



Speed without validation is risk. Validation without speed is missed opportunity. When your next decision determines a merger, a legal defense, or a regulatory filing, you need answers that can be trusted and defended.
Most teams treat AI inference as a runtime afterthought – a single model behind an API. That breaks under pressure. Evidence must be cross-checked. Bias must be probed. Answers must be reproduced across drafts and reviewers.
This guide reframes AI inference as a decision-validation system. You’ll learn how multi-model orchestration, persistent context, and reproducibility practices transform inference from a black box into a defensible workflow.
AI Inference vs Training: Understanding the Operational Divide
Training builds the model. Inference runs it. The operational KPIs shift completely between these two phases.
Training optimizes for accuracy and convergence. You measure loss curves, validation scores, and training time. Inference optimizes for latency, throughput, cost, and quality. You measure response time, requests per second, cost per inference, and output reliability.
The Inference Request Lifecycle
Every inference request follows a predictable path:
- Request arrival – Client submits input and context
- Preprocessing – Tokenization, embedding lookup, cache checks
- Model runtime – Forward pass through neural network
- Postprocessing – Decoding, formatting, guardrail checks
- Evaluation and logging – Quality checks, metrics capture, audit trail
Classical ML models (CNNs, gradient-boosted trees) complete this cycle in milliseconds. Large language models take seconds or minutes, depending on context window size and token generation rate.
Quality Dimensions Beyond Accuracy
Production inference demands more than correct answers. You need to evaluate:
- Robustness – Does the model handle edge cases and adversarial inputs?
- Factuality – Are claims grounded in provided documents or known facts?
- Bias – Does the output favor certain demographics or viewpoints?
- Variance – Do repeated runs produce consistent answers?
- Explainability – Can you trace reasoning steps and cite sources?
Single-model inference struggles with these dimensions. When a model confidently produces a wrong answer, you have no recourse. When two stakeholders get different results, you have no audit trail.
Inference Architectures: Cloud, Edge, and Hybrid Deployment
Where you run inference determines latency, privacy, and cost trade-offs. Three patterns dominate professional deployments.
Cloud Inference: Elasticity and Compute Power
Cloud providers offer on-demand GPUs, autoscaling, and managed serving frameworks. You pay for compute time and data egress.
Cloud inference works best when:
- Your workload has unpredictable spikes
- You need access to the latest GPU architectures
- Data privacy regulations permit cloud processing
- You want to avoid upfront hardware investment
Typical latency ranges from 50ms to 2 seconds, depending on model size and batch configuration. Cost per inference ranges from $0.0001 for small models to $0.05 for large language models with long contexts.
Edge Inference: Low Latency and Data Privacy
Edge deployment runs models on local hardware – phones, IoT devices, or on-premises servers. You trade compute power for control.
Edge inference works best when:
- You require sub-10ms latency
- Data cannot leave the device or premises
- Network connectivity is unreliable
- You want to eliminate per-request cloud costs
Edge devices run quantized models (INT8 or FP8 precision) to fit memory constraints. This reduces accuracy by 1-3% but enables real-time operation.
Hybrid Patterns: Balancing Control and Capability
Hybrid architectures route simple requests to edge models and complex requests to cloud infrastructure. This pattern appears frequently in regulated industries.
A legal team might run document classification on-premises and send only flagged sections to cloud models for detailed analysis. This keeps sensitive data local while accessing powerful reasoning capabilities.
