
Your team spent three hours debating product priorities. The AI transcribed everything. The summary looks clean. Everyone nods and moves forward.
Then someone asks: “Wait, who owns the API redesign?” Silence. The notes say Sarah, but Sarah remembers volunteering to coordinate it, not build it. Another 30 minutes evaporate re-litigating what was already decided.
This isn’t a meeting problem. It’s a reliability problem. When AI meeting notes miss edge cases – misattributed speakers, lost decisions, hallucinated action items – your strategy moves forward on faulty intelligence. The cost isn’t the meeting itself. It’s the rework, the missed deadlines, and the slow erosion of trust in your process.
The Hidden Cost of Confident-But-Wrong Summaries
Single-model AI notes sound authoritative. They format beautifully. They arrive seconds after your call ends. But under the surface, they’re fragile.
Where AI Meeting Notes Break Down
Most transcription failures cluster around predictable weak points:
- Diarization mix-ups – Two speakers with similar voices get merged into one person, scrambling who said what
- Domain jargon errors – Technical terms and acronyms get mangled (“API gateway” becomes “eight-way gateway”)
- Crosstalk and interruptions – Overlapping speech confuses the model, dropping critical objections or caveats
- Accent and audio quality – Low-bandwidth connections or non-native speakers introduce transcription drift
- Implicit context – References to “the dashboard” or “last quarter’s issue” get summarized without the context that makes them meaningful
Each failure mode is small. But in high-stakes work – quarterly planning, clinical reviews, legal discovery – small errors compound into strategic drift.
Why Commercial Investigation Matters Here
If you’re evaluating AI note-taking tools, you’re not just shopping for convenience. You’re assessing decision risk. The wrong choice means your team operates on unreliable intelligence. The right choice means action items land correctly, decisions stick, and follow-ups happen without re-litigation.
Buyer criteria shift when meeting criticality increases. Speed matters less than verifiable accuracy. A five-minute delay to cross-check summaries is trivial compared to a week of rework from missed commitments.
From Fast Notes to Verifiable Notes
The shift isn’t about better transcription models. It’s about changing the architecture from single-perspective summarization to orchestrated verification.
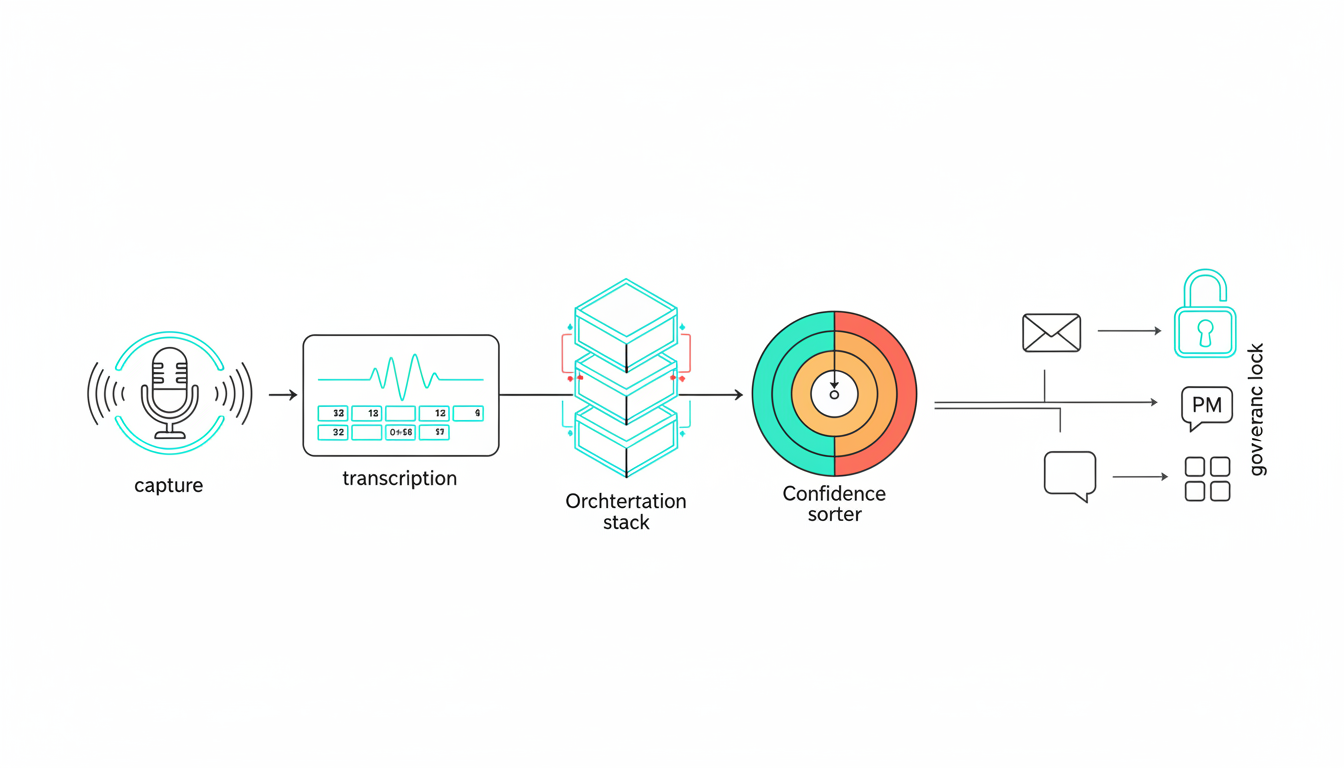
How Multi-Model Orchestration Works
Instead of one AI summarizing your meeting, multiple frontier models process the same transcript in sequence. Each model sees what the others concluded. Disagreements get flagged. Confidence scores attach to action items.
