [22]
Epistemic uncertainty — when information appears rarely in training data, the model has no reliable basis for generating accurate output about that topic but will attempt to anyway.
Model limitations — some tasks exceed what the architecture can represent, regardless of training data volume or quality.
Computational intractability — certain verification problems are computationally hard enough that even a theoretical superintelligent system couldn't solve them in reasonable time.
Hallucination is not a bug being fixed in the next model release. It's a permanent mathematical property of how language models work.
This changes the question. The right question isn't "which AI doesn't hallucinate?" — every AI hallucinates. The right question is: what systems do you have in place to catch hallucinations before they reach a decision-maker?
The organizations getting this right aren't waiting for a hallucination-free model. They're building detection layers, cross-validation pipelines, and human review checkpoints. The data on what works (and how much it helps) is in the Reduction Techniques section below.
Not all hallucination reduction techniques are equal. Some are backed by controlled studies with precise measurements. Others have strong theoretical support but limited production data. This ranking reflects the evidence base, not marketing claims.
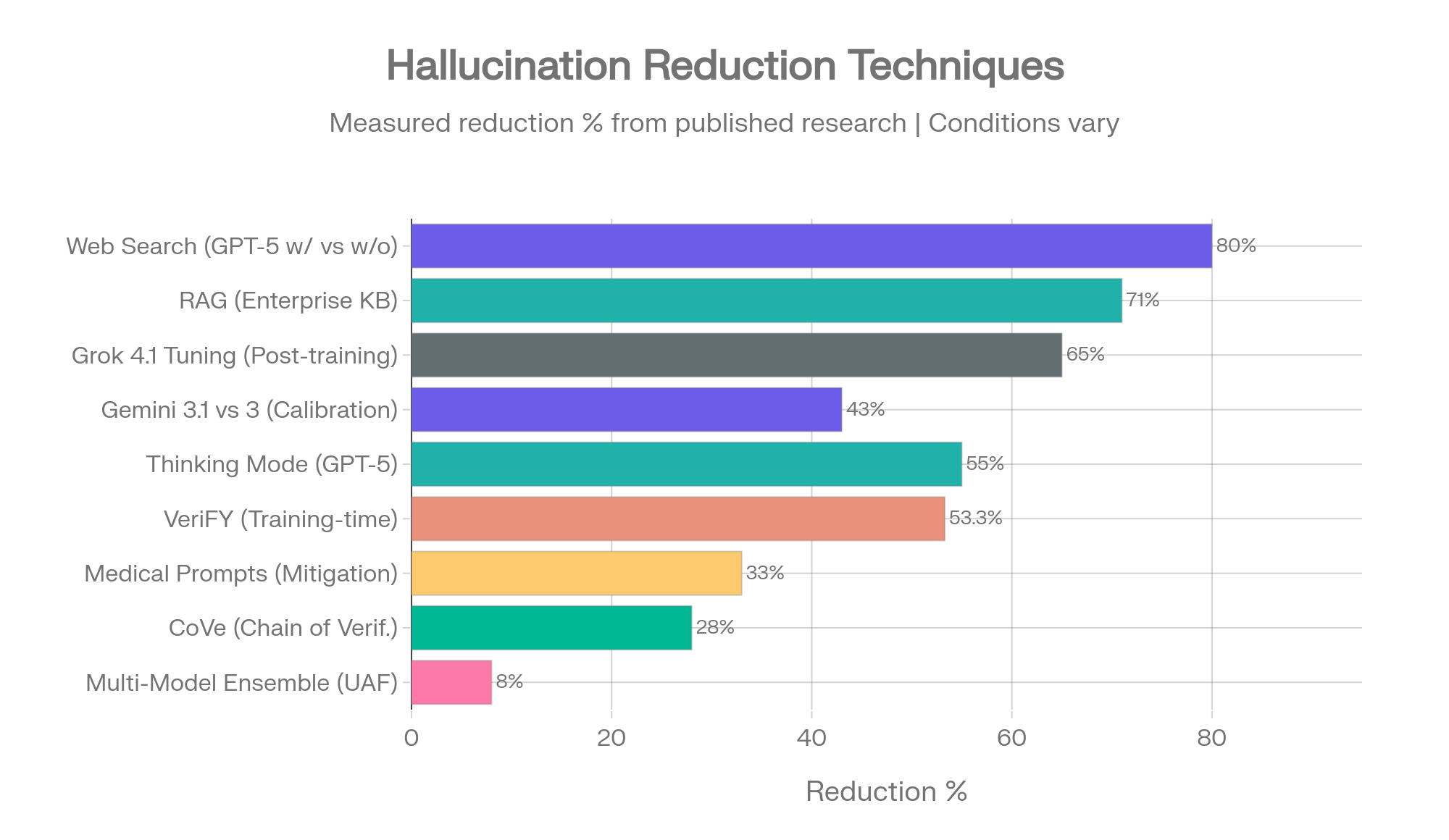
Hallucination reduction techniques ranked by measured impact. Sources: OpenAI [8][11], AllAboutAI [31], HealthBench [52], UAF [24], CoVe [23], VeriFY [25], Gemini 3.1 [15], MedRxiv [40]
Measured impact: 73-86% hallucination reduction (FActScore, browse-on vs browse-off)
The single highest-impact intervention documented in 2025-2026 research. GPT-5 drops from 47% to 9.6% hallucination with web access. The o4-mini drops from 37.7% to 5.1%. GPT-5.3 Instant shows 26.8% reduction when using web vs prior models. [8][11][10]
The mechanism is simple: instead of relying on potentially stale or incorrect training data, the model retrieves current information and grounds its response in external sources. For any enterprise deployment, enabling web or tool access should be the first configuration decision, not an afterthought.
