




For decision-makers, the cost of a wrong AI-assisted answer isn’t a bad paragraph – it’s a lawsuit, a failed deal, or a missed diagnosis. Modern LLMs are capable and fallible. Hallucinations, bias, and brittle prompts can slip into high-stakes work where “probably right” is unacceptable.
A safety operating model combines governance, robust evaluation, and multi-model orchestration to surface disagreements and validate outcomes before they matter. This guide provides a complete safety stack, measurable controls, and actionable frameworks you can implement tomorrow.
Written by practitioners building and using multi-AI orchestration for regulated, high-stakes workflows, this resource grounds every recommendation in current standards and real evaluation practices.
Understanding the AI Safety Landscape
AI safety prevents, detects, and mitigates harms while ensuring predictable, aligned behavior across the entire lifecycle. It’s not a single feature or checkbox – it’s an integrated operating system spanning design, data, training, inference, monitoring, and incident response.
The field addresses four distinct risk categories that require different controls and measurement approaches:
- Input and data risks: biased training sets, unrepresentative samples, privacy leakage, and labeling errors that corrupt model behavior from the start
- Model risks: hallucinations, calibration failures, adversarial vulnerabilities, and alignment gaps that emerge during training and fine-tuning
- Output risks: factual errors, compliance violations, harmful content, and ungrounded claims that reach end users
- Operational risks: model drift, versioning chaos, undocumented decisions, and missing audit trails that undermine reproducibility
AI safety intersects with but differs from adjacent disciplines. Security protects systems from unauthorized access and attacks. Ethics addresses moral implications and societal impact. Governance establishes policies, accountability structures, and compliance frameworks. All four must work together – a secure system can still produce biased outputs, and ethical guidelines mean nothing without operational controls to enforce them.
The Lifecycle Lens
Safety concerns manifest differently at each stage. During design, teams define acceptable behavior boundaries and failure modes. In the data phase, representativeness and privacy controls prevent downstream bias. Training introduces alignment techniques and robustness measures. At inference, guardrails and grounding mechanisms catch errors in real time. Monitoring detects drift and anomalies. Incident response closes the loop when issues escape earlier controls.
This lifecycle view ensures safety isn’t bolted on at the end but embedded from the first requirement through production operations.
Mapping Risks to Actionable Controls
Abstract risk categories become manageable when you map each one to specific metrics, controls, and tools. The following framework turns safety from philosophy into practice.
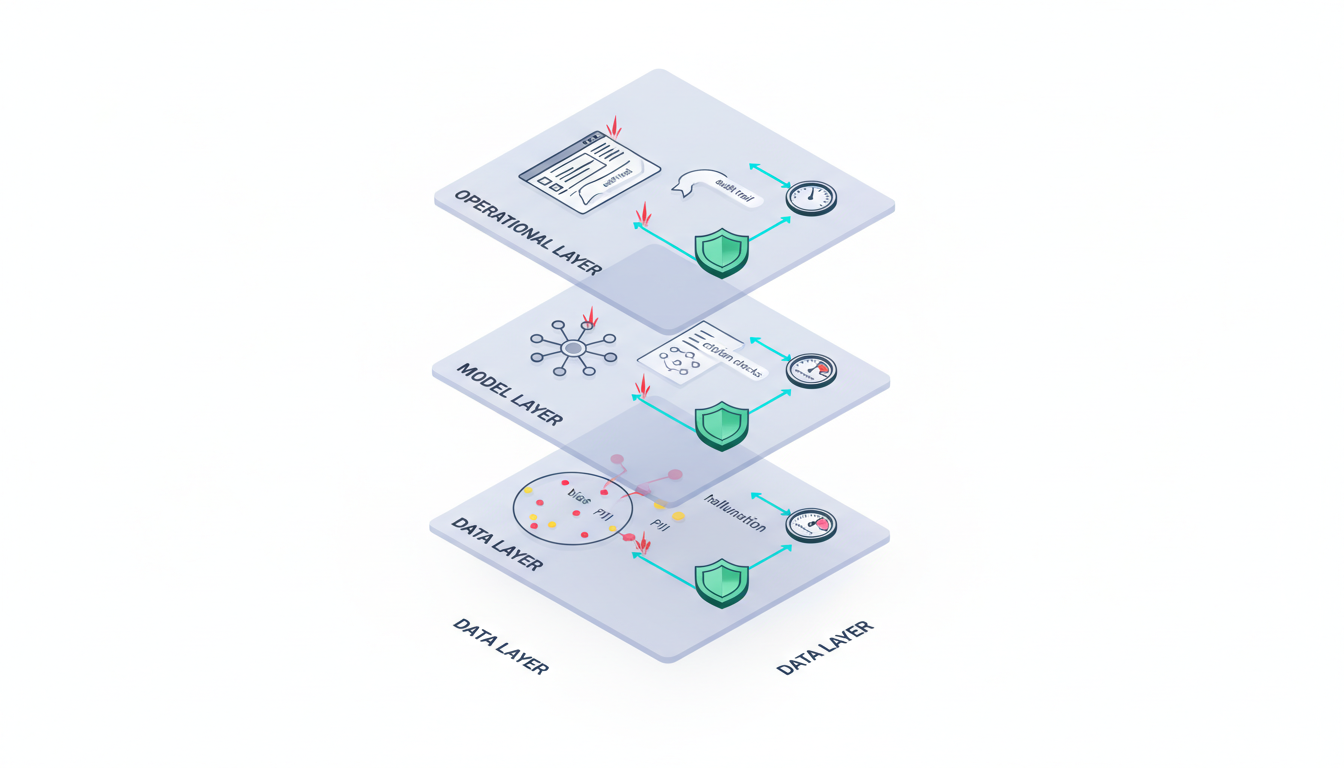
Data Layer Controls
Risks: unrepresentative training data, labeling quality issues, personally identifiable information (PII) leakage, and demographic imbalances that bake in bias.
Controls and tools:
- Data audits with statistical representativeness checks across protected attributes
- Privacy filtering pipelines that detect and redact PII before training
- Synthetic data generation to balance underrepresented groups
