




When getting it wrong costs more than getting it right, ‘good enough’ chat falls apart. A confident answer that misses a critical detail can derail a compliance review, compromise patient safety, or sink a strategic initiative. Conversational AI promises natural interaction with machines, but the gap between fluent responses and reliable outcomes remains wide.
Most AI chat sounds authoritative while missing edge cases, sources, and context. In high-stakes work, a single blind spot matters. This guide clarifies what conversational AI is, how different architectures handle reliability, and how to evaluate platforms when errors carry real costs.
You’ll see how natural language processing, dialog management, and large language models combine to create conversational systems. You’ll compare rule-based bots, single-model chat, and multi-model orchestration. You’ll get evaluation frameworks, implementation patterns, and governance checklists for professionals who need validated intelligence. Learn How It Works to see orchestration in practice.
What Conversational AI Actually Means
Conversational AI refers to systems that use natural language understanding, dialog management, and generation to interact with users through text or speech. These systems interpret intent, maintain context across exchanges, and produce coherent responses. The term encompasses chatbots, voice assistants, and orchestrated multi-model platforms.
Three key distinctions matter:
- Text vs speech interfaces – text-based systems process written input directly, while voice assistants add speech-to-text and text-to-speech layers
- Rule-based vs learning-based – older chatbots follow decision trees, modern systems use neural networks trained on language data
- Single-model vs orchestrated – most chat relies on one model, orchestrated platforms coordinate multiple models for cross-verification
The core components work together in sequence. Automatic speech recognition converts audio to text. Natural language understanding extracts meaning and intent. A dialog manager tracks conversation state and decides next actions. Natural language generation produces responses. Text-to-speech converts output to audio for voice interfaces.
Where Large Language Models Changed Everything
Large language models replaced rigid intent classifiers with flexible text understanding. Pre-2020 chatbots required explicit training for each intent. LLMs handle open-ended queries without predefined scripts. They generate contextually appropriate responses rather than selecting from templates.
This flexibility introduces new risks. LLMs produce hallucinations – confident statements unsupported by training data or retrieval sources. They lack built-in verification mechanisms. A single model’s perspective becomes the entire answer, with no cross-check against alternative interpretations.
Conversational AI vs Traditional Chatbots
Traditional chatbots follow decision trees. User input triggers predefined responses. Conversations stay on rails. These systems handle narrow tasks reliably but break when users deviate from expected paths.
Modern conversational AI handles open-ended dialog. It maintains context windows across multiple exchanges. It integrates with external data sources through retrieval-augmented generation. It adapts responses based on conversation history and user goals.
The trade-off shifts from predictability to flexibility. Rule-based systems rarely surprise you. LLM-based systems handle edge cases better but introduce uncertainty about factual accuracy and reasoning consistency.
How Conversational AI Systems Process Requests
A conversational AI request flows through several stages. Understanding this pipeline clarifies where reliability breaks down and where verification matters most.
Request-to-Response Flow
- Input processing – system receives text or converts speech to text, normalizes formatting, identifies language
- Intent recognition – model determines what user wants (question, command, clarification, objection)
- Entity extraction – system identifies key information (dates, names, amounts, categories)
- Context retrieval – system accesses conversation history, relevant documents, or external data
- Response generation – model produces answer based on intent, entities, and retrieved context
- Output formatting – system structures response (text, list, table, citation), converts to speech if needed
Each stage introduces potential failure points. Intent misclassification sends the request down the wrong path. Missing entities create incomplete context. Retrieval errors surface irrelevant information. Generation produces plausible but incorrect statements.
Dialog State and Memory Management
Dialog management tracks what’s been discussed, what’s been resolved, and what remains open. Simple systems forget previous exchanges. Advanced platforms maintain state across sessions and integrate with user profiles.
State management determines whether the system can:
- Reference earlier statements without repetition
- Track multi-step tasks across interruptions
- Personalize responses based on user history
- Escalate to human review when confidence drops
Memory limitations matter for professional work. A system that forgets the first question by the fifth exchange cannot synthesize information across a research session. Context window size determines how much history the model sees when generating each response.
Retrieval-Augmented Generation and Tool Use
Retrieval-augmented generation (RAG) grounds responses in external data. The system searches documents, databases, or APIs before generating answers. This reduces hallucinations by anchoring output to verified sources.