Measured impact: Up to 71% reduction on enterprise knowledge base tasks [31]
RAG connects models to external knowledge bases — company documents, databases, verified sources — and instructs the model to generate responses grounded in retrieved content rather than parametric memory. Hybrid retrievers combining sparse and dense methods achieve the strongest mitigation.
RAG is most effective for knowledge-gap hallucinations (the model lacks relevant training data). It's less effective for logic-based hallucinations (the model reasons incorrectly from correct premises). For enterprise document Q&A and knowledge base applications, RAG is the standard of care.
Measured impact: 55-75% reduction on open-ended medical and factual tasks; increases hallucination on grounded summarization [52]
GPT-5 thinking mode: HealthBench drops from 3.6% to 1.6%. Production ChatGPT traffic: 4.8% of responses contain major incorrect claims vs 11.6% without thinking. These are significant improvements.
But reasoning mode increases hallucination on Vectara's summarization benchmark (see Section 10). The impact is task-dependent. Enable reasoning for analysis, diagnosis, and complex queries. Disable it for summarization, extraction, and source-faithful tasks.
Measured impact: 8% accuracy improvement over single-model approaches (UAF framework) [24]
Amazon's Uncertainty-Aware Fusion framework (published ACM WWW 2025) combined multiple LLMs weighted by their accuracy and self-assessment quality. The key finding: different models excel on different question types, so combining them captures complementary strengths.
Cross-model disagreement detection catches hallucinations because models rarely fabricate the same false information. When one model makes an unsupported claim, others typically flag the inconsistency or provide conflicting data. Research on "wisdom of the silicon crowd" shows LLM ensembles can rival human crowd forecasting accuracy through simple aggregation.
The 8% figure understates the practical value. In production, multi-model approaches catch errors that no single-model check would flag — because the checking model has different training data, different biases, and different blind spots.
Measured impact: 28% FActScore improvement [23]
A four-step pipeline: generate baseline response, plan verification questions, answer those verification questions independently, then refine the final output. Published at ACL 2024, it outperforms zero-shot, few-shot, and chain-of-thought prompting on long-form generation accuracy.
The cost is latency and compute: four steps instead of one. For applications where accuracy matters more than speed — report generation, research synthesis, compliance documentation — the tradeoff is worth it.
Measured impact: 9.7-53.3% hallucination reduction across model families [25]
Published at ICML 2025, VeriFY teaches models to assess factual uncertainty during generation rather than relying on post-hoc checking. The model learns to verify its own claims as it produces them. Recall loss is modest: 0.4-5.7%.
This is a training-time intervention, meaning end users don't control it. Its value is in signaling where the field is heading: future model generations will likely internalize verification as a core capability rather than bolting it on after generation.
Measured impact: 38 percentage point AI hallucination reduction (Gemini 3.1 Pro, 88% to 50%) with only 1% accuracy loss [15]
Google demonstrated that tuning a model's calibration — its ability to match confidence to actual accuracy — can dramatically reduce hallucination without sacrificing knowledge. Gemini 3.1 Pro's Omniscience Index jumped from 16 to 33 with this approach.
Like VeriFY, this is a provider-side intervention. Users benefit from it when selecting newer model versions but can't apply it themselves.
Measured impact: 33% reduction on medical tasks (64.1% to 43.1%); GPT-4o dropped from 53% to 23% [40]
Structured prompts that instruct the model to constrain outputs to verified information, flag uncertainty, and avoid speculation. These work best in narrow domains with clear boundaries and well-defined terminology.
The medical results are encouraging but the absolute rates remain high (43.1% with mitigation is still dangerously wrong for clinical use). Domain prompts are a layer, not a solution.
Larger models alone: Accuracy correlates with model size. Hallucination rate does not. Bigger models know more but don't necessarily know what they don't know.