- Labeling quality scores with inter-annotator agreement thresholds
- Data cards documenting provenance, limitations, and known biases
Measurable outcomes: demographic parity scores, PII detection recall rates, and labeling consistency metrics above 0.85 agreement.
Model Layer Controls
Risks: hallucinations, uncalibrated confidence, adversarial prompt vulnerabilities, and alignment drift where models pursue unintended objectives.
Controls and tools:
- Red teaming with structured adversarial test suites targeting known failure modes
- Calibration checks comparing predicted confidence to actual accuracy
- Adversarial training exposing models to edge cases during fine-tuning
- Guardrails that reject prompts or outputs violating policy boundaries
- Model cards documenting intended use, known limitations, and performance across subgroups
Measurable outcomes: hallucination rates below 2%, calibration error under 0.05, and adversarial prompt success rates under 10%.
Output Layer Controls
Risks: factual errors, legal compliance violations, harmful content generation, and ungrounded claims that damage trust or create liability.
Controls and tools:
- Retrieval-augmented generation (RAG) grounding outputs in verified sources
- Policy filters blocking regulated content categories
- Human-in-the-loop review for high-stakes decisions
- Citation validation checking that references exist and support claims
- Confidence thresholds triggering escalation when uncertainty exceeds limits
Measurable outcomes: citation validity rates above 95%, policy violation detection recall above 98%, and abstention rates appropriate to task criticality.
Operational Layer Controls
Risks: model drift degrading performance over time, versioning confusion, undocumented prompt changes, and missing audit trails that prevent reproducibility.
Controls and tools:
- Continuous monitoring dashboards tracking accuracy, latency, and drift metrics
- Experiment tracking systems versioning prompts, models, and hyperparameters
- Audit logs capturing every decision with timestamps and provenance
- Incident response playbooks defining escalation paths and rollback procedures
- Automated alerts when metrics breach predefined thresholds
Measurable outcomes: drift detection within 24 hours, mean time to resolve (MTTR) incidents under 4 hours, and 100% audit trail coverage for regulated decisions.
Standards and Frameworks You Can Implement Today
Current guidance from standards bodies and regulatory signals provide actionable starting points. These aren’t theoretical – teams are implementing them in production systems right now.
NIST AI Risk Management Framework
The NIST AI RMF 1.0 organizes safety around four core functions: Govern, Map, Measure, and Manage. Govern establishes accountability and policies. Map identifies context and categorizes risks. Measure quantifies impacts and tracks metrics. Manage allocates resources and implements controls.
The framework’s profiles let you tailor controls to specific contexts. A legal research application needs different safeguards than a medical diagnostic tool, and NIST’s structure accommodates both without forcing one-size-fits-all checklists.
ISO/IEC 42001 AI Management System
ISO/IEC 42001 provides a certifiable management system for AI. It requires documented policies, risk assessment procedures, continuous improvement processes, and regular audits. Organizations pursuing certification demonstrate systematic safety practices that survive personnel changes and organizational shifts.