Tool use extends capabilities beyond text generation. The system can:
- Query databases for current information
- Run calculations or simulations
- Access specialized APIs (legal databases, medical references, financial data)
- Generate structured outputs (JSON, tables, forms)
Combining retrieval with generation creates a verification problem. The model must decide which sources to trust, how to reconcile conflicting information, and when retrieved data contradicts its training. Single-model systems make these judgments without external validation.
Latency vs Accuracy Trade-offs
Faster responses sacrifice thoroughness. A chatbot that answers in 500 milliseconds cannot perform deep retrieval or cross-verification. A system that takes 10 seconds can consult multiple sources and check consistency.
Professional use cases tolerate latency when accuracy matters. Customer support prioritizes speed. Legal review prioritizes correctness. The architecture must match the cost of delay against the cost of error.
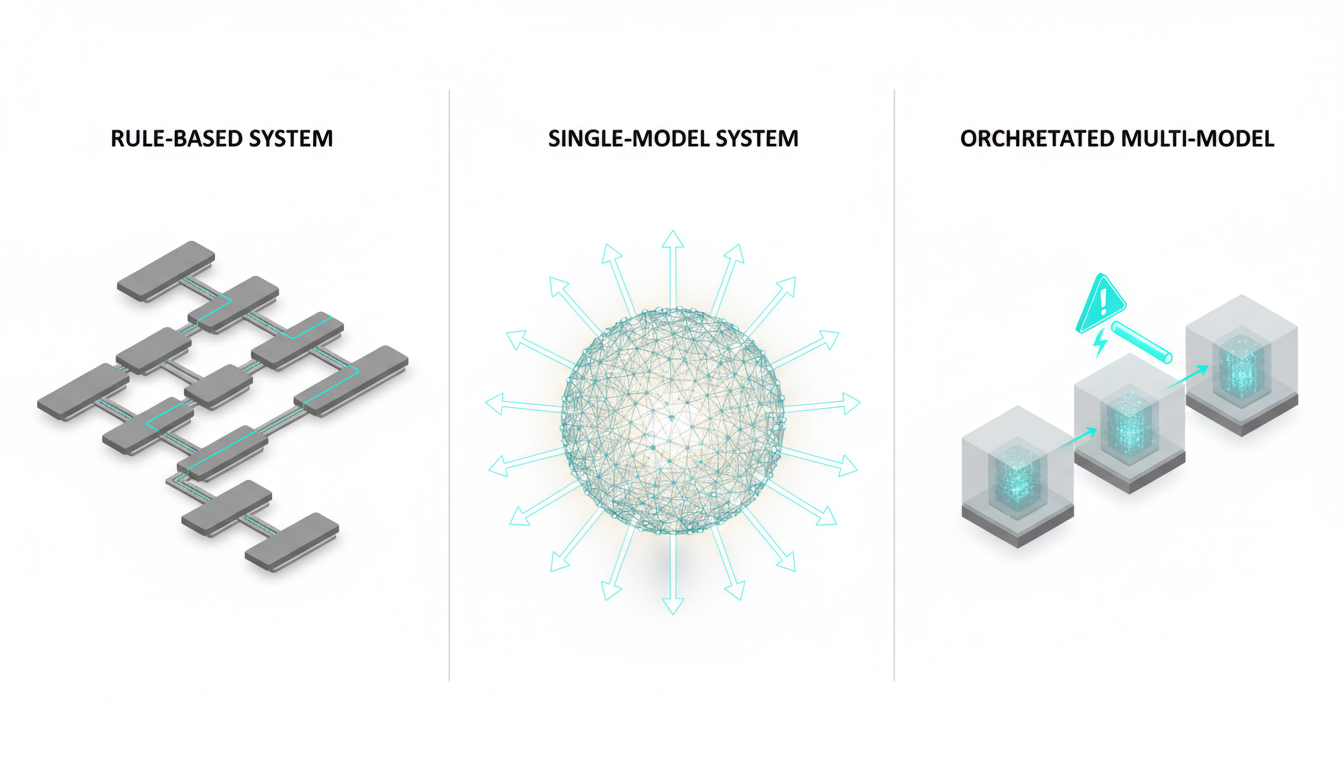
Three Architectures Compared: Rule-Based, Single-Model, and Orchestrated Multi-Model
Conversational AI systems fall into three architectural patterns. Each handles reliability, flexibility, and governance differently. Understanding these patterns helps you evaluate platforms for high-stakes work.