The workflow looks like this:
- Capture – Record with clean audio and speaker labels
- Transcribe – Generate text with timestamps and diarization
- Segment – Break transcript into logical blocks by speaker and topic
- Multi-model summarization – Five models each generate summaries, seeing prior context
- Cross-verification – Compare outputs and identify conflicts or gaps
- Conflict resolution – Surface disagreements for human review or consensus logic
- Confidence scoring – Assign A/B/C tiers to action items based on agreement
- Distribution – Send notes to email, Slack, or project management tools with source links
This isn’t parallelization. It’s sequential context-building. Each model compounds insight rather than offering isolated opinions. When models disagree, that friction reveals edge cases – the moments where a single perspective would have missed something critical.
Why Disagreement Is Signal, Not Noise
If three models agree Sarah owns the API redesign but two models flag ambiguity, that’s valuable. It means the meeting left room for misinterpretation. You can clarify ownership now instead of discovering the gap two weeks later.
Platforms that coordinate multiple frontier models – like Suprmind’s cross-verification approach – treat disagreement as a feature. When GPT, Claude, Gemini, Perplexity, and Grok process the same meeting sequentially, conflicts surface blind spots. The system doesn’t hide friction. It highlights where human judgment still matters.
Measuring What Actually Matters

You can’t improve what you don’t measure. Reliable AI meeting notes require quantified evaluation criteria, not anecdotal confidence.
Accuracy KPIs
- Action item recall – Percentage of actual commitments captured in notes
- Action item precision – Percentage of listed action items that are real (not hallucinated)
- Decision capture rate – How many explicit decisions make it into the summary
- Owner attribution accuracy – Correct assignment of tasks to individuals
Operational KPIs
- Time-to-summary – How quickly usable notes arrive post-meeting
- Rework reduction – Drop in follow-up meetings to clarify action items
- Follow-up completion rate – Percentage of action items closed on time
Governance KPIs
For regulated industries or enterprise buyers, compliance isn’t optional:
- Auditability – Can you trace every summary claim back to transcript timestamps?
- PII handling – Are sensitive details redacted or flagged automatically?
- Retention policy compliance – Do notes expire per your data governance rules?
- Access controls – Can you restrict who sees specific meeting outputs?
To benchmark, create a holdout set of annotated meetings. Run your AI notes against them quarterly. Track regression. If accuracy drifts, investigate model updates or prompt changes.
Building a Reliable AI Notes Pipeline This Week
You don’t need six months to pilot this. Start with one recurring meeting and iterate.
Step 1: Optimize Your Capture Setup
Garbage in, garbage out. Fix the basics:
- Use dedicated microphones or headsets – laptop mics introduce noise
- Ask participants to state their names when they first speak
- Record at 16kHz or higher sample rate
- Test audio levels before critical meetings
- Label speakers in your recording platform if possible
Step 2: Choose Your Transcription Model
Select a model with strong speaker diarization. Whisper variants and commercial APIs like AssemblyAI or Deepgram handle this well. Configure domain-specific vocabulary lists for acronyms and technical terms your team uses.
Step 3: Set Up Multi-Model Orchestration
If you’re building in-house, prompt multiple models with the same transcript. Have each model:
- Summarize key decisions and action items
- Extract owners and due dates
- Flag ambiguous statements or conflicting points
Feed each model’s output to the next so context compounds. Set disagreement thresholds – if two or more models conflict on an action item, escalate it for human review.