The standard’s emphasis on continual improvement aligns with the reality that AI systems evolve. Static controls become obsolete as models update, data distributions shift, and new attack vectors emerge.
Model Cards and Documentation Best Practices
Model cards document intended use cases, training data characteristics, performance across demographic groups, known limitations, and ethical considerations. They serve as both internal reference and external transparency mechanism.
Effective model cards answer five questions:
- What was this model designed to do (and not do)?
- What data trained it, and what biases does that introduce?
- How does performance vary across different user groups?
- What are the known failure modes and edge cases?
- What monitoring and retraining procedures maintain safety over time?
Data cards play a complementary role, documenting dataset composition, collection methodology, preprocessing steps, and known quality issues before they propagate into model behavior.
Regulatory Signals and Sector Expectations
The EU AI Act classifies systems by risk level and mandates controls proportional to potential harm. High-risk applications in healthcare, legal systems, and critical infrastructure face stricter requirements including human oversight, transparency, and conformity assessments.
Financial services regulators increasingly expect model risk management frameworks covering validation, ongoing monitoring, and governance. Healthcare applications must navigate HIPAA privacy requirements and FDA oversight for clinical decision support tools.
These regulatory developments aren’t distant threats – they’re shaping procurement requirements and vendor evaluations today.
Evaluation: Turning Claims Into Measurements
Safety without measurement is aspiration. Effective evaluation requires defining metrics, setting thresholds, and building test harnesses that produce repeatable results.
Truthfulness and Factual Accuracy
Grounded question answering tests whether outputs cite verifiable sources. Calculate the percentage of claims supported by provided references. For legal applications, verify that case citations exist, match the claimed jurisdiction, and actually support the legal proposition.
Hallucination rate measures fabricated information. Create test sets with known-correct answers and count how often the model invents facts. Rates above 2% become problematic for high-stakes work.
Citation validity goes beyond existence checks. Does the cited source say what the model claims? Does it apply to the current context? Manual spot-checking combined with automated reference verification catches most issues.
Robustness and Consistency
Adversarial prompt testing probes failure modes systematically. Build test suites targeting:
- Prompt injection attempts to override instructions
- Jailbreak patterns designed to bypass safety filters
- Edge cases with ambiguous or contradictory requirements
- Out-of-distribution inputs the model hasn’t seen during training
Track the adversarial success rate – the percentage of attacks that produce policy violations or incorrect outputs. Rates above 10% signal insufficient robustness.
Prompt variance stability tests whether semantically equivalent prompts produce consistent answers. Rephrase the same question five ways. If answers contradict each other, the model lacks stable behavior.
Bias and Fairness Metrics
Subgroup performance deltas measure whether accuracy varies across demographic groups. Calculate precision and recall separately for each protected attribute. Differences exceeding 5 percentage points warrant investigation and mitigation.
Disparate error rates reveal when mistakes disproportionately affect specific populations. A loan recommendation system that’s 95% accurate overall but only 85% accurate for a minority group fails fairness tests regardless of average performance.
Watch this video about ai safety:
Context matters. Legal research tools must maintain accuracy across jurisdictions. Medical literature reviews need consistent performance across disease categories and patient populations.
Calibration and Uncertainty Quantification
Calibration error compares predicted confidence to actual accuracy. If the model claims 90% confidence on 100 predictions, roughly 90 should be correct. Large gaps indicate the model doesn’t know what it doesn’t know.
Abstention rates measure how often the system refuses to answer when uncertain. Too many abstentions reduce utility. Too few risk presenting unreliable outputs as confident assertions. The right balance depends on task criticality.
For legal analysis, high abstention rates on edge cases beat confident wrong answers. For routine document classification, lower thresholds may be acceptable.
Operational Metrics
Time to detect drift measures how quickly monitoring systems identify degrading performance. Aim for detection within 24 hours of metrics breaching thresholds.
Incident MTTR (mean time to resolve) tracks how fast teams diagnose root causes, implement fixes, and restore safe operation. Four-hour resolution windows keep most incidents from escalating.
Audit trail completeness verifies that every decision includes timestamps, input data, model versions, and reasoning chains. Missing provenance breaks reproducibility and compliance.
Multi-Model Orchestration as a Safety Mechanism
Single-model systems amplify their blind spots and biases. Multi-model orchestration exposes disagreements, surfaces contradictions, and validates reasoning through structured interaction between diverse AI systems.
The AI Boardroom approach runs multiple models simultaneously through different orchestration modes, each serving specific safety objectives.