Simple temperature reduction: Lowering generation temperature reduces variety but doesn't eliminate hallucination. The model still picks the most probable token — it just does so more consistently, including consistently wrong tokens.
"Be accurate" system prompts: Generic instructions to avoid hallucination show minimal measured effect. Models already "try" to be accurate. The issue is architectural, not motivational.
Web search and RAG you already run. The next measured reduction is models catching each other - the mechanism the production data below documents across 1,324 real conversations.
Try Cross-Validation Free7 days free. No credit card. About twenty seconds to the first answer.
Research published across 2024-2026 increasingly converges on a specific finding: querying multiple AI models on the same question catches errors that single-model approaches miss. This isn't a theoretical argument. Multiple peer-reviewed studies provide measured evidence.
The Uncertainty-Aware Fusion (UAF) framework combines multiple LLMs weighted by two factors: each model's accuracy on the task and each model's ability to self-assess when it's uncertain. The measured result: 8% accuracy improvement over any individual model. [24]
The critical insight from the study: "LLMs' accuracy and self-assessment capabilities vary widely with different models excelling in different scenarios." No single model dominates all question types. GPT may be strongest on grounded tasks, Claude on knowledge-calibration tasks, Gemini on breadth-of-knowledge tasks. The ensemble captures all three strengths.
Models trained on different data, with different architectures and different alignment tuning, develop different failure patterns. When five models analyze the same question, they rarely fabricate the same false information.
One model claims a legal precedent exists. Four others don't mention it. That disagreement is a signal. A human reviewer can investigate the specific claim rather than reviewing the entire output.
This works because hallucinations are stochastic, not systematic. A model doesn't consistently hallucinate the same incorrect fact — it fills gaps with different plausible-sounding content each time. When multiple models fill the same gap with conflicting content, the gap becomes visible.
Multiple studies show that simple aggregation across LLM outputs can rival the accuracy of human crowd forecasting. The mechanism parallels Galton's ox-weight experiment and Surowiecki's "Wisdom of Crowds" — individual estimates are biased, but the aggregate cancels out uncorrelated errors. [28]
For AI, this means: five models with 60% individual accuracy, with uncorrelated errors, can produce aggregate outputs significantly above 60% accuracy. The math favors diversity over individual excellence.
The academic findings above describe the mechanism. The Suprmind Multi-Model Divergence Index measures it in the wild. [61][62]
The dataset: 1,324 multi-model conversation turns from 299 real users across 10 domains over 45 days (March 5 to April 19, 2026). Five frontier models (GPT, Claude, Gemini, Grok, Perplexity) responding to the same questions, with each model reading what came before. After every turn, a classifier records what happened between the models: contradictions, corrections, and unique insights. [61]
What the DMI measures, and what it does not. The index tracks disagreement and correction behavior. It does not measure which model is factually correct in any given exchange. A model being contradicted is a detection signal, not a verdict. The DMI complements accuracy benchmarks like Vectara and AA-Omniscience; it does not replace them.
Across all 1,324 turns, 99.1% produced at least one contradiction, correction, or unique insight that came only from a model other than the first responder. The "silent agreement" rate — turns where every model agreed without surfacing anything new — was 0.9%. In five of the ten domains tracked (Legal, Medical, Education, Research, Creative), the silent rate was zero. [61]
A single-model query would have missed something on 99 out of 100 of these turns. Whether what was missed was factually critical varies. That something was missed is not in dispute.
The MIT research cited earlier on this page found that AI models are 34% more confident when they're wrong than when they're right. The DMI data shows the same pattern in live multi-model conversations: a high-confidence answer (self-rated 7+ out of 10) is no shield against being contradicted by another model.
| Model (high-confidence answers) | Contradicted or corrected by another model |
|---|---|
| Gemini | 51.4% |
| Grok | 48.9% |
| GPT | 39.6% |
| Perplexity | 33.9% |
| Claude | 33.9% |
Source: Suprmind Multi-Model Divergence Index, April 2026 edition [61]
Across all five providers, between one in three and one in two confidently-stated answers had a substantive issue caught by a peer model. On high-stakes turns specifically, Claude's rate dropped to 26.4% — the lowest of the five — while Gemini's barely moved (50.3%). [61]
This is not a hallucination rate. It is a peer-review catch rate. But the implication for single-model use is direct: confidence in one model's answer, absent any external check, is the most common failure mode in the data. This pattern aligns with the Stanford AI Index 2026 finding above: when false statements are framed as something the user believes, single-model accuracy collapses. The multi-model review mechanism captures this failure mode because a second model, not anchored to the first model's overconfident framing, applies its own baseline to the same claim. [58][61]
Each model in the DMI dataset has a "catch ratio": corrections it made of others, divided by corrections it received from others. A ratio above 1.0 means the model catches more than it gets caught.
