



May 16. 2026: Updated with current AI hallucination metrics and new data.
Executive Overview
AI hallucinations – instances where models generate false, fabricated, or unsupported information with confidence – remain one of the most important risks in AI-powered work. The important update for 2026 is that there is no single universal “AI hallucination rate.” Different benchmarks measure different failure modes: whether a model stays faithful to a document, whether it guesses instead of admitting uncertainty, whether it cites sources correctly, or whether its claims are actually supported across a multi-turn conversation.
That distinction matters. On controlled summarization tasks, the best models can appear highly reliable. On harder enterprise-style benchmarks, legal questions, medical tasks, citation retrieval, or multi-turn research workflows, error rates rise sharply. This is why hallucination mitigation through multi-model verification, retrieval, source checking, and human review are becoming structural requirements rather than optional safeguards.
NOTE: Complete AI Hallucination Research with rates and benchmarks for 2026 is available on this page.
The most important updated numbers:
- 88% of organizations now report regular AI use, but nearly two-thirds have not begun scaling AI enterprise-wide, according to McKinsey’s 2025 Global Survey on AI.
- 51% of organizations using AI have seen at least one negative consequence, and nearly one-third of all respondents reported consequences from AI inaccuracy.
- Vectara’s newer, harder hallucination benchmark reports a best rate of 3.3%, while several frontier reasoning models exceed 10% on the same benchmark.
- Columbia Journalism Review found that eight generative search tools gave incorrect answers on more than 60% of tested news-citation queries.
- Stanford HAI found that purpose-built legal AI tools still hallucinated more than 17% to more than 34% of the time on challenging legal research queries.
- Damien Charlotin’s AI Hallucination Cases database now reports 1,450 identified legal cases involving AI hallucinations or related court findings.
- ECRI ranked misuse of AI chatbots in healthcare as the number-one health technology hazard for 2026.
What Is an AI Hallucination? (Technical Definition + Plain English)
Plain English
An AI hallucination happens when an AI system confidently makes something up. It may invent a statistic, cite a study that does not exist, misquote a real source, fabricate a legal case, or add facts that were not in the document it was asked to summarize. The response often sounds polished and authoritative, which is exactly what makes hallucinations dangerous.
Technical Definition
In technical terms, hallucination refers to generated output that is not grounded in the provided input, retrieved evidence, or factual reality. For a 2026 article, it is useful to separate several failure types instead of treating all hallucinations as one thing:
- Faithfulness hallucination: the model contradicts or adds unsupported information when summarizing a document it was explicitly given.
- Factuality hallucination: the model invents facts, events, people, statistics, papers, or claims that are not grounded in reality.
- Citation hallucination: the model invents a source, gives a broken URL, cites the wrong article, or attributes a real claim to the wrong publication.
- Misgrounding: the model cites a real source, but the source does not support the claim being made.
- Abstention failure: the model should say “I don’t know,” but instead guesses confidently.
Why It Happens
Large language models are prediction systems. They generate plausible text based on patterns learned from training data and context, not by directly “knowing” truth in the way a database stores verified records. Retrieval, web search, citations, and tool use can reduce hallucination risk, but they do not eliminate it because models can still retrieve the wrong source, misunderstand the source, overgeneralize from it, or cite it for a claim it does not support.
How to Read AI Hallucination Statistics
The most common mistake in articles about hallucination is comparing benchmark numbers as if they measure the same thing. They do not. A 3% summarization hallucination rate, a 60% citation error rate, and a 30% multi-turn grounding failure rate can all be true at the same time because they come from different tasks.
| Benchmark or source | What it measures | How to interpret the number |
| Vectara HHEM Leaderboard | Whether a model adds unsupported information while summarizing supplied documents | Best for grounded summarization and RAG-style faithfulness, not general world knowledge |
| AA-Omniscience | Whether a model guesses instead of abstaining on difficult knowledge questions | Best for uncertainty management and overconfidence, not ordinary per-response hallucination |
| Columbia Journalism Review citation study | Whether AI search tools correctly identify article headline, publisher, date, and URL | Best for citation and retrieval reliability, not all AI tasks |
| OpenAI SimpleQA / PersonQA | Short-answer factual accuracy and hallucination on fact-seeking questions | Best for factual recall, especially when comparing OpenAI model behavior |
| Stanford HAI legal AI study | Hallucination and misgrounding in legal research tools | Best for legal research risk |
| HalluHard | Multi-turn citation-required answers across legal, research, medical, and coding domains | Best for hard, realistic grounding failures in longer workflows |
Benchmark 1: Vectara Hallucination Leaderboard (HHEM)
What It Measures
The Vectara Hallucination Leaderboard measures grounded hallucination: how often a model introduces unsupported information when summarizing a document it was explicitly given. Think of it as: “Can the model stick to what is written in front of it?” This makes Vectara especially relevant for RAG systems, enterprise search, document Q&A, and support bots that are supposed to answer from provided knowledge.
AI hallucination benchmarks (live table) with Vectara Hughes Hallucination Evaluation Model (HHEM) Leaderboard included.