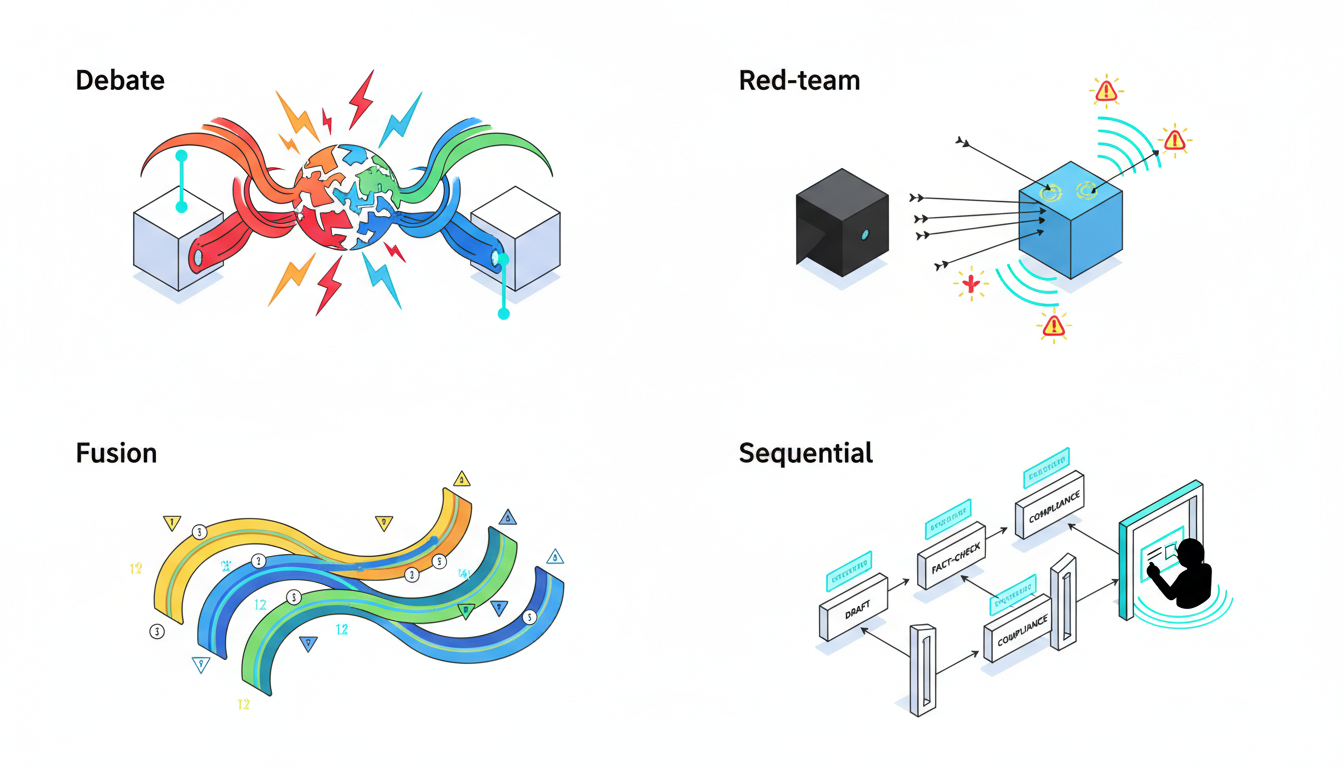
Red Team Mode for Systematic Probing
Red team mode assigns one model to generate adversarial prompts while others attempt to maintain safe, accurate behavior. This automated stress testing identifies failure modes before they appear in production.
Red team sessions target specific vulnerability categories:
- Instruction override attempts
- Privacy boundary violations
- Factual accuracy under misleading context
- Consistency across semantically equivalent inputs
The attacking model learns which prompts succeed, creating an evolving test suite that adapts as defenses improve. This arms race dynamic catches regressions that static test sets miss.
Debate Mode for Exposing Contradictions
Debate mode assigns models opposing positions on the same question. When models disagree, their arguments reveal assumptions, highlight missing evidence, and expose ungrounded claims.
For investment analysis, one model argues bull case while another presents bear thesis. Contradictions between them flag areas requiring human judgment or additional research. For due diligence, debate surfaces risks that single-model analysis might downplay or miss entirely.
The disagreement itself is valuable data. High consensus suggests robust conclusions. Persistent disagreement indicates genuine uncertainty that shouldn’t be hidden behind confident-sounding prose.
Super Mind mode for Traceable Synthesis
Super Mind mode combines multiple model outputs into a single coherent response while maintaining provenance. Each claim in the final output traces back to specific models and reasoning chains.