| Provider | Catches made | Times caught | Catch ratio |
|---|---|---|---|
| Perplexity | 335 | 132 | 2.54 |
| Claude | 304 | 135 | 2.25 |
| Grok | 193 | 269 | 0.72 |
| GPT | 111 | 295 | 0.38 |
| Gemini | 109 | 416 | 0.26 |
Source: Suprmind Multi-Model Divergence Index, April 2026 edition [61]
Perplexity catches roughly ten times more often than Gemini does. This is not a ranking of which model is "best" — Perplexity's edge comes partly from its search-grounded architecture, which gives it a structural advantage at flagging unsupported claims. The point is that the catching is not random. Different architectures produce different catch profiles, which is exactly what the multi-model thesis predicts. [61]
Disagreement rate by domain, ranked highest to lowest:
| Domain | Multi-model turns | Turns with disagreement |
|---|---|---|
| Financial | 258 | 72.1% |
| Other | 153 | 59.6% |
| Marketing & Sales | 131 | 55.0% |
| Business Strategy | 257 | 54.9% |
| Research Analysis | 74 | 52.7% |
| Technical | 172 | 49.4% |
| Creative | 38 | 42.1% |
| Legal | 135 | 41.5% |
| Medical | 56 | 33.9% |
| Education | 49 | 28.6% |
Source: Suprmind Multi-Model Divergence Index, April 2026 edition [61]
Financial questions produce model disagreement on nearly three out of four turns. Education questions produce it on roughly one in four. The high-stakes domains where this page documented the worst hallucination consequences — financial, legal, medical — are the same domains where running questions through more than one model surfaces the most divergence. Research Analysis specifically: 52.2% of contradictions in that domain were classified critical-severity (7+ on a 10-point scale), the highest critical share of any domain. When models disagree on research questions, they tend to disagree about something that matters. [61]
The academic research established that ensembles outperform individual models. The DMI shows the detection mechanism activating in real production usage — not in benchmarks designed for it, not in lab conditions, but in live conversations with paying users on real questions. The mechanism the research predicts is the mechanism the production data shows.
The remaining honest caveat from the section above still holds: cross-validation raises detection probability, it does not guarantee zero hallucination. Two findings in this dataset reinforce that point. First, models do still occasionally agree on the same wrong answer — the DMI does not catch shared training-data errors. Second, the DMI counts contradictions and corrections, not their resolutions. Knowing that two models disagreed is not the same as knowing which one was right.
The disagreement is the signal; the verification is still the user's job.
Catches well:
Catches less well:
Multi-model validation is a detection layer, not a guarantee. It raises the probability of catching hallucinations. It doesn't eliminate them. The organizations getting the best results combine multi-model cross-validation with domain-specific verification, human review checkpoints, and tool-enabled grounding. [27]
There is still limited standardized public reporting measuring "five-model cross-validation reduces hallucination by X%" across domains under controlled conditions. The UAF framework's 8% improvement is the strongest single number. Production case studies from multi-model platforms are emerging but not yet published in peer-reviewed venues.
The safest evidence-based position: multi-model orchestration is a risk-reduction architecture that increases detection probability. It is not a guarantee of zero hallucination. No approach achieves that guarantee — as the mathematical proofs in Section 11 demonstrate.
Ask something where accuracy matters. Watch five AI models respond — and see where they disagree.
Open the PlaygroundThe hallucination detection market grew 318% from 2023 to 2025, with $12.8 billion invested in dedicated solutions. This growth rate reflects how seriously enterprises take the problem — and how inadequate built-in model guardrails are for production use. [35]
| Tool | Detection Accuracy | Key Strength |
|---|---|---|
| W&B Weave | 91% | Chain-of-thought reasoning, production pipeline integration |
| Arize Phoenix | 90% | Label-based outputs, confidence scoring, real-time monitoring |
| Comet Opik | 72% | 100% precision (zero false positives), conservative approach |
| Galileo | N/A | Hallucination Index scoring, real-time blocking, CI/CD integration |
| GPTZero Citation Check | 99%+ | Verified citations against web/academic databases |
| Future AGI | N/A | RAG-specific hallucination detection, experiment monitoring |
| Pythia | N/A | Knowledge graph-based fact-checking, regulated industries |
Sources: AIMultiple benchmark (2026) [46], Future AGI (2025) [47], GPTZero/Fortune [45]
The top detection tools catch 90-91% of hallucinations. That means roughly 1 in 10 hallucinated outputs still passes undetected through the best available automated checking. For applications where a single undetected hallucination has material consequences — legal filings, medical decisions, financial reporting — automated detection is a necessary layer but not a sufficient one.