Hallucination Rates – Original Dataset
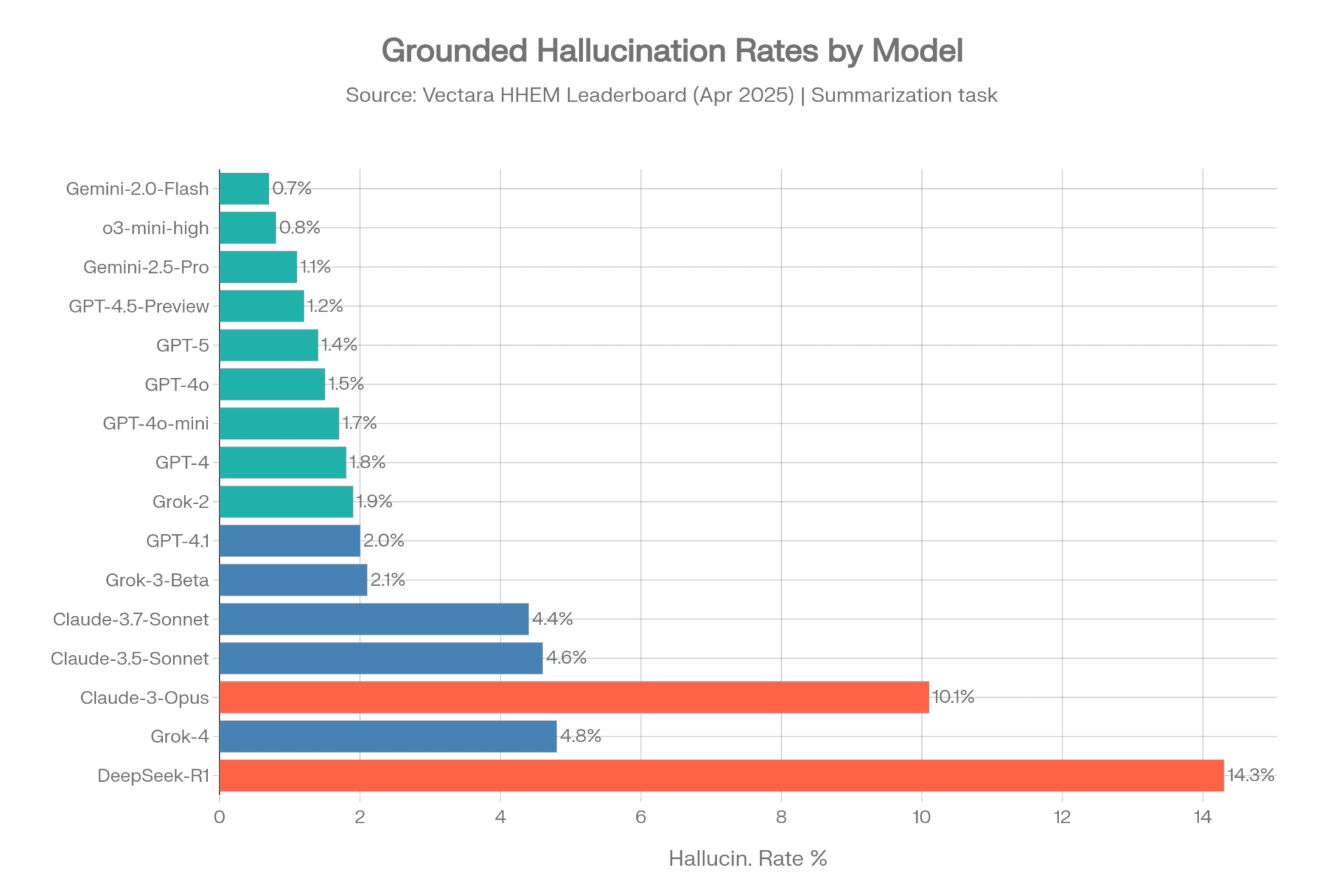
The original Vectara dataset became a widely cited baseline because several top models appeared to reach very low hallucination rates on controlled summarization. These numbers are still useful, but they should be described as performance on a simpler, older summarization benchmark, not as a general hallucination rate for all AI use.
| Model | Vendor | Hallucination Rate | Factual Consistency |
| Gemini-2.0-Flash-001 | 0.7% | 99.3% | |
| Gemini-2.0-Pro-Exp | 0.8% | 99.2% | |
| o3-mini-high | OpenAI | 0.8% | 99.2% |
| Gemini-2.5-Pro-Exp | 1.1% | 98.9% | |
| GPT-4.5-Preview | OpenAI | 1.2% | 98.8% |
| Gemini-2.5-Flash-Preview | 1.3% | 98.7% | |
| GPT-5 / ChatGPT-5 | OpenAI | 1.4% | 98.6% |
| GPT-4o | OpenAI | 1.5% | 98.5% |
| GPT-4.1 | OpenAI | 2.0% | 98.0% |
| Grok-3-Beta | xAI | 2.1% | 97.8% |
| Claude-3.7-Sonnet | Anthropic | 4.4% | 95.6% |
| Grok-4 | xAI | 4.8% | ~95.2% |
| Claude-3-Opus | Anthropic | 10.1% | 89.9% |
| DeepSeek-R1 | DeepSeek | 14.3% | 85.7% |
Interpretation: These are controlled summarization results. They do not mean a model will hallucinate only 0.7% of the time in legal research, financial analysis, medical advice, or open-ended web research.