Rule-Based Chatbots: Predictable but Brittle
Rule-based systems follow decision trees. User input matches against patterns. Each pattern triggers a predefined response or action. Conversations stay within scripted paths.
Strengths:
- Predictable behavior – same input produces same output
- Full auditability – every response traces to explicit rules
- No hallucinations – system only says what you programmed
- Low computational cost – pattern matching is fast and cheap
Weaknesses:
- Breaks on unexpected input – users must phrase requests exactly right
- Requires manual updates – adding capabilities means writing new rules
- Poor handling of ambiguity – cannot infer intent from context
- Limited personalization – treats all users identically
Rule-based bots work for narrow, high-volume tasks with well-defined paths. They fail when users need flexible dialog or open-ended problem-solving.
Single-Model LLM Systems: Flexible but Single-Perspective
Single-model systems use one large language model for understanding and generation. The model sees user input, conversation history, and retrieved context. It produces responses based on patterns learned during training.
Strengths:
- Handles open-ended queries – no predefined script needed
- Adapts to context – adjusts responses based on conversation flow
- Generates natural language – output sounds human-written
- Learns from examples – can be fine-tuned for specific domains
Weaknesses:
- Single perspective – one model’s biases and blind spots become the answer
- Hallucinations – produces confident statements without factual grounding
- No built-in verification – cannot check its own reasoning
- Training cutoff limits – knowledge freezes at training date
Single-model chat works for low-stakes interactions where occasional errors don’t matter. It fails when you need validated answers or when different perspectives reveal critical nuances.
Orchestrated Multi-Model Systems: Cross-Verification as Design
Orchestrated systems coordinate multiple models in sequence. Each model sees the full conversation, including responses from previous models. Models challenge assumptions, identify gaps, and surface disagreements.
This architecture treats disagreement as a feature rather than a bug. When models contradict each other, the system highlights the conflict. Users see where perspectives diverge and can investigate further. See Cross-Verification in Action for examples in regulated workflows.
Sequential orchestration differs from parallel queries. In parallel systems, models answer independently. You get five separate opinions with no interaction. In sequential orchestration, each model builds on prior responses. The second model sees what the first said. The third model challenges both. This creates compounding intelligence rather than isolated perspectives.
Strengths:
- Cross-verification catches hallucinations – models fact-check each other
- Multi-perspective analysis – different models surface different considerations
- Disagreement signals risk – conflicts highlight areas needing human review
- Context accumulation – each model adds detail and nuance
- Reduced blind spots – what one model misses, another catches
Weaknesses:
- Higher latency – sequential processing takes longer than single-model response
- Increased cost – running multiple models per request costs more
- Complexity in interpretation – users must evaluate conflicting perspectives
Orchestrated systems match high-stakes professional work where errors carry real costs. They fail when speed matters more than accuracy or when users want simple answers without nuance. About Suprmind describes one implementation of this orchestration approach.
Use Cases Where Conversational AI Delivers Value
Conversational AI applications span customer support, research synthesis, sales enablement, and regulated professional work. The architectural choice determines which use cases succeed.
Customer Support and Triage
Conversational AI handles routine support queries, freeing human agents for complex issues. Systems answer FAQs, troubleshoot common problems, and route requests to appropriate specialists.
Key capabilities:
- Intent recognition to classify request types
- Integration with knowledge bases and product documentation
- Escalation triggers when confidence drops below threshold
- Sentiment analysis to identify frustrated customers
Single-model systems work here because errors have low cost. If the bot misunderstands a question, the user rephrases or escalates. Speed matters more than perfect accuracy.
Research Synthesis and Due Diligence
Professionals use conversational AI to synthesize information across documents, identify patterns, and surface relevant details. Use cases include market research, competitive analysis, and regulatory review.
Critical requirements:
- Citation of sources for every claim
- Contradiction detection across documents
- Handling of ambiguous or incomplete information
- Audit trails showing reasoning path
Multi-model orchestration fits research work. Different models catch different details. Disagreement highlights areas where sources conflict or evidence is thin. Sequential context-building lets each model add depth.
Sales Enablement and RFP Response
Sales teams use conversational AI to draft proposals, answer product questions, and customize messaging. The system accesses product documentation, past proposals, and competitive intelligence.