Comet Opik's approach is worth noting separately. At 72% detection accuracy, it catches fewer hallucinations. But it has 100% precision — zero false positives. It never flags a correct statement as hallucinated. For workflows where false alarms are costly (interrupting a doctor mid-diagnosis, flagging a correct legal citation for review), this tradeoff may be preferable.
| Year | Best Hallucination Rate | Context |
|---|---|---|
| 2021 | ~21.8% | Early GPT-3 era |
| 2022 | ~15.0% | RLHF alignment improvements |
| 2023 | ~8.0% | GPT-4 launch and competitive pressure |
| 2024 | ~3.0% | Rapid iteration across all providers |
| 2025 | 0.7% | Gemini-2.0-Flash on Vectara original dataset |
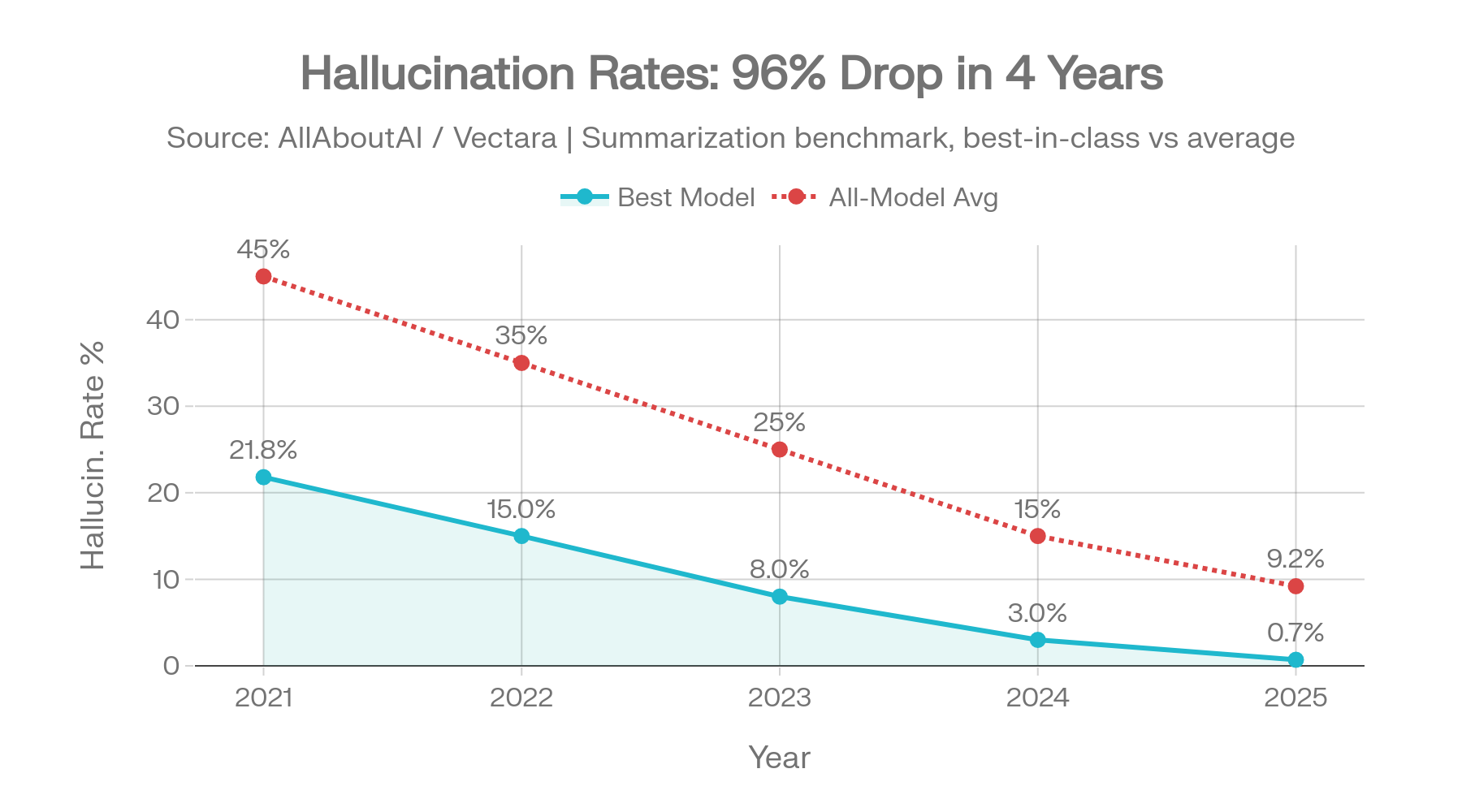
Four years of hallucination improvement on simple summarization tasks: 21.8% → 0.7%. Sources: Vectara [1], AllAboutAI [31]
That's a 96% reduction in best-model hallucination rates over four years on the Vectara summarization benchmark. The trend line is real and it's steep.