Alternatively, use a platform designed for orchestrated workflows. Cross-verification in high-stakes workflows shows how sequential model coordination reduces blind spots without manual wrangling.
Step 4: Apply a Confidence Rubric
Not all action items are equal. Assign tiers:
- Tier A – All models agree, owner confirmed, due date explicit
- Tier B – Models agree, but owner or deadline needs clarification
- Tier C – Models disagree or item is vague; requires human review
Send Tier A items directly to your project management tool. Flag Tier B and C items for quick confirmation before they enter the workflow.
Step 5: Distribute and Link to Source
Send notes to email, Slack, or your PM tool. Always include a link back to the source transcript with timestamps. If someone questions an action item, they can verify it in seconds.
Step 6: Lock Down Governance
Set retention policies now. Decide how long meeting notes and transcripts live. Configure redaction rules for PII. Enable audit logs so you can trace who accessed what. Assign admin controls for enterprise environments.
If you’re in a regulated industry, map these controls to your compliance framework before rolling out broadly.
Choosing the Right Tool Without Regret
The market splits into two camps: single-model meeting bots and multi-model orchestration platforms. Your requirements dictate which path makes sense.
Single-Model Bots
These tools integrate directly with Zoom, Teams, or Google Meet. They’re fast, cheap, and easy to deploy. They work well for low-stakes meetings where occasional errors don’t matter.
Pros:
- Plug-and-play setup
- Low cost per meeting
- Native platform integration
Cons:
- No cross-verification
- Brittle on edge cases (jargon, crosstalk, accents)
- Limited governance controls
- Hallucinations go undetected
Multi-Model Orchestration Platforms
These systems coordinate multiple frontier models to cross-check outputs. They surface disagreements and assign confidence scores. They’re built for high-stakes work where accuracy isn’t negotiable.
Pros:
- Cross-verification catches errors
- Disagreement flags edge cases
- Confidence scoring for action items
- Better handling of domain jargon and ambiguity
- Enterprise governance and audit trails
Cons:
Watch this video about ai meeting notes:
- Higher inference costs
- Slightly longer processing time
- Requires bring-your-own-recording or API integration
Must-Have Features for Enterprise Buyers
If you’re evaluating tools for a team or organization, these capabilities are non-negotiable:
- Long context windows – Models must handle 90-minute meetings without truncation
- Speaker diarization – Accurate attribution is foundational
- Domain glossaries – Custom vocabulary for your industry or team
- Cross-verification – Multiple models or human-in-the-loop validation
- Auditability – Trace every claim to source transcript
- SSO and access controls – Enterprise authentication and permissions
- Data residency – Control where meeting data lives
- SOC 2 or ISO posture – Compliance certifications for regulated industries
Total Cost of Ownership
Don’t just compare subscription prices. Factor in:
- Inference costs – Multi-model orchestration costs more per meeting but saves rework
- Rework savings – Fewer follow-up meetings and clarifications
- Compliance risk reduction – Avoiding audit failures or PII leaks
- Integration overhead – Time to connect to your existing tools
A tool that costs twice as much but cuts rework by 40% delivers positive ROI in weeks.
If you’re comparing orchestration approaches and want to see how multi-model coordination handles disagreement in practice, learn how multi-AI orchestration handles meeting notes reliably with sequential context-building and confidence scoring.
Templates and Tools to Start Today
Accelerate your pilot with these ready-to-use resources.
Meeting Minutes Template
Use this structure for every summary:
- Meeting title and date
- Attendees (with roles if relevant)
- Key decisions (bullet list with context)
- Action items (owner, due date, confidence tier)
- Open questions (items needing follow-up)
- Link to source transcript (with timestamps for key moments)
Action Item Confidence Checklist
Before sending action items to your PM tool, verify:
- Owner explicitly volunteered or was assigned (not inferred)
- Due date was stated or agreed upon
- Task is specific enough to be actionable
- No conflicting interpretations in the transcript
- All models (if using orchestration) agree on the item
If any check fails, escalate to Tier B or C for human confirmation.
Prompt Snippets for Edge Cases
When summarizing, add these instructions to your prompts:
- “Flag any action items where the owner is ambiguous or inferred.”
- “Highlight statements where speakers disagree or express uncertainty.”
- “List acronyms or jargon that may have been transcribed incorrectly.”
- “Note any crosstalk or interruptions that may have caused information loss.”
ROI Calculator Outline
Track these metrics to quantify value:
- Time saved per meeting – Manual note-taking hours eliminated
- Rework hours avoided – Follow-up meetings or clarifications prevented
- Error cost avoided – Estimate cost of one missed action item or wrong decision
- Compliance risk reduction – Value of avoiding audit failures or PII leaks
Multiply time saved by your team’s hourly rate. Add rework and error cost savings. Compare to tool subscription and inference costs. Most teams see positive ROI within four weeks.