Value drivers:
- Faster response to prospect questions
- Consistent messaging across team members
- Personalization based on prospect industry and needs
- Identification of relevant case studies and proof points
Hybrid approaches work here. Use single-model systems for initial drafts, then apply human review before sending to prospects. The cost of a generic response is lost deals, not regulatory violation.
Regulated Professional Workflows: Legal, Medical, Financial
High-stakes professional work demands accuracy, provenance, and review workflows. Conversational AI assists with contract review, medical literature search, financial analysis, and compliance checks.
Non-negotiable requirements:
- Source attribution for every statement
- Confidence scores and uncertainty flags
- Human review before final decisions
- Audit trails meeting regulatory standards
- Isolation of training data from client data
Orchestrated multi-model systems match these requirements. Cross-verification reduces hallucinations. Disagreement signals areas needing expert review. Sequential processing allows each model to challenge previous reasoning. The system never makes final decisions – it surfaces information for human judgment.
Internal Knowledge Management
Organizations deploy conversational AI to make internal documentation accessible. Employees query policies, procedures, and institutional knowledge through natural language.
Implementation considerations:
- Integration with existing knowledge bases and wikis
- Access control based on user roles and permissions
- Feedback loops to identify gaps in documentation
- Analytics on common questions to improve content
RAG-enhanced single-model systems work for internal knowledge bots. The retrieval layer grounds responses in company documents. Errors matter less because users can verify answers against source material.
Reliability Challenges and Risk Mitigation Strategies
Conversational AI systems fail in predictable ways. Understanding failure modes helps you build mitigation strategies and set appropriate review thresholds.
Error Taxonomy: How Systems Fail
Four error types dominate conversational AI failures:
- Omission – system misses relevant information that should inform the answer
- Fabrication – system invents facts, citations, or reasoning unsupported by data
- Misclassification – system misunderstands intent or context, answering the wrong question
- Unsafe guidance – system provides advice that could cause harm if followed
Omission errors hide in what the system doesn’t say. A legal research bot that misses a relevant precedent produces an incomplete answer that looks complete. Fabrication errors sound authoritative – the system cites nonexistent sources or invents statistics. Misclassification errors waste time by solving the wrong problem. Unsafe guidance creates liability when users act on incorrect advice.
Cross-Verification and Contradiction Detection
Cross-verification runs the same query through multiple models and compares outputs. Agreements increase confidence. Disagreements flag areas needing human review.
Contradiction detection identifies conflicting statements within or across responses. If one model says a regulation applies and another says it doesn’t, the system highlights the conflict rather than picking a winner.
Implementation patterns:
- Run parallel queries for speed, compare outputs, surface disagreements
- Run sequential queries for depth, let each model challenge previous responses
- Use smaller models for initial screening, larger models for verification
- Set agreement thresholds based on cost of error in each use case
Cross-verification adds cost and latency. The trade-off makes sense when errors are expensive. A customer support bot doesn’t need verification. A medical literature review does.
Provenance, Citations, and Audit Trails
Professional work requires knowing where information came from. Conversational AI systems must track sources and reasoning paths.
Provenance requirements:
- Link every claim to source documents
- Show which model generated each statement
- Log retrieval queries and results
- Record confidence scores and uncertainty flags
- Maintain version history of responses
Audit trails meet regulatory requirements. They let reviewers trace decisions back to inputs. They enable post-incident analysis when errors occur. They provide evidence that appropriate review processes were followed.
Human-in-the-Loop and Escalation Triggers
No conversational AI system should make high-stakes decisions autonomously. Human review remains essential for regulated work, strategic decisions, and novel situations.
Escalation triggers include:
- Low confidence scores across models
- High disagreement rates between models
- Requests involving regulated actions (medical advice, legal guidance, financial recommendations)
- Novel situations outside training data
- User-initiated escalation when answer seems wrong
The escalation threshold determines system utility. Set it too low and humans review everything, eliminating efficiency gains. Set it too high and errors slip through. The right threshold depends on error cost and human review capacity.
Watch this video about conversational ai:
Framework for Evaluating Conversational AI Platforms
Selecting a conversational AI platform requires evaluating technical capabilities, governance features, and business fit. This framework provides scoring criteria and decision points.