Multi-Model Orchestration Patterns for Decision Validation
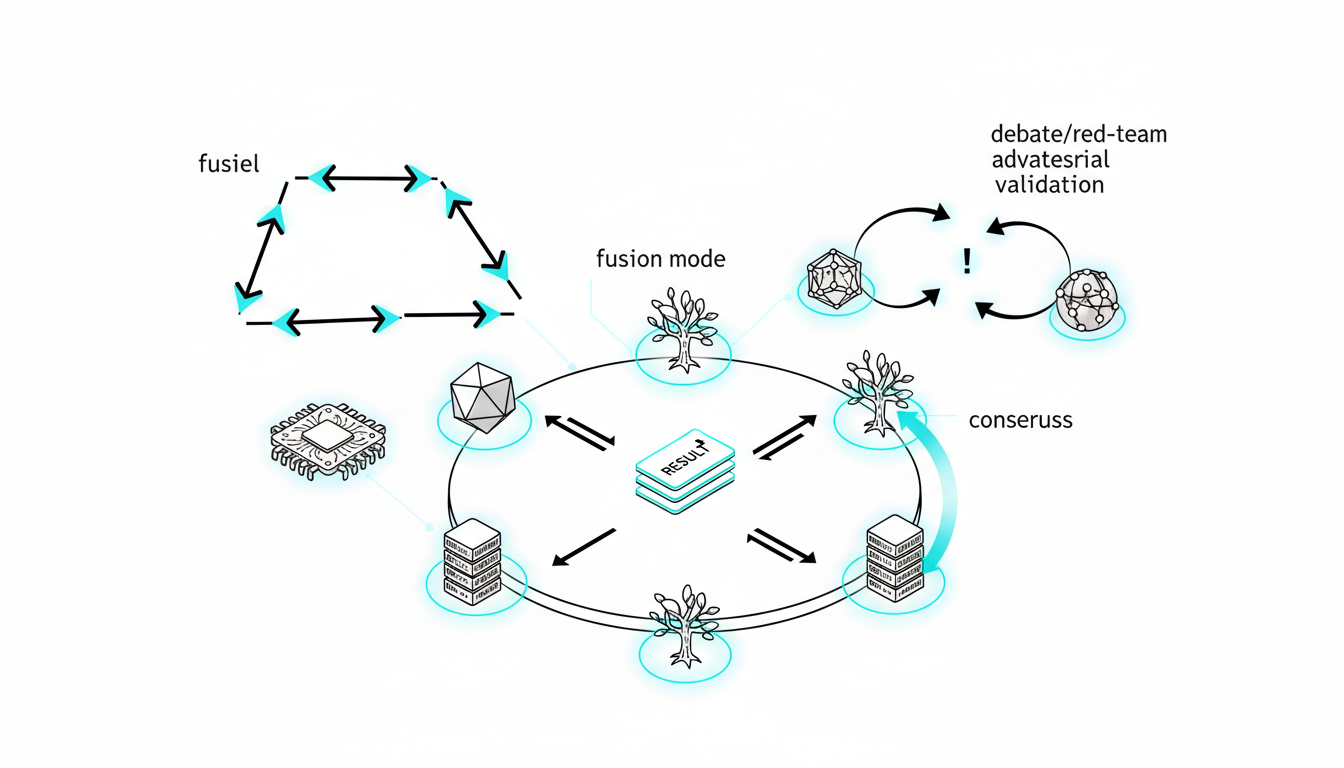
Single-model inference gives you one perspective. Multi-model orchestration gives you validation, debate, and consensus. When decisions carry real consequences, you need more than a single AI’s opinion.
Professional workflows use five orchestration modes, each suited to different validation requirements. You can see how a five-model AI Boardroom runs parallel inferences to surface disagreement and build confidence.
Sequential Mode: Stage-Wise Refinement
Models process input in sequence. Each model receives the previous model’s output as additional context.
Sequential orchestration works for:
- Multi-step reasoning – Break complex problems into stages
- Progressive refinement – Start broad, then narrow focus
- Specialized expertise – Route to domain-specific models
A due diligence workflow might use one model to extract key terms, a second to identify risks, and a third to draft recommendations. Each stage builds on verified prior work.
Super Mind mode: Consensus from Independent Analysis
Models analyze input independently. You synthesize responses to identify agreement and highlight divergence.
Super Mind mode reduces single-model bias. When three models agree on a conclusion but two dissent, you have a signal to investigate further. When all five models produce different answers, you know the question needs clarification.
Investment analysts use Super Mind mode to validate investment theses with orchestrated models. Each model evaluates the same financial data independently. Agreement builds confidence. Disagreement triggers deeper research.
Debate and Red Team Modes: Adversarial Validation
Debate mode assigns opposing positions to different models. One model argues for a conclusion while another challenges it. This surfaces weaknesses in reasoning and exposes unsupported claims.
Red team mode goes further. One model generates output while others actively try to break it – finding edge cases, logical gaps, and factual errors.