These improvements measure the easiest version of the problem: summarizing short documents without adding unsupported facts. When you move to harder, more realistic evaluations, the picture changes:
AA-Omniscience (hard knowledge questions): 36 out of 40 models are more likely to give a confident wrong answer than a correct one. Only four models achieved a positive Omniscience Index. [2]
HalluHard (realistic conversations): Even the best model (Claude Opus 4.5 with web search) hallucinates 30% of the time. Most models fall in the 50-70% range. [5]
Vectara new dataset (enterprise-length documents): Rates jump 3-10x compared to the original dataset. The best score is 3.3%, not 0.7%. [1]
Domain-specific tasks: Legal hallucination averages 18.7%. Medical averages 15.6%. These haven't shown the same improvement trajectory as general summarization. [31]
Improvement is real. But extrapolating from simple benchmarks to enterprise reliability is a mistake the data doesn't support.
This page draws from the following primary sources:
Benchmarks: Vectara HHEM Leaderboard (both the original ~1,000 document dataset and the refreshed 7,700-article dataset), Artificial Analysis AA-Omniscience, Google DeepMind FACTS Benchmark, OpenAI SimpleQA and PersonQA, HalluHard (Swiss-German research consortium), and the Columbia Journalism Review citation accuracy study.
System cards and technical reports: OpenAI GPT-5 system card, GPT-5.2 deployment update, o3/o4-mini system card, Anthropic model announcements for Claude Opus 4.5/4.6 and Sonnet 4.6, Google DeepMind FACTS methodology paper.
Industry studies and incident data: Stanford RegLab/HAI legal AI study, MedRxiv medical hallucination research, Deloitte Global AI Survey, Forrester enterprise AI cost analysis, AllAboutAI hallucination statistics compilation, Business Insider court ruling tracker, Damien Charlotin legal citation hallucination database, and the GPTZero/Fortune NeurIPS 2025 analysis.
Academic research: Xu et al. (2024) on impossibility of hallucination elimination, Karpowicz (2025) on mathematical impossibility across three proof frameworks, Amazon/ACM WWW 2025 Uncertainty-Aware Fusion framework, ICML 2025 VeriFY training-time verification, ACL 2024 Chain-of-Verification.
April 2026 additions: Stanford HAI 2026 AI Index Report (sycophancy benchmark and AI incident database), Vectara HHEM April 20, 2026 snapshot, Artificial Analysis AA-Omniscience April 2026 state (Claude Opus 4.7, GPT-5.5, Grok 4.20), Damien Charlotin database (1,200+ legal cases), OpenAI HealthBench Professional, and the Suprmind Multi-Model Divergence Index April 2026 edition.
June 2026 additions: Artificial Analysis AA-Omniscience figures for Claude Opus 4.8 (released May 28, 2026), Gemini 3.5 Flash (May 18, 2026), Grok 4.3 (April 30, 2026), and DeepSeek V4 Pro and V4 Flash (April 24, 2026), plus Muse Spark (Meta, April 2026) on HealthBench Hard. One caveat applies to Gemini 3.5 Flash: Google did not publish a first-party hallucination figure for it, so the 61% rate cited here is Artificial Analysis independent measurement, not a vendor number. [64][68]
This page now includes data from the Suprmind Multi-Model Divergence Index (DMI), a quarterly publication tracking inter-model disagreement and correction patterns in real production usage of the Suprmind platform. The April 2026 edition covers 1,324 multi-model conversation turns from 299 users across 10 domains over a 45-day window (March 5 to April 19, 2026). [61][62]
What the DMI measures: how often AI models contradict each other, correct each other, and surface insights missed by other models when run together on the same question.
What the DMI does not measure: factual accuracy against ground truth. The DMI records that one model contradicted another. It does not adjudicate which model was correct. Disagreement is treated as a detection signal, not as a verdict on accuracy.
We treat DMI data and accuracy benchmarks as complementary, not interchangeable. Vectara, AA-Omniscience, FACTS, and the other benchmarks on this page measure how often models are wrong in isolation. The DMI measures how often models catch each other in production. Both questions matter. They are not the same question.
The DMI dataset, methodology, and all twelve underlying CSV files are publicly available at the page linked in the references. Internal-account data is excluded; the published dataset is external users only.
Update cadence: quarterly. Next edition: July 2026.
TruthfulQA — partially saturated. Included in model training data, contains some incorrect gold answers, and can be gamed to 79.6% accuracy by a decision tree that never sees the question.
HaluEval — solvable by answer length. A classifier that flags answers over 27 characters as hallucinated achieves 93.3% accuracy, undermining the benchmark's validity for model comparison.