Core Capability Metrics
Measure these technical capabilities:
- Task success rate – percentage of queries answered correctly without escalation
- Factuality score – accuracy of claims when checked against source documents
- Agreement rate – consistency across multiple models or repeated queries
- Contradiction rate – frequency of conflicting statements within responses
- Latency – time from query to complete response
- Cost per session – computational cost including model calls and retrieval
Task success matters most for operational efficiency. Factuality matters most for professional accuracy. Agreement rate indicates reliability. Contradiction rate signals where human review is needed. Latency determines user experience. Cost determines scalability.
User Experience and Satisfaction
Technical metrics don’t capture user perception. Track these experience indicators:
- User satisfaction scores after interactions
- Escalation frequency – how often users give up and seek human help
- Session length and query count – longer sessions may indicate struggle or engagement
- Repeat usage rates – do users return after first experience
- Error correction requests – how often users rephrase or challenge answers
High satisfaction with low accuracy indicates users can’t judge correctness. Low satisfaction with high accuracy indicates poor explanation or presentation. The goal is high satisfaction with verifiable accuracy.
Security and Compliance Checklist
Regulated industries require specific security and governance controls. Verify these capabilities:
- Data isolation – client data never used to train models
- Access controls – role-based permissions for sensitive information
- Audit logging – complete records of queries, responses, and actions
- Encryption – data encrypted in transit and at rest
- Compliance certifications – SOC 2, HIPAA, GDPR as needed
- Data retention policies – configurable retention and deletion
- Human review workflows – built-in approval processes for regulated actions
Missing any item on this list disqualifies platforms for regulated use. Security cannot be added later – it must be architectural.
Platform Comparison Matrix
Score platforms across these dimensions:
| Criterion | Weight | Scoring Guidance |
|---|---|---|
| Orchestration capability | High | Single model = 1, parallel models = 2, sequential orchestration = 3 |
| Context window size | High | Score based on tokens: <10K = 1, 10K-50K = 2, >50K = 3 |
| Source attribution | High | None = 0, basic citations = 1, full provenance = 2 |
| Data governance | High | Score against security checklist: missing items = 0, partial = 1, complete = 2 |
| Integration options | Medium | API only = 1, API + webhooks = 2, native integrations = 3 |
| Customization | Medium | Fixed = 1, configurable = 2, fully customizable = 3 |
| Cost transparency | Medium | Opaque = 0, usage-based = 1, predictable = 2 |
Weight scores by importance to your use case. Sum weighted scores to compare platforms objectively.
Build vs Buy Decision Framework

Organizations face a choice between building custom conversational AI systems or buying existing platforms. The right answer depends on technical capability, use case specificity, and strategic importance.
When to Build In-House
Build when:
- Your use case requires proprietary data or processes competitors don’t have
- You have deep ML engineering expertise and infrastructure
- Existing platforms lack critical capabilities you need
- Data sensitivity prevents using external services
- Long-term cost of building is lower than licensing
Building requires sustained investment. You need data scientists, ML engineers, infrastructure specialists, and ongoing model maintenance. Underestimate these costs at your peril.
When to Buy Existing Platforms
Buy when:
- Your use case matches common patterns (support, research, knowledge management)
- You lack ML expertise or want to focus on core business
- Time-to-value matters more than perfect customization
- Vendors offer capabilities you can’t build quickly
- Platform costs are reasonable relative to build costs
Buying means accepting vendor constraints. You depend on their roadmap, their uptime, their pricing changes. Evaluate pricing transparency and lock-in risk carefully.
Vendor Evaluation Criteria
When evaluating vendors, prioritize:
- Orchestration capability – can they coordinate multiple models or just offer single-model chat
- Context handling – what context window sizes do they support, how do they manage long conversations
- Data governance – how do they handle your data, what certifications do they have, can you audit their practices
- Integration flexibility – how easily does their platform connect to your existing systems and data
- Customization options – can you tune models, adjust workflows, or add custom logic
- Pricing transparency – do you understand what you’ll pay at scale, are there hidden costs
- Vendor stability – will they be around in three years, do they have sustainable business model
Request proof-of-concept projects before committing. Test with your actual data and use cases. Measure latency, accuracy, and user satisfaction with real workflows.
Hybrid Approaches
Many organizations start with vendor platforms and add custom components over time. You might:
- Use vendor LLMs with your own retrieval and orchestration logic
- Build custom fine-tuned models for domain-specific tasks while using general models for everything else
- Develop proprietary evaluation and monitoring on top of vendor platforms
- Create custom human-review workflows that integrate with vendor AI
Hybrid approaches balance speed-to-market with customization. They require clear interfaces and contracts between your components and vendor services.