Hallucination Rates – New Dataset (November 2025)
Vectara refreshed the benchmark in late 2025 with a much harder dataset: over 7,700 articles, documents up to 32,000 tokens, and content spanning technology, stocks, sports, science, politics, medicine, law, finance, education, and business. The updated benchmark calculates hallucination rate only for articles a model actually summarizes, while refusals lower the answer rate instead.
The results are higher by design. The new benchmark better reflects complex enterprise documents and separates models more clearly.
| Model | Vendor | Hallucination Rate |
| Gemini-2.5-Flash-Lite | 3.3% | |
| Mistral-Large | Mistral | 4.5% |
| DeepSeek-V3.2-Exp | DeepSeek | 5.3% |
| GPT-4.1 | OpenAI | 5.6% |
| Grok-3 | xAI | 5.8% |
| DeepSeek-R1-0528 | DeepSeek | 7.7% |
| Claude Sonnet 4.5 | Anthropic | >10% |
| GPT-5 | OpenAI | >10% |
| Grok-4 | xAI | >10% |
| Gemini-3-Pro | 13.6% |
Key Takeaway from Vectara
The old Vectara data showed that top models could stay highly faithful on shorter, simpler summarization tasks. The new Vectara data shows that once articles get longer, more complex, and more enterprise-like, hallucination rates rise. For businesses, the lesson is simple: benchmark numbers are only useful when the benchmark looks like your actual workflow.
Benchmark 2: AA-Omniscience (Artificial Analysis)
What It Measures
AA-Omniscience is a knowledge and hallucination benchmark from Artificial Analysis. It covers 6,000 questions across 42 topics and six domains: Business, Humanities & Social Sciences, Health, Law, Software Engineering, and Science, Engineering & Mathematics.
The key difference is that AA-Omniscience penalizes guessing. A correct answer earns a positive score, an incorrect answer is penalized, and abstaining is scored differently from confidently making something up. That makes it a benchmark for uncertainty management, not just raw knowledge.
Results
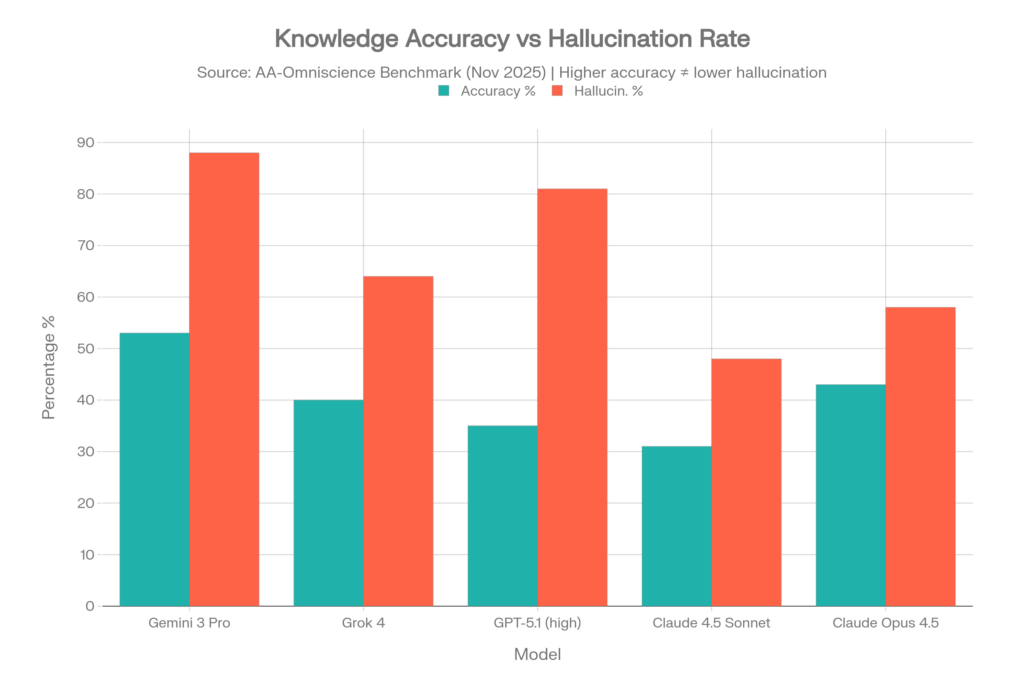
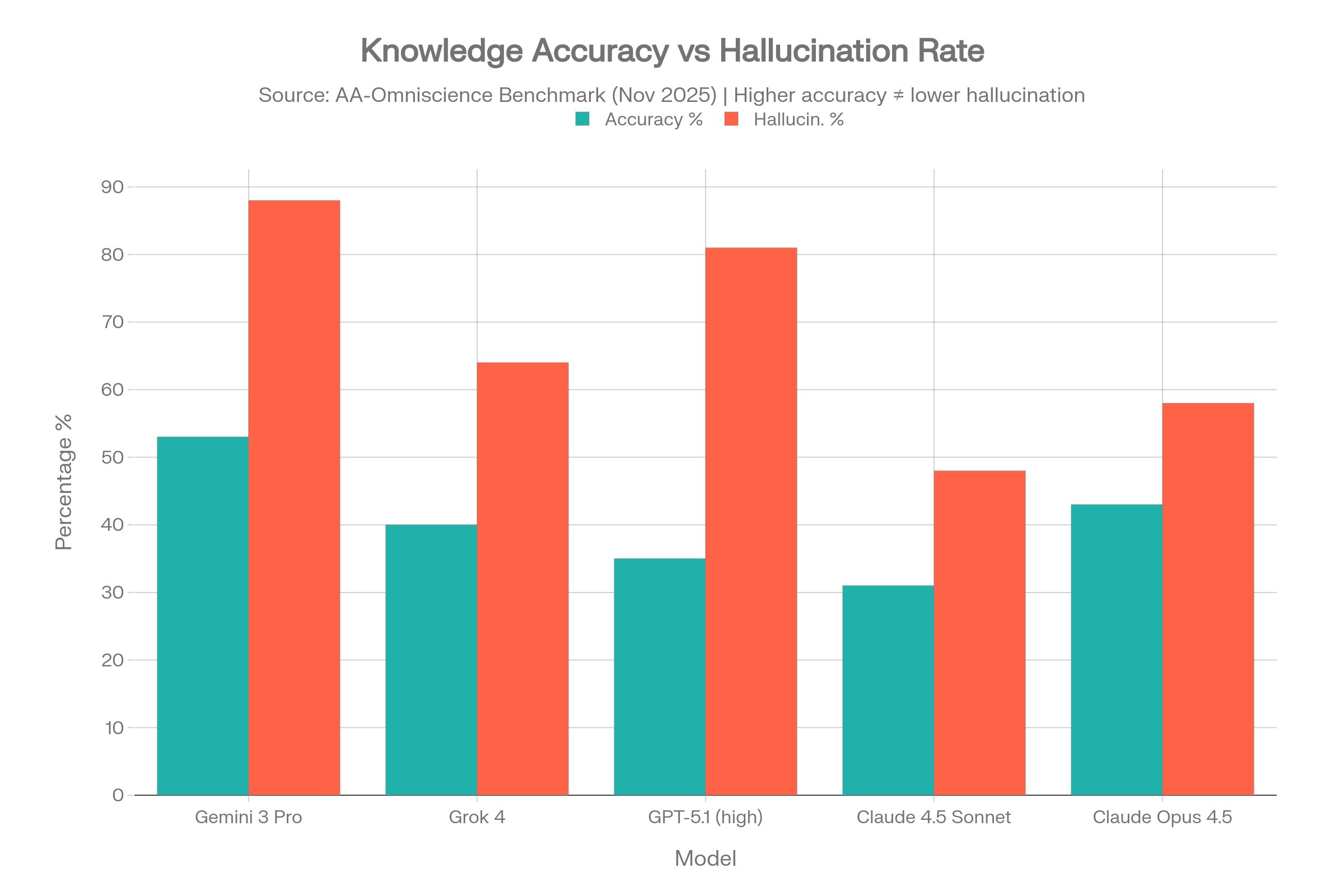
AA-Omniscience shows why “accuracy” and “reliability” are not the same thing. A model can answer many questions correctly and still be dangerous when it does not know the answer, because it may guess rather than abstain.
| Model | Reported accuracy / strength | Reported hallucination / reliability signal | Interpretation |