Unverified community benchmarks — Reddit posts, Twitter claims, and blog articles citing benchmark numbers without methodology documentation or reproducibility information were excluded unless they could be cross-referenced against primary sources.
Vendor marketing claims — where a provider claims a specific hallucination rate but independent benchmarks show different numbers, both are presented with the discrepancy noted. This applies particularly to xAI's internal Grok benchmarks versus AA-Omniscience results.
Vectara snapshots are dated. The original dataset was evaluated through April 2025. The refreshed dataset covers November 2025 through February 2026, with the most recent snapshot dated February 25, 2026. AA-Omniscience launched November 2025 and has been updated as new models release. FACTS was published December 2025. OpenAI system cards are dated per release.
When two benchmarks show different numbers for the same model, this usually reflects different evaluation dates, different dataset versions, or different aspects of factuality being measured. We flag these discrepancies rather than averaging them.
Perplexity Sonar models are not listed on AA-Omniscience or Vectara. Perplexity uses underlying models (including GPT and DeepSeek variants) making hallucination attribution complex. Their SimpleQA and Search Arena results are included where available.
Claude Opus 4.6 and Sonnet 4.6 were released in February 2026. AA-Omniscience data is appearing but early. Vectara new-dataset scores are not yet available for the 4.6 generation.
GPT-5.3 has AA-Omniscience data (51.8% accuracy for Codex variant) but limited coverage on other benchmarks as of this writing.
Domain-specific breakdowns for most benchmarks test general knowledge. Industry-specific hallucination data (financial, medical, legal) comes primarily from specialized studies rather than the major leaderboards.
Business cost figures come from surveys and estimates rather than verified incident databases. The $67.4 billion figure, the per-employee verification costs, and the per-incident ranges should be treated as indicative rather than precise.
Monthly: Vectara leaderboard snapshots, AA-Omniscience new model additions, OpenAI system card updates, new model release data.
Quarterly: FACTS leaderboard changes, new benchmark introductions, academic paper findings, regulatory developments (particularly EU AI Act enforcement related to accuracy requirements).
As needed: Major model releases, significant incident reports, court ruling milestones, and changes to benchmark methodology.
An AI hallucination rate measures how often a model generates false or fabricated information presented as fact. The rate varies by benchmark because different tests measure different failure modes. Vectara measures how often a model adds invented facts when summarizing a document. AA-Omniscience measures how often a model gives a confident wrong answer instead of admitting it doesn't know. FACTS measures factuality across four dimensions: grounding, multimodal, parametric knowledge, and search. A model can score 0.7% on Vectara and 88% on AA-Omniscience simultaneously because the tests measure completely different things.
There is no single answer - it depends entirely on the task. On knowledge questions where the model must admit ignorance: Claude 4.1 Opus achieved 0% hallucination on AA-Omniscience by refusing to answer rather than guessing. On document summarization: Gemini-2.0-Flash leads the Vectara original dataset at 0.7% hallucination rate. On multi-dimensional factuality: Gemini 3 Pro scored 68.8 on the FACTS benchmark. On realistic conversational tasks: Claude Opus 4.5 achieved 30% on HalluHard with web search enabled. No single model leads across all benchmarks.
Claude's hallucination rate varies significantly by model version and benchmark. Claude Opus 4.8 (current flagship, May 2026): 46.6% accuracy on AA-Omniscience with a 35.9% hallucination rate and an Omniscience Index of 27, second only to Gemini 3.1 Pro. Claude Opus 4.7 (prior flagship): 36% hallucination, Omniscience Index 26. Claude 4.1 Opus: 0% hallucination on AA-Omniscience (refuses rather than guesses), FACTS score 46.5. Claude Opus 4.6: 12.2% on Vectara new dataset, 46.4% accuracy on AA-Omniscience, Omniscience Index 14. Claude Opus 4.5: 45.7% accuracy on AA-Omniscience with 58% hallucination rate, FACTS score 51.3, 30% on HalluHard. Claude Sonnet 4.6: 10.6% on Vectara new dataset, approximately 38% hallucination rate on AA-Omniscience. Claude 4.5 Haiku: 25% hallucination rate on AA-Omniscience, third lowest of any model tested. On the harder Vectara new dataset, Claude models consistently exceed 10%.
GPT-5.3 Codex: 51.8% accuracy on AA-Omniscience, no Vectara data yet. GPT-5.2 (xhigh): 10.8% on Vectara new dataset, 43.8% accuracy on AA-Omniscience with approximately 78% hallucination rate, FACTS score 61.8, HalluHard 38.2%. GPT-5: 1.4% on Vectara original, over 10% on new dataset, 40.7% accuracy on AA-Omniscience. GPT-4.1: 2.0% on Vectara original, 5.6% on new, FACTS score 50.5. GPT-5.2 scores highest among OpenAI models on FACTS (61.8) but hallucinates at approximately 78% on AA-Omniscience hard knowledge questions.