Implementation Patterns for Enterprise Deployment
Deploying conversational AI at scale requires planning, piloting, and continuous evaluation. These patterns reduce risk and improve outcomes.
Pilot Selection and Scoping
Start with a pilot that:
- Addresses a real pain point with measurable impact
- Has manageable scope – one team, one workflow, clear success criteria
- Allows failure without catastrophic consequences
- Provides learning applicable to future use cases
Avoid pilots that are too small (no real impact) or too large (too many variables). Choose workflows where human experts can validate AI outputs and where errors are visible quickly.
Data Preparation and Quality
Conversational AI quality depends on data quality. Before deployment:
- Audit existing documentation for accuracy and completeness
- Identify gaps where AI will lack information to answer questions
- Standardize terminology and definitions across sources
- Tag documents with metadata for better retrieval
- Remove outdated or contradictory information
Poor data creates poor outputs. Garbage in, garbage out applies fully to conversational AI. Budget time for data cleanup before expecting good results.
Guardrails and Safety Mechanisms
Implement these safety controls:
- Input validation – reject queries outside allowed scope
- Output filtering – block responses containing prohibited content
- Confidence thresholds – escalate low-confidence answers to human review
- Rate limiting – prevent abuse or accidental overuse
- Audit logging – record all interactions for review
Guardrails prevent the most obvious failures. They don’t eliminate all risk – you still need human review for high-stakes decisions.
Human Review Loops and Escalation
Design review workflows before deployment:
- Define which outputs require review before use
- Set escalation triggers based on confidence, disagreement, or content type
- Create clear handoff processes from AI to human experts
- Track review time and bottlenecks
- Collect feedback to improve AI performance
Review workflows balance efficiency with safety. Too much review eliminates AI benefits. Too little review allows errors to propagate. The right balance depends on error cost and review capacity.
Monitoring and Continuous Evaluation
Track these metrics post-deployment:
- Usage volume and patterns
- Task success and escalation rates
- User satisfaction scores
- Error rates by category
- Latency and cost per session
- Human review time and outcomes
Set up automated alerts when metrics degrade. Review edge cases and errors weekly. Update documentation and guardrails based on what you learn. Conversational AI requires ongoing tuning – it’s not a set-and-forget technology.
Future Directions in Conversational AI
Conversational AI capabilities evolve rapidly. Understanding emerging trends helps you plan for change and avoid obsolete investments.
Long-Context Workflows and Multi-Agent Collaboration
Context windows expand from thousands to millions of tokens. This enables:
- Whole-document synthesis without chunking
- Multi-session conversations with full history
- Cross-document analysis at scale
- Reduced need for external retrieval systems
Multi-agent systems coordinate specialized models for different tasks. One agent handles research, another drafts, another fact-checks. Agents communicate through structured protocols rather than natural language.
Multimodal Reasoning and Tool Ecosystems
Multimodal AI processes text, images, audio, and video together. Conversational systems will:
- Analyze documents with charts and diagrams
- Generate visual explanations alongside text
- Process meeting recordings with speaker identification
- Combine multiple input types in single queries
Tool ecosystems expand beyond simple API calls. Systems will chain tools together, learn from tool outputs, and propose new tool combinations. The boundary between conversational AI and workflow automation blurs.
Standardization of Provenance and Audit
Regulatory pressure drives standardization of:
- Source attribution formats
- Confidence score methodologies
- Audit log structures
- Model card requirements
- Bias and fairness reporting
Standards enable comparison across platforms and regulatory compliance across jurisdictions. Expect increased requirements for explainability and documentation in regulated industries.
Implications for Platform Selection
When evaluating platforms, consider:
- How quickly does vendor adopt new model capabilities
- Can platform handle longer context as it becomes available
- Does architecture support multi-agent patterns
- Will vendor meet emerging regulatory requirements
- Can you migrate to newer models without rebuilding integrations
Avoid platforms locked to specific model versions or vendors. The field moves too quickly for rigid commitments.
Resource Grid and Next Steps

These resources help you evaluate, implement, and govern conversational AI systems.