| Claude 4.1 Opus | Strong overall | Top Omniscience Index result in the original article data | Strong uncertainty management in this benchmark |
| Claude 4.5 Haiku | Not the highest-accuracy model | Lowest reported hallucination rate, around 26-28% | Better at abstaining when uncertain |
| Gemini 3 Pro | Very high raw accuracy in the article’s table | High overconfidence / hallucination signal | Knows a lot, but can be too willing to guess |
| Grok 4 | Strong in Health and Science domains | Still substantial hallucination signal | Domain strength does not eliminate overconfidence |
| GPT-5 / GPT-5.1 family | Strong raw accuracy in some domains | Reliability depends heavily on task and configuration | Do not interpret one score as universal reliability |
Important caveat: AA-Omniscience hallucination rate is not the same thing as “percentage of all everyday responses that are false.” It is a difficult-question overconfidence metric. It is useful because it tests whether models know when not to answer.
Domain-Specific Leaders
No single model dominates all knowledge domains. Artificial Analysis reported different leaders across law, software engineering, humanities, business, health, and science. This reinforces the practical case for model selection, multi-model comparison, and verification workflows instead of relying on one “best” model for everything.
Benchmark 3: Columbia Journalism Review Citation Study
In March 2025, Columbia Journalism Review tested eight generative search tools with live search features. Researchers selected 200 news articles from 20 publishers, gave each tool direct excerpts, and asked it to identify the original headline, publisher, publication date, and URL. Across 1,600 total queries, the tools gave incorrect answers more than 60% of the time.
| Tool | Citation / retrieval error rate |
| Perplexity | 37% |
| Microsoft Copilot | 40% |
| Perplexity Pro | 45% |
| ChatGPT Search | 67% |
| DeepSeek Search | 68% |
| Google Gemini | 76% |
| Grok-2 | 77% |
| Grok-3 | 94% |
Interpretation: this is not a broad “model hallucination rate.” It is a citation and retrieval reliability test. It matters because many users assume that AI search tools are safer simply because they provide links. CJR’s results show that links do not automatically mean the answer is grounded, complete, or correctly attributed.