Legal teams cross-check legal arguments with adversarial prompts to identify vulnerabilities before opposing counsel does. A model drafts a brief. Another model attacks it from the other side’s perspective. A third model evaluates which arguments hold.
Research Symphony: Coordinated Parallel Investigation
Research symphony assigns distinct research threads to different models. Each model investigates a specific angle or hypothesis. Results merge into a comprehensive analysis.
This mode appears in due diligence reviews where multiple risk categories require simultaneous investigation. One model examines financial statements. Another reviews regulatory filings. A third analyzes competitive positioning. A fourth checks reputation signals.
Routing and Disagreement Resolution
When models disagree, you need a resolution strategy:
- Majority vote – Use the most common answer (works for classification)
- Confidence weighting – Trust models that express higher certainty
- Human arbitration – Flag disagreements for expert review
- Hierarchical delegation – Route to a more powerful model as tiebreaker
You can control depth, interruption, and message queuing during inference to manage how models interact and when to pause for human input.
Performance Engineering: Latency, Throughput, and Cost Trade-Offs
Production inference requires quantitative thinking. You need formulas, not intuition, to predict whether your architecture will meet SLOs.
Latency Components and Calculation
End-to-end latency breaks into measurable components:
Total Latency = Network Time + Queue Time + Compute Time + Postprocessing Time
- Network time – Round-trip between client and server (10-100ms typical)
- Queue time – Wait for available compute slot (0ms to seconds under load)
- Compute time – Model forward pass (1ms to 30s depending on size)
- Postprocessing – Decoding and formatting (1-50ms)
For a large language model generating 500 tokens, compute time dominates. For a small CNN classifying images, network time matters most.
Throughput and Concurrency
Throughput measures how many requests your system handles per second. The basic formula:
Throughput = (Tokens per Second × Concurrent Workers) / Average Tokens per Request
A GPU generating 100 tokens per second with 8 concurrent workers can handle 800 tokens per second total. If average requests need 400 tokens, throughput is 2 requests per second.
Batching improves throughput by processing multiple requests together. A batch size of 16 might increase throughput 10x while adding only 50ms to latency.
Quantization and Model Compression
Quantization reduces model precision from 32-bit floats (FP32) to 8-bit integers (INT8) or 8-bit floats (FP8). This cuts memory usage by 75% and speeds inference by 2-4x.
Quality impact varies by model architecture:
- CNNs and transformers – 1-2% accuracy loss with INT8
- Large language models – 2-5% perplexity increase with INT8
- Small models – Can become unusable below FP16
Distillation creates smaller models that mimic larger ones. A distilled model might be 10x faster with only 5-10% quality degradation. This trade-off works when speed matters more than marginal accuracy.
Caching Strategies for LLM Inference
LLMs process context windows token by token. Caching eliminates redundant computation:
- Prompt caching – Store processed system prompts and reuse across requests
- Document caching – Process long documents once, reference in multiple queries
- KV cache – Preserve key-value tensors from previous tokens in generation
A legal team analyzing a 50-page contract might process it once and cache the result. Subsequent questions about the contract skip the initial processing, reducing latency from 30 seconds to 2 seconds.
Cost Modeling Framework
Calculate cost per inference using this formula:
Cost per Inference = (Compute Cost per Second × Latency) + (Storage Cost × Context Size)
For cloud GPU inference:
- A100 GPU costs $3/hour = $0.00083/second
- Average inference takes 2 seconds
- Cost per inference = $0.00083 × 2 = $0.00166
At 1 million inferences per month, that’s $1,660 in compute costs. Add storage, networking, and orchestration overhead, and total cost reaches $2,000-2,500.
Serving Stacks and Runtime Selection
The serving stack sits between your application and the model. It handles batching, autoscaling, monitoring, and optimization.
ONNX Runtime and TensorRT for Classical Models
ONNX Runtime provides cross-platform model serving with built-in optimizations. It supports CPU, GPU, and custom accelerators.
TensorRT optimizes models specifically for NVIDIA GPUs. It fuses layers, prunes unused operations, and selects optimal kernels. Speedups range from 2x to 10x compared to unoptimized frameworks.
Use ONNX Runtime when you need portability across hardware. Use TensorRT when you deploy exclusively on NVIDIA infrastructure and need maximum performance.
vLLM and Text Generation Inference for LLMs
vLLM (from UC Berkeley) and Text Generation Inference (from Hugging Face) specialize in large language model serving. Both implement continuous batching and PagedAttention for efficient memory use.