A Strategy Review That Avoided a Costly Misstep
A product team was planning their Q2 roadmap. The meeting ran 90 minutes. Everyone left confident about priorities.
The AI summary listed five features in ranked order. Feature three was “expand API rate limits.” The team started design work.
Two weeks later, the engineering lead asked why they were prioritizing rate limits. He remembered the discussion differently – the team had agreed rate limits were a nice-to-have, not a Q2 commitment.
They pulled the transcript. The conversation was messy. Three people talked over each other. The final decision was ambiguous. One model had interpreted it as a commitment. Another model flagged it as uncertain.
The orchestration platform surfaced the disagreement. The team caught it before investing design and engineering time. They clarified the priority in five minutes and moved forward with confidence.
That’s the value of cross-verification. Not eliminating human judgment, but highlighting where judgment is needed before costly mistakes happen.
What You’re Taking With You
Reliable AI meeting notes aren’t about faster summaries. They’re about verifiable intelligence that supports high-stakes decisions without rework.
- Single-model AI notes are fast but fragile – they miss edge cases and hallucinate with confidence
- Multi-model orchestration cross-checks outputs, surfaces disagreements, and assigns confidence scores
- Measure accuracy with KPIs – action item recall, decision capture, owner attribution
- Use a confidence rubric to tier action items before they enter your workflow
- Choose tools based on reliability requirements, not just speed or cost
- Enterprise buyers need long context, diarization, cross-verification, and governance controls
You now have a framework to evaluate accuracy, a practical setup plan, and templates to run reliable AI notes without extra meetings. The question isn’t whether AI can take notes. It’s whether those notes are trustworthy enough to base your strategy on.
If you’re ready to see how orchestrated multi-model workflows handle disagreement and confidence scoring in real calls, start your first orchestration to test cross-verified meeting notes on your next high-stakes conversation.
Frequently Asked Questions
How accurate are AI-generated meeting notes compared to human note-takers?
Single-model AI notes achieve 70-85% accuracy on action items in clean conditions but drop significantly with crosstalk, jargon, or accents. Multi-model orchestration with cross-verification pushes accuracy above 90% by catching errors that individual models miss. Human note-takers remain gold standard for nuance but miss details during fast-paced discussions. The best approach combines AI speed with human review of flagged uncertainties.
What happens when models disagree on an action item?
Disagreement signals ambiguity in the source conversation. The system flags the conflict and escalates it for human review. You see what each model concluded and can check the transcript timestamps. This catches edge cases where a single model would have confidently delivered the wrong answer. Most disagreements resolve in under a minute of clarification.
Can these tools handle technical meetings with domain-specific jargon?
Yes, with configuration. Feed the system custom glossaries of acronyms and technical terms specific to your industry. Multi-model orchestration helps because different models have different training data – one may recognize a term another misses. Expect 2-3 weeks of tuning for highly specialized domains like biotech or aerospace.
How do I ensure meeting notes comply with data privacy regulations?
Choose platforms with built-in PII redaction, data residency controls, and audit logs. Set retention policies so transcripts and notes expire per your governance rules. Use SSO and role-based access controls to restrict who sees sensitive meetings. For regulated industries, verify the vendor’s SOC 2 or ISO certifications before deployment.
What’s the difference between real-time transcription and post-meeting summarization?
Real-time transcription streams text as people speak – useful for live captions but prone to errors that don’t get corrected. Post-meeting summarization processes the full recording after the call ends, allowing for better diarization, context analysis, and cross-verification. Most orchestration platforms work post-meeting to maximize accuracy over speed.
How much does multi-model orchestration cost per meeting?
Inference costs vary by meeting length and model selection. Expect $2-8 per 60-minute meeting for orchestrated processing with five frontier models. Compare this to the cost of one rework meeting (typically $200-500 in team time) or one missed action item. Most teams see positive ROI within four weeks of deployment.
Can I integrate these notes with my existing project management tools?
Yes. Most platforms offer APIs or native integrations with tools like Asana, Jira, Monday, and Linear. Action items flow directly into your PM system with owners, due dates, and confidence tiers. Link back to source transcripts so team members can verify context without asking for clarification.
What if my team uses multiple meeting platforms?
Bring-your-own-recording approaches work across Zoom, Teams, Google Meet, and phone calls. Record locally or use platform recording features, then upload to your AI notes system. This gives you consistent processing regardless of where meetings happen. Native bots lock you into specific platforms and limit governance controls.