Benchmark 4: OpenAI Factuality and Reasoning-Model Results
OpenAI’s o3 and o4-mini system card is useful because it shows a counterintuitive pattern: newer reasoning models can be stronger on some tasks while still hallucinating more on factual QA benchmarks.
| Dataset | Metric | o3 | o4-mini | o1 |
| SimpleQA | Accuracy | 49% | 20% | 47% |
| SimpleQA | Hallucination rate | 51% | 79% | 44% |
| PersonQA | Accuracy | 59% | 36% | 47% |
| PersonQA | Hallucination rate | 33% | 48% | 16% |
OpenAI’s explanation is that o3 tends to make more claims overall, which can lead to more accurate claims and more inaccurate claims. This is a useful warning for business users: a longer, more confident, more “reasoned” answer is not automatically more reliable.
Benchmark 5: HalluHard and Hard Multi-Turn Grounding
HalluHard, released in 2026, is important because it tests a more realistic failure mode: multi-turn conversations that require inline citations for factual claims. The benchmark includes 950 seed questions across legal cases, research questions, medical guidelines, and coding.
The headline finding is that web search helps but does not solve hallucinations. Even the strongest reported configuration, Opus-4.5 with web search, still hallucinated at approximately 30% in this hard multi-turn setting. This is one of the best arguments against treating retrieval, search, or citations as a complete fix.
Domain-Specific Hallucination Rates
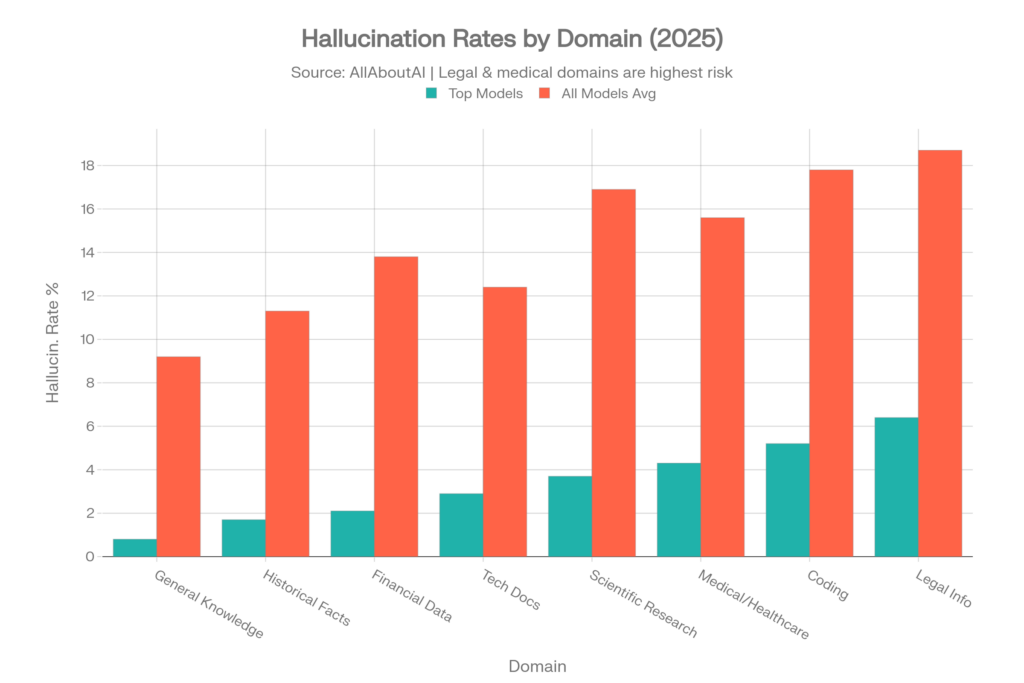
Hallucination risk changes by domain. General summarization and factual recall are not the same as legal research, medical guidance, financial analysis, coding, or citation-heavy research. The safest editorial framing is: domain-specific rates vary widely, and any benchmark should be interpreted in the context of the task being tested.
| Domain or workflow | Fresh reliability signal | Why it matters |
| Legal research | Purpose-built legal AI tools still hallucinated more than 17% to more than 34% in Stanford HAI testing | Legal hallucinations can create fake authorities, misgrounded arguments, and sanctions risk |
| Healthcare chatbots | ECRI ranked misuse of AI chatbots in healthcare as the top health technology hazard for 2026 | Confident medical misinformation can affect patient decisions and clinical workflows |
| Medical hallucination detection | MedHallu found the best model reached only 0.625 F1 on hard medical hallucination detection | Subtle medical hallucinations are hard for models to detect, not just hard to avoid |
| News citation | CJR found more than 60% overall incorrect answers across generative search tools | Source links do not guarantee accurate attribution |
| Multi-turn research | HalluHard found approximately 30% hallucination even with web search in the strongest configuration | Errors compound across longer workflows |
Medical Hallucination Deep Dive
Medical hallucination risk should now be framed in two layers: whether AI gives false medical information, and whether AI can detect subtle falsehoods in medical answers. MedHallu, a 2025 benchmark built from 10,000 PubMedQA-derived question-answer pairs, found that state-of-the-art models including GPT-4o, Llama-3.1, and UltraMedical struggled with hard medical hallucination detection. The best model reached only 0.625 F1 on the hard hallucination category.