This transparency enables validation. When the fused output cites a legal precedent, you can verify which models identified it, what sources they used, and whether their interpretations align. Disagreements that survive fusion become explicit caveats rather than hidden assumptions.
Super Mind also enables ensemble calibration. Models that disagree on confidence levels produce more honest uncertainty estimates than any single model’s self-assessment.
Sequential Mode for Gated Reviews
Sequential mode chains models in a pipeline where each stage validates or refines the previous output. One model drafts, another fact-checks, a third reviews for policy compliance, and a human approves before release.
This staged approach catches errors early. A hallucination in the draft gets flagged during fact-checking rather than reaching the client. Policy violations trigger automatic escalation before anyone sees problematic content.
Sequential workflows also enforce separation of concerns. The creative generation model optimizes for completeness and relevance. The fact-checking model focuses solely on accuracy. The compliance model applies policy rules without worrying about fluency. Each specialist does one job well rather than compromising across competing objectives.
Persistent Context and Provenance
Safety requires reproducibility. Persistent context management maintains conversation history, decision rationale, and source attribution across sessions.
When an audit asks why a recommendation was made three months ago, complete context lets you reconstruct the reasoning chain. What data was available? Which models participated? What alternatives were considered? What uncertainties were flagged?
Relationship mapping traces how claims connect to sources, how sources relate to each other, and how conclusions depend on specific evidence. This graph structure makes validation systematic rather than ad hoc.
Operationalizing AI Safety: A 30-60-90 Day Plan
Turning concepts into practice requires a phased rollout with clear milestones, accountable owners, and measurable outcomes. This plan assumes a team with basic AI deployment experience starting from minimal safety infrastructure.
Days 1-30: Foundation and Assessment
Week 1: Define risk taxonomy and assign ownership
- Identify high-stakes use cases where errors create legal, financial, or reputational risk
- Map risks to the four-layer framework (data, model, output, operational)
- Assign RACI (Responsible, Accountable, Consulted, Informed) roles across product, legal, risk, and engineering teams
- Document current controls and identify gaps
Week 2: Adopt evaluation scorecard
- Select 5-8 metrics covering truthfulness, robustness, bias, and calibration
- Set initial thresholds based on task criticality (tighter for legal/medical, looser for low-stakes tasks)
- Build or procure test datasets with ground truth labels
- Establish baseline measurements on current systems
Weeks 3-4: Launch red team test harness
- Create adversarial prompt library targeting your specific domain (legal jailbreaks, financial manipulation attempts, medical misinformation)
- Run initial red team sessions and document success rates
- Prioritize top 3 vulnerabilities for immediate mitigation
- Schedule weekly red team runs to track improvement
Deliverables: risk register, evaluation scorecard with baselines, red team vulnerability report, RACI matrix.
Days 31-60: Implementation and Monitoring
Week 5-6: Implement orchestration-based validation
- Deploy debate mode on high-stakes decisions to surface disagreements
- Add Super Mind mode for synthesis with traceable provenance
- Configure sequential pipelines with fact-checking and compliance stages
- Train team on interpreting multi-model outputs and disagreement patterns
Week 7: Add monitoring and alerting
- Deploy dashboards tracking accuracy, latency, and drift metrics in real time
- Configure alerts for threshold breaches (hallucination rate > 2%, calibration error > 0.05, etc.)
- Establish on-call rotation for incident response
- Document escalation paths and rollback procedures
Week 8: Build incident playbooks
- Create postmortem template covering root cause, contributing factors, and corrective actions
- Define severity levels and response time SLAs
- Conduct tabletop exercise simulating a major incident
- Establish feedback loop from incidents to prompt refinement and policy updates
Deliverables: operational orchestration workflows, monitoring dashboards, incident playbooks, tabletop exercise report.
Days 61-90: Governance and Continuous Improvement
Week 9-10: Align with ISO/IEC 42001 framework
- Document AI management policies covering lifecycle stages
- Establish risk assessment procedures and review cadences
- Define roles and responsibilities for ongoing governance
- Create continuous improvement process incorporating incident learnings
Week 11: Automate reporting and audit preparation
- Build automated reports showing scorecard trends, incident summaries, and mitigation status
- Compile audit-ready documentation including model cards, data cards, and decision logs
- Verify 100% audit trail coverage for regulated decisions
- Generate compliance evidence package for relevant standards (NIST AI RMF, sector-specific regulations)
Week 12: Conduct end-to-end audit drill
- Simulate external audit requesting evidence of safety controls
- Test ability to reproduce past decisions from archived context and provenance
- Identify documentation gaps and remediate before real audits
- Present findings to executive stakeholders with roadmap for next 90 days
Deliverables: governance policy documentation, automated compliance reports, audit drill results, 90-day retrospective and forward plan.