Key features:
- Continuous batching – Add new requests to in-flight batches without waiting
- PagedAttention – Reduce memory fragmentation in KV cache
- Speculative decoding – Use small model to predict tokens, verify with large model
- Multi-LoRA serving – Serve multiple fine-tuned variants from one base model
vLLM typically achieves 2-3x higher throughput than naive implementations for the same hardware.
Ray Serve for Multi-Model Orchestration
Ray Serve handles distributed model serving and orchestration. You can deploy multiple models, route requests dynamically, and scale each model independently.
This matters for multi-model workflows. When running five models simultaneously, Ray Serve manages resource allocation and request routing. You can scale the most-used model to 10 instances while keeping specialized models at 2 instances.
Serverless Inference Options
Serverless platforms (AWS Lambda, Google Cloud Functions, Modal) eliminate infrastructure management. You pay per request with automatic scaling.
Serverless works best for:
- Unpredictable traffic patterns
- Small to medium models (under 2GB)
- Latency tolerance of 1-5 seconds
Cold starts remain the primary challenge. The first request after idle period takes 5-30 seconds while the runtime loads the model. Subsequent requests complete in milliseconds.
Observability and Monitoring Requirements
Production inference requires visibility into system health and quality metrics:
- Request tracing – Track each request through preprocessing, inference, and postprocessing
- Token-level metrics – Measure tokens per second, context length, cache hit rate
- Quality monitoring – Sample outputs for factuality, bias, and coherence
- Saturation indicators – Queue depth, GPU utilization, memory pressure
- Error tracking – Capture timeouts, OOM errors, and guardrail failures
When latency degrades, you need to know whether the problem is network congestion, model overload, or cache thrashing. When quality drops, you need to know which model version introduced the regression.
Watch this video about ai inference:
Evaluation and Governance at Inference Time
Most teams evaluate models before deployment and hope they stay accurate. Production reality differs. Data drifts. Edge cases emerge. Adversaries probe for weaknesses.
Moving evaluation into production transforms inference from a black box into a governed process.
A/B Testing and Canary Deployments
A/B testing compares two model versions on live traffic. Route 5% of requests to the new model. Compare quality metrics, latency, and cost. Roll out gradually if results improve.
Canary deployments take a more cautious approach. Deploy the new model to a single region or customer segment. Monitor for 24-48 hours. Expand if metrics hold.
Both patterns require automated evaluation. You cannot manually review thousands of inferences. Set up guardrails that flag outputs for human review when:
- Confidence scores drop below threshold
- Multiple models disagree significantly
- Output contains sensitive terms or PII
- Latency exceeds SLO
Adversarial Probes and Red Team Testing
Adversarial testing exposes failure modes before users do. Generate inputs designed to trigger incorrect outputs:
- Prompt injection – Embed instructions that override system prompts
- Jailbreak attempts – Request prohibited content through indirect phrasing
- Hallucination triggers – Ask about nonexistent facts to test grounding
- Bias probes – Test demographic fairness across protected attributes
Run these probes continuously. When a new attack vector emerges, add it to your test suite. Track the pass rate over time.
Reproducibility Through Context Artifacts
High-stakes decisions require audit trails. You need to reproduce the exact inference that led to a conclusion.
Store these artifacts for every decision-grade inference:
- Input prompt and context – Exact text sent to models
- Model versions and configurations – Which models ran, with what parameters
- Raw outputs – Unedited responses from each model
- Orchestration mode – Sequential, fusion, debate, or red team
- Timestamp and user – When and who triggered the inference
You can use persistent context management across long analyses to maintain these artifacts automatically. When a stakeholder questions a conclusion six months later, you can replay the exact inference session.
Knowledge Graphs for Explainability
Text outputs hide relationships. Knowledge graphs make them explicit. When models extract entities and relationships during inference, you can map relationships between entities surfaced during inference.
A due diligence review might extract:
- Company A acquired Company B in 2022
- Company B had regulatory issues in 2021
- The acquiring executive previously led Company C
- Company C faced similar regulatory issues
The graph reveals a pattern that text alone obscures. This supports both decision-making and post-hoc explanation.