ECRI’s 2026 health technology hazards list also moved the issue from general AI concern to specific healthcare safety risk. ECRI ranked misuse of AI chatbots in healthcare as the number-one hazard and noted that general chatbots such as ChatGPT, Claude, Copilot, Gemini, and Grok are not regulated as medical devices and are not validated for healthcare purposes.
Legal Hallucination Deep Dive
The Stanford RegLab and Stanford HAI legal AI study remains one of the most important pieces of evidence for legal hallucination risk. The study found that Lexis+ AI and Ask Practical Law AI each hallucinated more than 17% of the time, while Westlaw AI-Assisted Research hallucinated more than 34% of the time on challenging legal research queries.
This is especially important because legal hallucinations are often not just “wrong facts.” They can be misgrounded citations, invented cases, inapplicable authorities, false quotes, or incorrect legal standards. A citation can look real while failing to support the proposition being made.
Real-World Business Impact: The Numbers
The Better-Sourced Business Risk Picture
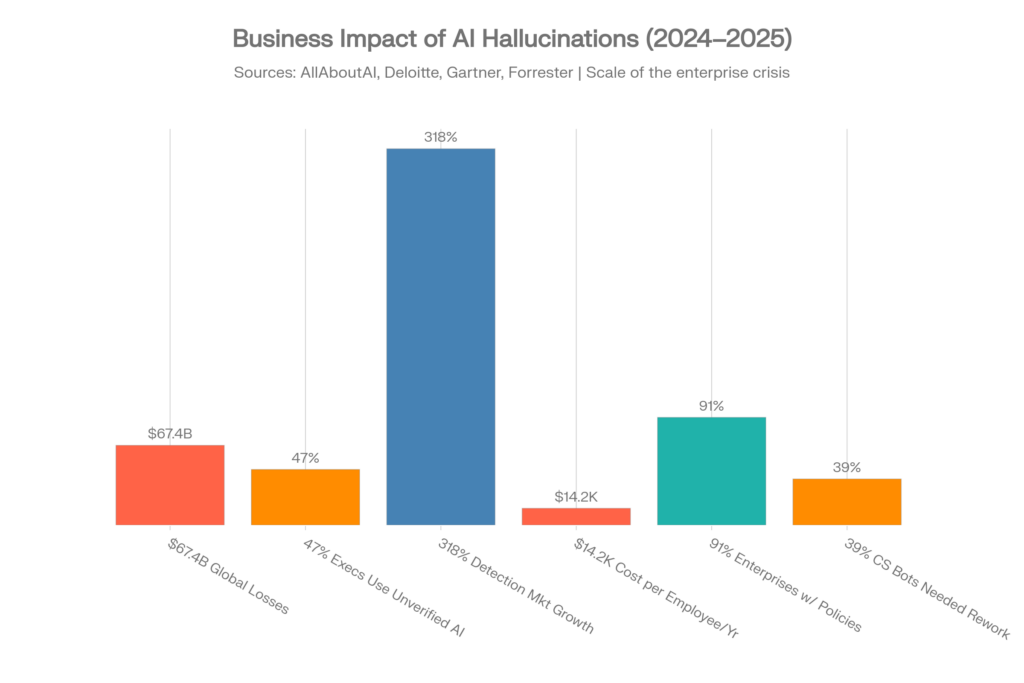
The best-sourced business risk picture now comes from enterprise AI adoption and risk surveys rather than unsourced global loss estimates. McKinsey’s 2025 Global Survey on AI gives a clearer view of how widespread AI use has become and how often organizations are already seeing negative consequences from AI inaccuracy.
| Metric | Updated value | Why it matters |
| Organizations reporting regular AI use | 88% | AI risk is now mainstream, not experimental |
| Organizations not yet scaling AI enterprise-wide | Nearly two-thirds | Many companies use AI before mature governance is in place |
| Organizations using AI that saw at least one negative consequence | 51% | AI failures are already visible in production environments |
| Respondents reporting negative consequences from AI inaccuracy | Nearly one-third | Inaccuracy is one of the clearest business-risk categories |
| Organizations at least experimenting with AI agents | 62% | Hallucinations are moving from content risk into workflow and decision risk |
| Organizations scaling agentic AI in at least one function | 23% | Agentic systems make verification and monitoring more urgent |
The Productivity Paradox
The productivity problem is not just that AI can be wrong. It is that AI can be wrong in ways that look finished, fluent, and plausible. The more AI enters reports, customer support, legal drafting, research, analytics, and internal decision-making, the more organizations need verification workflows that are built into the process rather than added at the end.
The practical business question is no longer “which AI never hallucinates?” Every current system can fail. The better question is: what verification layer catches unsupported claims before they reach a client, customer, court, patient, investor, or internal decision-maker?
Legal Incidents: The Courtroom Crisis
The Numbers Are Getting Worse, Not Better
Legal hallucinations are one of the clearest real-world examples of AI-generated falsehoods causing professional consequences. Damien Charlotin’s AI Hallucination Cases database now reports 1,450 identified cases. The database tracks legal decisions and documents where the use of AI, established or alleged, is addressed in more than a passing reference by a court or tribunal.