Role-Specific Safety Patterns You Can Use Tomorrow
Generic checklists miss domain-specific risks. These tailored patterns address safety concerns unique to different professional contexts.
Legal Professionals
Citation verification controls:
- Validate that cited cases exist in official reporters
- Confirm jurisdiction matches the legal question
- Verify the case actually supports the stated proposition
- Check that precedent hasn’t been overruled or distinguished
- Cross-reference with Shepard’s or KeyCite for current validity
Jurisdictional policy filters prevent citing law from wrong jurisdictions. A California employment question shouldn’t reference Texas precedent unless explicitly comparing approaches.
Privilege controls ensure attorney-client communications and work product remain protected. Audit logs track who accessed sensitive material and when.
Conflict checking integrates with matter management systems to flag potential conflicts before analysis begins.
Investment Analysts and Financial Professionals
Source attribution for numerical claims:
- Every figure includes source, date, and calculation methodology
- Historical data points link to original filings or databases
- Projections clearly distinguish from actuals
- Assumptions underlying models are explicit and testable
Sensitivity checks vary key assumptions to show range of outcomes. Bull and bear cases bracket uncertainty rather than presenting single-point estimates as certain.
Scenario variance bounds quantify how much conclusions change under different market conditions, regulatory environments, or competitive dynamics.
Contradiction detection flags when different sections of analysis make incompatible claims about the same metric or trend.
Watch this video about ai alignment:
Medical Researchers
Literature triangulation requires claims to be supported by multiple independent studies, not just one paper that might be an outlier.
Contraindication checks automatically flag drug interactions, allergies, and condition-specific risks before recommendations reach clinicians.
Harm avoidance filters block outputs that could lead to patient injury if followed without appropriate medical supervision.
Evidence grading distinguishes randomized controlled trials from case reports, meta-analyses from expert opinion, and assigns confidence levels accordingly.
Software Engineers and Security Teams
Secure prompt patterns prevent code generation from introducing SQL injection, cross-site scripting, or other common vulnerabilities.
Dependency provenance tracks which libraries and packages generated code imports, enabling vulnerability scanning and license compliance checks.
Adversarial tests for generated code:
- Fuzz testing with malformed inputs
- Boundary condition checks (null, empty, maximum values)
- Race condition and concurrency stress tests
- Security scanning with static analysis tools
Human review gates require senior engineer approval before AI-generated code reaches production, especially for security-critical components.
Incident Response and Closing the Feedback Loop
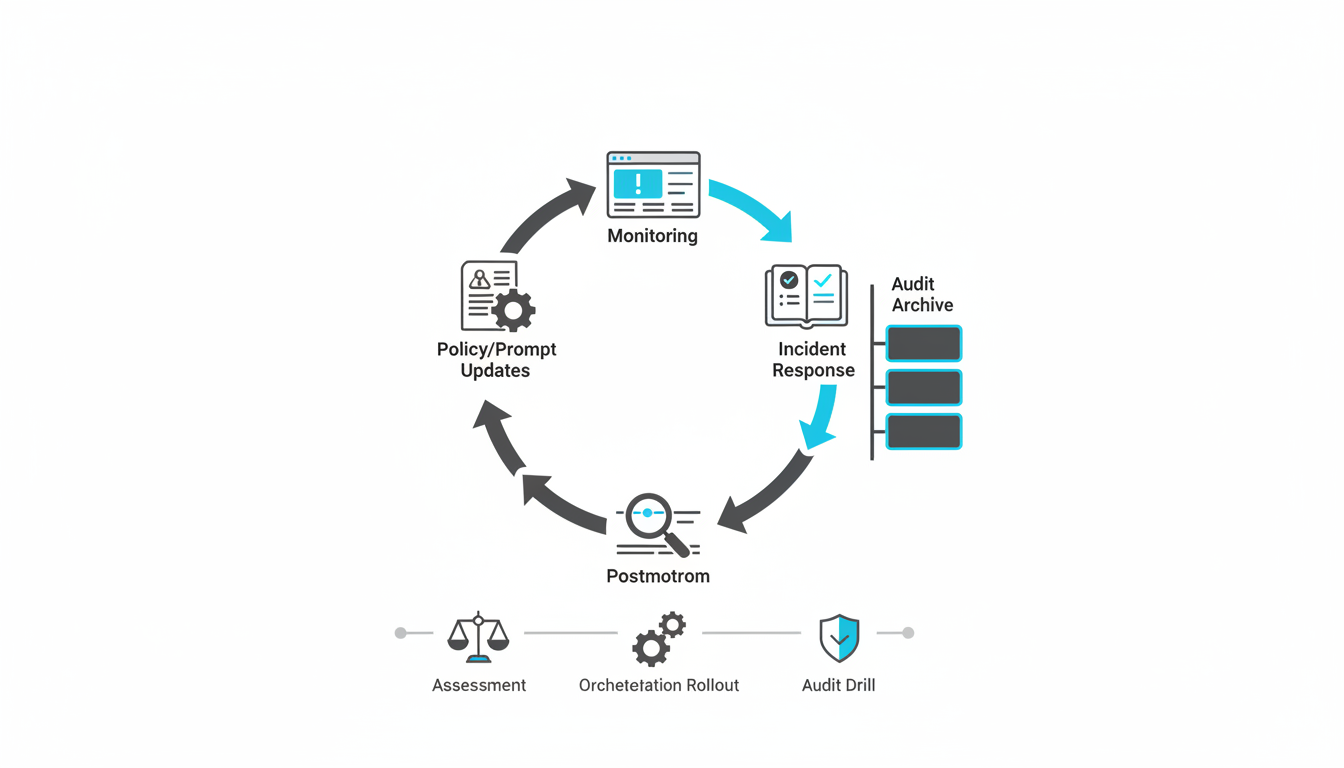
Even robust controls fail. Effective incident response limits damage, identifies root causes, and prevents recurrence through systematic improvement.
Detection Channels and Auto-Escalation
Automated detection catches metric breaches, policy violations, and anomalous patterns without waiting for user reports. Monitoring systems should alert within minutes of threshold violations.