Key Terms Defined
- Natural language processing – techniques for analyzing and generating human language
- Natural language understanding – extracting meaning, intent, and entities from text
- Dialog management – tracking conversation state and deciding next actions
- Large language models – neural networks trained on massive text corpora to understand and generate language
- Intent recognition – classifying what user wants from their query
- Entity extraction – identifying key information like names, dates, and amounts
- Context window – amount of prior conversation the model sees when generating responses
- Hallucinations – confident AI statements unsupported by training data or sources
- Retrieval-augmented generation – grounding responses in external documents or data
Evaluation Templates
Download these tools to assess platforms and track performance:
- Vendor comparison matrix with scoring rubric
- Security and compliance checklist for regulated industries
- Pilot success criteria template
- Error taxonomy and severity classification
- Human review workflow design template
Implementation Checklists
Use these checklists to guide deployment:
- Pre-deployment data quality audit
- Guardrail configuration checklist
- Escalation trigger definitions
- Monitoring dashboard requirements
- Incident response procedures
External Standards and Research
Reference these sources for deeper technical understanding:
- NIST AI Risk Management Framework for governance guidance
- Stanford HELM benchmarks for model evaluation
- ACL and EMNLP conference proceedings for latest research
- Industry-specific guidelines (FDA for medical AI, SEC for financial AI)
Frequently Asked Questions
How does conversational AI differ from a simple chatbot?
Conversational AI uses natural language understanding and learning-based models to handle open-ended dialog and maintain context across exchanges. Simple chatbots follow predefined decision trees and require exact input patterns. Conversational AI adapts to user phrasing and intent. Chatbots break when users deviate from scripts.
What causes AI systems to hallucinate, and how can you prevent it?
Hallucinations occur when models generate plausible-sounding content unsupported by training data or retrieval sources. Prevention strategies include retrieval-augmented generation to ground responses in verified documents, cross-verification across multiple models to catch inconsistencies, confidence thresholds to flag uncertain outputs, and human review for high-stakes decisions.
Which industries benefit most from conversational AI?
Customer service, healthcare, legal services, financial services, and education see significant value. Any industry with high-volume information requests, complex documentation, or need for 24/7 availability benefits. The key factor is whether natural language interaction improves access to information or services compared to traditional interfaces.
How do you measure ROI for conversational AI implementations?
Track cost savings from reduced human handling time, revenue impact from faster response to customers, error reduction in high-stakes decisions, and user satisfaction improvements. Calculate cost per interaction for AI versus human handling. Factor in implementation costs, ongoing maintenance, and human review requirements. ROI varies dramatically by use case and error cost.
What data governance requirements apply to conversational AI?
Requirements include data isolation preventing client data from training models, access controls limiting who sees sensitive information, audit logging recording all interactions, encryption protecting data in transit and at rest, compliance certifications like SOC 2 or HIPAA, configurable retention policies, and human review workflows for regulated actions. Regulated industries face stricter requirements than general business use.
Can conversational AI work offline or in air-gapped environments?
Yes, but with limitations. You can deploy models locally for offline use, but you lose access to cloud-based updates, retrieval from external sources, and orchestration across multiple hosted models. Local deployment requires significant computational resources and expertise. Most organizations use cloud services for flexibility and capability, with local deployment reserved for specific security requirements.
Making Conversational AI Work for High-Stakes Decisions
Conversational AI integrates natural language understanding, dialog management, retrieval, and generation to enable natural interaction with systems. The architecture you choose determines reliability. Rule-based systems offer predictability but break on edge cases. Single-model systems provide flexibility but lack verification. Orchestrated multi-model systems enable cross-verification and disagreement detection at the cost of latency and complexity.
Key takeaways for professionals evaluating conversational AI:
- Match architecture to error cost – high-stakes work requires cross-verification and human review
- Evaluate platforms on orchestration capability, context handling, data governance, and audit features
- Implement guardrails, escalation triggers, and monitoring before deployment
- Start with focused pilots that provide learning without catastrophic risk
- Plan for continuous evaluation and improvement – conversational AI requires ongoing tuning
You now have definitions, architectural comparisons, evaluation frameworks, and implementation patterns to guide platform selection and deployment. The right conversational AI system reduces error rates, improves decision quality, and scales expertise across your organization.
When reliability matters more than speed, when errors carry real costs, and when single perspectives miss critical details, orchestrated multi-model systems change what’s possible. Explore frameworks that prioritize cross-verification and disagreement detection to see how architecture shapes outcomes. For an overview of options and decision points, visit the product hub.