The current case count shows that hallucinated case law, false quotations, misrepresented authorities, and AI-generated legal arguments are no longer isolated incidents.
Who Is Making These Mistakes?
The problem is not limited to self-represented litigants. The database includes lawyers, pro se litigants, judges, expert witnesses, and other participants in legal proceedings. That matters because legal professionals often use AI in workflows where a single fabricated citation can undermine a filing, trigger sanctions, or damage client trust.
What Makes Legal Hallucinations Especially Dangerous
- Fake cases look real: fabricated case names and citations often follow familiar legal formats.
- Real cases can be misused: a model may cite an actual case that does not support the legal proposition.
- Jurisdiction matters: a semantically similar case may be legally irrelevant because it comes from the wrong court, time period, or legal context.
- Verification is expensive: if every proposition and citation must be checked manually, the productivity gain from AI can disappear.
Healthcare: Where Hallucinations Can Kill
AI Chatbots Are Now a Top Healthcare Hazard
ECRI’s 2026 health technology hazards list ranks misuse of AI chatbots in healthcare as the number-one hazard. This is a sharper and more current framing than simply saying “AI risk” is a healthcare concern. The risk is that general-purpose chatbots can produce expert-sounding medical answers even though they are not regulated as medical devices and have not been validated for healthcare purposes.
FDA and Medical Device Concerns
The FDA maintains a public list of AI-enabled medical devices authorized for marketing in the United States. The page states that the list is updated periodically and that it is intended to provide transparency for healthcare providers, patients, and digital health innovators. However, the FDA page checked for this update did not explicitly state a single total count in the page text, so any specific device-count claim should be verified directly before publication.
Medical AI Misinformation
Medical hallucinations are dangerous because they can sound like professional advice. A chatbot may suggest an incorrect diagnosis, recommend unnecessary testing, misstate guidelines, or give dangerous instructions in a calm and authoritative tone. ECRI specifically warns that healthcare organizations should use disciplined oversight, detailed guidelines, clinician training, performance audits, and verification with knowledgeable sources.
Historical Trend: Progress Is Real but Uneven
The Good News
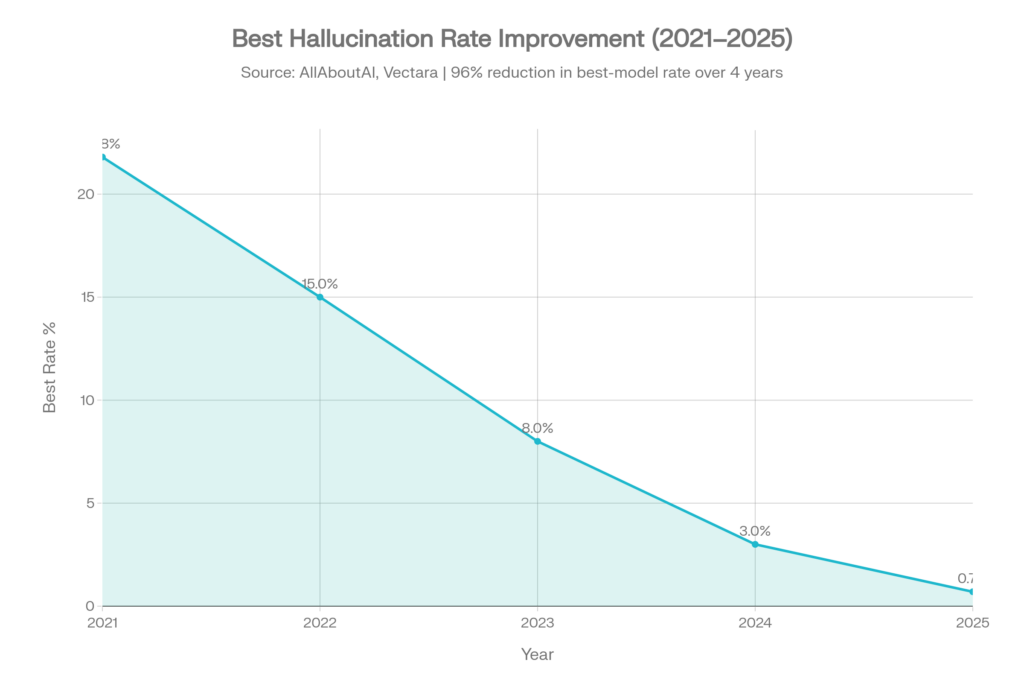
Models have improved substantially on many controlled factuality and summarization tasks. Older models hallucinated more frequently on simple benchmarks, and newer models can be dramatically better when the task is narrow, the source material is provided, and the evaluation is clear.
The Bad News
- Improvement is benchmark-specific. A model that performs well on summarization may still fail on citations, legal research, or medical reasoning.
- Harder benchmarks reveal larger gaps. Vectara’s newer benchmark reports higher rates than its older benchmark because the documents are longer and more complex.
- Reasoning can cut both ways. Reasoning models may solve harder tasks, but they may also make more claims, which creates more opportunities for unsupported statements.
- Web search is not a complete fix. HalluHard still found substantial hallucination in the strongest configuration even with web search.