User feedback channels let people report errors, bias, or unexpected behavior directly. Make reporting easy and acknowledge submissions promptly.
Escalation criteria trigger automatic notifications based on severity:
- Critical: potential legal liability, privacy breach, or safety risk → immediate page to on-call engineer and risk team
- High: repeated hallucinations, significant bias, or compliance near-miss → alert within 1 hour, incident review within 24 hours
- Medium: drift detection, minor accuracy degradation → daily summary, weekly review
- Low: isolated errors, edge case failures → logged for quarterly analysis
Postmortem Template and Root Cause Analysis
Effective postmortems answer five questions without blame:
- What happened? Timeline of events from first detection through resolution
- What was the impact? Quantify affected users, decisions, or outputs
- What was the root cause? Distinguish immediate trigger from underlying vulnerability
- What were contributing factors? Identify conditions that allowed the root cause to manifest
- What corrective actions prevent recurrence? Specific, measurable changes with owners and deadlines
Share postmortems across teams. Patterns emerge when you see multiple incidents with similar root causes or contributing factors.
Feedback Into Prompts, Policies, and Orchestration Settings
Incidents generate actionable improvements:
- Prompt refinement: add examples or constraints that prevent the specific failure mode
- Policy updates: tighten filters or add detection rules for newly discovered violations
- Orchestration tuning: adjust debate intensity, fusion weights, or sequential gates based on where errors escaped
- Test suite expansion: add regression tests ensuring the same incident can’t recur undetected
Conversation control features like stop/interrupt and response detail settings let you intervene when outputs start trending toward problematic territory.
Audit-Readiness with Versioned Artifacts
Compliance requires proving you can reproduce past decisions and demonstrate controls were active at the time. Maintain:
- Versioned prompts with timestamps showing what instructions were active when
- Model versions and fine-tuning states tied to specific decisions
- Conversation logs with complete context, not just final outputs
- Policy snapshots showing which rules were enforced at decision time
- Evaluation results proving models met safety thresholds before deployment
Retention policies balance storage costs against compliance windows. Financial services often require seven years. Healthcare may demand longer for certain clinical decisions.
Building Specialized Validation Teams
Different tasks need different safety profiles. Specialized AI teams combine models and orchestration modes optimized for specific validation requirements.
Legal validation team: emphasizes citation checking, jurisdiction filtering, and precedent verification. Uses sequential mode with dedicated fact-checking stage.
Financial analysis team: prioritizes source attribution, numerical consistency, and scenario testing. Debate mode surfaces conflicting interpretations of the same data.
Medical literature team: focuses on evidence grading, contraindication detection, and harm avoidance. Super Mind mode synthesizes findings while maintaining provenance to original studies.