Use-Case Playbooks: Applying Inference to Professional Workflows
Theory becomes practical through concrete workflows. These playbooks show how multi-model inference solves real problems.
Due Diligence: Document-Grounded Synthesis
Due diligence reviews process hundreds of documents under tight deadlines. Single-model inference misses details or hallucinates facts.
Multi-model workflow:
- Upload all documents to context fabric
- Use sequential mode to extract key entities and dates
- Switch to Super Mind mode to identify risk factors independently
- Apply red team mode to challenge each identified risk
- Generate final report with citations to source documents
Each model grounds its analysis in provided documents. When models cite different passages for the same conclusion, you know the evidence is strong. When only one model flags a risk, you investigate whether others missed it or whether it’s a false positive.
Teams using this workflow apply multi-model inference to due diligence reviews and report 40% faster completion with higher confidence in findings.
Investment Analysis: Thesis Debate and Counterfactuals
Investment decisions rest on assumptions. What if those assumptions are wrong?
Multi-model workflow:
- One model drafts the investment thesis
- A second model argues the bear case
- A third model identifies key assumptions and tests them
- A fourth model generates counterfactual scenarios
- A fifth model synthesizes the debate into a recommendation
This surfaces blind spots. If the bear case identifies risks the bull case ignored, you adjust position sizing. If counterfactuals show the thesis depends on a single assumption, you seek additional evidence.
Legal Analysis: Case Law Retrieval with Adversarial Challenge
Legal arguments must withstand opposing counsel’s scrutiny. Testing them in advance reveals weaknesses.
Multi-model workflow:
- One model retrieves relevant case law and statutes
- A second model drafts the argument
- A third model attacks the argument from the opposing side
- A fourth model identifies the strongest counterarguments
- A fifth model suggests how to strengthen weak points
The adversarial challenge exposes logical gaps and unsupported claims before they reach court. This reduces the risk of surprise attacks during proceedings.
ROI and Risk Reduction Metrics
Multi-model inference costs more than single-model inference. The ROI comes from risk reduction and quality improvement:
- Due diligence – Catch risks that would have cost millions in deal failure
- Investment analysis – Avoid losses from unexamined assumptions
- Legal analysis – Strengthen arguments that determine case outcomes
When a single missed risk costs more than a year of inference costs, the ROI calculation becomes straightforward.
Implementation Checklist: From Prototype to Production
Moving from experimentation to production requires systematic planning. This checklist ensures reproducibility and smooth handoffs.
Define Service Level Objectives
Set quantitative targets before you build:
- P95 latency – 95% of requests complete within X seconds
- Cost per inference – Average cost stays below $X
- Guardrail pass rate – 99%+ of outputs pass safety checks
- Quality metrics – Accuracy, factuality, or other domain-specific measures
These SLOs guide architecture decisions. If you need sub-second latency, edge deployment becomes necessary. If cost must stay under $0.01 per inference, you’ll need quantization and caching.
Choose Orchestration Mode and Serving Stack
Match orchestration mode to your validation requirements:
- Sequential for multi-step reasoning
- Super Mind for consensus building
- Debate for adversarial validation
- Red team for security and robustness testing
Select serving stack based on model types and scale:
- ONNX Runtime or TensorRT for classical models
- vLLM or TGI for large language models
- Ray Serve for multi-model orchestration
- Serverless for unpredictable traffic
You can assemble specialized AI teams for domain-specific inference by configuring which models handle which stages of your workflow.
Set Up Observability and Evaluation
Instrument your inference pipeline before the first production request:
- Add request tracing through all components
- Log inputs, outputs, and intermediate states
- Track quality metrics on a sample of outputs
- Set up alerts for latency, error rate, and quality degradation
- Create dashboards for real-time monitoring
Run your evaluation harness continuously. Sample 1-5% of production traffic for detailed quality checks. Flag outliers for human review.
Establish Audit Trails and Governance
Store artifacts that enable reproducibility:
- Prompt templates and system instructions
- Model versions and configurations
- Input documents and context
- Raw outputs from each model
- Final synthesized results
- User actions and timestamps
Define retention policies. Critical decisions may require 7-year retention. Routine queries might expire after 90 days.