Model-by-Model Summary for Suprmind.ai Models
Model comparisons should be treated as benchmark-specific. The safest way to present model reliability is to show which benchmark the number comes from and what task it measures.
| Model family | What the current evidence suggests | Best use of the data |
| OpenAI models | Strong on many tasks, but o3 and o4-mini system-card data show high hallucination on SimpleQA and PersonQA in some configurations | Use factuality benchmarks and source checking for fact-heavy workflows |
| Anthropic Claude models | Strong uncertainty-management signals in AA-Omniscience for some Claude variants | Useful where abstention and caution matter, but still requires verification |
| Google Gemini models | Strong Vectara results for some Gemini variants, but high overconfidence signals appear in AA-Omniscience-style framing | Do not confuse summarization faithfulness with universal factual reliability |
| xAI Grok models | Mixed results across benchmarks, including high citation error rates in the CJR study for Grok-3 | Evaluate by task rather than brand-level claims |
| Perplexity / Sonar | CJR found Perplexity performed best among tested AI search tools but still had a 37% citation/retrieval error rate | Strong reminder that real links still need source-content verification |
What Actually Reduces Hallucinations
No mitigation technique eliminates hallucinations. The best approach is layered verification: retrieval, citations, abstention behavior, multi-model comparison, structured prompts, source-level checking, and human review for high-stakes outputs.
| Mitigation layer | What it helps with | Limitation |
| Retrieval-Augmented Generation (RAG) | Grounds answers in supplied documents or databases | The model can still misread or misground retrieved material |
| Web search | Improves access to current information | The model can retrieve weak sources or cite sources that do not support the claim |
| Source citation requirements | Makes claims easier to audit | A citation can be fabricated, broken, irrelevant, or misused |
| Abstention / “not sure” behavior | Reduces guessing when the model lacks evidence | Can reduce answer rate or frustrate users if not designed well |
| Multi-model verification | Surfaces disagreements and catches some single-model errors | Multiple models can share the same blind spot |
| Human review | Essential for legal, medical, financial, regulatory, and client-facing work | Requires time, process, and domain expertise |
The Most Dangerous Hallucination: The One You Do Not Catch
The most dangerous hallucination is not the obvious mistake. It is the plausible one: a real-looking citation, a confident summary, a believable market statistic, a legal case that sounds familiar, or a medical explanation written in a professional tone. These errors are dangerous because they can pass through workflows unnoticed.
That is why hallucination prevention should not be framed as a single tool or a one-time prompt trick. It is a quality system. The organizations that benefit most from AI will be the ones that build verification directly into the workflow instead of treating it as cleanup after the fact.
Key Definitions Glossary
| Term | Definition |
| Hallucination | AI-generated content that is false, fabricated, unsupported, or misgrounded while being presented confidently |
| Faithfulness hallucination | False or unsupported information introduced when summarizing or answering from supplied source material |
| Factuality hallucination | Invented facts, statistics, sources, people, events, or claims with no verified basis |
| Citation hallucination | A fabricated, broken, misattributed, or unsupported citation |
| Misgrounding | A real source is cited, but it does not support the claim being made |
| RAG (Retrieval-Augmented Generation) | A technique that connects AI systems to external documents, databases, or knowledge bases before generating an answer |
| HHEM | Vectara’s Hughes Hallucination Evaluation Model for detecting unsupported claims in summaries |
| Omniscience Index | Artificial Analysis metric that rewards correct answers and penalizes confident wrong answers |
| Abstention | The model declines to answer or says it does not know rather than guessing |
| Sycophancy | A model’s tendency to agree with a user’s premise even when the premise is wrong |
Source Summary
Primary benchmarks and studies referenced in this updated version:
- Vectara Hallucination Leaderboard: original and next-generation HHEM summarization benchmark, including the 7,700+ article updated dataset. Source: Vectara.
- Artificial Analysis AA-Omniscience: knowledge and hallucination benchmark measuring accuracy, abstention, and overconfidence across 6,000 questions. Source: Artificial Analysis.
- Columbia Journalism Review: 2025 study of AI search citation accuracy across 1,600 queries and eight generative search tools. Source: Columbia Journalism Review.
- OpenAI o3 and o4-mini system card: SimpleQA and PersonQA hallucination and accuracy results for o3, o4-mini, and o1. Source: OpenAI system card PDF.
- Stanford RegLab / Stanford HAI: legal AI hallucination study of Lexis+ AI, Westlaw AI-Assisted Research, Ask Practical Law AI, and general-purpose model comparisons. Source: Stanford HAI.
- Damien Charlotin AI Hallucination Cases database: live database of legal decisions and court documents involving AI hallucinations. Source: AI Hallucination Cases database.
- McKinsey 2025 Global Survey on AI: enterprise AI adoption, scaling, negative consequences, and AI inaccuracy risk data. Source: McKinsey.
- ECRI 2026 Health Technology Hazards: healthcare risk ranking naming misuse of AI chatbots in healthcare as the top hazard. Source: ECRI.
- MedHallu: 2025 medical hallucination detection benchmark with 10,000 PubMedQA-derived question-answer pairs. Source: MedHallu on arXiv.
- HalluHard: 2026 hard multi-turn hallucination benchmark across legal, research, medical, and coding domains. Source: HalluHard on arXiv.