Security review team: runs red team mode continuously, probing for vulnerabilities and testing robustness against adversarial inputs.
Team composition changes as requirements evolve. Add models with specific capabilities (medical knowledge, financial reasoning, legal expertise) and adjust orchestration parameters based on validation results.
Frequently Asked Questions
Is using multiple models always safer than a single model?
Not automatically. Multiple models amplify safety when orchestrated to expose disagreements and validate reasoning. Simply running several models and picking one output provides no safety benefit. The orchestration mode matters – debate surfaces contradictions, fusion maintains provenance, sequential enforces staged validation. Random model selection or majority voting can actually hide important uncertainties.
How do we measure hallucination rates reliably?
Build test datasets with verified ground truth answers. Run your system against these questions and count fabricated facts or unsupported claims. For domain-specific work, create test sets covering your actual use cases – legal citations, financial figures, medical references. Automated checking catches obvious fabrications. Manual review samples 10-20% to find subtle errors. Track both rate and severity. A hallucinated date is less critical than an invented legal precedent.
What’s a realistic timeline for implementing comprehensive safety controls?
The 30-60-90 day plan in this guide assumes a team with AI deployment experience starting from minimal safety infrastructure. Expect 3-6 months to reach production-ready safety for high-stakes applications. Complex regulated environments (healthcare, finance, legal) may need 6-12 months to satisfy all compliance requirements. Start with highest-risk use cases and expand coverage incrementally.
How often should we update our evaluation metrics and thresholds?
Review quarterly at minimum. Update immediately when incidents reveal gaps in current metrics. Thresholds should tighten as systems improve – what’s acceptable during initial deployment becomes unacceptable once you’ve demonstrated better performance. New attack vectors and failure modes emerge constantly, requiring new test cases and detection methods.
Do we need different safety controls for different deployment contexts?
Yes. Risk-based approaches tailor controls to potential harm. Internal research tools need less stringent safeguards than customer-facing applications. Low-stakes tasks (document summarization) tolerate higher error rates than high-stakes decisions (legal memos, investment recommendations). Regulatory context matters – HIPAA for healthcare, GDPR for EU personal data, sector-specific rules for finance. Start with a base safety stack and add controls based on specific risks.
How do we balance safety controls with system usability?
Excessive friction reduces adoption and drives users to unsafe workarounds. Design controls that run automatically without requiring constant user intervention. Reserve human-in-the-loop reviews for genuinely high-stakes decisions. Provide clear feedback when safety controls block or modify outputs so users understand the system is working as intended. Measure both safety metrics and user satisfaction – if people abandon the system, safety controls become irrelevant.
What role does transparency play in AI safety?
Transparency enables validation. When outputs include provenance showing which models contributed, what sources they used, and where disagreements occurred, reviewers can verify reasoning rather than trusting black-box assertions. Model cards and data cards document limitations and known biases upfront. Audit trails prove controls were active when decisions were made. Transparency doesn’t guarantee safety, but opacity guarantees you can’t demonstrate it.
Implementing Safety as an Operating System
AI safety isn’t a feature you add at the end – it’s an integrated operating system spanning governance, data, models, outputs, and operations. This guide provided a complete safety stack with measurable controls, evaluation frameworks, and role-specific patterns you can implement starting tomorrow.
Key takeaways:
- Safety requires measurement: define metrics, set thresholds, and build test harnesses that produce repeatable results across truthfulness, robustness, bias, and calibration dimensions
- Multi-model orchestration exposes what single models hide: debate surfaces contradictions, fusion maintains provenance, sequential enforces staged validation, and red teaming probes vulnerabilities systematically
- Standards provide actionable frameworks: NIST AI RMF and ISO/IEC 42001 offer proven structures for governance, risk management, and continuous improvement
- Operational playbooks sustain safety over time: monitoring detects drift, incident response limits damage, and feedback loops prevent recurrence
- Context and provenance enable validation: complete audit trails let you reproduce decisions, verify reasoning chains, and demonstrate compliance
The 30-60-90 day implementation plan, evaluation scorecards, and role-specific checklists give you concrete starting points. Begin with your highest-risk use cases, establish baseline measurements, and expand coverage as you build capability and confidence.
Safety isn’t achieved once and forgotten. Models evolve, data distributions shift, new attack vectors emerge, and regulatory requirements change. Continuous improvement processes incorporating incident learnings, evaluation results, and operational feedback keep safety controls effective as systems and threats evolve.
Explore how structured multi-model orchestration can strengthen your current evaluation workflow and provide the validation mechanisms high-stakes decisions require.