Plan Rollout and Rollback
Deploy incrementally:
- Start with internal users or a single team
- Monitor for 48 hours
- Expand to 10% of users
- Monitor for one week
- Expand to 50% of users
- Monitor for two weeks
- Complete rollout
Maintain the ability to roll back instantly. If quality metrics degrade or latency spikes, you need a one-command revert to the previous version.
Frequently Asked Questions
When does multi-model cost outweigh benefits?
Multi-model inference costs 3-5x more than single-model inference. The break-even point depends on decision value. For routine queries where errors have low cost, single-model inference suffices. For high-stakes decisions where a single error costs more than months of inference, multi-model validation pays for itself immediately.
How do I handle sensitive data and compliance at inference time?
Use a hybrid architecture. Process sensitive data on-premises or in a private cloud region. Send only aggregated or anonymized results to external models for reasoning. Maintain audit logs showing which data left your control and which stayed internal. Configure data retention policies that comply with GDPR, HIPAA, or industry-specific regulations.
What if models disagree persistently?
Persistent disagreement signals ambiguity in the input or task. First, check whether the question is well-defined. Vague questions produce divergent answers. Second, examine whether models interpret key terms differently. Add definitions to the prompt. Third, use a more powerful model as tiebreaker or escalate to human judgment. Track disagreement rates over time – rising rates indicate data drift or model degradation.
How do I choose between cloud and edge deployment?
Cloud wins when you need elasticity, access to latest hardware, or infrequent usage. Edge wins when you need sub-10ms latency, data cannot leave premises, or you want to eliminate per-request costs. Hybrid works when you can route simple requests locally and complex requests to cloud. Run cost projections for your expected traffic pattern – edge has high upfront cost but low marginal cost, while cloud has low upfront cost but high marginal cost.
What’s the minimum viable monitoring setup?
Start with these three metrics: P95 latency, error rate, and cost per inference. Add quality sampling on 1% of traffic – manually review a few outputs per day. Set alerts if latency exceeds 2x normal, error rate exceeds 1%, or cost per inference exceeds budget. Expand monitoring as usage grows, adding throughput, queue depth, and model-specific quality metrics.
How do I optimize for cost without sacrificing quality?
Try these techniques in order: prompt caching for repeated context, batching for higher throughput, quantization to INT8 or FP8, model distillation for smaller variants, and selective routing where simple queries use cheaper models. Measure quality impact at each step. Stop when quality degradation exceeds your tolerance. For most applications, prompt caching and batching provide 3-5x cost reduction with zero quality loss.
What’s the difference between model serving and orchestration?
Model serving runs a single model and returns its output. Orchestration coordinates multiple models, manages their interactions, and synthesizes results. Serving focuses on latency and throughput. Orchestration focuses on validation and consensus. You need both – serving handles the runtime, orchestration handles the workflow.
How do I prevent prompt injection and jailbreak attempts?
Use multiple defense layers. First, input validation filters obvious attacks. Second, system prompts with clear boundaries resist override attempts. Third, output guardrails catch prohibited content. Fourth, red team mode where one model tries to break another’s output. Fifth, human review of flagged outputs. No single technique is perfect – defense in depth reduces risk.
Treating Inference as a Decision-Validation System
AI inference is not just a runtime. It’s the last mile to high-stakes decisions. When those decisions determine legal outcomes, financial positions, or strategic directions, you need more than speed and cost efficiency.
You need validation. You need reproducibility. You need confidence that answers can be defended.
Multi-model orchestration transforms inference from a black box into a governed process. Sequential mode breaks complex reasoning into verifiable stages. Super Mind mode surfaces consensus and disagreement. Debate mode exposes weaknesses before they matter. Persistent context and knowledge graphs enable audit trails.
The architecture choices – cloud, edge, hybrid – determine latency and cost. The serving stack – ONNX Runtime, TensorRT, vLLM, Ray Serve – determines throughput and scalability. The orchestration mode determines confidence and quality.
When you combine the right architecture, serving stack, and orchestration mode, inference becomes fast, cost-effective, and defensible. That’s what high-stakes work demands.
Explore how orchestration modes and context tools support your inference workflow. The difference between a single AI’s opinion and a validated decision is the difference between risk and confidence.