Grok 4.3 (April 30, 2026): approximately 49% accuracy and 26% hallucination on AA-Omniscience, roughly 8 points better on both axes than the prior Grok 4.20 release. Grok 4.20 (0309 v2) remains the lowest-hallucination Grok at 17%. Grok 4: 4.8% on Vectara original, over 10% on new dataset, 41.4% accuracy on AA-Omniscience with 64% hallucination rate, FACTS score 53.6. Grok 4.1 Fast Reasoning: 20.2% on Vectara new dataset (highest of any frontier model tested), 72% hallucination rate on AA-Omniscience, FACTS score 36.0. Grok-3: 2.1% on Vectara original, 5.8% on new, 94% citation hallucination on CJR. The Grok 4.1 Fast Reasoning variant performs notably worse than base Grok 4, suggesting the reasoning mode adds inferences that become hallucinations on factual tasks.
Gemini 3.1 Pro: 10.4% on Vectara new dataset, 55.3% accuracy on AA-Omniscience (highest of any model) with 50% hallucination rate, Omniscience Index 33 (highest overall). Gemini 3.5 Flash (May 2026): 61% hallucination on AA-Omniscience by independent measurement, a 31-point improvement over Gemini 3 Flash's 92%, though Google did not publish a first-party hallucination figure for it. Gemini 3 Pro: 13.6% on Vectara new, 55.9% accuracy but 88% hallucination on AA-Omniscience, FACTS score 68.8 (highest overall). Gemini 2.0 Flash: 0.7% on Vectara original (lowest of any model), 3.3% on new dataset. The 3.1 Pro update was significant: hallucination dropped from 88% to 50% with only 1% accuracy loss. Gemini models know the most but fabricate the most aggressively when uncertain.
Perplexity Sonar Pro scored 37% citation hallucination on the Columbia Journalism Review benchmark - the lowest of any model tested, but still meaning more than one in three cited sources contained fabricated claims. ChatGPT hit 67% on the same test. Gemini hit 76%. Grok-3 reached 94%. Perplexity's failure mode is uniquely dangerous: the URLs it cites are real, but the information it attributes to those sources is sometimes fabricated. No Vectara or AA-Omniscience benchmark data exists for Perplexity Sonar models.
Different benchmarks measure fundamentally different failure modes. Vectara tests summarization faithfulness. AA-Omniscience tests knowledge calibration. FACTS tests multi-dimensional factuality across grounding, multimodal, parametric, and search tasks. CJR tests citation accuracy. A model like Grok-3 scores 2.1% on Vectara (sticks to source documents well) but 94% on CJR (fabricates nearly every citation). Both numbers are accurate. They measure different skills. The responsible approach: cross-reference at least two benchmarks measuring different things, specify the exact model version and settings, and note whether web search or reasoning mode was enabled.
No. Two independent mathematical proofs have demonstrated that hallucination is a fundamental limitation of the language model architecture. It is not an engineering problem awaiting a fix. Best-case hallucination rates have dropped from 21.8% to 0.7% over four years on simple summarization tasks. But on harder tasks - legal questions (18.7% average), medical queries (15.6%), knowledge questions requiring the model to rely on its own training data - rates remain high across all models. The research community has shifted from eliminating hallucinations to managing hallucination risk through detection, flagging, containment, and cross-validation. Web search access is the single biggest reducer, cutting hallucination rates 73-86% when enabled.
Global business losses from AI hallucinations reached an estimated $67.4 billion in 2024. 47% of business executives reported making major decisions based on unverified AI-generated content. 66% of users rely on AI output without evaluating its accuracy. There are 944+ documented legal cases involving AI-generated false information. Domain-specific costs range from $18,000 per customer service incident to $2.4 million in healthcare malpractice cases. The FDA has authorized over 1,350 AI-enhanced medical devices, with 60 devices involved in 182 recalls.
Research increasingly supports this. Different AI models rarely hallucinate the same false information because they have different training data, different architectures, and different blind spots. A UAF framework study measured 8% accuracy improvement through multi-model ensemble approaches. Cross-model disagreement catches fabrications specifically because the failure modes don't overlap. When three models analyze the same question and two disagree with the third, the disagreement itself is a signal that a claim needs human review. This is the principle behind multi-AI orchestration platforms that route questions to multiple frontier models simultaneously. See how Suprmind uses this approach →
Five frontier models. One conversation. Every answer cross-checked. See why professionals who can't afford to be wrong are switching to multi-model validation.
Select Your Plan -->


